
기초: 단방향 매핑
테이블과 객체가 어떻게 서로 협력 관계를 맺는지에 대한 생각이 필요하다.
-
테이블은 외래 키 (FK) 로 다른 테이블에 기본키 (PK) 를 참고하여 테이블을 조인하고 연관된 테이블을 찾는다.
-
객체는 참조(Reference) 를 사용해서 연관된 객체를 찾는다.
우리가 JPA 를 사용하게 되면은 결국 객체를 JPA 인터페이스에 맡기고 개발자가 SQL을 번거롭게 작성하지 않아도 되는 큰 장점을 가지지만 객체 지향적인 프로그래밍을 위해 자바에서는 참조값을 필수로 가지게 된다.
JPA 를 쓰는 목적은 객체지향적인 프로그래밍을 관계형 데이터베이스에 종속받지 않고 사용하는 목적인 객체 설계를 관계형 데이터베이스를 중심적으로 풀면은 말이 안된다. 그렇기에 객체끼리 연관관계를 가질수 있게 만들어 줘야한다.
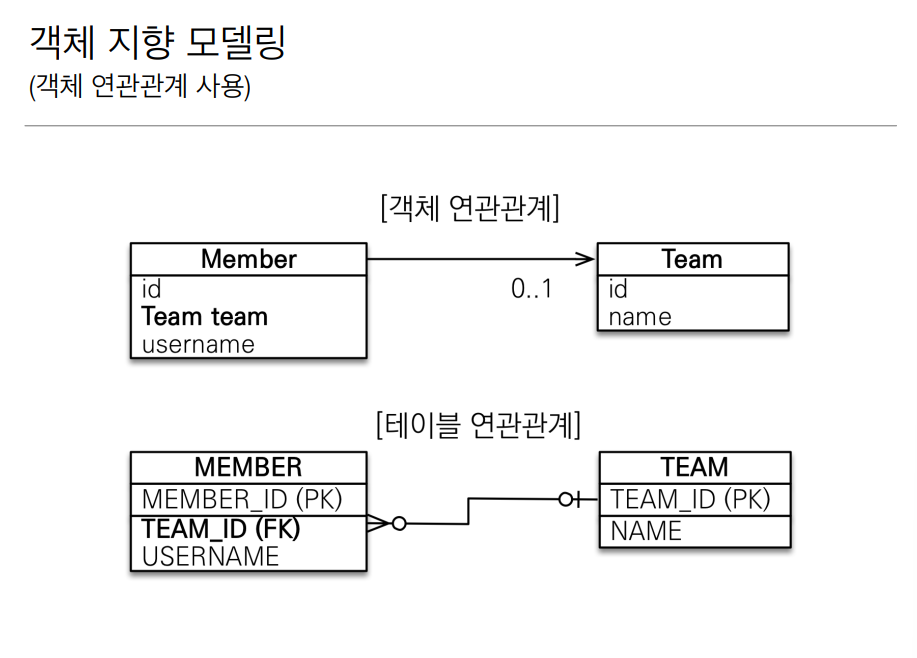
멤버 클래스안에는 팀 클래스를 넣을수 있고 멤버 테이블안에는 FK 를 이용해 팀 테이블과 조인할 수 있다. 이것을 객체 지향설계로 코드로 풀자면은 아래와 같다.
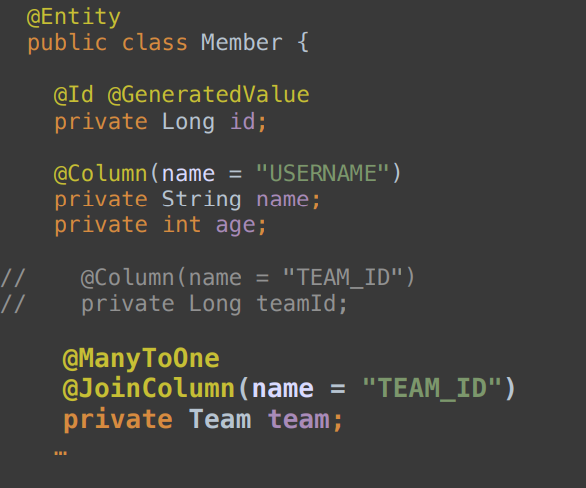
이렇게 TEAM_ID로 값을 저장하고 조회하는건 관계형 데이터베이스에 종속된 설계고 객체는 객체를 참고해야한다 그렇기 때문에 Team이란 참조 값을 멤버 클래스 안에 넣어주었고 이것을 RDBMS에서 연관관계를 JPA가 안전하게 맺어줄수 있도록 @JoinColumn(name = "Team_ID") 로 설정해줬다.
@JoinColumn은 그냥 말그대로 일반 SQL을 사용할때 JOIN ON {id} = {id} 와 비슷한 말인거 같다. @JoinColumn을 사용할때는 참조하고 싶은 객체의 PK 값을 찾아서 매핑 시켜주면 된다.
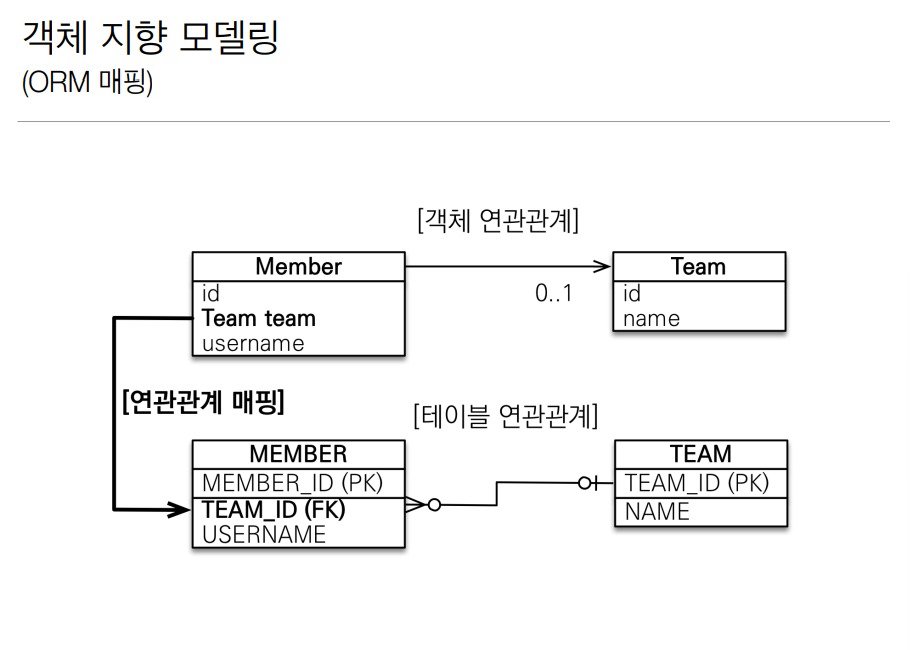
단방향 연관관계의 예다. 지금 멤버에서는 팀의 참조값을 포함시켰고 이것을 RDBMS에 적용시키기 위해서 Team 참조값 위에다가 @JOINCOLUMN 후 팀객체의 기본키를 넣어주었다. 결과는 위에 그림과 같게 만들어진다.

