실시간 스트리밍 데이터 처리에서 중요한 것
실시간 스트리밍 데이터 처리에서 한 번만 정확하게(exactly-once) 처리하는 것은 중복 데이터 처리와 데이터 손실을 방지하고 분석 결과가 왜곡되지 않도록 하는 데 중요하다.
What is Exactly-Once for Stream Processing?
정의 자체는 이렇다.
for each received record, its processed results will be reflected once, even under failures.
- 실패나 장애가 일어난 상황에서도 정확하게 한 번 처리하는 것.
Kafka Streams 는 어떻게 exactly-once 로 처리할 수 있을까?
processing.guarantee=exactly_once 설정만 하면 Kafka Streams 는 자동으로 정확히 한 번 처리하는게 가능해진다. default value 는 at_least_once 이다.
Exactly-Once: Why is it so Hard?
Kafka Streams 의 message 처리 방식은 다음과 같다.
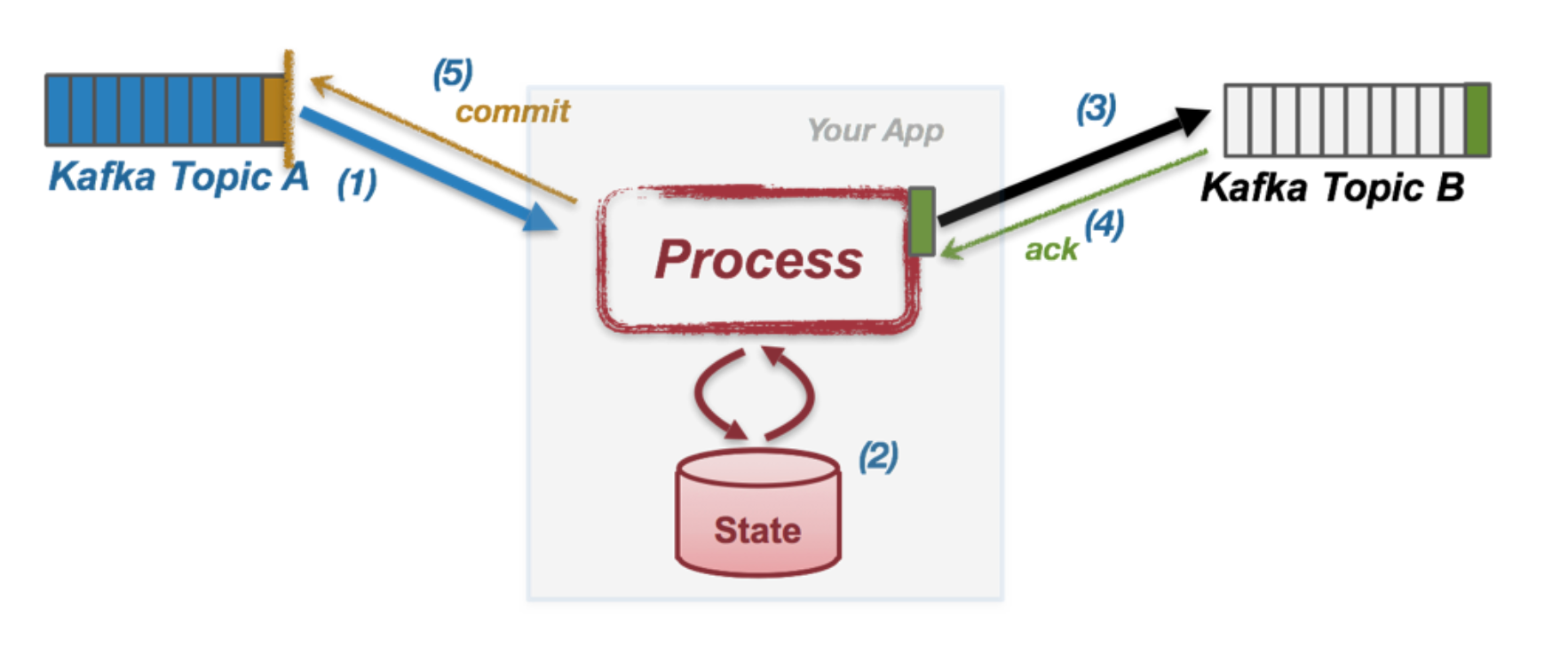
1) Kafka Topic 으로 부터 message A 를 읽는다.
