
실무에서 겪었던 성능 개선 기록을 남겼습니다.
이슈 발견
CloudWatch 그래프
영화관 시스템의 운영 담당자로서 매일 하는 업무는 CloudWatch metrics 를 통해 전날에 있었던 RDS CPU Utilization 을 확인하는 것입니다.
영화 "파묘" 가 큰 흥행을 하며, RDS의 CPU 사용량을 확인 하던 중 아래와 같은 그래프를 발견 했습니다.
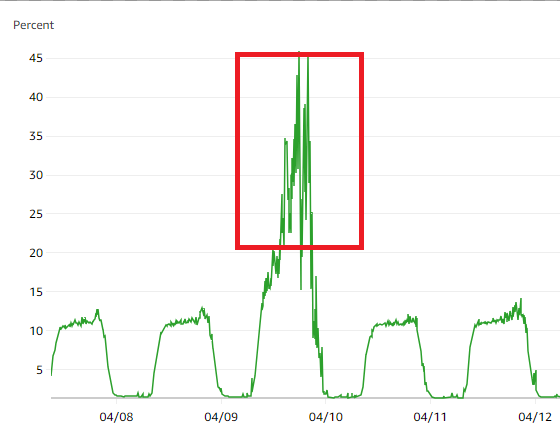
관객들이 더 많았던 주말이라는 상황을 생각해도, 36,000건 정도의 데이터가 인입 된 상황에서 CPU 사용량이 45% 상승한 것은 비정상적인 이슈라 판단하였습니다.
또 한번의 천만 관객이 예상 되는 "범죄 도시 4" 영화가 개봉하기 전에 더 깊이 있는 분석이 필요하다 생각해서 튜닝 업무를 주도적으로 맡아 진행 했습니다.
이슈 접근 1
어떤 쿼리가 지연을 발생 하는거지?
CPU 사용량의 원인을 파악하기 위해 어떤 쿼리가 지연을 발생 시키는것인지 알아내는게 중요하다 생각했습니다. PostgreSQL 을 메인으로 사용하고 있는 저희의 서비스에서 AWS RDS Performance Insight 기능을 처음 사용해봤습니다.
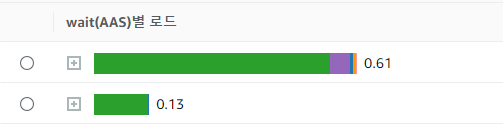
AAS 란?
- Average Active Session, 평균 활성 세션이라고도 불린다.
- 쿼리의 결과를 받기 위해 대기중인 connection
초록색 Bar은 RDS 가 현재 connection 을 유지하면서 사용 중인 CPU 지표를 뜻합니다. CPU 사용량의 비중이 높을 수록 쿼리 실행 이 오래 걸린 것을 의미합니다.
결과적으로, RDS Performance Insight 를 통해서 "제조용 모니터의 매점 주문 조회 쿼리" 가 가장 높은 SQL 지연을 발생시키는 것을 찾아냈습니다.
이슈 접근 2
왜 지연이 걸리는 걸까?
지연 쿼리를 찾아낸 이후에는 어떤 원인에서 지연이 걸리는지 확인하고 싶었습니다. 가장 먼저 의심 했던 부분은 아래와 같습니다.
"조회 성능이 떨어지는 건 Index가 컬럼에 적용이 안되어서 그런가?"
과거에 프로젝트를 진행하면서 조회 성능 개선에 관한 실험을 하던 중에 index 를 추가 후 많은 성능 개선을 경험했기에 접근을 해봤습니다.
select indexname, indexdef
from pg_indexes
where tablename = "order_table" //주문 조회 테이블 (예시)
매점 주문 조회 쿼리에 사용되는 테이블과 WHERE 조건 안에 있는 컬럼들을 비교하면서 찾아봤을 때, 필요한 모든 컬럼에는 이미 index 가 잘 적용이 되어 있었습니다. 그럼에도 조회 성능에 지연이 크게 걸리는 점은 깊이 있는 분석이 필요하다 생각했습니다.
