
이 글은 단위 테스트 책을 읽고 리뷰한 글입니다.
테스트의 목표
코드를 작성하는 행위는 소프트웨어에서 엔트로피 (entropy) 를 높이는 행위다.
이 작성한 코드 때문에 기존에는 발생하지 않았던 에러가 갑자기 생길수도 있다.
테스트는 이러한 상황에서 문제가 생겼다는 것을 알려줄 수 있는 안전망 같은 역할을 한다.
테스트를 통해서 우리는 코드를 더 작성할 수 있고 소프트웨어를 더 발전시킬 수 있다.
즉 테스트는 소프트웨어의 지속적인 성장 을 위해서 존재한다.
이를 위한 성공적인 테스트 스위트 (Test Suite) 들은 다음과 같은 특징을 가지고 있다.
- 개발 주기에 포함되어 있다.
- 코드 베이스 중에 가장 중요한 부분을 테스트하며 최소한의 테스트로 최대한의 가치를 얻는다.
개발 주기에 포함되어 있다는 뜻은 개발 중 언제든지 테스트를 실행해서 잘못된 부분이 있는지 피드백을 받을 수 있다는 뜻이고
최소한의 테스트로 최대한의 가치를 얻어야 한다는 뜻은 쓸데없는 시간을 보내지마라 와 테스트 코드도 결국 유지해야할 비용이 든다 라는 뜻이다.
테스트에 대한 오해가 있는데 테스트는 많다고 좋은 걸까? 테스트 커버리지가 높다고 좋을까?
그렇지 않다. 테스트를 작성한다는 것 자체가 목표가 되면 안된다.
테스트는 좋은 테스트가 많아야 좋고, 여러 시나리오를 검증하는게 많은 테스트가 좋다.
(여러 시나리오를 검증한다고 해서 테스트 커버리지가 마냥 높아지진 않는다.)
여기서 우리는 좋은 테스트를 알아보는 시각과 이를 작성하는 방법에 대해서 소개하겠다.
좋은 테스트의 4대요소
좋은 단위 테스트의 4대 요소는 다음과 같다.
- 회귀 방지 (Protection against regressions)
- 리팩터링 내성 (Resistance to refactoring)
- 빠른 피드백 (Fast feedback)
- 유지보수 용이성 (Maintainability)
회귀 방지 (Protection against regressions)
회귀 방지는 소프트웨어 버그를 방지한다는 것이다.
코드가 복잡할수록, 실행되는 코드의 양이 많을수록, 도메인 영역의 코드일수록 이런 회귀 테스트는 필요하다.
- 단순한 코드는 딱히 테스트가 필요하지 않다.
그리고 중요한게 우리가 작성한 코드 뿐 아니라 라이브러리와 프레임워크를 사용하는 “우리가 작성하지 않은 코드" 에 대해서도 검증이 필요하다.
- 이것들이 항상 정상적으로 작동한다고 가정하지 말자.
회귀방지가 있어야 프로그램의 안정성을 지킬 수 있다.
리팩터링 내성 (Resistance to refactoring)
리팩터링을 했는데 테스트가 실패하면 안된다.
즉 정상적으로 작동하는데 테스트가 실패하면 안된다 라는 뜻이다.
리팩터링 내성이 있어야 리팩터링 하기 쉽다.
리팩터링을 했는데 이런 거짓 양성 (false positive) 이 계속해서 일어난다면 우리는 문제가 났는데도 그걸 주의깊게 찾아보려고 하지 않을 것이다.
즉 테스트에 대한 신뢰가 꺠진다.
그래서 결론적으로 버그가 나도록 이끌것이다.
리팩터링 내성이 있어야 프로그램을 성장으로 이끌 수 있다.
거짓 양성을 피할려면 어떻게 해야할까?
테스트가 실제 객체의 세부 구현에 의존하지 않도록 하자.
변경되지 않는 부분인 추상화된 인터페이스에 대한 결과를 검증하자.
테스트 정확도
이 쯤에서 테스트 정확도를 낮추는 요인은 뭘까?
- 에러가 나야하는데 테스트가 성공하는 경우 (거짓 음성)
- 제대로 동작하는데 테스트가 실패하는 경우 (거짓 양성)
거짓 음성의 경우 회귀 방지가 해결해줄 수 있고 리팩터링 내성은 거짓 양성을 해결해주는데 도움을 준다.
즉 좋은 테스트 요소인 회귀 방지와 리팩터리 내성은 테스트 정확도를 높이는데 사용한다.
빠른 피드백 (Fast feedback)
테스트를 빠르게 실행시키고 버그라는 피드백을 빠르게 받을 수 있다면 버그를 고치는 비용은 엄청 줄어들 것이다.
이를 위해서 테스트는 빨리 실행되어야 한다.
유지보수 용이성 (Maintainability)
테스트 코드를 유지하는 비용을 말한다.
유지 비용은 다음과 같다.
- 테스트 코드가 읽기 쉬어야지 테스트 코드를 리팩터링하고 필요한 테스트를 보완할 수 있다.
- 테스트 코드를 실행하기 좋아야 한다. 실행하기 어려우면 테스트를 돌리기 어렵다.
테스트의 가치
테스트의 가치는 이 네가지 요소를 곱한 값이다.
즉 하나라도 0 이면 가치는 없다.
테스트 가치가 없는 극단적인 사례들을 보자.
-
엔드 투 엔드 (E2E) 테스트
-
엔드 투 엔드 테스트는 최종 사용자 입장에서의 테스트이므로 회귀를 방지하는데 도움을 주고 리팩터링을 한다고 거짓 양성을 내지 않는다.
-
다만 빠른 피드백을 줄 수 없다. 그래서 버그가 난다면 버그 수정 비용이 엄청 클 것이다.
-
그리고 테스트를 작성할 때 필요한 설정들을 연결해야하는 작업이 클 것이므로 유지보수면에서도 비싸다.
-
-
간단한 테스트
-
간단한 테스트는 간단한 코드를 테스트 하는 것이므로 빠르다. 그리고 리팩터링 한다고 실패하지도 않을 것이다.
-
하지만 테스트 자체가 필요한 정보를 전달해주지 않는다.
-
회귀를 방지하는데 도움을 주지 않는다.
-
-
깨지기 쉬운 테스트
-
이런 테스트는 회귀를 방지할 확률이 높다. (거의 실패하므로 고치겠지.)
-
하지만 이런 테스트는 리팩터링 내성이 없다.
-
테스트 설계의 방향성
유지보수성은 코드를 짜는 개발자의 역량에 따라 다를 것이라서 배제를 하고 생각을 해보자.
리팩터링 내성도 OOP (object-oriented-programming) 기준 객체간의 결합을 얼마나 느슨하게 하느냐에 따라서 다르다.
하지만 회귀 방지와 피드백의 속도는 다르다. 이 두 요소는 서로 반비례한다.
회귀를 방지한다는 뜻은 객체지향 설계 기준으로 많은 객체가 협력하고 있는 동작을 검증하겠다는 뜻으로 그만큼 느려진다.
즉 개발자는 리팩터링 내성과 유지 보수성은 신경쓰면서 회귀 방지와 빠른 피드백 사이를 조율해야 한다.
이 말은 단위 테스트와 통합 테스트 사이에서 조율을 잘해야 한다 는 뜻이다.
단위 테스트는 어떻게 작성해야 할까?
단위 테스트를 작성할 때 지켜야 할 구조
일반적으로 테스트를 작성한다고 하면 AAA (준비 - 실행 - 검증) 구조를 따른다.
@Test
void test() {
// Arrange
// Act
// Assert
}이 패턴은 Given - When - Then 과 같다. (이렇게 알고 있는 사람이 더 많을수도.)
