

스프링과 더불어 JPA 강의를 사용하는 실전 프로젝트를 끝냈다. 야생형 커리큘럼이라 해서 실전을 먼저하고 기본편으로 내가 이해하지 못했던 부분들을 하나씩 채워나갔다. 원래는 나만의 글 정리를 강의를 보면서 적고 그랬는데 이번 강의는 미리 한번 정독을 하고 두번씩 다시 보면서 적게 되는 글이다. 그렇기 때문에 빠른 시일안에 끝낼거고, JPA 기본 강의를 다 적고 나면은 바로 JPA 2편으로 넘어가 API 를 사용하고 최적화 하는 실습으로 공부를 할 계획이다.
JPA
JPA
JPA 소개에 앞서가지고 JPA 의 약자는 Java Persistence API 로 객체 지향형 프로그래밍을 위한 데이터 베이스로 보는게 맞다. 나는 지금까지 SQL 등을 사용하면서 DB를 유지했는데 현실적으로 객체 (Object) 를 위주로 개발을 하는 요즘 시대에 일반적인 RDB (Relational Database) 만을 사용하며 유지보수를 하기에는 제한이 굉장히 많다.

객체 지향적 DB 를 사용하는것은 많은 이점이 있는데 가장 간단하게 얘기해서 위에같은 장점들이 있다. 객체는 서로 상속 관계가 있고 연관관계가 있고, 데이터 타입이 존재한다.
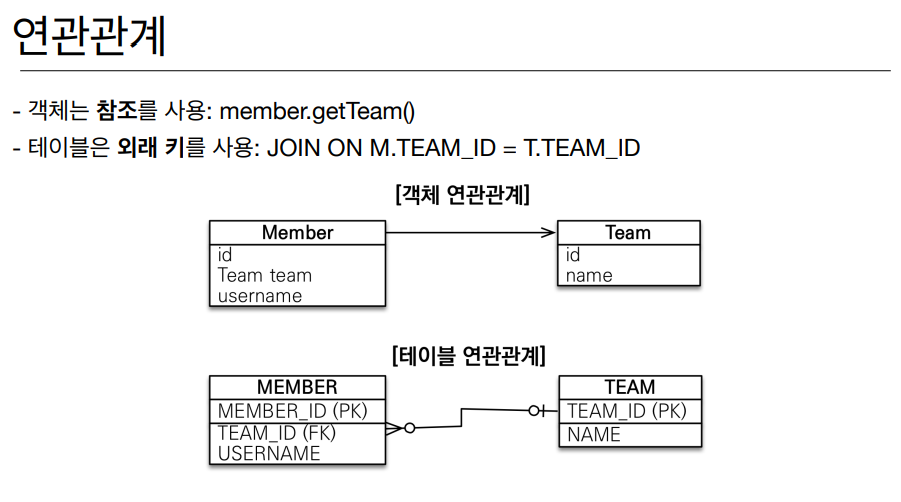
그런데 RDB 로만 이 모든것을 유지할려고 하면 기본적으로 손이 너무 많이 간다. 객체 모델링 요구사항이 바뀌거나 관계가 바뀌게 되면 RDB 에서는 그만큼 많은 SELECT 문구를 날려줘야 하고 테이블 자체가 복잡해진다. 그러나 객체 지향적 DB 를 사용하게 되면은 객체 요구사항이 바뀌거나 어떤 추가사항이 있어도 객체 자체를 바꾼것만으로 DB에 자동으로 저장이 되고 개발 환경이 훨씬 더 편해지는데 이때 소개됐던게 JPA 이다.