조회 쿼리에서 사용 된 실행 계획을 자세하게 볼 수 있게 PostgreSQL 에서의 EXPLAIN 쿼리를 사용 했습니다. PostgreSQL 공식 문서
EXPLAIN ANALYZE ANALYZE 쿼리를 통해서 실행 되는 각 쿼리마다 걸린 actual time 및 cost 같은 유용한 정보를 얻을 수 있었지만, 깊이 있는 튜닝을 위해서는 시간적인 정보 외에 디스크 I/O 와 같은 디테일한 부분이 필요 하다 생각해서 BUFFERS 를 추가 했습니다. BUFFERS 의미
EXPLAIN (ANLYZE, BUFFERS) 쿼리를 상세하게 분석해본 결과, 특이한 점이 눈에 들어왔습니다.
이슈 접근 3
Index Only Scan 인데 왜 Heap Fetch를 하는거지?
PostgreSQL 에서는 데이터를 검색할 때 아래 5가지 방법을 사용합니다
- Sequential Scan : 순차적으로 테이블을 읽는 방식
- Index Scan : 컬럼 인덱스를 사용하여 데이터를 빠르게 찾는 방식
- Index-Only Scan : 테이블에 엑세스하지 않고 인덱스에서만 데이터를 검색하는 방식
- Bitmap Index Scan : 여러 인덱스를 사용하여 데이터를 찾는 방식
- TID Scan : 필요한 행의 튜플 ID(TID) 를 사용하여 데이터를 찾는 방식
앞서 EXPLAIN 문을 사용한 쿼리 분석 과정에서 주문 테이블을 읽는 방식에 Index-Only-Scan 이 활용 되고 있었습니다. WHERE 조건 문 안에 있는 모든 컬럼에는 INDEX 가 적용이 되어 있었고, 쿼리 플랜에서는 테이블에 액세스 하지 않는 방식의 Index-Only Scan 을 사용하고 있었지만 동시에 Heap Fetch 가 포함되어 있어서 의문을 가졌습니다.

Heap Fetch 란?
- 쿼리를 실행할 떄 힙 또는 테이블의 데이터를 읽는 작업
Heap Fetch 가 많을 수록, DB는 디스크에서 데이터를 가져오는 작업을 더 많이 수행하게 됩니다. 일반적으로 디스크에서 데이터를 자주 읽어오는 방식은 디스크 I/O 영역을 건드리는 것이기 때문에 많은 READ 가 일어날 수록 성능에 영향을 줍니다.
문제를 더 깊게 분석하기 위해 Heap Fetch 가 포함되는 이유를 알아야 했고 아래 개념을 추가로 분석 했습니다.
-> PostgreSQL 에서 Visibility Map 이란?
영화관 시스템에서 주문이 들어오면 호출, 완료, 미수령 등 많은 양의 주문 상태 값 UPDATE 작업이 실행 됩니다. 현재 호출 된 트랜잭션은 가장 최근에 UPDATE 된 데이터를 찾기 위해 Visibility Map 에 매핑 된 정보를 보지만, 매핑이 잘 안되어 있었기에 Heap Fetch 를 통해 테이블에서의 데이터를 읽었습니다.
결론적으로,
Index-Only Scan 임에도 Heap Fetches 가 포함되어 있던 이유는 현재 Transaction 에서 가장 최근 변경 된 최신 데이터를 찾기 위해 테이블을 스캔해야 했기 때문입니다.
최종 튜닝
최종 튜닝 방안으로 PostgreSQL 의 Vacuum 을 공부하게 되었습니다.
AutoVacuum 파라미터 튜닝
PostgreSQL 을 공부하며 MVCC 개념을 배울 수 있었습니다.
MVCC 란?
- Multi-Version Concurrency Control
- 동시에 실행되는 여러 트랜잭션에서 수행 시점의 데이터를 제공
- 읽기 일관성을 보장
대부분의 다른 DBMS 에서는 MVCC 를 제공하기 위해 LOCK 을 사용하기도 하지만, PostgreSQL 에서는 다중 버전 모델 (multiversion model) 을 사용하여 일관성을 유지합니다.
