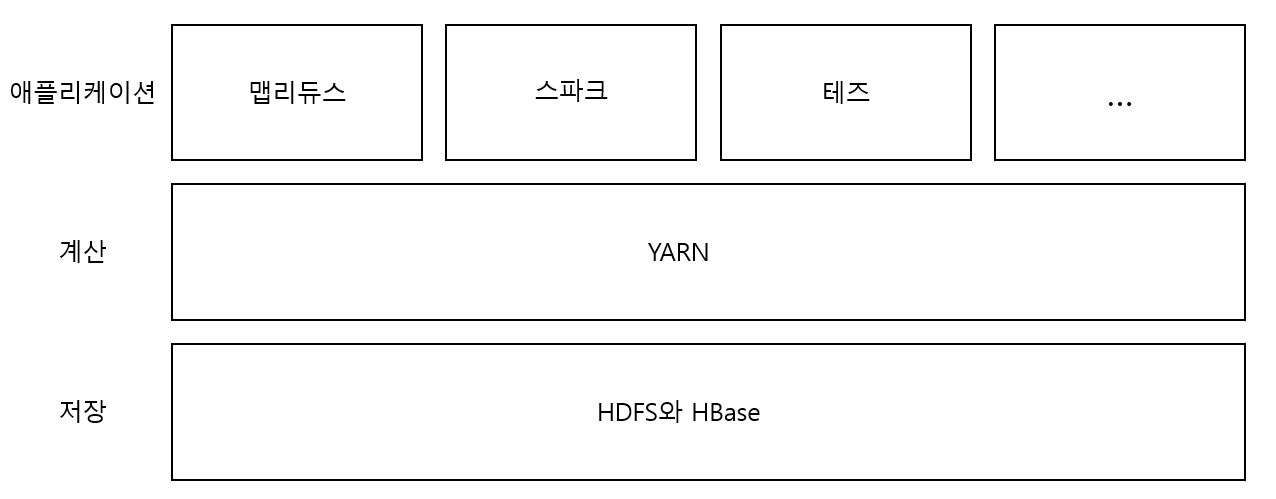
- Apache YARN은 Hadoop의 클러스터 자원 관리 시스템이다.
- MapReduce 뿐만 아니라, 다른 분산 컴퓨팅 도구도 지원한다.
- Cluster의 자원을 요청하고 사용하기 위한 API를 제공한다.
- 사용자 코드에서 이 API를 사용할 수는 없고, YARN이 내장된 분산 컴퓨팅 프레임워크에서 고수준 API를 작성해야한다. 자원관리의 자세한 내용은 추상화 되어있다.
- MapReduce, Spark 등과 같은 분산 컴퓨팅 프레임워크는 Cluster 계산 계층(YARN)과 클러스터 저장 계층(HDFS와 HBase)위에서 YARN 애플리케이션을 실행한다.
- Resource Manager와 Node Manager
- 하나의 Resource Manager는 Cluster 전체 자원의 사용량을 관리한다.
- 모든 machine에서 실행되는 Node Manager는 Container를 구동하고 모니터링하는 역할을 한다.
- 자원요청
3.1 MapReduce는 처음에 필요한 Map Task 컨테이너를 요청한다. Reduce Task 컨테이너는 Map Task가 어느정도 실행된 후에 요청/시작할 수 있다. 또, 특정 Task가 실패하면 실패한 Task를 다시 실행하기 위해 컨테이너를 추가로 요청한다.
3.2 Spark는 처음에 모든 요청을 한다. Cluster에서 고정 개수의 executor를 시작한다.
3.3 세번째는 여러 사용자들이 공유할 수 있는 장기 실행 애플리케이션이다.(임팔라/슬라이더)
※ Job의 방향성 비순환 그래프(DAG)를 실행하고 싶으면 스파크가 적합하다.

yozzum