2) processing function 이 트리거 되서 기존 상태 S 를 S' 으로 업데이트 시킨다.
3) output message B1~Bn 까지 만들어서 output kafka topic 에다가 쓴다.
4) Kafka Broker 로 부터 send 요청에 대한 응답을 기다린다.
5) 처리된 message A 에 commit 한다. 메시지 A 는 완전히 처리된 것.
여기서 (4) 과 (5) 쪽에 문제가 생긴다면 exactly-once 로 처리하기 어려워진다. 다음 예시를 보자.
Failure Scenario #1: Duplicate Writes

- output Topic 으로의 쓰기 요청 이후 네트워크 상황이 잠시 안좋아서 ack 를 못받았다고 가정해보자.
- retry 를 통해서 재전송할 것이고 이로인해서 topic 에 같은 결과물이 여러개가 생길 수 있다.

Failure Scenario #2: Duplicate Processing & Duplicate Writes

(4) 까지의 작업이 완료되고 source Topic 에 commit 을 하려고 할 때 App 이 갑자기 죽는다면 어떻게 될까?
commit 을 하지 못하고 죽었기 때문에 다시 해당 메시지를 처리한다. 그래서 processing 도 두 번 일어나서 상태도 두 번 업데이트 되고 output topic 에다가도 두 번 쓰게되는 문제가 생긴다.
How Kafka Streams Guarantees Exactly-Once Processing
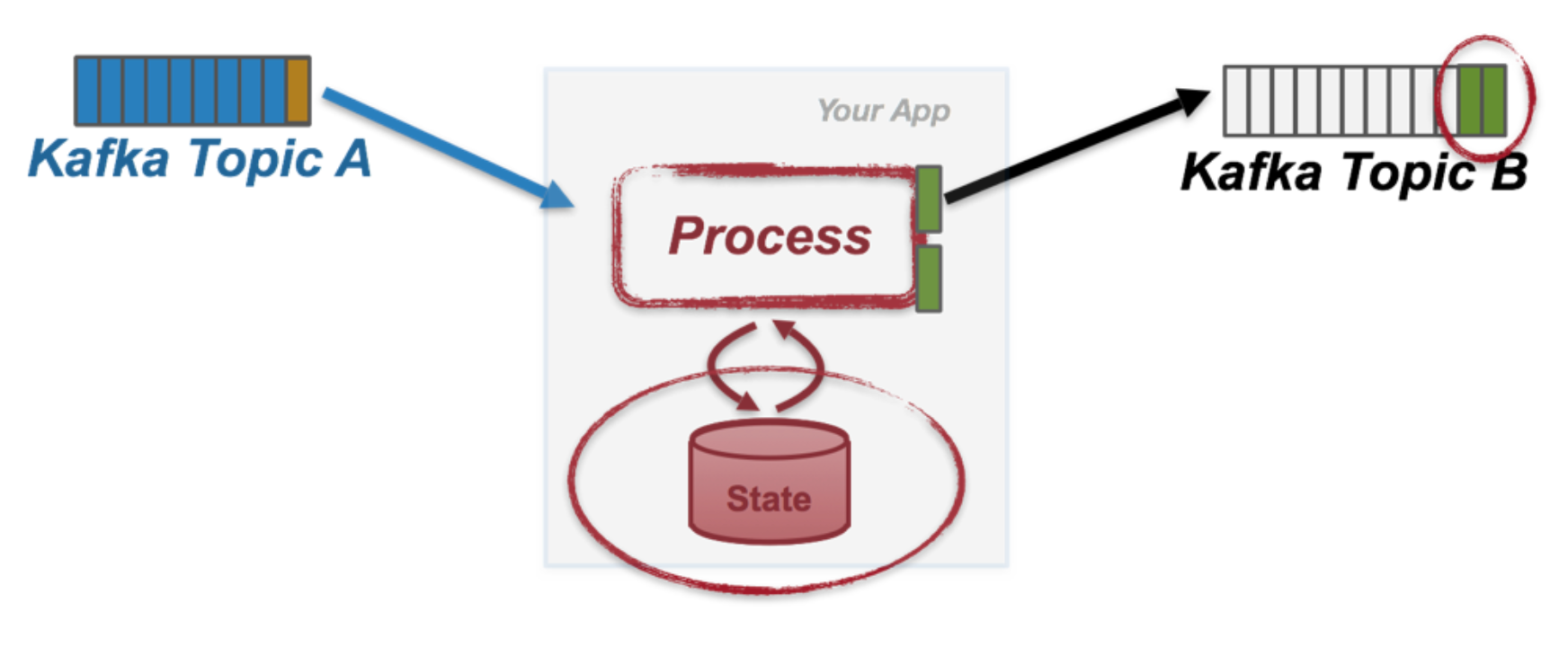
결국에 exactly-once 를 보장하려면 다음 3가지 step 을 트랜잭션으로 보장되면 된다.
- Update the application state from S to S`
- Write result messages B1, … Bn to output Kafka topic(s) TB.
- Commit offset of the processed record A on the input Kafka topic TA
이 세가지 일을 다 성공시키거나 하나라도 실패하면 다 롤백 시키면 된다.
어떻게 그게 가능할까? 위 세가지 작업은 다 토픽으로 데이터를 전송하는 과정으로 변환시켜 볼 수 있다.
Update the application state from S to S->Kafka changelog topicWrite result messages B1, … Bn to output Kafka topic(s) TB.->Kafka sink topicCommit offset of the processed record A on the input Kafka topic TA->Kafka offset topic