이로서 우리는 Setter을 통한 멤버의 팀 설정이 객체를 사용하듯이 가능해진다.

조회하는 과정도 객체스럽게 변했다. em.find() 로 멤버를 영속성 컨텍스트에서 가지고오고 해당 맴버의 팀또한 Getter 매서드를 통해서 얻는게 가능하다.
기초: 양방향 매핑
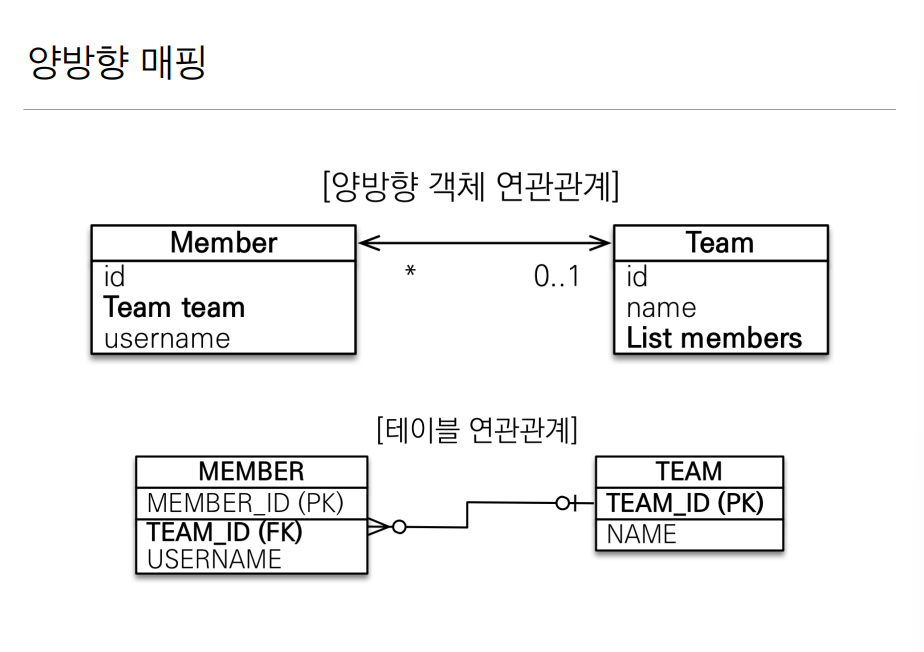
단방향 매핑에서는 오직 맴버만이 팀을 참조값으로 가지고 있었다. 그렇지만 이번에는 팀도 맴버를 참조값으로 가지고 싶다면 어떻게 될까? 이것을 양방향 매핑이라 한다.
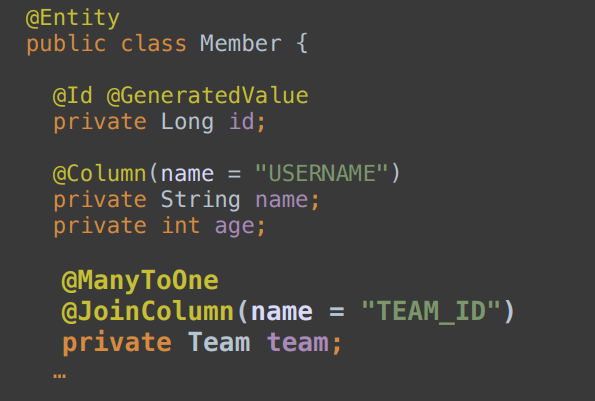
먼저 맴버가 팀의 참조값을 가지고 @JoinColumn 을 통해서 팀의 기본키를 받는 과정은 똑같다.

그렇지만 팀에서 멤버의 참조값을 가지고 싶을때는 연관관계 매핑과 함께 mappedBy = {value} 를 넣어줘야 한다. 이것을 우리는 키의 주인을 설정해준다고 하는데. 주인이 아닌쪽은 읽기만 가능하고 연관관계의 주인만이 외래 키를 관리 해야한다 (등록, 수정)
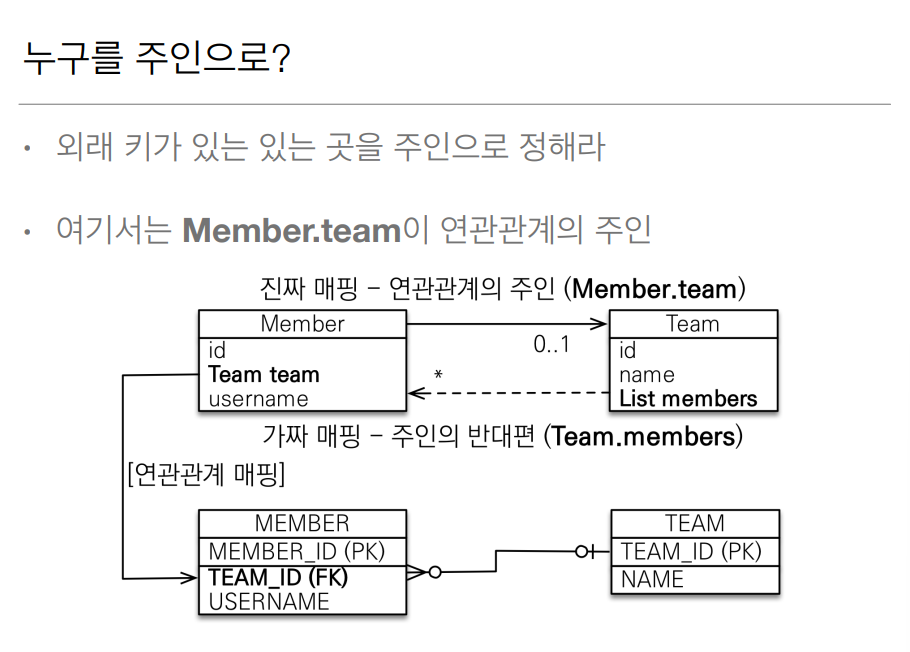
이렇게 @JoinColumn 을 사용해주었던 클래스를 외래 키가 있는곳이라고 하는데 주인으로 설정하게 되면 양방향 탐색이 가능하다.