이 구조의 장점은 모든 테스트가 일관된 규칙을 가질 수 있는 점과
준비 -> 실행 -> 검증으로 가면서 테스트를 이해하기 더 쉽다는 점이 있다.
이 구조로 할 때 고려할 점이 있다.
1) 딱 한 개의 검증문 만을 가질 필요는 없다.
- 테스트는 하나의 동작 이후에 검증을 하는 것이다. 즉 검증할 게 딱 하나만 있지는 않아도 된다. 다만 같은 속성을 검증하는 것이라면 클래스로 뺴내서 검증하면 코드를 좀 더 줄일 수 있을 것.
2) 하나의 테스트에 하나의 준비와 실행을 가지도록 하는게 가독성 면에서 더 좋다.
- 여러개의 준비, 실행, 검증문을 가진다면 테스트를 이해하는데 복잡할 수 있다. 검증도 물론 하나면 더 가독성 있다.
3) 준비 구절이 너무 크다면 이를 팩토리 클래스나 메소드로 빼내는게 더 가독성 면에서 좋을 수 있다.
- 빌더 패턴을 통해서도 객체를 생성할 순 있는데 너무 많은 메소드 체이닝이 있기 때문에 추천하지는 않는다.
4) 실행 절이 한 줄보다 많다면 API 설계의 문제일 수 있다. 캡슐화를 해서 하나의 실행 절로 줄이자.
5) 준비 - 실행 - 검증 이렇게 세 부분을 주석으로 남겨두면 더 알기 쉬울 수 있다. 물론 빈 줄로 분리할 수도 있다.
6) 준비만 조금 다른 테스트가 있다면 하나의 테스트로 묶는게 더 코드를 줄이므로 유지보수 측면에서 좋다.
(작은 팁으로 테스트 명명법으로는 스네이크 케이스 (= _ ) 로 작성하는게 가독성 면에서 좋다.)
단위 테스트는 ‘동작' 단위로 검증해라.
어떠한 사람들은 내가 작성한 ‘코드’ 위주로 테스트를 작성해야 한다고 말하기도 한다.
그래서 하나의 모듈 (클래스) 에는 하나의 테스트가 있어야 한다고 말한다.
이런식의 테스트는 문제의 원인을 정확히 찾을 수 있다는 장점이 있다.
하지만 이런 류의 테스트는 우리가 작성한 코드를 검증하기 떄문에 ‘구현' 과 관련있는 경우가 많다.
즉 리팩터링 내성이 부족하다. 그리고 테스트가 어떠한 목적을 가지고 있는지도 명확하지 않다. (유지보수 측면에서도 부족하다.)
테스트는 객체의 협력을 바탕으로 제공해주는 ‘식별할 수 있는 동작' 을 기반으로 검증을 해야한다.
정의는 다음과 같다.
클라이언트가 목표를 달성하는 연산 or 클라이언트가 목표를 달성하는 상태
즉 핵심 비즈니스 문제를 해결할 수 있는 연산으로 주로 변경할 여지가 없는 부분을 말한다.
이러한 동작 단위로 검증을 하고자 할 땐 애초에 검증을 하고자 하는 동작 단위를 public 메소드로 노출하고 구현의 세부 사항을 private 메소드로 숨겨야 한다.
이렇게 캡슐화를 잘 하는 것부터 시작이다.
이는 마틴 파울러가 말하는 Tell-Don’t-Ask 와 같다.
육각형 아키텍처 (Hexagonal architecture) 입장에서의 식별할 수 있는 동작
여기서는 일반적으로 어플리케이션을 설계할 때 사용하는 핵사고날 아키텍처 (Hexagonal architecture) 입장에서 식별할 수 있는 동작 이 뭔지 보자.
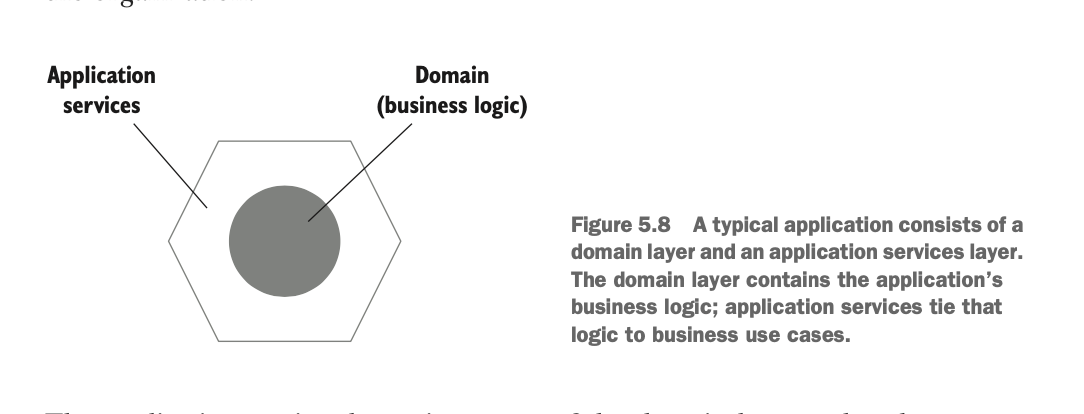
핵사고날 아키텍처는 어플리케이션 서비스와 핵심 도메인 이렇게 크게 두 가지 영역으로 나뉜다.
어플리케이션 서비스는 외부로부터 받는 요청을 핵심 비즈니스를 담당하는 도메인에게 전달하는 역할을 하며, 도메인은 도메인끼리 내부적으로 협력을 하면서 핵심 비즈니스를 처리해나간다.
절대 도메인에게 바로 요청을 보낼 수 없다. 서비스를 통해서만 요청이 전달된다.
서비스는 도메인이 처리한 결과를 데이터베이스에 저장하거나 그 결과를 바탕으로 또 다른 도메인에게 전달하는 역할을 한다.
이렇게 서비스와 도메인을 분리하는 이유는 다음과 같다.
- 도메인 계층과 서비스 계층의 관심사 분리: 도메인은 제일 중요한 비즈니스를 처리하는 역할에만 집중해야 한다. 그외의 다른 로직과 연결이 되면 안된다.
잘 설계된 핵사고날 아키텍처에서 어플리케이션 서비스와 도메인은 다음과 같은 프렉탈 (fractal) 특성을 띈다.
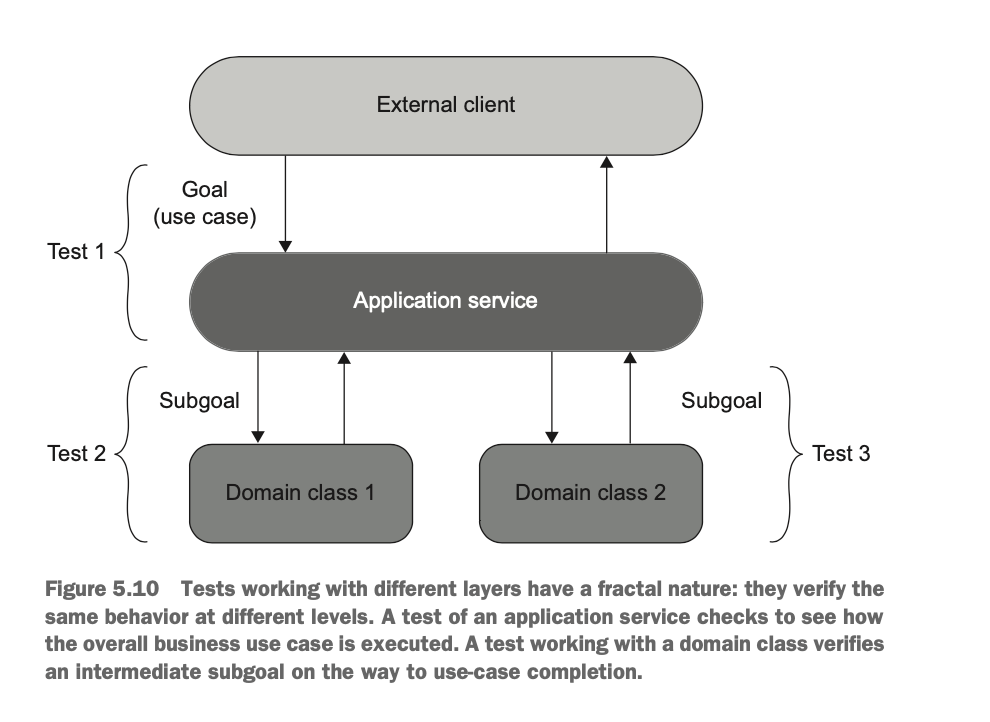
- 서비스는 외부 클라이언트로부터 원하는 목표 수행을 위해 요청을 전달 받는다.