JPA 자바 진형의 ORM 기술 표준이라고도 하는데 위에 설명과 같다. 개인적으로 JPA 구조를 제대로 알게되면서 많이 신기했고 강의에서는 정말 다양한 이점들을 소개 했지만 내가 느꼈기에 제일 흥미롭다고 생각했던 부분만 짧게 적겠다.
JPA 동작 - 저장, 조회
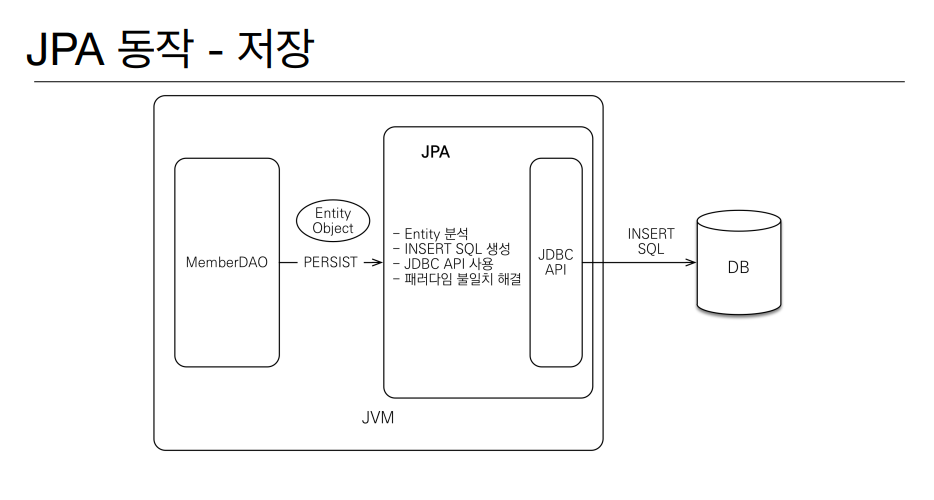
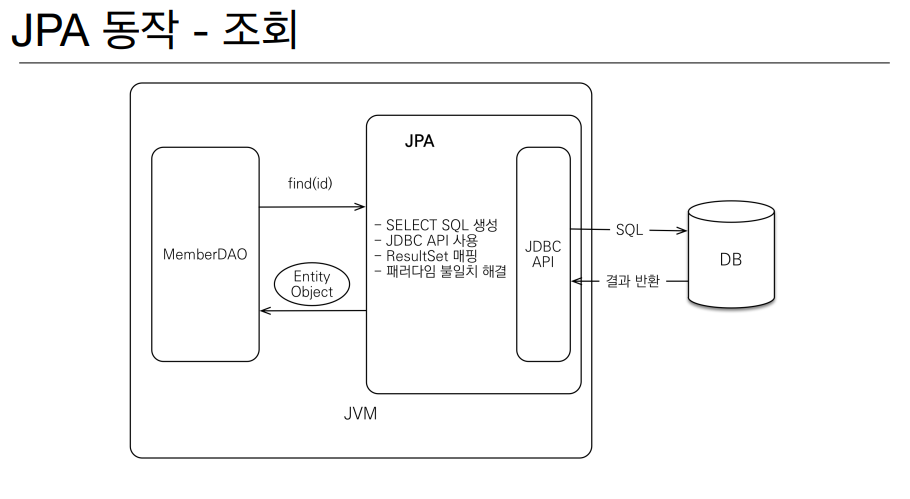
항상 궁금했던 부분 중 하나였는데 JPA 는 동작할때 위와 같은 원리로 작동한다. 뭔가 마법처럼 이루어지는 것은 아니고 JPA 에서 JDBC API 를 사용하면서 DB 를 조회하고 EntityManger 을 사용해서 저장은 Persist, 조회는 find(id) 를 날려줄 수 있다. Entity 자체를 분석해주고 저장에서는 INSERT SQL 을 날려주며 조회에서는 SELECT SQL 을 생성해준다는것이 많이 신기했다.

위에는 살짝 요약본이라고 볼 수 있다. 저장과 요약까지는 저런 method 를 쓸 수 있겠구나 하고 이해를 대충 할 수 있지만 수정 (update) 같은 경우 그냥 스프링에 @SETTER 만을 사용한것을 볼 수 있는데 이것은 1차 캐쉬와 연관이 되어있고 자세한 내용은 나중에 강의를 더 요약하면서 적을 것이다.
그 외에도, 지연로딩, 즉시로딩 등 JPA를 최적화 하는 기능은 많지만 나도 강의를 다시 들으면서 차차 작성할 예정이다.
결론

결론적으로 JPA 를 사용해야 하는 이유를 함축했다. 스프링을 사용하면서 필수로 알아야 할거같고 미래에도 많이 쓰일거같아서 최대한 많이 알아가보고 싶다.