간단하게 PostgreSQL의 다중 버전 모델을 설명하면 아래와 같습니다.
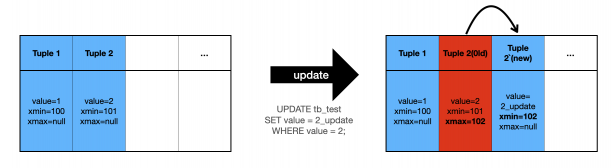
- 한 트랜잭션이 실행되는 상황에서 UPDATE 작업이 실행
- PostgreSQL 에서는 가장 최신에 변경 된 정보를 저장하기 위해 Page 내 사용 가능한 공간에 UPDATE 된 데이터를 기록
- UPDATE 이전의 원본 데이터를 바라보던 포인터를 새롭게 UPDATE 된 데이터를 바라보게 해줍니다.
하지만, 많은 UPDATE 작업이 동시 다발적으로 발생하는 경우 아래의 이슈가 발견 됩니다.
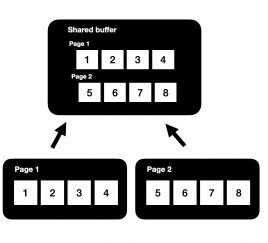
일반적으로 데이터를 읽는 상황에서 DBMS 는 Page 단위로 데이터를 읽어와 메모리에 올리게 됩니다. 하지만 많은 UPDATE 작업이 동시 다발적으로 실행 되는 경우, PostgreSQL 에서는 UPDATE 이전 데이터, UPDATE 이후의 데이터 가 같이 Page 내 저장 되기 때문에 데이터를 읽을 경우 쓸모 없는 공간을 차지할 수 있습니다.
UPDATE 이전의 데이터가 쌓일 수록, 실제로 사용되는 데이터를 읽기 위해 더 많은 Page를 읽어야 하고, 이는 더 많은 디스크 I/O가 발생 되어 성능 저하의 원인이 됩니다.
이렇게 UPDATE 이전의 데이터, 즉 더 이상 보지 않는 원본 데이터를 Dead Tuple 이라합니다.
PostgreSQL 에서 VACUUM의 주요 역할은 이런 Dead Tuple 을 정리하고, 실제로 읽어야하는 데이터를 매핑할 수 있는 Visibility Map을 갱신하여 Index Scan의 효율을 올려줄 수 있습니다. 또한, AutoVacuum 이란 PostgreSQL 내에서 특정 조건이 감지 되면은 자동으로 Vacuum 을 실행 시켜줍니다.
이번 튜닝의 목적은, AutoVacuum 을 기존보다 더 자주 실행 시켜주는 것으로 많은 UPDATE 가 있는 컬럼에 대한 Dead Tuple 을 정리하고 Index Scan의 효율을 높이고 싶었습니다.
AutoVacuum이 호출 되는 기본적인 조건은 *Dead Tuple 의 개수의 누적치가 임계치에 도달했을 때 입니다. 그리고 Dead Tuple의 누적치가 임계치에 도달하는 공식은 아래와 같습니다.
vacuum threshold = autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * number of Tuples
- autovacuum_vacuum_scale_factor : 테이블의 전체 Tuple 개수 중 설정한 비율 (기본 값 : 20%)
- autovacuum_vacuum_threshold : 테이블 내 변경된 Tuple 개수 (기본 값 : 50 rows)
AutoVacuum 파라미터 튜닝 을 위해서 저는 쿼리 지연 시간을 모니터링 하며, 가장 높았던 시간대에 살아 있는 Live Tuple 및 Dead Tuple 의 비율을 기록하고 임계치를 어떤 비율로 조정할 지 분석 했습니다.
최종적으로 아래의 비율로 조정을 하게 되었고, UPDATE 가 많은 테이블에 AutoVacuum 이 더 자주 실행 될 수 있도록 튜닝 되었습니다.