보면은 팀 또한 멤버를 가지고 올 수 있게되있다. 연관관계 설정후에 mappedBy 를 쓸때는 주인 클래스에서 어떤 변수 이름을 사용했는지 보고 적어주도록 하자.
Member 클래스에서 Team team 으로 적었기 때문에 Team 클래스에서는 mappedBy = "team" 이라고 적어준게 예시다.

강의에서 주던 꿀팁은 이미 단방향 매핑만으로 연관관계 매핑은 완료 된것이기 때문에 정말로 양방향이 필요하다고 생각할때 연결해주라고 말하고있다.
기초: 연관관계 매핑
연관관계 매핑시 고려해야할 3가지가 있다.
-
다중성
-
단방향, 양방향
-
연관관계의 주인
우리는 앞서 작성했던 기초 단계를 통해 단방향 설정과 양방향 설정, 그리고 FK가 있는 클래스를 주인으로 담는 방법을 배웠지만 다중성에 관해서 지식이 좀 더 필요하다.

다중성을 요약한 어노테이션이다. JPA가 제공해주는 어노테이션이고 이 모든 어노테이션은 DB와 매핑하기 위해서 존재한다. 연관관계에 위와 같은 다중성을 넣어줄 수 있지만 사실 실무에서는 많이 쓰이는 어노테이션과 사용되면 안되는 어노테이션이 존재한다.
@ManyToOne
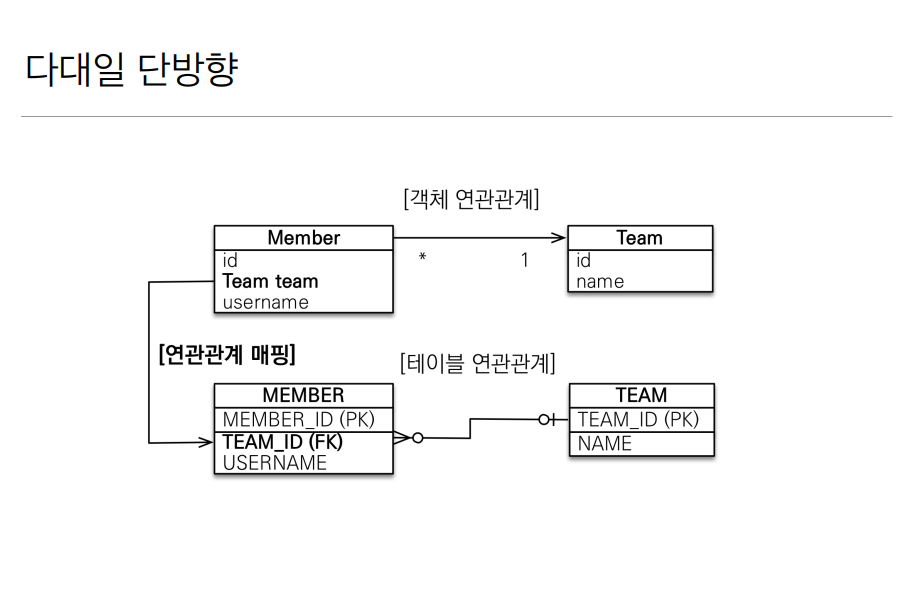
가장 많이 쓰이는 형태의 매핑이다. 단방향으로 했을때는 위와 같이 멤버 안에 있는 다(Many) 쪽이 외래키의 주인이 되고 @JoinColumn 을 통해서 Team의 아이디를 참고하면 된다.
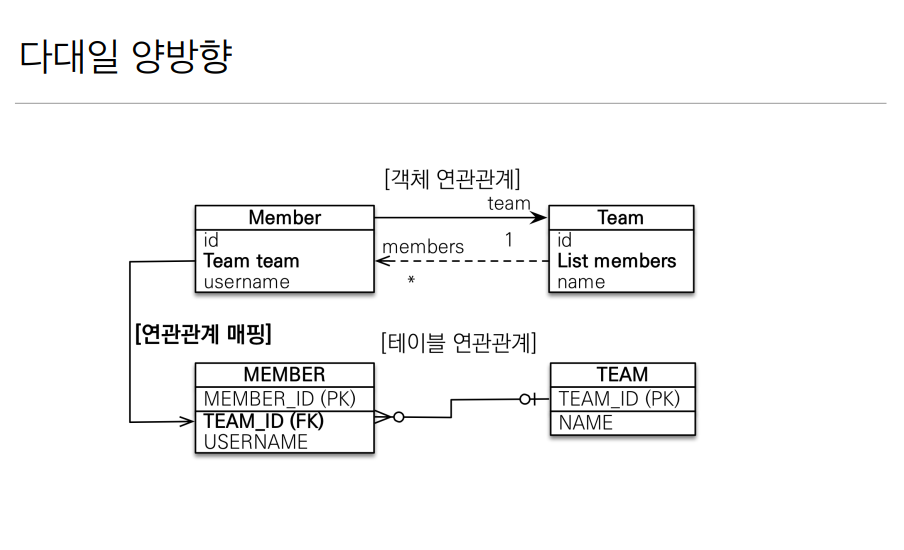
양방향의 경우도 간단하다. 멤버가 팀의 참조값을 가지고 있기때문에 다대일의 외래키 주인이면 팀 또한 멤버의 참조키를 가지고 반대인 일대다의 형태로 매핑 시켜주면 된다. mappedBy를 잊지말자!