- 서비스는 이러한 목표 수행을 위해서 도메인이 요청을 처리하도록 한다.
- 도메인은 궁극적인 목표를 위해서 하위 목표를 하나씩 처리해나간다.
- 즉 달성하는 목표는 같지만 처리하는 수준은 다르다. 애플리케이션 서비스는 큰 목표라면 도메인은 하위 목표를 처리한다.
이를 서비스 입장에서 본다면 상대적으로 도메인끼리 협력해서 처리하는 하위 목표는 세부 구현 사항 으로 볼 수 있고 어플리케이션 서비스를 통해서 시스템 외부 어플리케이션간의 통신은 식별할 수 있는 동작 으로 볼 수 있다.
하지만 이를 도메인 입장에서 본다면 도메인끼리 협력해서 처리하는 목표는 식별할 수 있는 동작 으로 볼 수 있고 간단히 도메인끼리 이웃하는 클래스끼리의 협력은 세부 구현 사항 으로 볼 수 있다.
즉 이웃하는 클래스끼리의 협력은 세부 구현 사항이므로 작성하면 안된다.
오로지 식별할 수 있는 동작을 기준으로만 단위 테스트를 작성하자.
물론 예외도 있다. 해당 도메인 클래스에서의 처리 로직이 아주 복잡한 경우에는 테스트 할 가치가 있겠지.
가치 있는 테스트를 작성하는 방법
이전에 가치 있는 테스트를 식별하는 요소들을 봤다면 여기서는 가치 있는 테스트를 작성하기 위한 코드 설계법을 알아보겠다.
제품 코드와 테스트 코드 사이에는 관련성이 많으므로.
테스트 할 코드 식별하기
먼저 테스트 할 코드를 식별하는 방법이다.
우리가 테스트 할 코드는 (코드의 복잡도와 도메인 유의성) 그리고 (협력자 수) 를 기반으로 다음과 같이 나눌 수 있다.
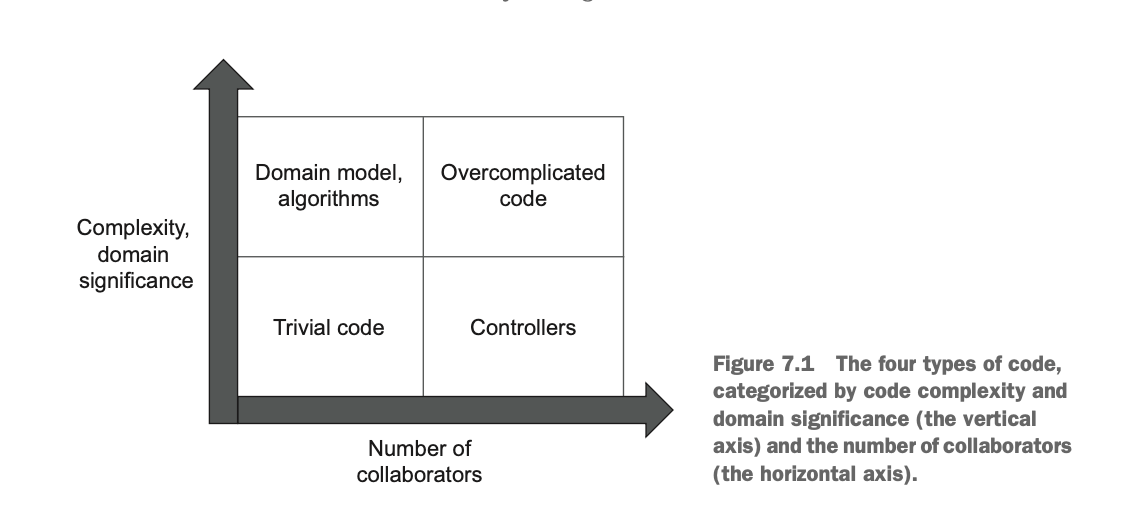
- 도메인 모듈과 알고리즘: 도메인 모듈과 복잡한 코드는 회귀 방지를 위해서 테스트틀 꼭 해야한다.
- 간단한 코드: 간단한 코드는 테스트 할 가치가 없다.
- 컨트롤러 (서비스): 컨트롤러 레벨의 테스는 통합 테스트로서 가치가 있다.
- 지나치게 복잡한 코드: 문제는 이 부분인데 테스트 할 가치는 충분하지만 테스트 하기 어렵다. 이 부분의 해결은 쪼개서 도메인 모듈과 컨트롤러노 나누도록 해야한다.
험블 객체 패턴을 통해서 지나치게 복잡한 코드 분할하기
지나치게 복잡한 코드를 쪼개기 위해서는 험블 객체 패턴 (Humble Object Pattern) 을 쓰면 된다.
복잡한 코드는 다음과 같이 하나의 모듈 안에 테스트하기 어려운 의존성들과 핵심 로직을 같이 가지고 있다.
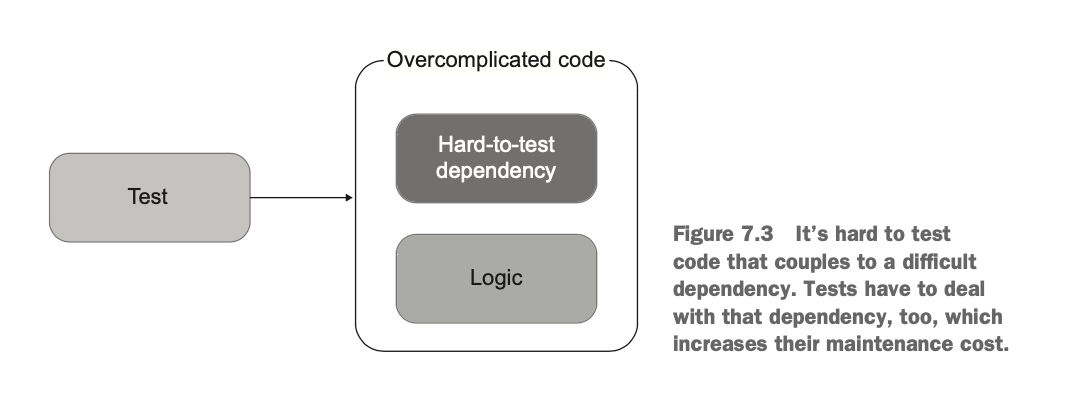
이 코드를 앞 단에 험블 객체를 둬서 의존성과 핵심 로직을 분리함으로써 복잡한 코드를 쪼갤 수 있다.
