ElasticSearch 필수 지식
Lucene 이란?
어떤 공부를 해도 기본기는 필수다. Elastic Search 를 직접 알아보기 전에 Lucene 개념을 우선 알아야 하는 이유는 Lucene 은 Elastic Search 의 실질적인 코어라고 볼 수 있기 때문이다.
Lucene 이란? Java로 구성된 검색 엔진 라이브러리로, 택스트 기반 데이터의 색인 생성와 검색을 위한 도구를 제공한다. 그렇지만 Lucene 그 자체로는 검색엔진 어플리케이션이 될 수는 없고, 오로지 라이브러리의 역할을 수행한다. 그렇기 때문이 ElasticSearch 는 이런 Lucene 을 코어 라이브러리로 사용하는 검색엔진, 즉 어플리케이션 그 자체의 역할을 수행한다고 생각하면 된다.
Lucene의 핵심 개념과 구조
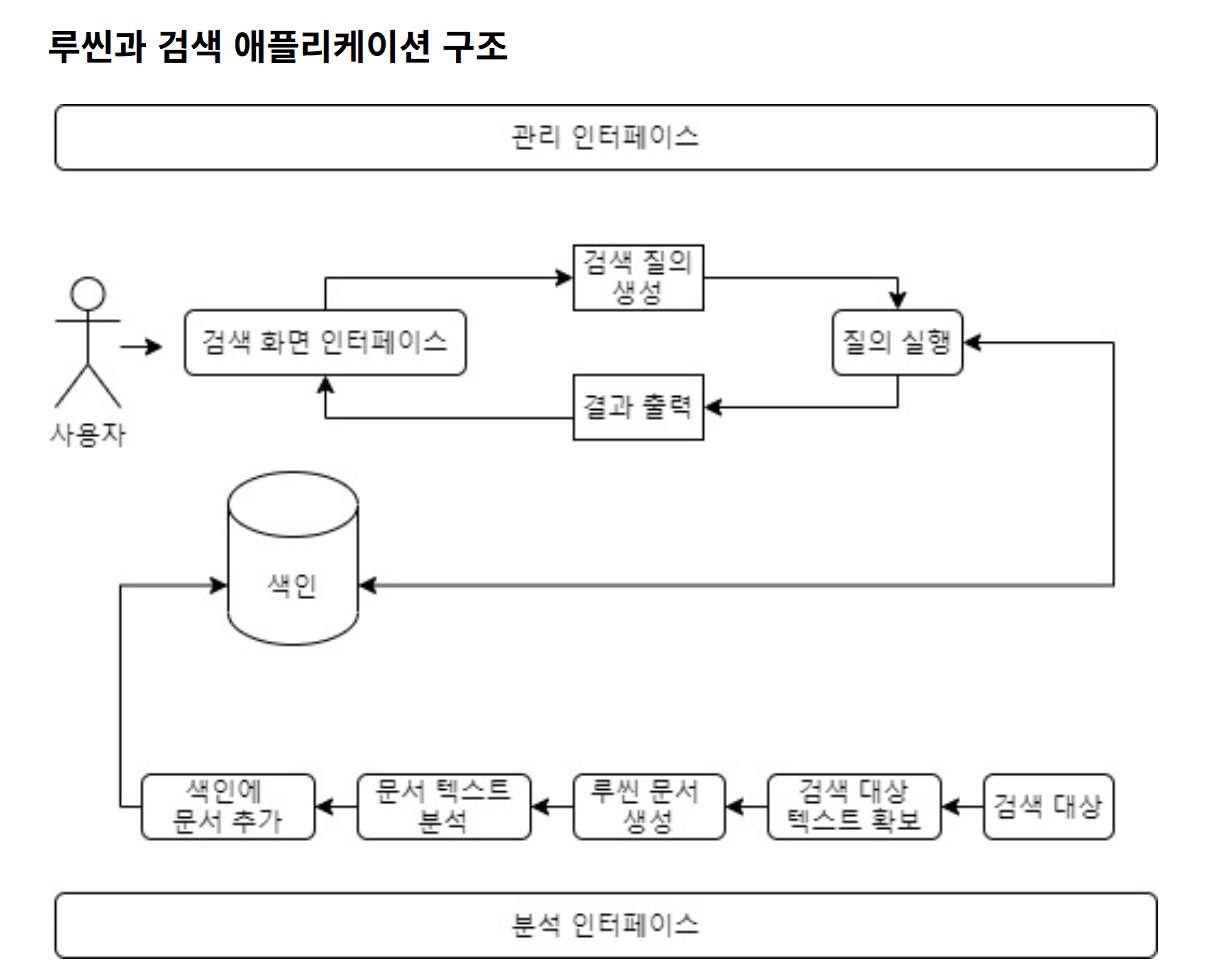
루씬과 관련된 내용을 학습하려고 검색하면 위와 같은 이미지가 나오게 되는데, 이 부분은 루씬이라는 라이브러리가 검색 대상을 분석하는 과정, 그리고 실제 사용자가 검색을 하는 과정으로 분리가 된다.