@OneToMany
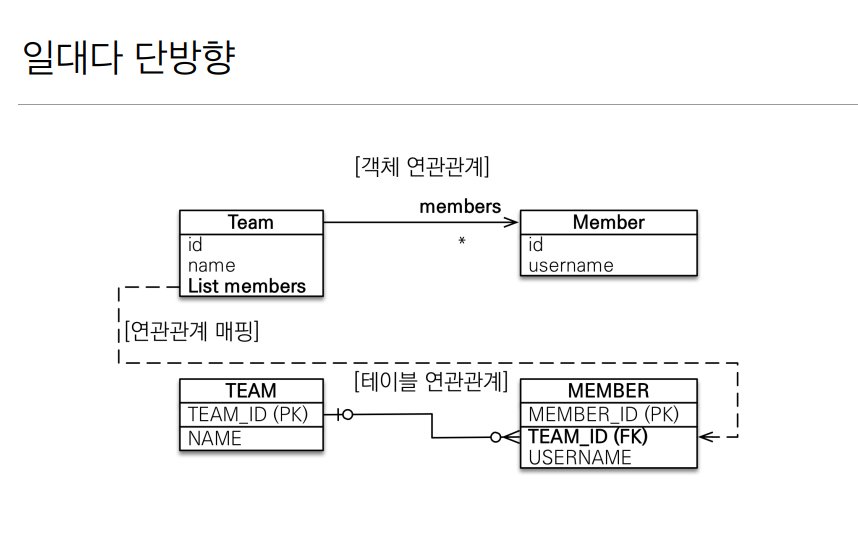
일대다의 관계이다. N:N 이든 1:N 이든 맨 처음에 나오는 숫자 or 알파벳이 연관관계의 주인이다. 이 경우에는 One to Many 이기때문에 팀이 연관관계의 주인을 가지게 되는 경우지만 위와 같은 설계는 매우 안좋다.
테이블 일대다 관계는 항상 다(Many)쪽에 외래키가 존지한다.
이런 이유때문에 객체가 가지고 있는 주인 클라스와 테이블이 가지게 되는 외래키의 주인이 다르고 혼동이 온다.

강의에서도 말하기를, OneToMany의 관계를 주인으로 만드려고 하기보다 다대일 관계에서 양방향 처리 를 해서 OneToMany 관계를 만드는게 테이블적으로도 유리한 설계다. 그게 설령 팀에서 멤버 객체를 참조할 일이 없어도 이런 설계가 더 유리하다.
@OneToOne
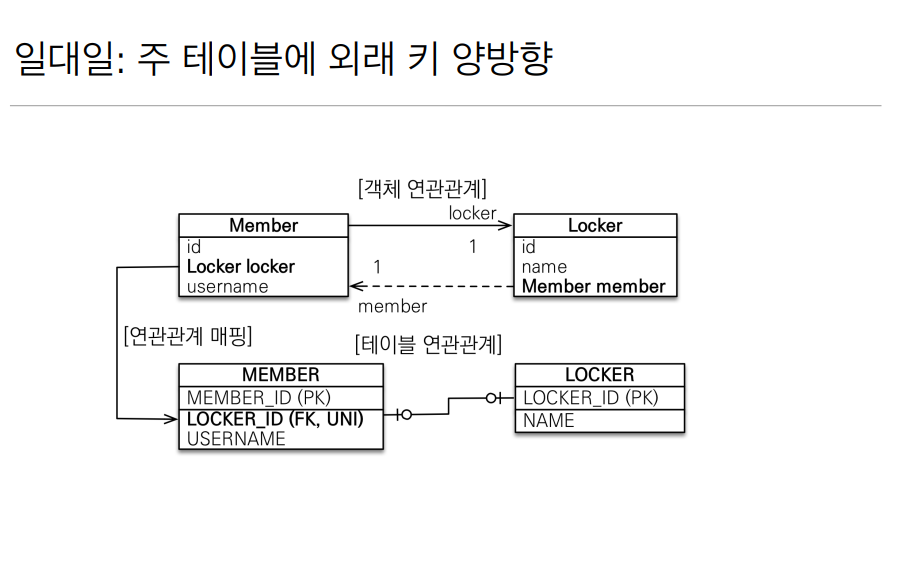
일대일(OneToOne) 은 다대일(ManyToOne) 설계와 비슷하다.
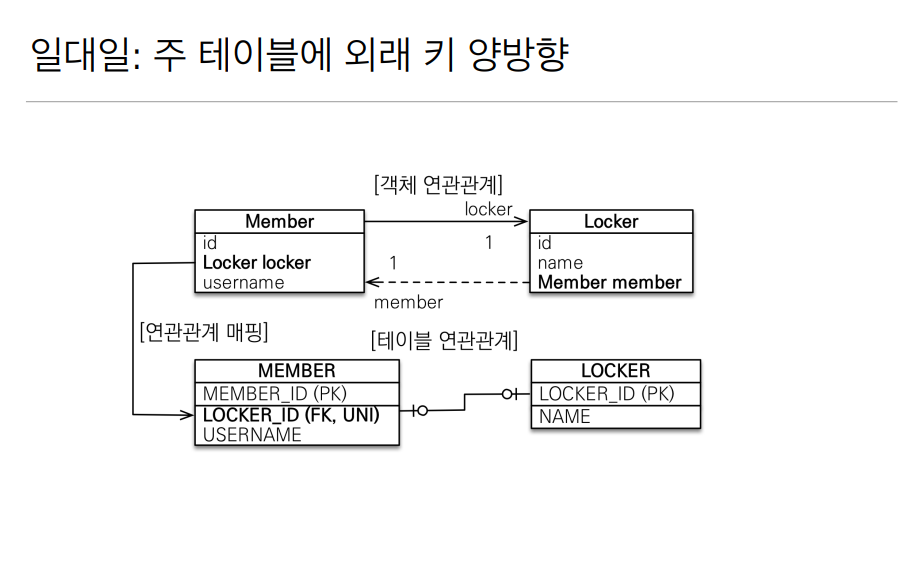
크게 설명할 부분이 없는게 일대일의 반대도 일대일임으로 양방향 관계는 위와 같이 해결할 수 있다. 다대일 관계를 만들었던거 처럼 주인이 되는곳에는 FK 가 있고 읽기만 가능한곳에는 mappedBy 를 꼭 넣어줘야한다.