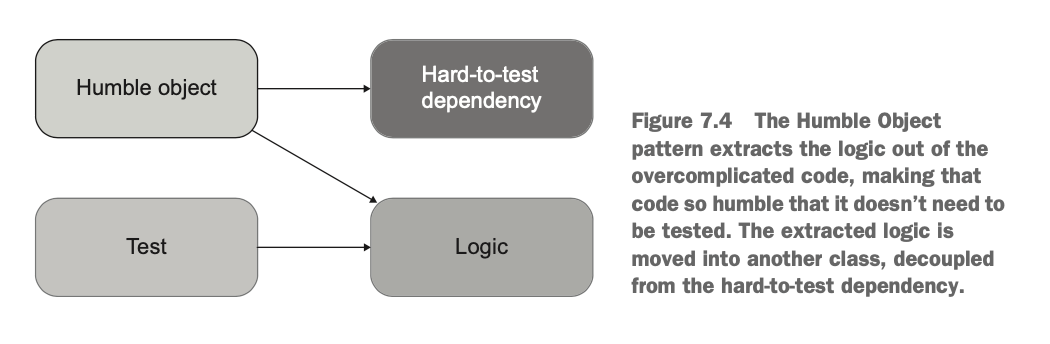
이렇게 나누면 테스트는 해당 로직에만 집중해서 설계하면 된다. (지나치게 복잡한 코드 → 도메인 모델의 테스트로 이동시킴)
그리고 험블 객체의 테스트는 컨트롤러 레벨로 이동시키면 된다. (지나치게 복잡한 코드 -> 컨트롤러 테스트로 이동)
정리하자면 험블 객체 패턴은 비즈니스 로직과 오케스트레이션 (orchestration 으로 복잡한 의존성을 말함.) 을 분리하는 패턴을 말한다.
이렇게하면 복잡한 의존성을 분리시킬 수 있어서 테스트에 용이하고 비즈니스 로직에만 집중할 수 있어서 코드의 복잡도를 줄일 수 있다.
이 패턴은 도메인 주도 설계 (Domain-Driven-Design) 의 Aggregate Pattern 과도 유사점이 있다.
- Aggregate Pattern 은 클래스를 클러스터로 묶어서 클러스터 안의 클래스는 서로 긴밀하게 관련이 있지만 클러스터 끼리의 결합은 느슨하게 필요한 결합만 하도록 한다.
실제 예시가 궁금하다면 여기 를 참조하자.
통합 테스트를 작성해야 하는 이유
통합 테스트는 왜 작성해야 할까?
통합 테스트를 하면 단위 테스트로는 확인하기 어려운 '시스템이 전반적으로 잘 작동하는 지' 를 알 수 있다.
그리고 통합 테스트는 많은 범위를 테스트 하므로 회귀 방지가 단위 테스트 보다 좋고 테스트를 위한 협력이 필요한 협력만으로 테스트를 하니 리팩터링 내성도 좋다.
물론 단위 테스트는 통합 테스트보다 빠르게 실행될 수 있다는 장점이 있고 격리된 상태에서 도메인 로직과 알고리즘을 테스트하기에는 적합하다.
예전에 테스트의 종류 4 가지를 알아봤었다.
- 간단한 테스트
- 지나치게 복잡한 테스트
- 컨트롤러 (서비스) 테스트
- 도메인 모델과 알고리즘 테스트
통합 테스트는 여기서 컨트롤러쪽 테스트가 되야한다.
(실제로 테스트 4 종류에서 간단한 테스트와 지나치게 복잡한 테스트는 있으면 안된다.)
모든 테스트들은 단위 테스트와 통합 테스트 그리고 빠른 실패 원칙 (Fail Fast Principle) 정도면 충분하다.
단위 테스트는 여러가지 비즈니스 시나리오를 검증하는데 사용하고
통합 테스트는 시스템의 작동 여부와 함께 중요한 비즈니스의 유즈 케이스와 단위 테스트로는 하지 못하는 예외 상황 (Edge case) 를 다루도록 사용한다.
그리고 통합 테스트는 모든 프로세스 외부 의존성을 사용하고 있는 플로우가 있어야 한다. (목적이 시스템의 기능 작동이 되고 있는지 확인하는 것이므로.)
- 프로세스 외부 의존성이란 데이터베이스와 같은 내가 제어할 수 있는 의존성과 메시지 큐와 같은 제어할 수 없는 외부 서비스로 이뤄진다.
만약 이러한 플로우가 없다면 모든 프로세스 외부 의존성을 다룰 수 있는 케이스만큼 작성해야 한다.
마지막으로 빠른 실패 원칙 (Fail Fast Principle) 같은 경우는 예상치 못한 상황을 만나면 즉시 연산을 중지하도록 예외를 던지는 걸 말한다.
이 방식은 초기에 실패하도록 해서 더 큰 버그가 생기도록 막는 방식이다.
주로 유효하지 않은 값이 넘어올 때 예외를 던지도록 하는 방법이 있고
어플리케이션의 초기 상태를 설정 프로퍼티에서 읽어오고 유효성 검사를 한 후 적절한 상태가 아니라면 실행하지 못하도록 하는 방법이 있다.
통합 테스트에서는 프로세스 외부 의존성을 모두 테스트해야 하는가?
내가 컨트롤 할 수 있는 관리 의존성 (데이터베이스 같은것) 은 목으로 대체하지 않고 실제 객체를 쓰는 걸 권장한다.
이 의존성은 변경될 가능성이 많기 때문에 목으로 대체하면 리팩터링 내성이 생기지 않을 수 있다.
내가 제어할 수 없는 비관리 의존성 (이메일 서비스나 메시지 큐 서비스 같은 것) 은 목으로 대체하는 걸 권장한다.
이 부분에서 실제 객체를 쓴다면 부작용을 야기할 수 있으므로 목을 쓰는게 좋다.
이런 의존성과의 연동에서는 주로 하위 호환성을 보장하도록 하니까 리팩터링 내성에도 강하다.
예외로 어플리케이션에서 실제 데이터베이스를 사용할 수 없는 경우가 있다면 데이터베이스를 모킹하기 보다는 그냥 단위 테스트에 집중하는게 낫다.
괜히 모킹하면 리팩터닝 내성이 없어져 의미없는 테스트가 된다.
통합 테스트 모범 사례
통합 테스트를 잘 쓰기 위해서 사용되는 몇 가지 지침이 있다. 하나씩 보자.
- 도메인 모델 경계 명시하기
- 어플리케이션 내 계층 줄이기
- 순환 의존성 제거하기
도메인 모델 경계 명시하기
도메인 모델을 코드베이스에서 명시적으로 격리 시켜서 단위 테스트와 통합 테스트를 구분하기 쉽도록 하자.
단위 테스트는 도메인 모델의 비즈니스 로직과 알고리즘을 테스트 하도록 하고
통합 테스트는 시스템의 기능 작동에 집중하도록 관심사를 나누자.
어플리케이션 내 계층 줄이기
엔터프라이즈급 어플리케이션에서는 계층이 여러겹인 경우가 있는데 계층 수는 필요한 계층만 있고 되도록 줄이도록 하자.