검색 대상 분석
- 검색 대상 텍스트 확보
- 루씬 내부적으로 수집에 대한 기능은 없다. 누군가 대상을 수집해서 전달해줌으로서 검색 대상 텍스트를 확보한다.
- 루씬 문서 생성
- 검색할 대상의 원본을 확보한 후, 원본을 루씬이 이해할 수 있는 구조인 Document 객체로 변환 후 텍스트를 필드 (Field) 단위로 분리하여 저장한다.
Document doc = new Document();
doc.add(new TextField("title", "Elasticsearch와 Lucene", Field.Store.YES));
doc.add(new TextField("content", "Elasticsearch는 Lucene 기반의 검색 엔진입니다.", Field.Store.YES));이 과정에서 title 이랑 content 라는 필드로 나누어서 저장을 했다.
- 문서 텍스트 분석
- 원본 문서에서 루씬 문서를 만들고 나면, 텍스트를 토큰이라고 부르는 단위로 자른다. 루씬 내에 여러개의 텍스트 분석기가 내장되어 있고, 필요에 따라서 직접 만들어서 사용이 가능하다.
원본 텍스트: "Elasticsearch는 Lucene 기반입니다."
분석 결과: ["Elasticsearch", "Lucene", "기반"]- 색인에 문서 추가
-> 토큰화된 단어들을 역색인 구조로 저장한다. 역색인은 각 단어와 해당 단어가 포함된 문서 ID를 매핑한다.
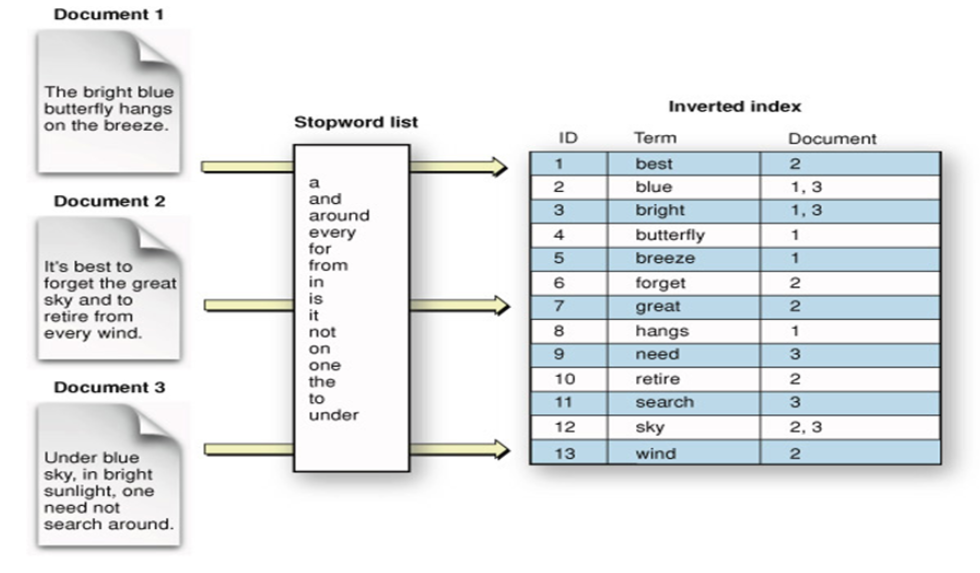
역색인이란?
역색인 (inverted index) 를 배우는 과정에서, 일반적인 DBMS 의 index 에 더 익숙해져있어서 너무 헷갈린 개념이었다. 그렇지만, 역색인이라는 개념이 있기 때문에 Elastic Search 가 빠른 속도를 가질 수 있는 것이다.

일반적인 index 의 개념은 데이터를 "컬럼" 을 기준으로 순차적으로 정리해서 "위치"를 기록한다. 책에 맨 앞에 있는 목차와 같다.
역색인은 이와 달리 "단어" 를 중심으로 각 단어가 등장하는 위치를 반대로 연결한다. 그렇기 때문에 특정 단어가 포함된 문서 목록을 빠르게 찾고 검색에 특화되어있다.
일반적인 색인:
- 데이터를 순차적으로 정리하여 위치를 기록한다.
- 예시:
- 문서 1 : "검색", "강력한", "엔진"
- 문서 2 : "검색", "최적화"
역색인 :
- 단어를 중심으로 해당 단어가 포함된 문서 목록을 저장한다.