Kafka changelog 에 기록하는 작업은 모든 state 들을 capture 해서 changelog 에 보관하는 작업이다.
새롭게 상태가 업데이트 될 때마다 그것들을 기록해놓는 것. 이 세가지 topic partition 에다가 offset 을 쓰는 것은 Kafka 의 Transactional API 를 쓰면 가능하다.
Transactional API 를 쓰려면 프로듀서를 트랜잭션 프로듀서로 올려서 설정해야한다. (이런 이유로는좀비 어플리케이션이 생겨서 중복 데이터를 만드는 문제를 막기 위함과 트랜잭션 메시지 처리는 일반 메시지 처리와는 다르기 때문이다.)
Kafka Streams 에서 processing.guarantee=exactly_once 이 설정을 키면 내부적인 embedded producer client 가 transaction.id 를 이용해서 atomic 하게 모든 토픽 파티션에 쓰게 보장해준다.
- 만약 일시적인 network 장애가 일어났다면
idempotent producer로 인해서 duplicate message 는 버려지게 된다. - 만약 치명적인 error 가 발생했다면 exception 을 던지기 전에 카프카는 해당 트랜잭션을 abort 한다. 이로 인해서 같은 transaction.id 를 재시작할 수 있다.

자바 코드로 보면 이렇다.
/** when commit() is called */
try {
// send the offsets to commit as part of the txn
producer.sendOffsets(“inputTopic”, offsets);
// commit the txn
producer.commitTxn();
} catch (KafkaException e) {
producer.abortTxn();
}
/** in the normal processing loop */
try {
recs = consumer.poll();
for (Record rec <- recs) {
// process ..
producer.send(“outputTopic”, ..);
producer.send(“changelogTopic”, ..);
}
} catch (KafkaException e) {
producer.abortTxn();
}How transactional work in Kafka
Kafka 의 트랜잭션 API 가 어떻게 동작하는지 보자.