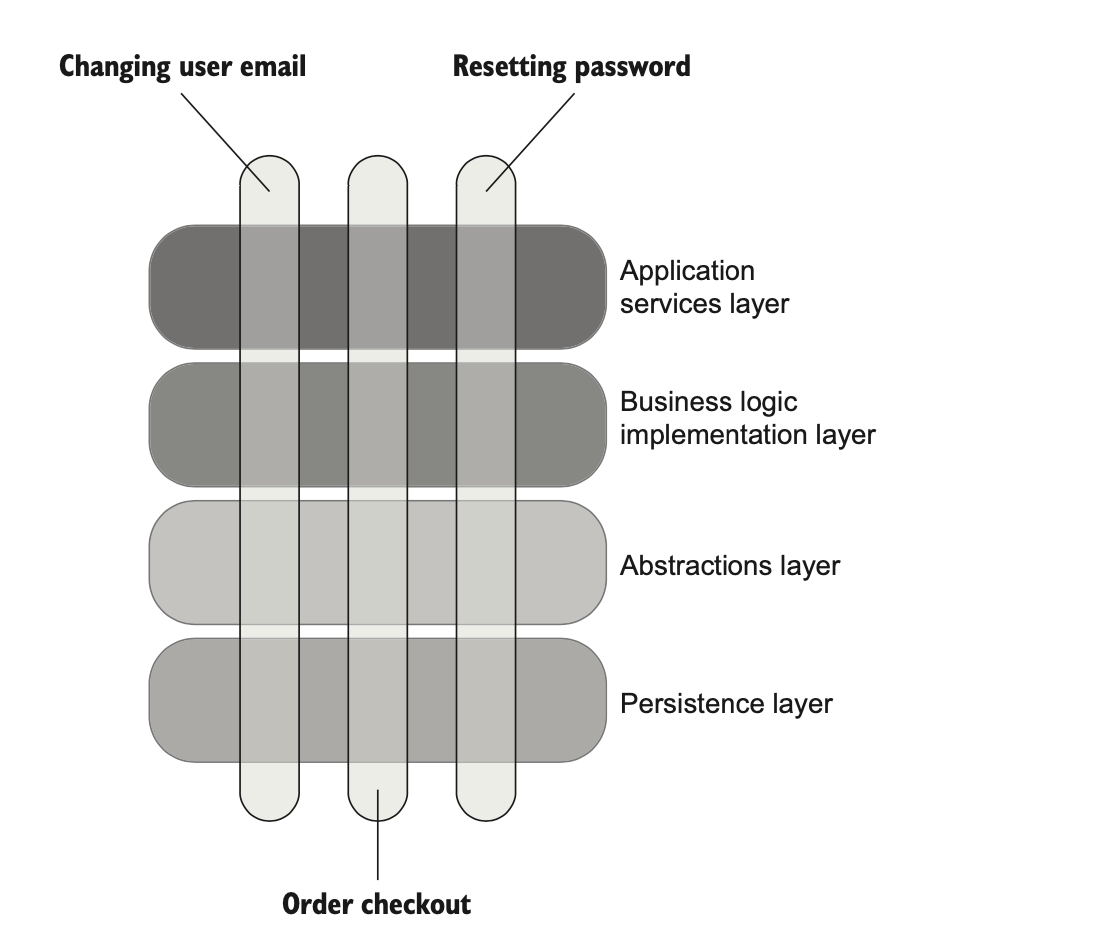
다음과 같이 레이어가 여러개 생긴다면 단위 테스트와 통합 테스트간의 간격도 명확하지 않아진다.
그래서 그냥 각 레이어별로 검증하도록 되게 되는데 이렇게되면 테스트가 서로 겹치는게 많아져서 테스트의 가치가 떨어진다.
가능한 필요한 계층만 두도록 하자.
주로 어플리케이션 서비스 계층, 도메인 계층, 인프라 계층 이 정도면 충분하다.
인프라 계층은 도메인 모델에 속하지 않는 알고리즘과 프로세스 외부 의존성에 접근할 수 있는 코드로 구성된다.
순환 의존성 제거하기
순환 의존성 (circular dependency) 는 둘 이상의 클래스가 제대로 작동하고자 할 때 서로 의존하는 것을 말한다.
주변 클래스 그래프 전체를 이해해야 하기 때문에 순환 의존성이 있다면 코드를 이해하기 어렵다.
그리고 동작 단위를 검증하려고 의존성을 만들 때 불편하다. 즉 테스트하기가 어렵다.
이 경우 순환 의존성을 제거하는게 좋다.
서로가 의존하기 보다는 메시지를 받으면 처리할 수 있도록 단방향 관계가 되도록 리팩터링 하는게 좋다.
통합 테스트에서 코드 재사용하기
통합 테스트는 코드가 보편적으로 단위 테스트보다 많은데 (협력자 수가 많고 검증할 게 많을 수 있다.)
이 경우 코드의 가독성이 떨어지고 유지 보수 비용을 증가시킬 수 있다.
그래서 중복되는 코드 같은 경우는 재사용하는 걸 권장한다.
준비 구절에서 코드 재사용하기
테스트를 위한 데이터를 생성하는 과정을 private 팩토리 메소드로 대체하는걸 추천한다.
그리고 이런 팩토리 메소드가 여러개 생긴다면 별도의 헬퍼 클래스를 만들자.
예시로는 다음과 같다.
User user = CreateUser(
email: "user@mycorp.com",
type: UserType.Employee);이렇게 테스트 픽스처 (테스트 실행 대상) 을 생성하는 방식의 패턴을 오브젝트 마더 (Object Mother) 라고 부른다.
이렇게 생성하는 것과 빌더 패턴을 이용해서 생성하는 방식이 있는데 빌더 패턴은 상용구가 너무 많이 필요하다.
실행 구절에서 코드 재사용하기
모든 통합 테스트 구절에서 실행 구절이 중복되는 부분이 있다면 이를 재사용할 수 있다.
이거는 데코레이터 패턴을 이용하는 것으로 예제를 통해서 보자.
string result;
using (var context = new CrmContext(ConnectionString))
{
var sut = new UserController(
context, messageBus, loggerMock.Object);
// Act
result = sut.ChangeEmail(user.UserId, "new@gmail.com");
}- 실행을 위해서 트랜잭션을 사용하는 구절이 필요하다. 이것들은 테스트마다 중복될 것.
이 코드를 재사용 하도록 줄일 수 있다.
// Delegate defines a controller function.
private string Execute(
Func<UserController, string> func,
MessageBus messageBus,
IDomainLogger logger)
{
using (var context = new CrmContext(ConnectionString))
{
var controller = new UserController(context, messageBus, logger);
return func(controller);
}
}결과적으로 실행 구절에는 다음과 같은 코드만 사용할 것이다.
string result = Execute(
x => x.ChangeEmail(user.UserId, "new@gmail.com"),
messageBus, loggerMock.Object);검증 구절에서 코드 재사용하기
검증 구절에서도 준비 구절과 같이 검증할 데이터를 생성하는 부분을 헬퍼 메소드를 통해서 줄일 수 있다.
더 나아가서 기존 도메인 클래스 위에 플루언트 인터페이스 (fluent interface) 를 기반으로 검증할 수도 있다.
public static class UserExternsions
{
public static User ShouldExist(this User user)
{
Assert.NotNull(user);
return user;
}
public static User WithEmail(this User user, string email)
{
Assert.Equal(email, user.Email);
return user;
}
}이를 통해서 다음과 같이 검증할 수 있을 것이다.
User userFromDb = QueryUser(user.UserId);
userFromDb
.ShouldExist()
.WithEmail("new@gmail.com")
.WithType(UserType.Customer);테스트에 목을 적용할 때 고려할 사항
테스트 대역에서 목과 스텁이란?
테스트 대역의 정의를 먼저 보자면 테스트 대역은 '비운영용 가짜 의존성' 을 나타내는 모든 것들을 테스트 대역이라고 부른다.
테스트 대역의 종류는 크게 목 (Mock) 과 스텁 (Stub) 이렇게 두 종류가 있다.
목과 스텁의 가장 큰 차이는 목은 주로 외부로 나가는 상호작용을 검사하고 모방하는 반면에 스텁은 내부에 있는 상호작용을 모방하며 검사한다.