강의에서는 여러가지 재밌는 설명이 많았지만 지금의 내가 들어도 잘 이해 안가는 부분들이 많았다. 그리고 결론으로는 아무리 일대일 관계의 주인은 양쪽 어디에 넣어도 상관이 없다 해도
주 객체가 대상 객체의 참조값을 가지고 있는것처럼 테이블 또한 주 테이블에 외래키를 둘 수 있는 설계를 하자!
@ManyToMany
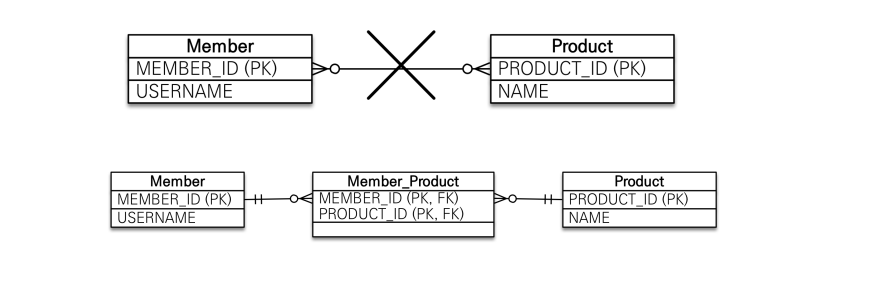
이번 JPA 기본 강의를 다시 정독하자 라고 마음 먹게된 계기이다. 회원과 상품 관계를 생각해봤는데 ManyToMany 기억이 났지만 실무에서 안좋은 방법이라고 얘기했던것도 생각이 나서 1회차때 잘 이해 못했던거를 이제서야 이해 했다.
위에 보이는 예시와 마찬가지로 관계형 데이터베이스 테이블은 다대다를 표현할때 테이블 두개로 표현할 수 없다. 그렇기 때문에 연결 테이블을 추가해서 일대다, 다대일로 풀어내야한다.
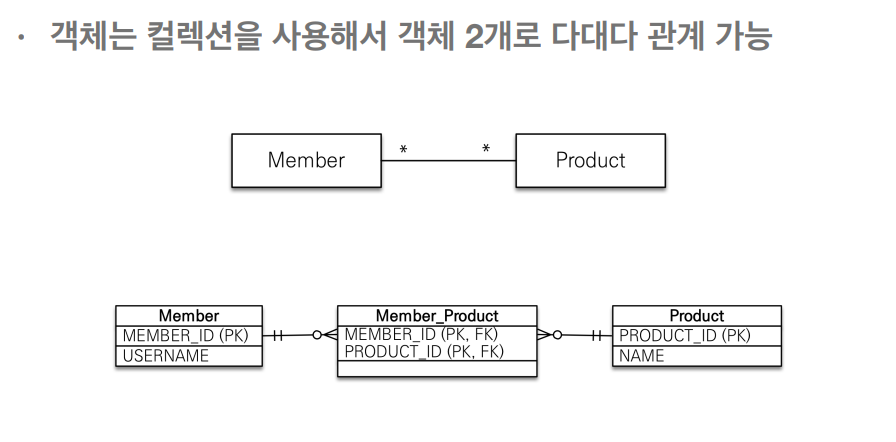
그렇지만 객체의 시점에서는 양방향의 참조값으로 List를 포함한다면 사실 다대다가 성립 가능하지만 테이블에서는 하나의 테이블을 한번 더 만들어야 완성이 된다.

다대다 또한 단방향, 양방향이 가능하지만 테이블을 하나 더 조인해야 한다는 특징 때문에 PK를 주던 JoinColumn 과 다르게 JoinTable로 다른 테이블과 합치게 된다.
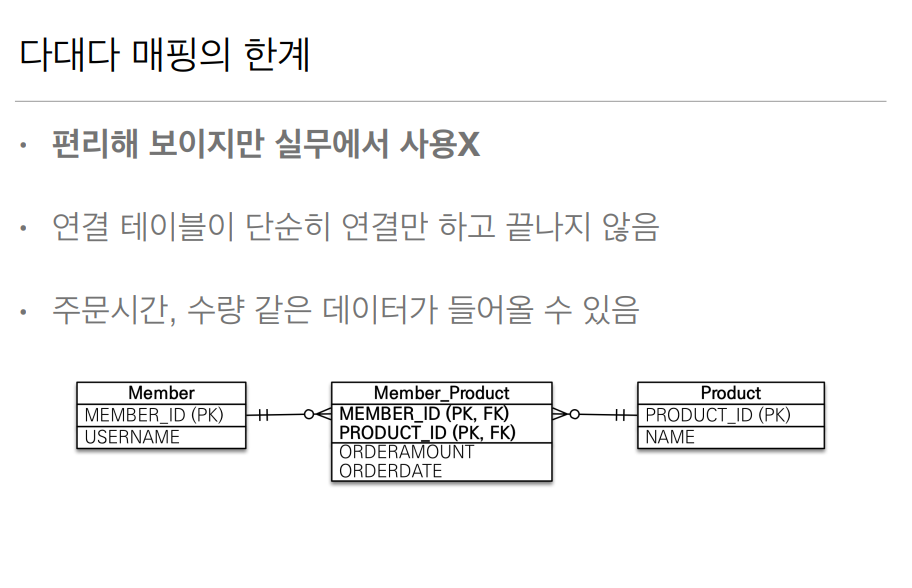
이 방법에는 다만 한계가 있다, 매니 투 매니로 만들어진 테이블은 단순한 연결용 으로 사용되지 추가적인 데이터를 많이 넣어야하는 실무적인 환경에서 적합하지 않다.
위에 그림에서는 Member_Product가 양쪽 멤버와 프로덕트 테이블을 연결해주는 역활을 하고 있지만 주문시간, 주문수량 같은 부가적인 데이터를 추가 못한다는 단점이 있다.
