데이터베이스
1.데이터베이스

데이터베이스 사용 이전 파일 시스템을 이용하여 데이터를 관리하였다. 하지만 이러한 방식은 데이터 종속성, 중복성 무결성에 대한 문제를 발생시켰다.논리적 독립성응용 프로그램에 영향을 주지 않고 데이터베이스의 논리적 구조를 변경할 수 있다.물리적 독립성응용 프로그램이나 데
2.DB Index
Key-value로 이루어진 데이터를 저장하는데 특화된 구조컬럼 값으로 해시 값을 계산해서 인덱싱 하는 방법Hash Table 기반의 DB Index는 특정 컬럼의 값과 데이터의 위치를 key-value로 사용속도 빠름O(1)값을 변형하는 방법동등 연산에 특화된 방법해
3.정규화
관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스 데이터 중복으로 인하여 발생할 수 있는 문제 해결삽입 이상 : 자료가 부족해서 데이터가 삽입 되지 않아 발생하는 문제삭제 이상 : 하나의 자료만 삭제하고 싶지만 해당 자료가 포함된 튜플 전체가
4.NOSQL & REDIS
둘은 대체될 수 있는 것이 아니고 상황에 따라 적절히 선택해서 사용해야 한다.테이블들의 관계를 통해서 데이터를 저장하는 데이터베이스로 SQL롤 데이터를 CRUD구조화가 굉장히 중요명확한 데이터 구조 보장, 중복을 피할 수 있다자유로운 형태로 데이터 저장Key-value
5.Elasticsearch
자바 기반 오픈소스 검색 엔진원본 데이터 → 색인 → 인덱스원본 문서를 변환하여 저장하는 과정색인 과정을 거친 결과물색인된 데이터가 저장되는 저장소인덱스는 샤드(shard)라는 단위로 분리되고 각 노드에 분산되어 저장된다.프라이머리 샤드 & 레플리카 샤드노드에 문제가
6.샤딩
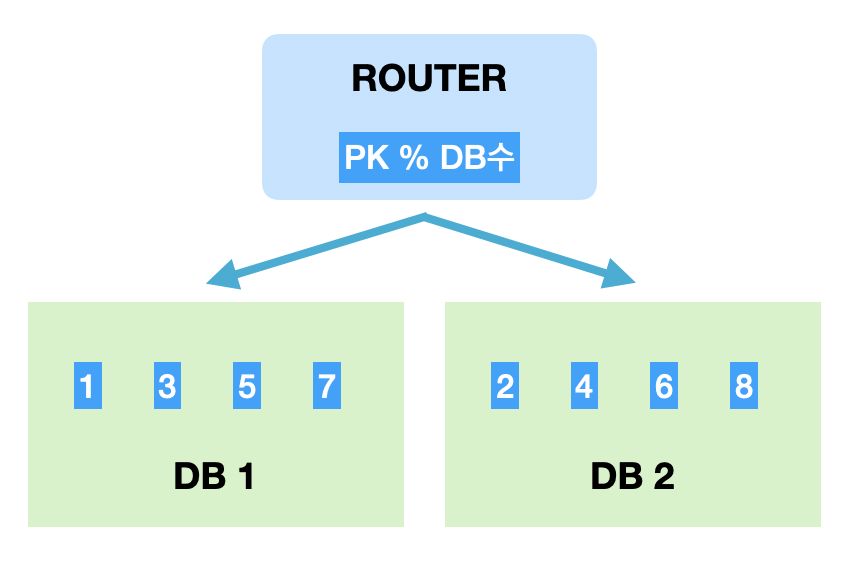
데이터의 빠른 검색을 위해 사용같은 테이블의 데이터를 다수의 데이터베이스에 분산하여 저장하는 방식으로 DB 트래픽의 분산을 목적으로 한다.Modular shardingPK를 모듈러 연산한 결과로 DB를 특정하는 방식데이터량이 일정 수준에서 유지도리 것으로 예상되는 데이
7.Join 방식
2개 이상의 테이블에서 하나의 테이블을 기준으로 순차적으로 상대방 ROW를 결합하여 원하는 결과를 추출하는 방식선행 테이블조인 시 먼저 액세스 되는 테이블Where 절로 최대한 데이터를 거를 수 있는 테이블/데이터 양이 적은 테이블로 선정후행 테이블조인시 나중에 액세스
8.Query 실행 순서
SELCT → FROM → WHERE →GROUP BY → HAVING → ORDER BYFROM : 각 테이블 확인ON : 조인 조건 확인JOIN : 테이블 조인WHERE : 데이터 추출 조건 확인GROUP BY : 특정 컬럼으로 데이터 그룹화HAVING : 그룹화
9.Transaction
데이터베이스에 상태를 변화시키는 작업의 논리적인 단위하나로 처리해야하는 명령문들의 그룹분할 할 수 없는 업무처리의 단위트랜잭션은 ACID 특징을 보장해야 한다.단 상황에 성능(동시성)을 위해 희생시킬 수 있다(by isolation level)트랜잭션에서 일관성과 동시
10.Postgresql window function 정리