
Apache Kafka Data Model
카프카가 고성능, 고가용성 메시징 어플리케이션으로 발전한 데는 토픽과 파티션이라는 데이터 모델의 역할이 컸다.
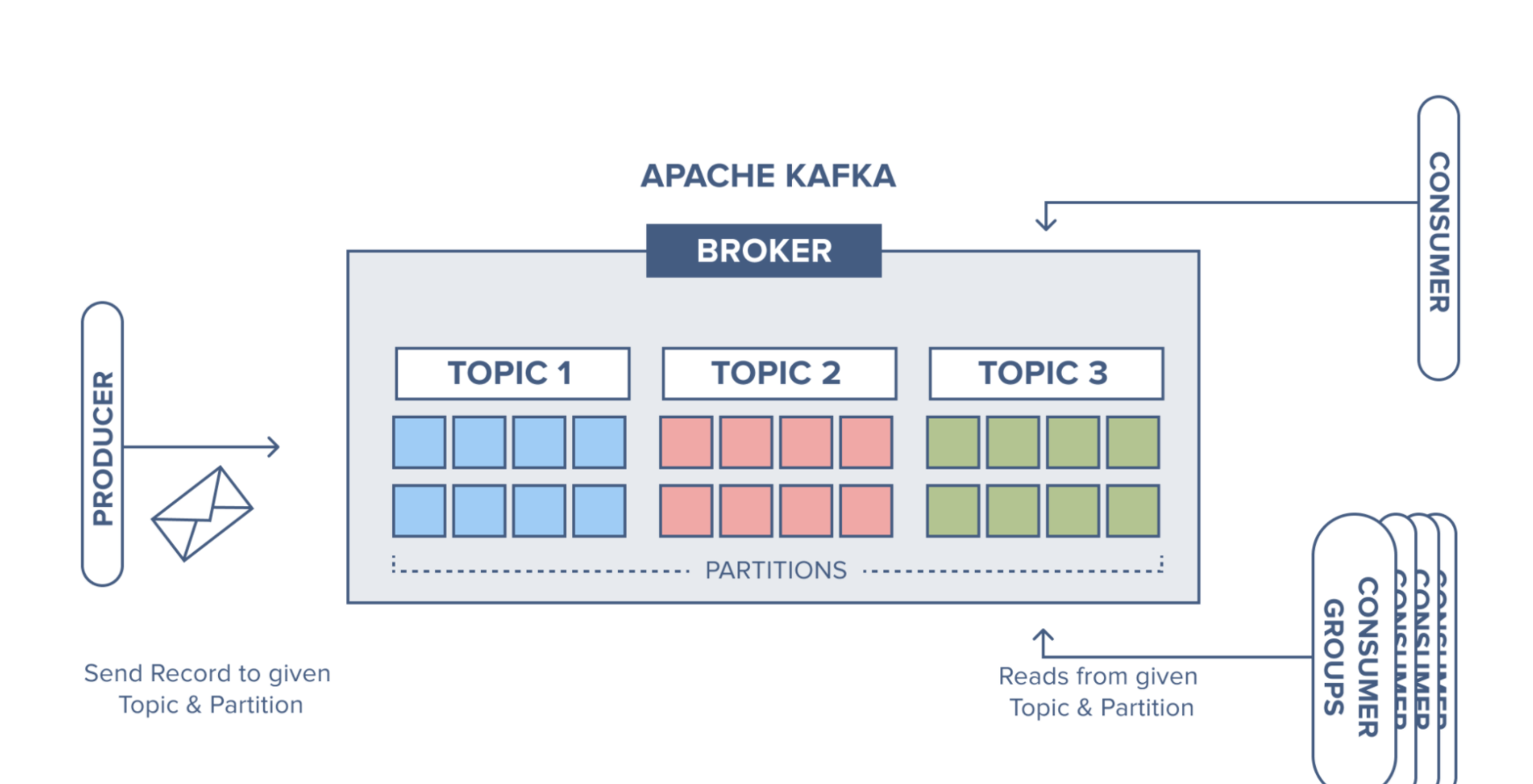
토픽은 메시지를 받을 수 있도록 하는 논리적으로 묶은 개념이라면 파티션은 토픽의 메시지를 저장하는 곳으로 스케일 아웃을 할 수 있다.
토픽의 이해
카프카 클러스터는 토픽이라 불리는 곳에 데이터를 저장한다. 이를 메일 시스템과 비교해보자면 토픽은 메일주소라고 생각하면 쉽다.
이렇듯 카프카에서는 데이터를 구분하기 위한 단위로 토픽이라는 용어를 사용한다.
토픽 이름은 249자 미만으로 영문, 숫자, '.', '_', '-' 를 조합해서 자유롭게 만들 수 있다.
카프카 클러스터는 하나의 서비스에 독립적으로 사용하는 게 아니라 여러 서비스에서 공통적으로 사용할 것이므로 토픽 이름에 접두어로 서비스 명을 추가해 다른 서비스에서 사용하는 토픽 이름과 중복을 피할 수도 있다.