그래서 목은 주로 명령 (Command) 와 관련이 있고 스텁은 조회 (Query) 와 관련이 있다.
그리고 세부적으로는 목안에 목과 스파이가 있고 스텁 안에는 더미, 스텁, 페이크가 있는데 개념적으로 정리하면 다음과 같다.
- 스파이 (Spy): 목을 구현한 것으로 실제 호출에 대한 정보를 기록할 수 있다. 이를 테스트에서 검증할 수 있음. (ex. 데이터베이스와 같은 역할을 해서 정보를 저장해야 하는 경우.)
- 목 (Mock): 특정 메소드의 호출 여부와 인자가 기대한 대로 잘 전달되는지 검증할 때 사용된다. (ex. 메일 발송을 위한 상호작용을 검증해야 하는 경우)
- 더미 (Dummy): 테스트에서 사용되지 않지만 인자로 전달되야 하는 경우에 사용된다. (ex. 테스트에 필요하지 않은 인자의 경우)
- 스텁 (Stub): Mock 과 유사하지만 반환 값에 좀 더 관심이 있는 경우에 사용된다. (ex. 외부 API 를 테스트 하는 경우)
- 페이크 (Fake): 스텁과 같지만 아직 존재하지 않은 의존성임.
우리가 목과 스텁을 만들 때는 Mock Library 를 쓰는 경우가 많은데 그래서 그런지 보편적으로는 Mock 이라는 용어을 포괄적으로 쓰기도 한다.
스텁을 사용할 때 주의할 점으로는 상호작용을 검사하지 마라.
스텁은 내부 상호작용을 모방하는 용도로 사용하는데 이런 내부 상호작용은 변경될 가능성이 많다.
즉 좋은 테스트의 요소인 리팩터링 내성이 부족하다.
그러므로 웬만하면 스텁은 사용하지 말자.
목 처리에 대한 모범사례
여기서는 목을 사용할 때의 방법과 목의 가치를 극대화 하는 방법에 대해서 알아보겠다.
목을 사용할 수 있는 경우는 프로세스 외부 의존성 (비관리 의존성) 을 대체할 때, 즉 통합 테스트를 작성하는 경우에만 사용할 수 있다.
이 방침만 가지고 목을 쓰기에는 목의 가치를 최대한으로 이끌어 낼 수 없다.
목을 사용할 때는 시스템의 상호 작용 끝에서 사용하도록 하자.
이 말을 보다 정확하게 이해하기 위해서 예시를 준비했다.
예제 프로젝트는 사용자 등록을 처리하는 고객 관리 시스템 (CRM, Customer Management System) 이며 모든 사용자가 데이터베이스에 저장된다.
이 연산에는 세 가지 비즈니스 규칙이 있다.
- 사용자 이메일이 회사 도메인에 속한 경우 해당 사용자는 직원으로 표시된다. 그렇지 않으면 고객으로 간주한다.
- 시스템은 회사의 직원 수를 추적해야 한다. 사용자 유형이 직원에서 고객으로, 또는 그 반대로 변경되면 이 숫자도 변경해야 한다.
- 이메일이 변경되면 시스템은 메시지 버스로 메시지를 보내 외부 시스템에 알려야 한다.
public class UserController
{
private readonly Database _database;
private readonly EventDispatcher _eventDispatcher;
public UserController(
Database database,
IMessageBus messageBus,
IDomainLogger domainLogger)
{
_database = database;
_eventDispatcher = new EventDispatcher(messageBus, domainLogger);
}
public string ChangeEmail(int userId, string newEmail)
{
object[] userData = _database.GetUserById(userId);
User user = UserFactory.Create(userData);
string error = user.CanChangeEmail();
if (error != null)
return error;
object[] companyData = _database.GetCompany();
Company company = CompanyFactory.Create(companyData);
user.ChangeEmail(newEmail, company);
_database.SaveCompany(company);
_database.SaveUser(user);
_eventDispatcher.Dispatch(user.DomainEvents);
return "OK";
}
}유저의 이메일 변경사항을 프로세스 외부 의존성인 메시지 버스에 보내도록 한다.
이 메시지 버스는 목으로 대체할 수 있다.
그래서 우리는 통합 테스트를 이렇게 작성할 것이다.
[Fact]
public void Changing_email_from_corporate_to_non_corporate()
{
// Arrange
var db = new Database(ConnectionString);
User user = CreateUser("user@mycorp.com", UserType.Employee, db);
CreateCompany("mycorp.com", 1, db);
var messageBusMock = new Mock<IMessageBus>();
var loggerMock = new Mock<IDomainLogger>();
var sut = new UserController(
db, messageBusMock.Object, loggerMock.Object);
// Act
string result = sut.ChangeEmail(user.UserId, "new@gmail.com");
// Assert
Assert.Equal("OK", result);
object[] userData = db.GetUserById(user.UserId);
User userFromDb = UserFactory.Create(userData);
Assert.Equal("new@gmail.com", userFromDb.Email);
Assert.Equal(UserType.Customer, userFromDb.Type);
object[] companyData = db.GetCompany();
Company companyFromDb = CompanyFactory.Create(companyData);
Assert.Equal(0, companyFromDb.NumberOfEmployees);
messageBusMock.Verify(
x => x.SendEmailChangedMessage(
user.UserId, "new@gmail.com"),
Times.Once);
loggerMock.Verify(
x => x.UserTypeHasChanged(
user.UserId,
UserType.Employee,
UserType.Customer),
Times.Once);
}- 메시지를 날리는
MessageBus를 목으로 대체하고 상호작용을 검증한다.
MessageBus 의 구조를 한번 보자.
public interface IMessageBus
{
void SendEmailChangedMessage(int userId, string newEmail);
}
public class MessageBus : IMessageBus
{
private readonly IBus _bus;
public void SendEmailChangedMessage(int userId, string newEmail)
{
_bus.Send("Type: USER EMAIL CHANGED; " +
$"Id: {userId}; " +
$"NewEmail: {newEmail}");
}
}
public interface IBus
{
void Send(string message);
}MessageBus는IBus라는 메시지를 보내는 사용자 정의 Wrapper 클래스를 내부에 가지고 있다.- 여기서 IBus 는 메시지를 보낼 때 사용자 연결 자격 증명과 같은 세부적인 구현을 숨기기 위해서 작성한 클래스다.
- IMessageBus 는 IBus 를 좀 더 추상화해서 도메인과 관련된 정보를 남기도록 헀다.
이전에 말한 시스템의 상호 작용 끝에서 목을 사용해야 한다면 우리는 여기서 MessageBus 가 아닌 IBus 에 목을 사용해야한다.
그 이유로는 IBus 에서 목을 사용할 경우 코드 범위를 극한까지 검증하는게 가능하다.
또 다른 이유로는 결국에 메시지를 보내는 부분은 IBus 를 통해서 보낸다.
즉 MessageBus 보다 IBus 가 더 변경될 이유가 적다.
정리하자면 리팩터링 내성과 회귀방지 측면을 따져볼 때 시스템의 상호작용 끝에서 목을 쓰는게 좋다.
그렇다면 시스템의 끝은 어디까지일까?
일반적으로 프로세스 외부 의존성을 사용하는 경우 해당 의존성을 직접적으로 사용하는 경우보다 래핑 (Wrapping) 해서 사용하는 걸 권장한다.
이렇게하면 다양한 장점이 있다.
- 구현을 숨기는 캡슐화 측면
- 라이브러리의 업데이트나 변경에 따른 전파를 막을 수 있다는 측면
- 마지막으로 도메인 언어를 이용할 수 있다는 장점이 있다.