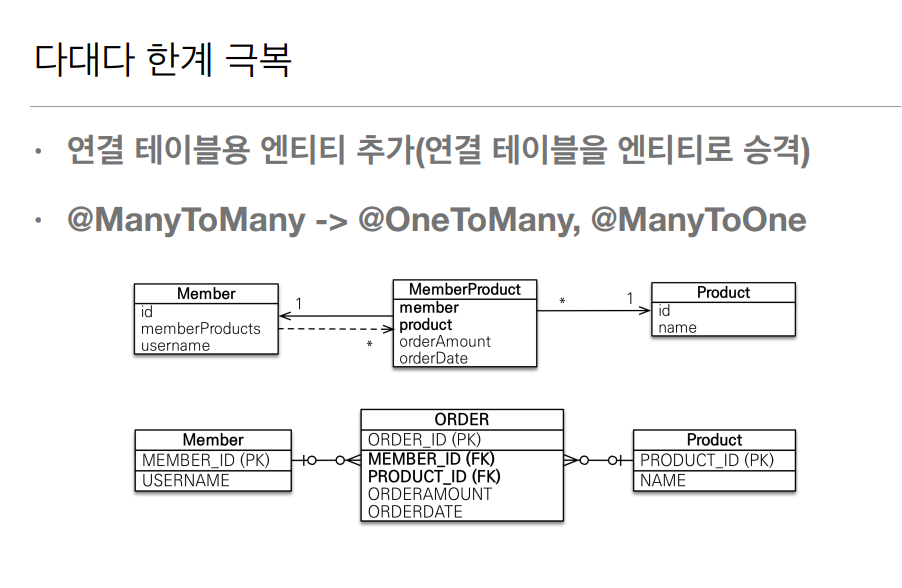
이것을 해결하는 방법은 추가적인 @Entity를 JPA가 관리하게 만들어 주고 Member에서 일대다, 다대일의 양방향 관계 생성, 다대일,일대다 양방향으로 Product와 연결 해준다면 결과적으로 우리가 목표했던 RDBMS에서 다대다 관계가 완성될 수 있다.
정말로 이해 못했었던 내용이었는데 CS 지식 공부로 DB를 더 깊이 있게 배우고 스프링과 관련된 지식이 늘다보니 한번에 이해가 가능했다.
고급: 상속관계 매핑
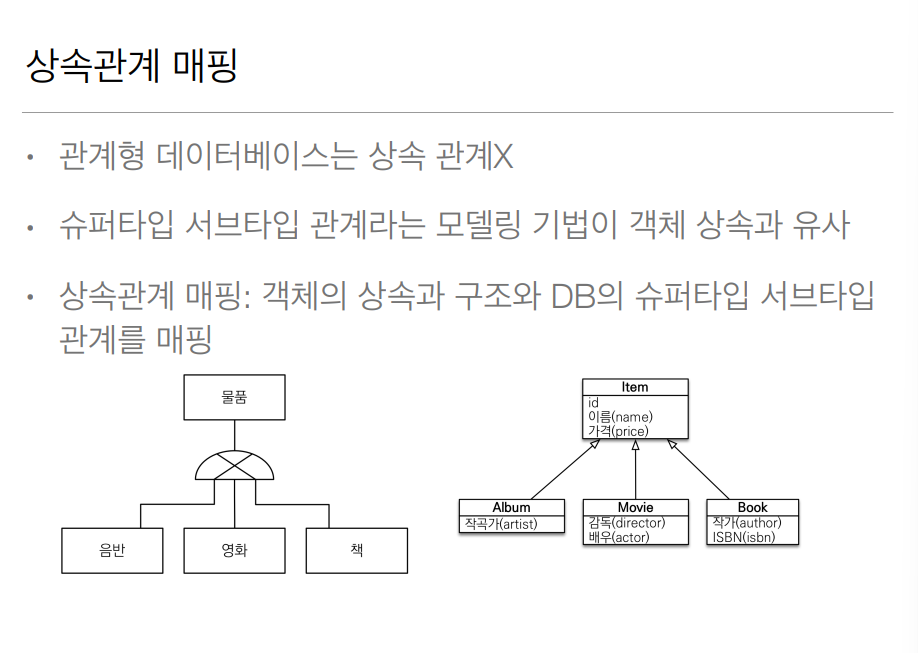
자바에서 상속관계를 만들때 클래스 안에 abstract를 사용해서 추상화 클래스로 만드는 방법이 있다. 그리고 이런 추상 클래스를 다른 자식 클래스가 상속을 해서 부모의 매서드나 변소를 공유 받을 수 있다는 장점이 있는데 RDBMS에도 비슷한게 존재하고 슈퍼타입 서브타입 관계라는 모델링이 있다.

상속관계 매핑에는 위와 같은 세가지 전략이 있고 가장 많이 쓰이는 전략, 상황에 맞게 사용하는 전략, 그리고 아예 사용하지 말아야하는 전략이 존재한다.
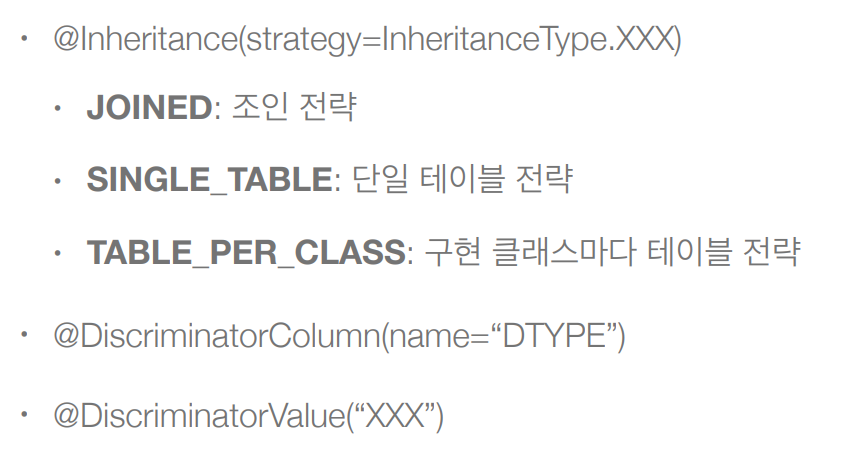
상속관계 매핑을 할때 사용해야 하는 어노테이션이다. @Inheritance 를 사용하고 안에 타입을 지정해주는 것이 전략을 선택해주는 것이고 밑에 @DiscrinatorColumn 같은 경우는 테이블을 구분해줄 수 있게 도와주는 타입이라고 보면 된다.