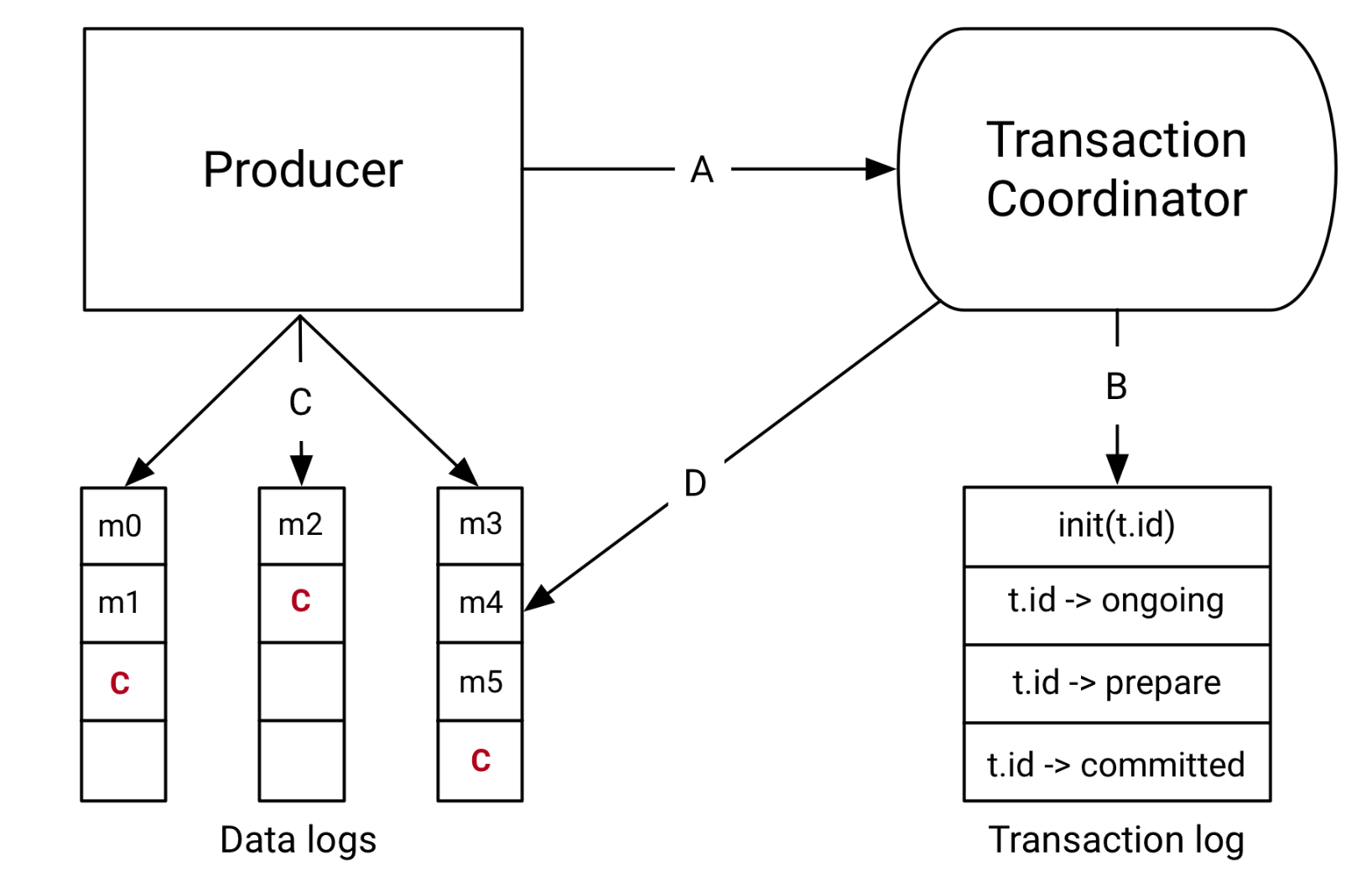
- Transaction log 는 Kafka 토픽 중 하나다. 제일 최신 transaction 의 상태를 보관하는 역할을 한다. 여기에 보내는 메시지를 보관하는게 아니다. 메시지는 Topic-Partition 에 저장된다.