토픽 이름 규칙 예
| 토픽 이름 | 토픽 설명 |
|---|---|
| sbs-news | sbs에서 뉴스 용도로 사용하는 토픽 이름 |
| sbs-video | sbs에서 동영상 용도로 사용하는 토픽 이름 |
| kbs-news | kbs에서 뉴스 용도로 사용하는 토픽 이름 |
| kbs-video | kbs에서 동영상 용도로 사용하는 토픽 이름 |
파티션의 이해
카프카에 파티션이란 토픽을 분할한 것이다. 그렇다면 왜 하나의 토픽을 파티셔닝 하는 걸까?
하나의 프로듀서가 카프카의 뉴스 토픽으로 4개의 메시지를 전송하는 과정을 생각해보자. 메시지를 보내는 데 걸리는 시간은 1초라고 가정을 한다면 메시지를 순서대로 보낼 것이므로 총 4초가 걸릴 것이다.
이를 위해 좀 더 효과적으로 보내기 위해서는 어떻게 해야할까? 프로듀서를 4개로 늘려보면 각각의 메시지를 프로듀서가 하나씩 보낼 것이므로 1초가 걸린다고 생각할 수 있다.
일반적인 분산 시스템의 경우에는 이 경우 4배의 성능을 보장할 수 있지만 메시징 큐 시스템의 경우에는 메시지의 순서를 보장해야 한다. 그러므로 다시 메시지의 순서를 보장하기 위해서 4초가 걸릴 것이다.
결국 카프카에서 효율적인 메시지 전송과 속도를 높이려면 토픽의 파티션 수를 늘려야 한다. 프로듀서 4개 파티션 4개라면 한번에 전송을 할 수 있으므로 1초가 소요될 것이다.
무조건 파티션 수를 늘려야 하나?
토픽의 파티션 수를 무조건 많이 늘려주는 것은 좋지 않다. 오히려 악영향을 미칠 수 있다. 이런 것은 어떠한 것들이 있는지 알아보자.
그림. Apache Kafka Broker Architecture
장애 복구 시간 증가
카프카는 높은 가용성을 위해 리플리케이션을 지원한다. 브로커에는 토픽이 있고 토픽은 여러 개의 파티션으로 나눠진다.
그러므로 브로커에는 여러 개의 파티션이 존재한다고 생각하면 된다.
또한 각 파티션마다 리플리케이션이 동작하므로 하나의 파티션은 리더일 것이고 다른 파티션은 팔로우일 것이다.
만약 여기서 브로커가 다운된다면 해당 브로커에 리더가 있는 파티션은 일시적으로 사용할 수 없게 된다.
카프카는 리더를 팔로워 중 하나로 이동시켜 클라이언트 요청을 처리할 수 있게 해야한다.
이와 같은 장애 처리는 컨트롤러로 지정된 브로커가 수행한다. 컨트롤러는 카프카 클러스터 내 하나만 존재하고 만약 컨트롤러 역할을 수행하는 브로커가 죽는다면 살아 있는 브로커 중 하나가 자동으로 컨트롤러 역할을 대신한다.
만약 브로커에 1,000개의 파티션이 있고 2개의 리플리케이션이 있는 브로커가 갑자기 종료된다면 일시적으로 이 브로커에 있는 1,000개의 파티션은 사용할 수 없다.
게다가 파티션의 리더를 다른 브로커가 있는 곳으로 이동시켜야 하는데 만약 컨트롤러가 각 파티션 별로 새로운 리더를 선출하는데 5밀리초의 시간이 소요된다고 가정하면 1,000개의 모든 파티션에 대해 새로운 리더를 선출하는 데는 총 5초가 소요되며 일부파티션의 경우 장애 시간은 5초 이상일 수도 있다.
최악의 상황으로 다운된 브로커가 컨트롤러의 경우라면 컨트롤러가 살아있는 브로커에게 완전히 넘어가기 전까지 새로운 리더를 선출할 수 없다.
컨트롤러의 페일오버(failover)는 자동으로 동작해서 새 컨트롤러를 초기화하는 동안 주키퍼에서는 모든 파티션의 데이터를 읽어와야 한다. 그러므로 파티션이 많을수록 읽는 시간이 길어진다.