고급: 조인 전략
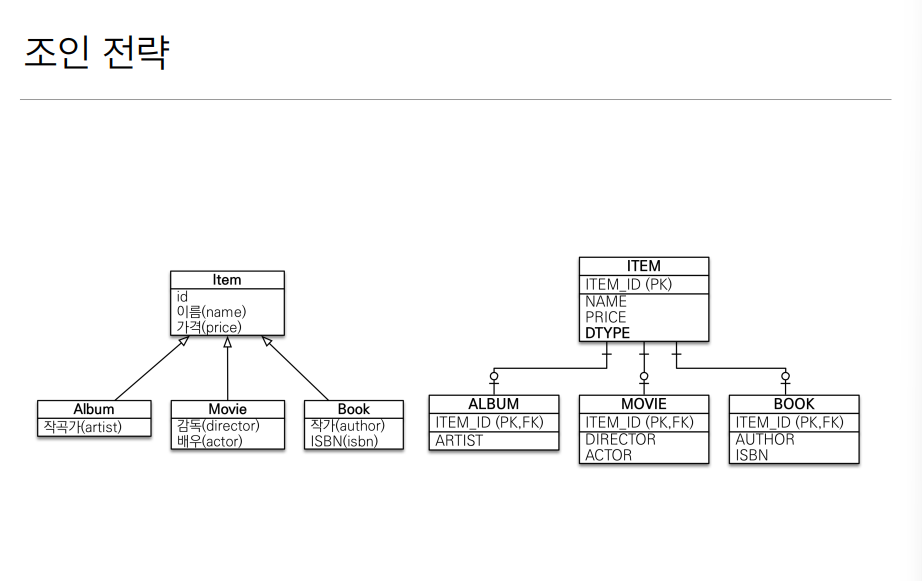
자바 객체를 사용하면서 만드는 상속관계와 가장 구조가 비슷하게 만들 수 있다. 아이템 테이블이 상위 클래스이고 아래에 앨범, 영화, 책이 하위 테이블로 나뉘어지게 되는데 전부 테이블을 조인하는 전략이라서 아이템에 있는 변수들을 다른 테이블에서 모두 공유 가능하다.

장점과 단점이다, 테이블 정규화란 한 테이블이 모든 정보를 가지고 있는게 아닌 여러 테이블로 분산되어 있다는 뜻이다. 데이터베이스 정규화를 알게되면서 이해 가능했다.
외래 키 참조 가능이란 조인으로 인해 외래키를 사용하고 있음으로 제약 조건이 필요해 아이템에서 걸어주게 되면은 자연스럽게 하위 테이블도 따라가게 될것이다.
단점으로 조인을 많이 사용하고 INSERT 쿼리를 두번씩 넣어주는 트레이드가 있지만, 강의에서 말하기를 실제로 성능에 저하를 줄 정도는 아니라고 한다.
고급: 단일 테이블 전략
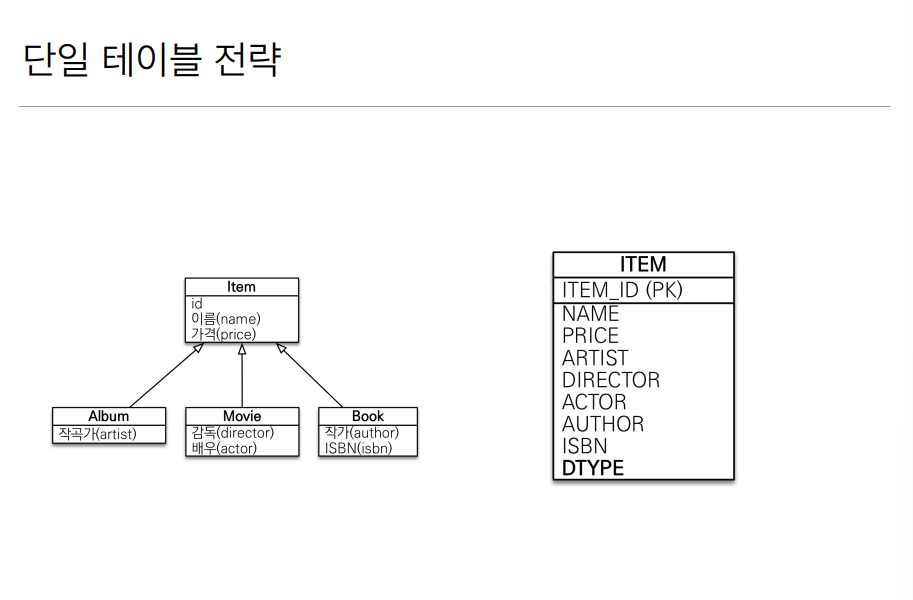
단일 테이블 전략은 상속같은 느낌보다는 그냥 한 테이블안에 모든 정보를 떄려넣는것이다. 즉, 아이템 클래스 안에는 앨범이 가지고 있는정보, 영화가 가지고 있는 정보 등등이 전부 포함되고 있다.

장점으로는 일단 조인이 필요 없기 때문에 그만큼 성능이 빠르고 조회 쿼리가 복잡하지 않고 단순하다.
단점으로는 자식 엔티티가 매핑한 컬럼이 모두 null로 허용된다고 하는데, 이 말은 만약 앨범에 대한 정보를 넣게 되면 나머지 영화, 책의 컬럼들은 null로 쓸데 없이 넣어진다는것이다.
꽤 뻔한 단점이지만 단일 테이블 전략은 테이블 컬럼이 무수히 많아질 수 있고 조회 성능이 상황에 따라 낮아질 수 있다고 한다.