- Transaction Coordinator 는 Kafka Broker 에서 실행되는 모듈로 Transaction.log 를 읽고 쓰는 관리하는 역할을 한다.
A) the producer and transaction coordinator interaction
- 트랜잭션을 시작할 때 producer 는 coodinator 에게 트랜잭션 시작을 등록하는 request 를 날린다.
- transaction.id 를 coordinator 에게 등록시킨다. 이런 과정을 통해서 하나의 트랜잭션만 실행되도록 보장해준다. 장애가 나서 pending 된 트랜잭션 같은 경우는 이 시점에 정리된다.
- producer 가 데이터를 보낼 파티션도 이 시점에 coordinator 에게 등록된다.
B) the coordinator and transaction log interaction
- transaction 이 진행됨에 따라서 coordinator 는 트랜잭션의 상태를 업데이트 한다. 오로지 coordinator 에 의해서 transaction 상태가 업데이트 됨.
- 물론 이 요소도 replication 된다. 그래서 broker 가 장애가나도 복구가 가능함.
C) the producer writing data to target topic-partitions
- producer 는 coordinator 에게 등록한 여러 partition 에 데이터를 보낸다.
D) the coordinator to topic-partition interaction
- producer 가 데이터를 다 보내고 commi() 요청을 보내면 coordinator 는 two-phase-commit 을 통해서 작업을 완료한다.
- 첫 번째로 트랜잭션의 상태를
prepare_commit으로 업데이트 한다. 일단 이게 되면 트랜잭션은 완료될 수 있다. - 두 번째로 transaction coordinator 는 topic-partition 에 있는 데이터에 commit marker 를 남긴다. 이렇게하면 consumer 가 commit 된 데이터를 읽을 수 있다. (commit 된 데이터와 rollback 된 데이터를 구별할 수 있다!)
- consumer 는 isolation level 을 read_committed 로 설정하면 커밋된 데이터만 읽을 수 있다.
- 첫 번째로 트랜잭션의 상태를
two-phase-commit 을 하는 이유로는 트랜잭션 처리의 내구성을 보장하기 위함이다. 트랜잭션 코디네이터는 commit marker 를 남기던 중에 언제든지 죽을 수 있다. 이런 경우에 복구했을 때 트랜잭션 처리를 완료하기 위함이다.
Idempotence: Exactly-once in order semantics per partition
카프카에서 트랜잭션을 위해선 이런 멱등성 프로듀서를 통해서 데이터를 정확하게 한번 토픽에다가 메시지를 보내놓는 것으로부터 시작된다. 토픽에 데이터가 들어있다면 이후부터는 Transaction API 를 통해서 트랜잭션 처리를 하면 되니까.
idempotent operation 은 producer 레벨에서 데이터를 한 번만 정확하게 보낼 수 있도록 하는 기능이다. 만약 producer 가 topic-partition 에 데이터를 보냈는데 broker 로 부터 응답을 늦게 받았다고 가정해보자.
그럼 producer 는 retry 를 재개할 것이고 topic paritition 에 데이터가 중복으로 쌓일 수 있다. 이를 막기 위한 기능으로 idempotent 기능이 추가되었다. producer 에 설정으로 `enable.idempotence = true` 를 설정하면 해당 기능이 자동으로 써진다.
어떻게 그럼 중복 Write 를 막을 수 있을까? 이는 TCP 의 처리방식괴 유사하다. Broker 로 보내는 각각의 batch message 에 sequence Number 를 붙혀서 중복인 메시지는 버리는 방식으로 해결한다.
TCP 와의 차이점은 해당 sequence Number 는 replication 되기 때문에 broker 가 죽어도 이 number 는 계속해서 유지할 수 있다.