시스템의 끝은 이 래핑 클래스까지를 말한다.
이 래핑 클래스를 어댑터 (Adapter) 식으로 사용하도록 하고 이 어댑터를 목으로 대체하는 걸 권장한다.
목을 스파이로 대체하는 기법
목을 수동으로 작성한 걸 스파이라고 한다.
스파이는 목을 검증할 때 일반 목보다 나을 수 있는데 예시로 보자.
위의 IBus 를 스파이로 구현한 예시다.
public class BusSpy : IBus
{
private List<string> _sentMessages = new List<string>();
public void Send(string message)
{
_sentMessages.Add(message);
}
public BusSpy ShouldSendNumberOfMessages(int number)
{
Assert.Equal(number, _sentMessages.Count);
return this;
}
public BusSpy WithEmailChangedMessage(int userId, string newEmail)
{
string message = "Type: USER EMAIL CHANGED; " +
$"Id: {userId}; " +
$"NewEmail: {newEmail}";
Assert.Contains(
_sentMessages, x => x == message);
return this;
}
}[Fact]
public void Changing_email_from_corporate_to_non_corporate()
{
var busSpy = new BusSpy();
var messageBus = new MessageBus(busSpy);
var loggerMock = new Mock<IDomainLogger>();
var sut = new UserController(db, messageBus, loggerMock.Object);
/* ... */
busSpy.ShouldSendNumberOfMessages(1)
.WithEmailChangedMessage(user.UserId, "new@gmail.com");
}즉 스파이를 통해서 좀 더 꼼꼼한 검증을 하는게 가능해지고 추상화를 시킬 수 있다.
목 검증할 때 주의사항
목을 검증할 땐 상호작용을 했다. 정도만 검증하지 말고 더 자세하게 검증하도록 하자.
예상하는 호출이 있는가? 를 넘어서 예상하지 못한 호출은 없는지 에 대한 검증도 필요하다.
즉 모킹한 메소드를 몇 번 호출헀다던지, 해당 메소드 외의 따른 메소드는 호출하지 않았다던지 등을 검증하도록 하자.
데이터베이스 테스트
통합 테스트에서는 데이터베이스를 목으로 사용하지 않고 실제로 접근해서 사용한다.
이렇게 사용할 때 준비하기 위한 전제들을 먼저 보고 그 후에 데이터베이스에서 테스트를 할 때 유의해야 할 사항들에 대해서 알아보자.
데이터베이스 테스트 전제 조건
1) Git 과 같은 형상 관리 시스템에 데이터베이스 스키마를 기록하는 것.
- 히스토리를 알 수 있도록 해야한다.
2) 개발자를 위해 데이터베이스 인스턴스를 개발자 머신에서 사용하는 것.
- 데이터베이스를 공유해서 사용하면 문제가 생길 여지가 많음. 주로 데이터베이스에서의 테스트는 데이터베이스에 들어간 데이터를 기반으로 테스트하기 때문에.
3) 데이터베이스 배포에 마이그레이션 기반 방식을 사용하는 것.
- 마이그레이션 방식을 사용하면 데이터 모션 문제를 방지할 수 있다. 데이터 모션은 새로운 데이터 스키마를 따르도록 하는 문제다.
데이터베이스 트랜잭션 관리
어플리케이션에서 데이터베이스와 관련된 작업을 할 땐 데이터베이스 작업 단위인 트랜잭션을 고려해야한다.
여기서 고려해야 한다는 건 원자적 (Atomic) 한 연산을 어디까지 보장할 것인가? 를 묻는 것이다.
예로 고객이 회사 이메일로 변경하면 이메일 변경 작업과 회사 이메일을 사용하는 고객의 수를 증가하는 작업은 같이해야 한다.
이를 별도의 트랜잭션으로 관리하면 데이터 모순이 일어날 수 있다.
트랜잭션을 관리하면 또 불필요한 데이터베이스 호출이 줄어들어서 좋다.
통합 테스트에서도 트랜잭션을 사용할 때 주의해야 할 점은 다음과 같이 트랜잭션을 재사용하면 안된다.
[Fact]
public void Changing_email_from_corporate_to_non_corporate()
{
using (var context = new CrmContext(ConnectionString))
{
// Arrange
var userRepository =
new UserRepository(context);
var companyRepository =
new CompanyRepository(context);
var user = new User(0, "user@mycorp.com",
UserType.Employee, false);
userRepository.SaveUser(user);
var company = new Company("mycorp.com", 1);
companyRepository.SaveCompany(company);
context.SaveChanges();
var busSpy = new BusSpy();
var messageBus = new MessageBus(busSpy);
var loggerMock = new Mock<IDomainLogger>();
var sut = new UserController(
context,
messageBus,
loggerMock.Object);
// Act
string result = sut.ChangeEmail(user.UserId, "new@gmail.com");
// Assert
Assert.Equal("OK", result);
User userFromDb = userRepository
.GetUserById(user.UserId);
Assert.Equal("new@gmail.com", userFromDb.Email);
Assert.Equal(UserType.Customer, userFromDb.Type);
Company companyFromDb = companyRepository
.GetCompany();
Assert.Equal(0, companyFromDb.NumberOfEmployees);
busSpy.ShouldSendNumberOfMessages(1)
.WithEmailChangedMessage(user.UserId, "new@gmail.com");
loggerMock.Verify(
x => x.UserTypeHasChanged(
user.UserId, UserType.Employee, UserType.Customer),
Times.Once);
}
}일반적으로 제품 코드는 트랜잭션을 사용하고 폐기한다. 하지만 여기서는 여러 검증 구문에서 트랜잭션을 재사용하고 있다.
ORM 같은 도구를 사용할 경우 성능을 위해서 캐시로 데이터를 보관하는 경우가 있는데 이러면 데이터베이스에 보관된 데이터 상태를 테스트하지 않는 문제가 생긴다.
그러므로 별도의 트랜잭션을 적용하는게 좋다.
테스트 데이터 생명주기
통합 테스트에서 데이터베이스를 공용으로 사용할 경우 각 통합 테스트는 서로 분리하기 어렵다.
각 통합 테스트마다 데이터를 지우고 넣고를 반복하면서 영향을 줄 수 있기 떄문에.
그러므로 통합 테스트는 조금 느리더라도 순차적으로 실행해야 한다.
또 통합 테스트는 데이터베이스 데이터의 상태에 의존하지 않도록 해줘야 한다.
그러므로 데이터를 늘 데이터베이스에서 지워줘야 하는데 이는 테스트를 시작할 때 지우는게 가장 좋다.
테스트 마지막에 지우는 방법도 생각해볼 수 있는데 이는 중간에 작업이 실패하면 더미 데이터가 데이터베이스에 남게 되는 문제가 생긴다.
다른 얘기로 성능의 문제 때문에 운영 환경의 데이터베이스 대신에 인메모리 데이터베이스를 사용하는 경우가 많은데 추천하지 않는다. (똑같은 환경을 맞추는게 유의미하기 때문에.)
데이터베이스 테스트에 대한 일반적인 질문들
읽기 테스트를 해야하는가?
일반적으로 읽기 작업보다는 쓰기 작업이 중요하다. 잘못된 데이터가 들어갔을 때 생기는 버그가 더 크기 때문에.
그리고 읽기 작업은 도메인 클래스 레이어와 협력할 일이 없다.
일반적으로 읽기 작업은 성능을 고려한 쿼리로 짜는 경우가 많기 떄문에.
그래서 읽기 작업만을 위한 테스트 보다는 통합 테스트로 가는게 훨씬 낫다. 아니면 가장 중요한 읽기 테스트만 테스트하자.