변경 전:
autovacuum_vacuum_threshold = 50
autovacuum_vacuum_scale_factor = 0.2
변경 후:
autovacuum_vacuum_threshold = 40
autovacuum_vacuum_scale_factor = 0.1
결과
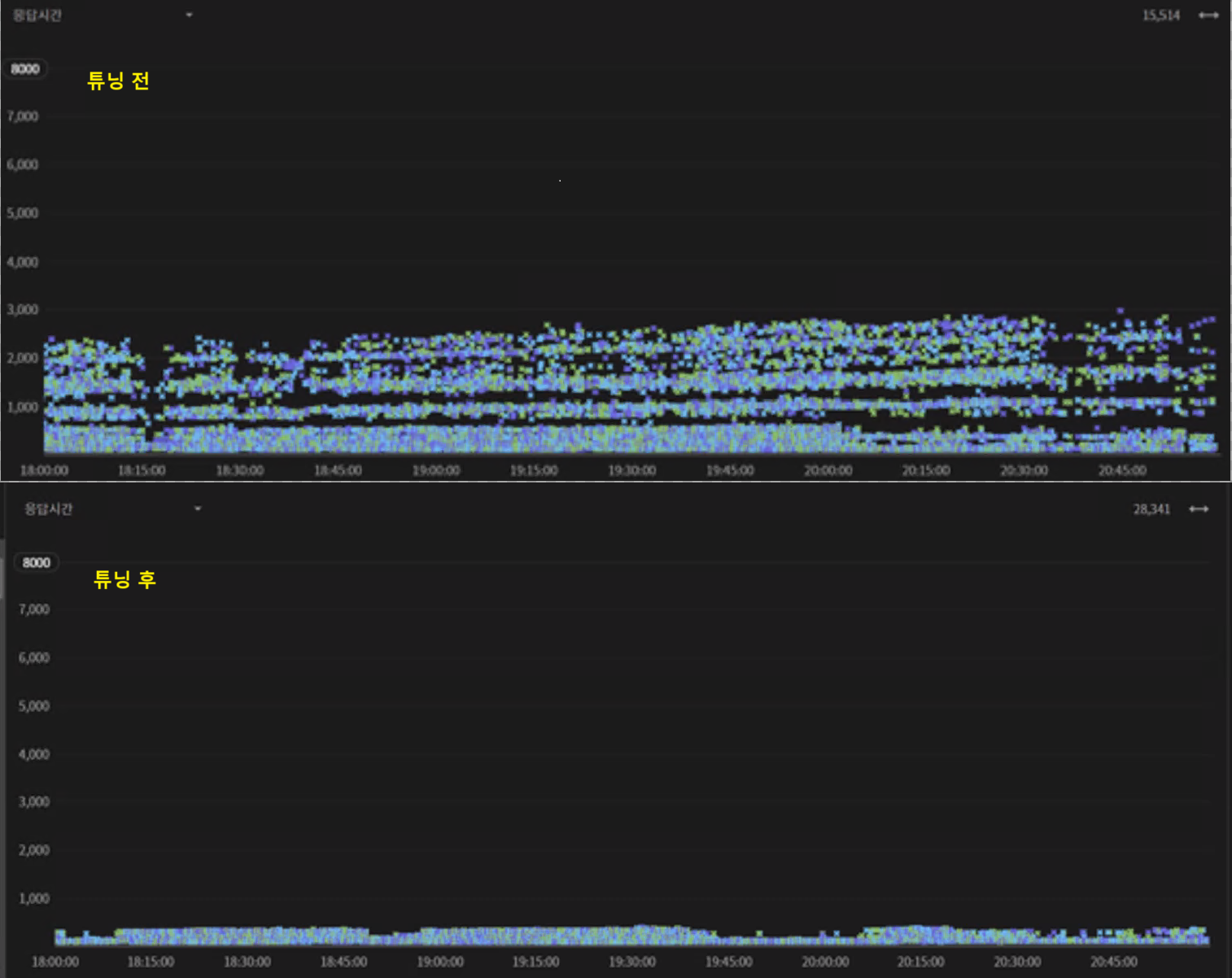
지연 시간 2.5초 -> 0.8초 개선
튜닝 전
| 날짜 | 시간 | 거래 건수 | 평균 (ms) |
|---|---|---|---|
| 04/10 | 18 ~ 21 | 37,677 | 2,500 ms |
튜닝 후
| 날짜 | 시간 | 거래 건수 | 평균 (ms) |
|---|---|---|---|
| 04/26 | 18 ~ 21 | 40,212 | 800 ms |
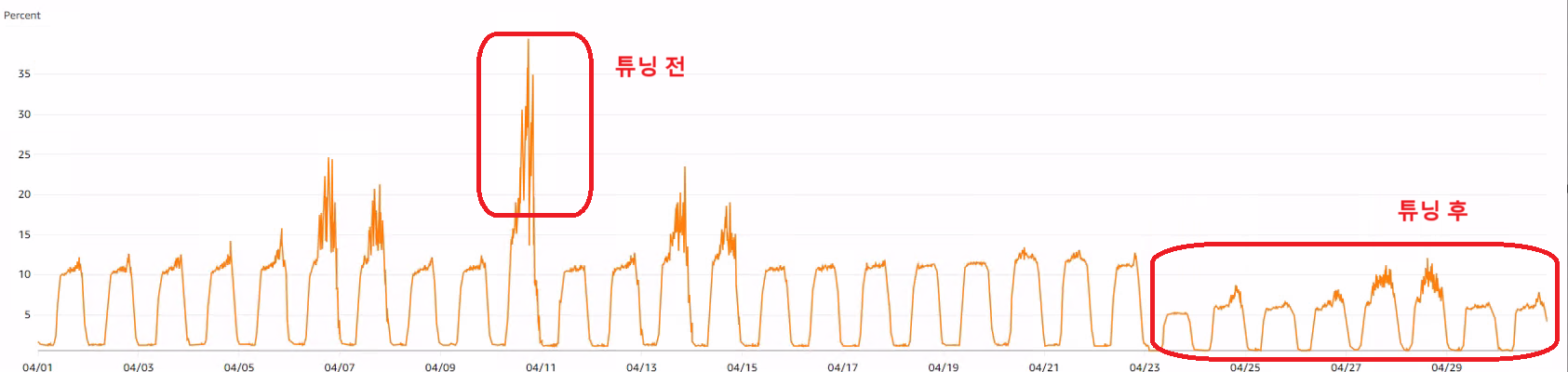
RDS CPU Utilization 45% -> 12%로 개선
튜닝 전
| 날짜 | 거래 건수 |
|---|---|
| 04/10 | 37,677 |
튜닝 후
| 날짜 | 거래 건수 |
|---|---|
| 04/24 | 41,820 |
| 04/25 | 27,242 |
| 04/26 | 40,212 |
| 04/27 | 75,314 |
| 04/28 | 66,408 |
느낀 점
처음으로 주도적으로 맡은 성능 개선 업무였습니다. MS-SQL을 주로 사용하는 팀내에서 PostgreSQL 관련 된 내용을 기술적으로 깊게 공부하고 실제로 성과도 낼 수 있었던 기회 였습니다.
"범죄 도시 4" 영화가 개봉 된 이후에도 CPU 사용량이 안정적인 범위 내 꾸준하게 유지 되었기 때문에 기존에 사용하던 RDS 스펙을 낮춤으로서 (m6g.2xlarge -> m6g.xlarge) 연 $8,600 의 비용을 감소를 할 수 있었습니다.
현재는 팀내에서 제가 배운 기술을 팀원들과 공유하며 기술적으로 더 성장하고 있습니다. 앞으로도 이런 성능 개선 과제를 주도적으로 맡아서 성장하고 싶다는 생각이 들었습니다.
출처
Index-only-scan
PostgreSQL - Table Scan
Visibility Map
PostgreSQL 에서의 MVCC
우아한 기술 블로그
