- VACUUM에 대한 블로그 글을 읽고 정리한 내용입니다. 읽은 블로그는 아래와 같습니다.
- 틀린 내용이 존재할 수 있습니다.
MVCC(Multi-Version Concurrency Control)
vacuum이 무엇이며 왜 필요한지 이해하기 위해서는 PostgreSQL의 MVCC에 대해 알아야 합니다.
MVCC란
동시에 여러 트랜잭션이 수행되는 환경에서 각 트랜잭션에게 쿼리 수행 시점의 데이터를 제공하여
읽기 일관성을 보장하고 Read/Write 간의 충돌 및 lock을 방지하여 동시성을 높일 수 있는 기능으로,
모든 MVCC의 기본 원리는 트랜잭션이 시작된 시점의 Transaction ID와 같거나 작은 Transacion ID를
가지는 데이터를 읽는 것...
PostgreSQL Vacuum에 대한 거의 모든 것
실시간으로 데이터가 변경되는 환경에서 사용자가 조회를 시작한 시점의 데이터를 제공 받을 수 있도록 하는 방법입니다. 해당 방법은 DB 벤더마다 다르게 구현되는데 Oracle 또는 MySQL의 경우 현재 데이터와 과거 데이터가 분리된 공간에서 관리되도록 구현되었지만 PostgreSQL의 경우 현재 데이터와 과거 데이터가 한 공간에서 관리되도록 구현되어 있습니다. 이러한 차이가 PostgreSQL에서 VACUUM이 필요한 이유 입니다.
👉 현재 데이터: 변경된 데이터
👉 과거 데이터: 변경 전 데이터
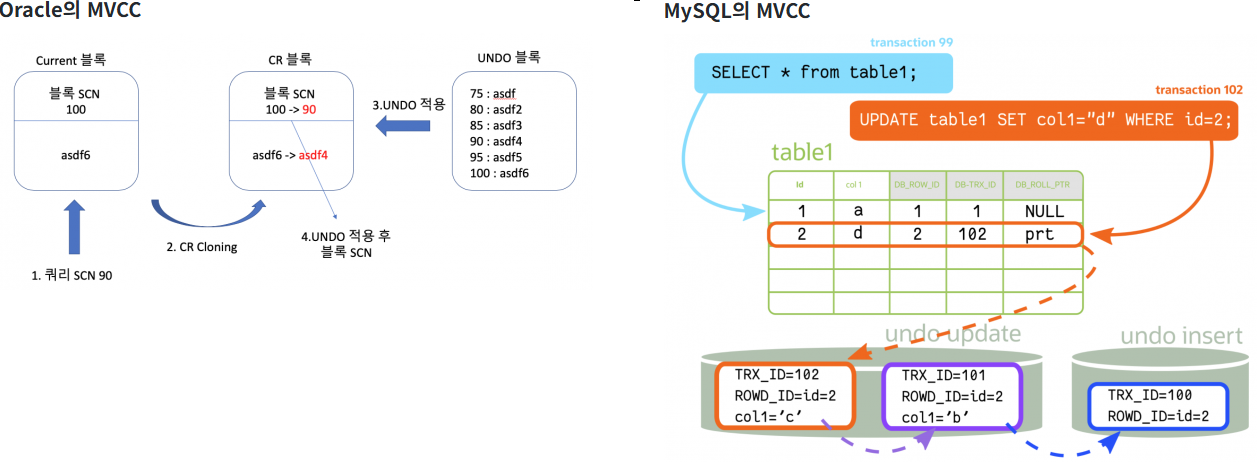
위 그림에서 확인 할 수 있듯이 Oracle과 MySQL은 모두 UNDO segment를 통해 현재 데이터와 과거 데이터를 분리하여 관리함을 확인 할 수 있습니다. (Oracle과 MySQL의 MVCC에 대한 자세한 내용은 블로그 내용 참고하길 바랍니다.)
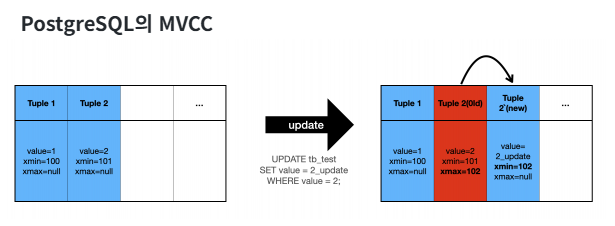
위 그림에서는 PostgreSQL은 과거 데이터(붉은색)와 현재 데이터(파란색) 를 분리하지 않고 관리하는 것을 확인할 수 있습니다. 그림의 붉은 색으로 칠해져 있는 데이터를 Dead Tuple이라고 하는데 이는 어디에서도 사용되지 않는 Tuple(쓸 데 없이 페이지의 공간을 차지하고 있는 Tuple)입니다.
PostgreSQL의 MVCC
PostgreSQL의 MVCC을 이해하려면 XMIN, XMAX에 대해 알아야 합니다.
XMIN
- Tuple을 insert/update 하는 시점의 Transaction ID를 가짐
- insert/update → XMIN에 해당 시점의 Transaction ID 할당
XMAX
- Tuple을 delete/update 하는 시점의 Transaction ID를 가짐
- delete → 변경되기 전 tuple의 XMAX에 해당 시점의 Transaction ID 할당
- update → 변경되기 전 tuple의 XMAX, 신규 Tuple의 XMIN에 해당 시점의 Transaction ID
위의 두 값을 이용하여 현재 트랜잭션에서 해당 Tuple을 볼 수 있을지 없을지 판단하게 됩니다. XMIN ≤ Transaction ID < XMAX의 범위에 들어간다면 Tuple을 보고 그렇지 않다면 볼 수 없게 됩니다. (좀 더 자세한 예시는 블로그 내용 참고하길 바랍니다.)