- 예시:
- "검색" -> [문서1,문서2]
- "강력한" -> [문서1]
ElasticSearch 란?
앞서 Lucene 이라는 라이브러리에 대해서 설명을 간단하게 하였다.
Lucene 자체는 검색에 핵심적인 기능을 제공하는 라이브러리지만 Lucene 하나만으로는 검색 어플리케이션이 될 수는 없다. 실제 어플리케이션으로 사용되는 Elastic Search 란 루씬을 기반으로 방대한 양의 데이터를 신속하게 검색할 수 있는 분석 엔진이다.
ES는 NRT 검색 플랫폼이라는 특징 또한 가지고 있다. Near Real Time 의 약자로 문서 색인화 -> 검색 가능 시점까지 대기 시간이 대략 1초로 있어 실시간은 아니어도 매우 빠른 속도로 색인된 데이터의 검색, 집계가 가능하다.
Elastic Search 의 특징
-
Scale Out -> 샤드를 통해 규모가 수평적으로 늘어날 수 있다.
-
고가용성 -> Replica 샤드를 통해 데이터의 안정성을 보장
-
Schema Free -> Json 문서를 통해 데이터 검색을 수행하고 스키마 개념이 없다.
-
Restful -> 데이터 CRUD 작업은 HTTP Restful API 를 통해서 가능
Elastic Search 와 용어
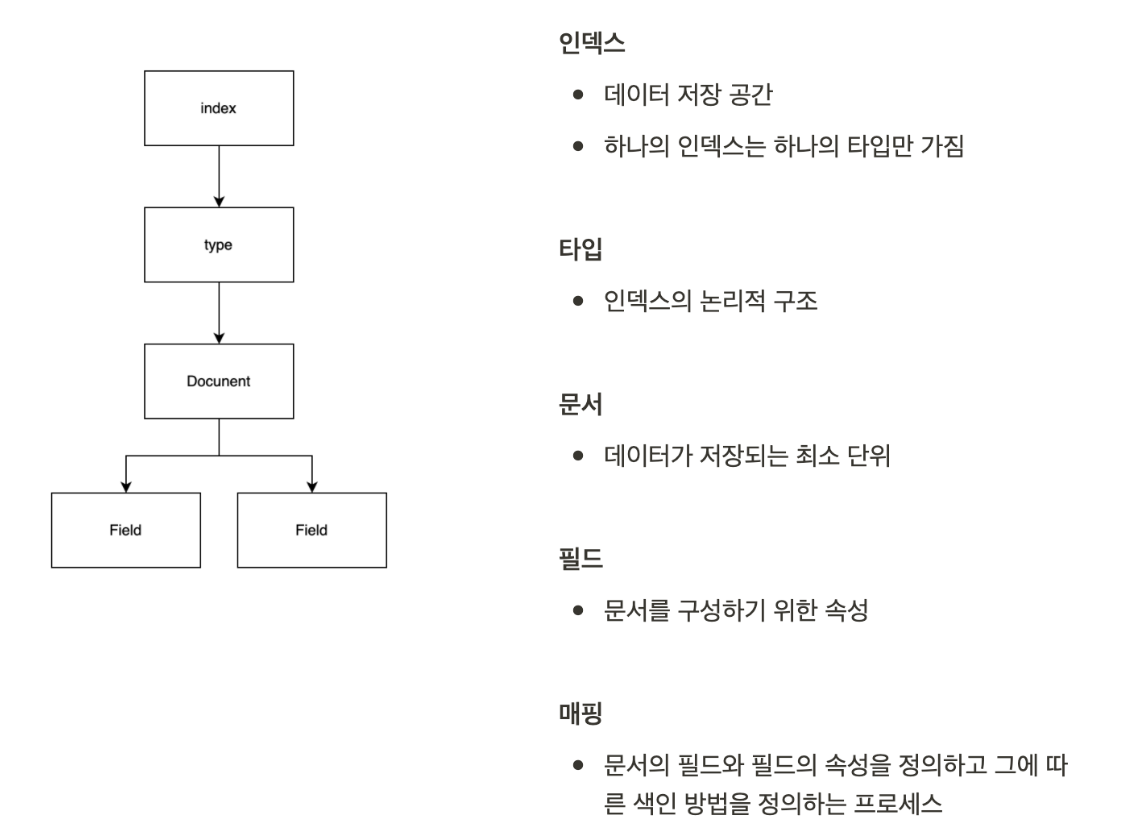
처음 ES 를 배워보면서 정말 이해하기 힘들었던 구조인데 그래도 계속 보다보니 조금 이해가 되고있다.
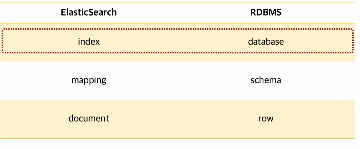
일단 위에 개념은 필수고 여기에서 샤드라는 개념도 꼭 알 필요가 있다.