고급: 구현 클래스마다 테이블 전략
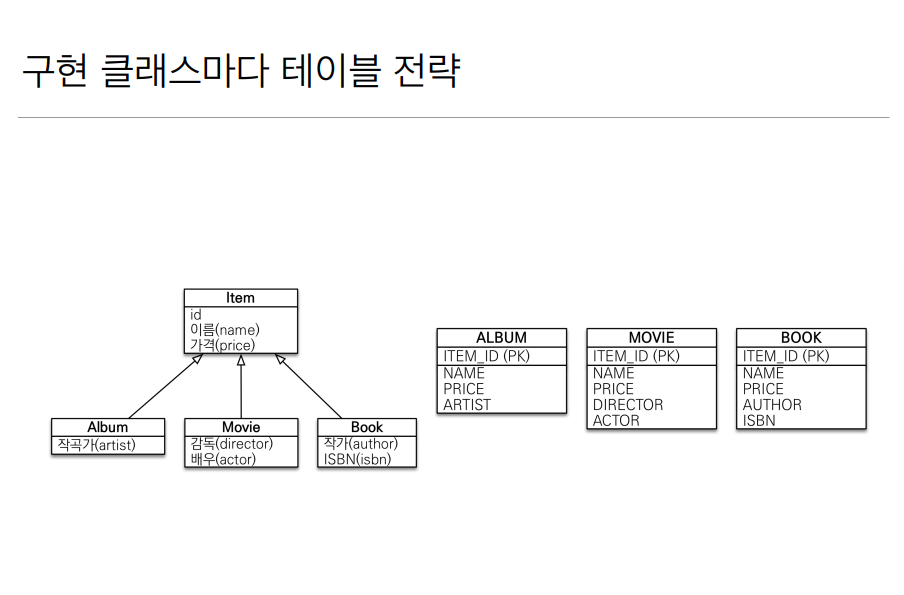
이번에는 조인도 아니고, 한 테이블에 다 넣는것도 아니고 정말 각 클래스 마다 아이템에 요소와 특정 테이블에 요소를 담은 테이블을 하나씩 생성해주는 것이다.

어떻게든 장점과 단점을 작성하긴 했지만 사실 이 전략은 안쓰는게 맞다고만 생각하면 좋을거 같다.
@MappedSuperclass
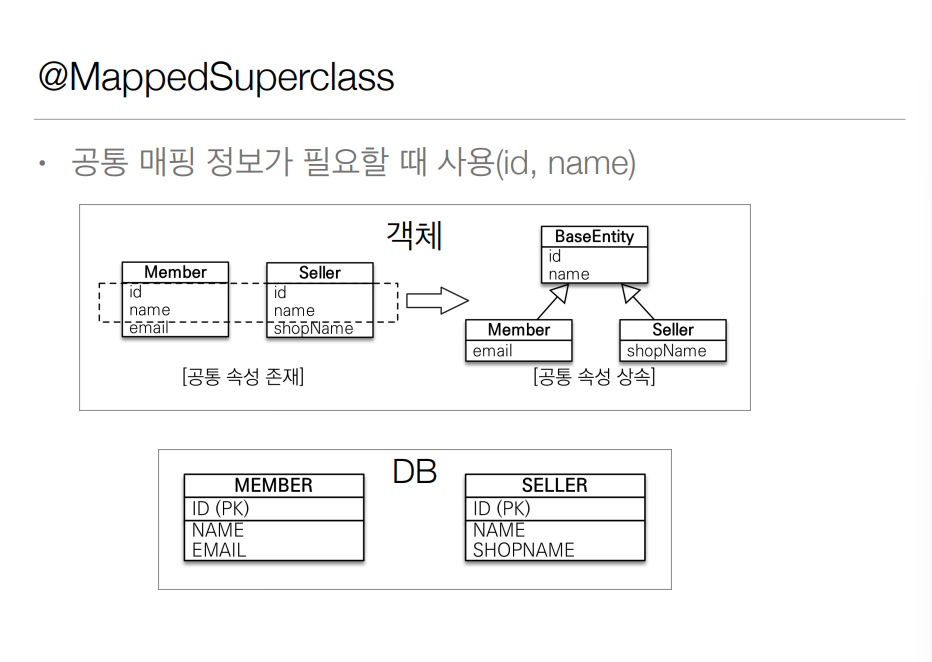
1회차 강의때는 아예 이해 못해서 넘어간 강의 같은데 만약 공통적으로 사용되는 매핑 정보가 있을때는 @MappedSuperclass 라는 어노테이션을 사용할 수 있다.
위와 같은 예시에서는 id와 name은 모두 공통적으로 들어가는 매핑 정보이다. 그런데 각 클래스마다 공통 매핑 정보를 전부 적게 되는것은 상당히 귀찮은 일이다. 그렇기 때문에 BaseEntity 라는 클래스를 정의해주고 거기에 들어가는 매핑 정보를 채워준 뒤에 @MappedSuperclass를 붙혀준다.
이후에는 엔티티로 사용될 다른 클래스를 만들때 BaseEntity를 상속 받음으로서 공통 매핑 정보를 손쉽게 받을 수 있다.

결국에 @MappedSuperclass 는 공통된 매핑 정보만 주는 역활을 수행함으로서 추상화 (abstract) 클래스로 만들어주는게 맞다. 엔티티로 등록이 안되기 때문에 JPA를 통해서 관리가 안됨으로 조회, 검색이 불가하다.
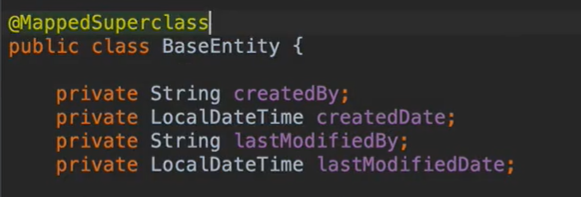
이런식으로 등록일, 수정일, 등록자, 수정자를 공통 로직으로 @MappedSuperclass 처리 가능하다.
결론
아직 다시 보고 정리해야할 강의가 많이 남아 있지만 1회차 2회차...이렇게 늘어날 수록 이해하는 폭이 달라지는거 같다. 상속 클래스를 RDBMS에 사용할때 선택되는 전략이 다르다고 언급했는데 일단 조인 테이블 전략을 가장 기본으로 가지고 오고 확장성이 없고 정말 간단한 상속 관계는 싱글 테이블 전략을 사용해도 괜찮다.