리포지터리 테스트를 해야하는가?
이것도 결론만 말하면 통합 테스트로 포함시키는게 훨씬 낫다.
리포지토리 테스트는 간단한 테스트라서 가치가 별로 없기도 하고
단위 테스트 안티패턴
여기서는 단위 테스트의 안티패턴의 몇가지 예시를 소개하겠다.
비공개 메소드 단위 테스트
비공개 메소드만을 위한 단위 테스트를 작성하는 건 올바르지 않다.
주로 구현의 세부사항과 관련 있어서 좋은 테스트의 요소인 리팩터링 내성이라는 지표가 부족하기 때문이다.
계속해서 말하지만 단위 테스트는 식별할 수 있는 동작 단위로 검증을 해야한다.
근데 만약에 식별할 수 있는 동작 단위로 단위 테스트를 짰는데 비공개 메소드에서는 충분한 커버리지를 보여주지 못하고 있고 비공개 메소드가 복잡하며 중요한 로직을 포함하고 있다면 어떻게 해야할까?
비공개 메소드만을 위한 테스트를 작성해야 할까?
아니다. 이 상황 자체가 문제인데 충분한 커버리지가 나오지 않고 있다면 필요없는 코드가 있을 수 있다.
또 다른 문제로 비공개 메소드가 복잡하고 중요한 로직을 포함하고 있다면 그건 추상화가 충분히 되지 않은 코드일 수 있다.
그러므로 다른 클래스로 뺴서 협력하도록 해야한다.
비공개 메소드의 테스트가 타당한 경우는 비공개 메소드 자체가 식별할 수 있는 동작일 때이다.
이게 이해가 되지 않을 수 있는데 ORM 같은 도구를 사용하면 데이터베이스에서 조회한 후 객체를 생성해주니까 도메인 모델은 비공개 생성자로 해두는 경우가 있다.
이러면 이 객체는 직접 생성할 수 없으므로 테스트하기 어려워진다. 이런 경우는 리플렉션을 통해서 테스트 해도 된다.
물론 비공개 생성자를 공개 생성자로 바꿔도 충분히 문제가 되지 않기 때문에 돌려도 된다.
비공개 상태 노출
어떠한 동작 후에 비공개 상태가 변경되었고 이를 테스트하고 싶다.
이때는 어떻게 해야할까?
테스트를 위해서 이 비공개 상태를 공개 상태로 바꾸는 건 캡슐화를 위반하는 행동이다.
이때는 비공개 상태를 이용하는 식별할 수 있는 동작을 기반으로 테스트를 검사하면 된다.
즉 다음과 같은 에시를 기준으로는 promote() 메소드 호출 후 상태가 변경될 것인데 이때는 GetDiscount() 메소드를 통해서 변경된 상태에 따른 동작을 검증해보면 된다.
public class Customer
{
private CustomerStatus _status = CustomerStatus.Regular;
public void Promote()
{
_status = CustomerStatus.Preferred;
}
public decimal GetDiscount()
{
return _status == CustomerStatus.Preferred ? 0.05m : 0m;
}
}
public enum CustomerStatus
{
Regular,
Preferred
}테스트로 유출된 도메인 지식
도메인 지식과 세부 구현 사항을 테스트로 노출하는 것도 또 하나의 안티 패턴이다.
다음과 같이 계산 알고리즘이 있고 이를 테스트하는 예를 보자.
public static class Calculator
{
public static int Add(int value1, int value2)
{
return value1 + value2;
}
}public class CalculatorTests
{
[Fact]
public void Adding_two_numbers()
{
int value1 = 1;
int value2 = 3;
int expected = value1 + value2; // 구현 노출
int actual = Calculator.Add(value1, value2);
Assert.Equal(expected, actual);
}
}- 여기서
expected값을 만드는 곳에서 세부 구현이 노출되고 있다. 즉 리팩터링 내성이 없어지는 문제가 생긴다.
이런 경우에는 검증할 값을 그냥 하드 코딩으로 명시하는 것이 좋다. 객체인 경우에는 직접 만들던가.
public class CalculatorTests
{
[Theory]
[InlineData(1, 3, 4)]
[InlineData(11, 33, 44)]
[InlineData(100, 500, 600)]
public void Adding_two_numbers(int value1, int value2, int expected) {
int actual = Calculator.Add(value1, value2);
Assert.Equal(expected, actual);
}
}코드 오염
제품 코드안에 테스트를 위한, 테스트 환경을 위한 코드가 있다면 이것도 안티 패턴이다.
이런 코드는 혼란을 줄 수 있고 유지비용을 높인다.
구체 클래스를 목으로 처리하기
지금까지 목을 사용하는 방법은 인터페이스를 목으로 처리하는 방법이다.
하지만 클래스의 경우에도 목으로 처리할 수 있다.
이를 통해 불필요한 기능은 구현하고 필요한 기능은 그대로 사용하는 방식을 적용할 수 있다.
하지만 이렇게 목을 통해 구체 클래스를 처리한다는 자체가 SRP 를 위반하고 있다는 뜻이기도 하다.
해당 객체의 기능이 많으니까 이런식으로 목으로 처리하는 것이다.
이 경우에는 클래스를 쪼개면 된다. 예시로보자.
public class StatisticsCalculator
{
public (double totalWeight, double totalCost) Calculate(
int customerId)
{
List<DeliveryRecord> records = GetDeliveries(customerId);
double totalWeight = records.Sum(x => x.Weight);
double totalCost = records.Sum(x => x.Cost);
return (totalWeight, totalCost);
}
public List<DeliveryRecord> GetDeliveries(int customerId)
{
/* 프로세스 외부 의존성을 용한 기능으로 부작용을 야기할 수 있는 메소드 */
}
}StatisticCalculator는 특정 고객에게 배달된 모든 배송들의 무게와 비용 같은 고객 정보 통계를 수집하고 계산한다.- 이 클래스를 목으로 대체할 때, 프로세스 외부 의존성을 사용하는
GetDeliveries()기능만을 대체한다.
통합 테스트를 작성할 때 해당 객체를 그대로 넣는다면 부작용을 일으킬 수 있다. 그래서 목으로 대체해야 한다고 생각할 수 있다.
하지만 이렇게 하는 경우는 SRP 를 위반하는 거니까 이 문제는 프로세스 외부 의존성을 사용하는 부분을 객체로 쪼개서 처리하면 된다.
코드로 보자.
public class DeliveryGateway : IDeliveryGateway
{
public List<DeliveryRecord> GetDeliveries(int customerId)
{
/* Call an out-of-process dependency
to get the list of deliveries */
}
}
public class StatisticsCalculator
{
public (double totalWeight, double totalCost) Calculate(
List<DeliveryRecord> records)
{
double totalWeight = records.Sum(x => x.Weight);
double totalCost = records.Sum(x => x.Cost);
return (totalWeight, totalCost);
}
}이렇게 하면 IDeliveryGateway 를 목으로 대체해서 사용하면 깔끔하게 구현하는게 가능하다.
시간 처리하기
시간 같은 특정 시점에 따라서 값이 달라지는 경우는 테스트하기 어렵다.
특히 정적 필드나 정적 메소드 (= LocalDateTime.now()) 와 같은 메소드를 이용할 때 특히 어렵다.
이 경우에 해결 방법은 다음과 같다.
- 시간을 만들어주는 서비스를 만들고 의존성으로 넣어준다. 그리고 이 서비스를 통해서 시간을 생성하도록 만든다. (대체하기 쉽다.)
- 메소드를 리팩터링해서 메소드의 인자로 시간을 받도록 한다.



아무리 봐도 평범한 개발자는 아닌 것 같네요 ..