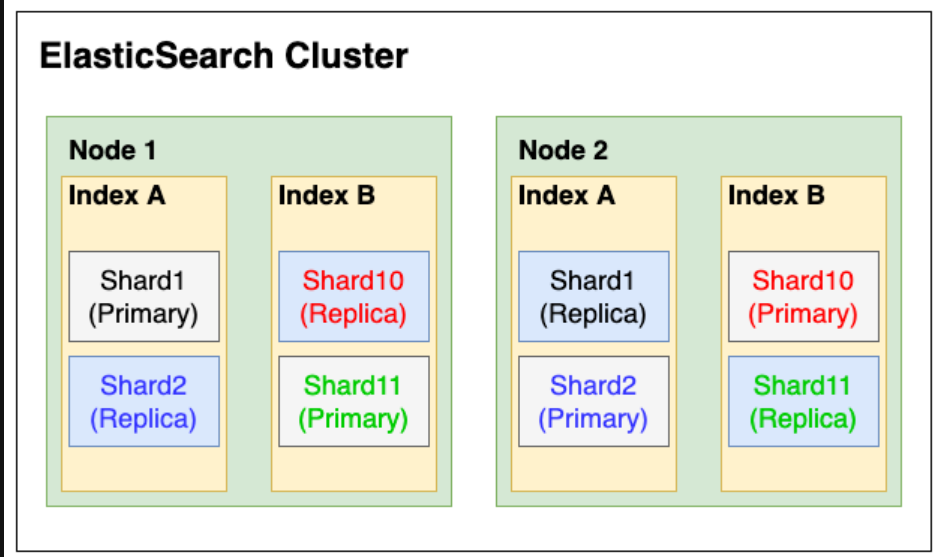
ES 를 클러스터 단위로 볼때 위와 같은 특징이 있다.
클러스터 > 노드 > 인덱스 > 샤드의 개념이 있는데 이때 갹 용어가 어떤 것을 의미하는지 알아보겠다.
노드 (Node) -> 클러스터에 포함된 단일 서버
- master 노드
- data 노드
- ingest 노드
- coordinating 노드
로 구분이 된다.
인덱스 (index)
단일 데이터 단위인 도큐먼트를 모아놓는 집합체를 인덱스라고 한다.
샤드 (shard)
문서가 저장되는 "공간" 의 개념.
인덱스는 논리적인 데이터 집합으로, 대량의 데이터를 포함할 수 있습니다.
이 대량의 데이터를 하나의 서버(노드)에 모두 저장하기 어렵기 때문에, Elasticsearch는 인덱스를 샤드로 나누어 여러 노드에 분산하여 저장합니다.
즉, 샤드가 인덱스의 데이터를 실제로 저장하는 "물리적 공간" 역할을 하며, 각 샤드는 데이터를 일부 분할하여 담습니다.
문서가 샤드에 저장되는 세부 방식
-
인덱스에 문서가 추가되면, Elasticsearch는 해시 알고리즘을 사용하여 해당 문서를 어느 샤드에 저장할지 결정합니다.
예를 들어, customer라는 인덱스가 3개의 샤드로 구성된 경우, 각 문서는 특정 샤드에 저장됩니다.
이렇게 샤드로 나누어진 데이터는 Elasticsearch 클러스터의 여러 노드에 분산 배치되며, 각 샤드가 인덱스 내 일부 문서를 저장하게 됩니다. -
색인(indexing)과 샤드의 관계:
색인(indexing) 과정에서 문서는 각 샤드에 저장되고, Lucene을 통해 역색인 구조로 관리됩니다.
색인된 데이터는 샤드 내부에서 Lucene 인덱스로 만들어져, 샤드가 문서를 저장하고 검색할 수 있는 공간이 됩니다.
즉, 샤드는 데이터를 물리적으로 저장하는 것뿐만 아니라, Lucene 인덱스를 통해 검색 가능한 형태로 문서를 색인해 두는 공간입니다.
예시
-
customer 인덱스가 있고, 3개의 샤드로 구성된다고 가정합니다.
-
고객 데이터를 입력할 때, 이 데이터를 해당 인덱스의 특정 샤드로 분배하여 저장합니다.
-
각 샤드는 자체 Lucene 인덱스를 통해 데이터를 역색인하여, 나중에 검색 요청 시 빠르게 찾아낼 수 있도록 저장합니다.
즉, Lucene 이 활용되는 공간은 샤드라는 개념이고 이때 역색인 과정이 이루어지고 Elastic Search 에서 어떤 요청을 하게 되면은 샤드를 통해서 검색 후 결과가 반환된다.
