데이터베이스의 필요성
모든 서비스는 데이터를 만들고 만들어진 데이터의 저장을 필요로 한다
데이터베이스의 종류
프로덕션 관계형 데이터 베이스(RDMS)
- 서비스 운영에 필요한 데이터를 저장하는 곳
- 속도가 중요
- 구조화된 테이블들의 집합으로 구성하여 저장하고 관리
- MySQL, PostgreSQL
데이터 웨어하우스
- 회사 내부에서 의상결정과 서비스 최적화를 위해 사용
- 속도보다 큰 데이터를 처리하하는 것이 중요
- BigQuery, SnowFlake, Redshift, MySQL...
관계형 데이터베이스
- 구조화된 데이터
- 프로덕션용 관계형 데이터베이스
비관계형 데이터베이스
- NoSQL 데이터베이스
- 구조화된 데이터 + 비구조화 데이터(이미지, 영상 등)
데이터 순환 구조
프로덕션 관계형 데이터베이스
→ 데이터 웨어하우스
→ 비지니스 인사이트(데이터 분석가가 수집된 데이터 분석)
→ 데이터 과학자에 의한 머신 러닝 모델 형성 및 서비스 개선
→ 프로덕션 관계형 데이터베이스
...
백엔드 관련 직군
백엔드 직군
-
DevOps(Development Operations)
서비스 모니터링, 최적화 작업을 통하여 서비스의 운영을 책임진다. -
Fullstack
프론트엔드와 백엔드 개발을 모두 할수 있는 개발자이다.
데이터 직군
-
데이터 엔지니어
데이터 웨어 하우스 관련일 담당한다. -
데이터 분석가
수집된 데이터를 분석한다. -
데이터 과학자
데이틀 이용하여 예측 모델링 또는 개인화 작업을 통해 서비스 개선한다.
백엔드 시스템 구성도
tier의 구분이 단순히 물리적인 공간의 구분을 의미하는 것은 아닌거 같다. 예를 들어 spring의 Business Layer는 application tier이고 Persistence Layer는 Data tier이다.
2 tier
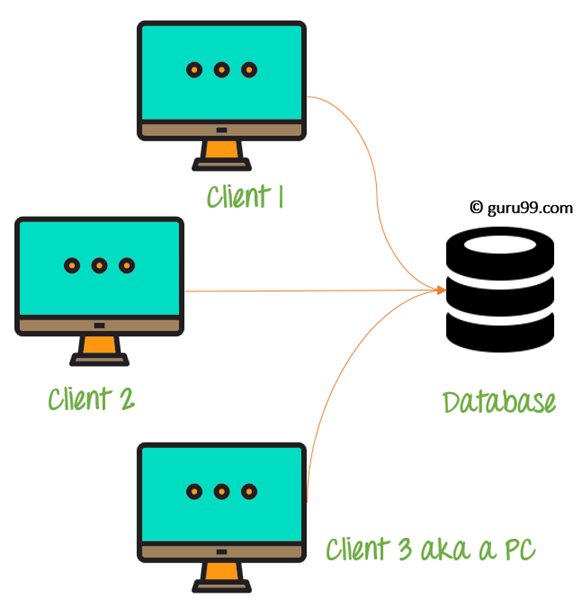
front-end와 back-end(데이터베이스 역할도 수행)
3 tier
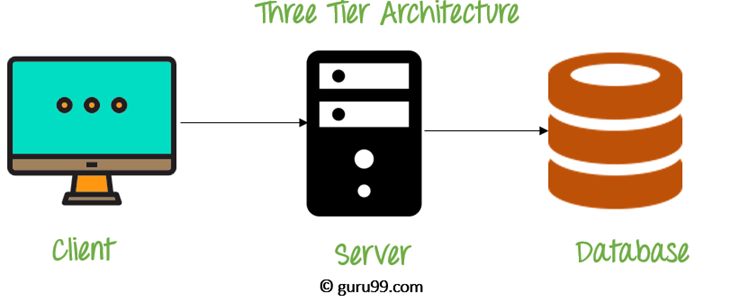
Presentation Tier, ApplicationTier, Data Tier
결국 어느 구조던 데이터베이스는 필요하다!
관계형 데이터베이스 소개
- 구조화된 데이터를 저장하고 질의할 수 있도록 해주는 스토리지
- DDL: Data Definition Language, 테이블을 정의한다.
- DML: Data Manipulation Language, 대데이터 조작과 질의를 한다.
OLTP(OnLine Transaction Processing)
- 프로덕션 관계형 데이터베이스
- 빠른 속도에 집중
OLAP(OnLine Analytical Processing)
- 데이터 웨어하우스
- 처리 데이터 크기에 집중
관계형 데이터베이스 구조
- 테이블들은 데이터베이스라는 폴더 밑으로 구성된다.
database1--
|--table1
|--table2
|--table3
database2--
|--tableA
|--tableB- 테이블은 레코드(행)으로 구성
- 레코드는 하나 이상의 필드(컬럼, 행)으로 구성
- 필드는 이름과 타입과 속성으로 구성
SQL
- 관계형 데이터베이스에 있는 데이터를 질의하거나 조작해주는 언어
- 데이터 규모에 상관 없이 사용된다.
단점
- 비구조화된 데이터를 다루기에 제약이 많다.
- nested 구조가 지원되지 않는다.
기본
- SQL문은 세미콜론으로 분리
- 주석
- 한줄 주석:
-- - 여러줄 주석:
/**/
- 한줄 주석:
- 팀 단위 활동시 규칙이 필요하다
- SQL 키워드 대문자 사용 여부
- 테이블/필드 이름 명명 규칙
단수형 VS 복수형 → User VS Users
_ VS CamelCase → user_session_channel vs. UserSessionChannel
DDL
- CREATE TABLE
CREATE TABLE DB_이름.table_이름 (
컬럼_이름 컬럼_타입 컬럼_속성,
...
);- DROP TABLE
DROP TABLE table_name;- ALTER TABLE
- ADD COLUMN
- 컬럼 추가
ALTER TABLE table_name ADD COLUMN field_name filed_type;
- 컬럼 추가
- RENAME TO
- 컬럼 이름 변경
ALTER TABLE table_name RENAME field_name TO new_filed_name; - 테이블 이름 변경
ALTER TABLE table_name RENAME TO new_table_name;
- 컬럼 이름 변경
- DROP COLUMN
- 기존 컬럼 제거
ALTER TABLE table_name DROP COLUMN field_name;
- 기존 컬럼 제거
- ADD COLUMN
DML
- SELECT
- 조회
- SELECT FROM: 테이블에서 레코드와 필드를 읽어온다.
- WHERE: 레코드 선택 조건 설정한다.
- GROUP BY: 레코드를 그룹화한다.
- ORDER BY: 레코드 순서를 설정한다.
- INSERT INTO
- 레코드 추가
- UPDATE SET
- 레코드 수정
- DELETE FROM
- 레코드 삭제
- 조건을 사용할 수 있다.
- TRUNCATE는 조건을 사용할 수 없다.
schema
Star schema
- 프로덕션 관계형 데이터베이스에서 주로 사용한다.
- 데이터를 논리적 단위로 나누어 저장하고 필요시 조인한다.
- 데이터를 테이블 형태로 나눈다.
- 스토리지 낭비가 덜하고 업데이트가 쉽다.
Denormalized schema
- NoSQL이나 데이터 웨어하우스에서 사용
- 별도의 조인이 필요 없는 형태를 말한다. 그리고 이는 빠른 계산이 가능하도록 만든다.
참고

꾸준히 나아가자 🐢