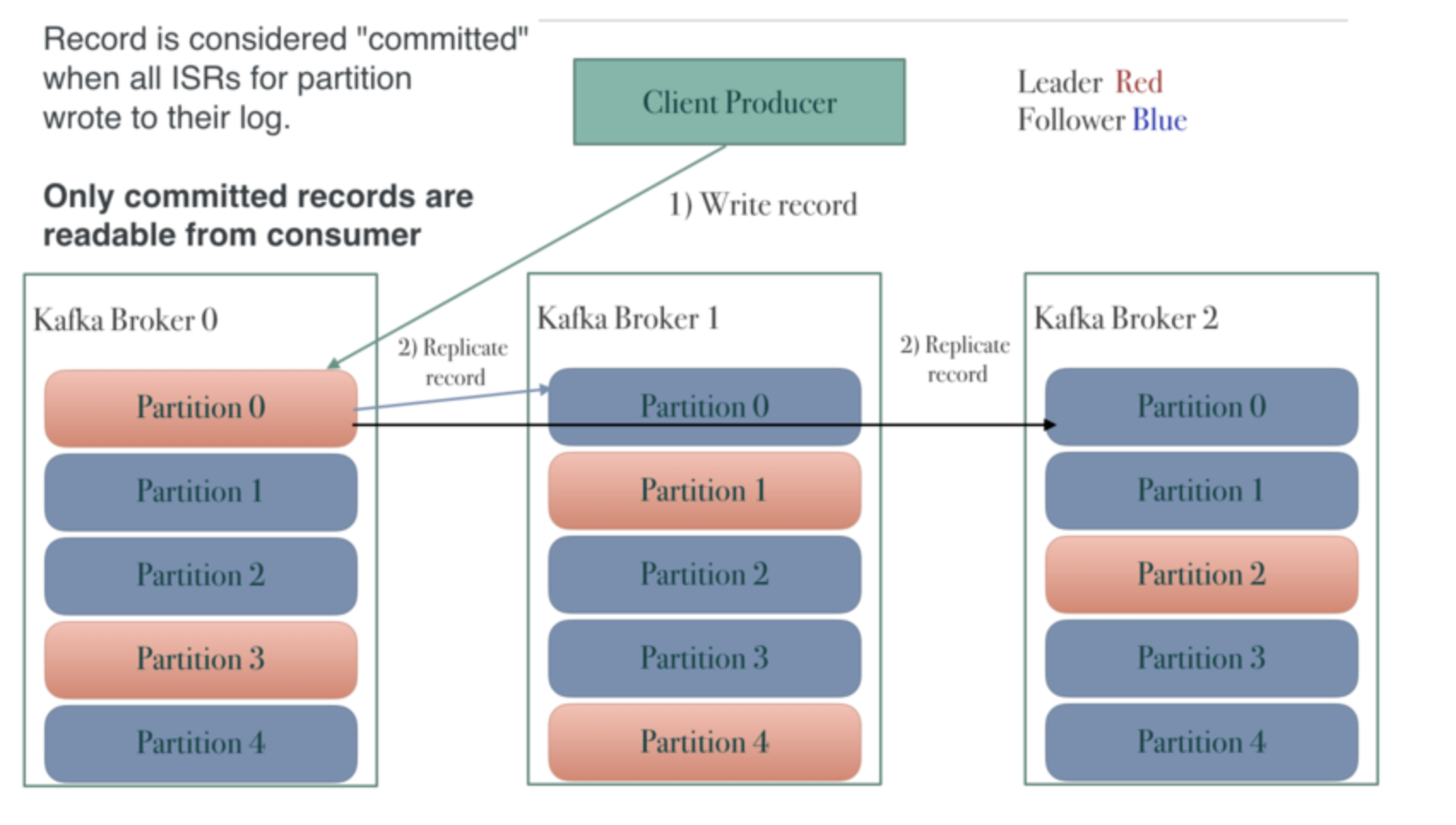
그림. Kafka Architecture: Kafka Replication
파일 핸들러 낭비
각 파티션은 브로커의 디렉토리와 매핑되고 저장되는 데이터마다 2개의 파일(인덱스 파일, 실제 파일)이 있다.
카프카에서는 모든 디렉토리의 파일들에 대한 파일 핸들을 열게 된다. 결국 파티션이 많아지면 파일 핸들 수 역시 많아지게 되므로 리소스 낭비가 심해진다.
내 토픽의 적절한 파티션 수는
그럼 토픽의 정확한 파티션 수는 어떻게 게산하는가?
먼저 토픽의 파티션 수를 정할 때 원하는 목표 처리량 기준을 잡아야 한다. 프로듀서 입장에서 4개의 프로듀서에서 각각 초당 10개의 메시지를 카프카의 토픽으로 보낸다고 하면 카프카의 토픽에서 초당 40개의 메시지를 받아줘야 한다.
이를 위해서는 파티션을 4로 늘려줘서 목표치를 달성할 수 있게 해야한다.
하지만 카프카에서는 컨슈머도 있기 때문에 컨슈머의 입장도 고려해야 한다. 컨슈머 입장에서는 8개의 컨슈머가 각각 초당 5개의 카프카의 토픽에서 가져올 수 있다면 해당 토픽의 파티션 수는 컨슈머 수와 동일하게 8개로 맞춰서 컨슈머마다 각각의 파티션에 접근할 수 있게 해야한다.
여기서 파티션과 관련한 주의사항을 하나 알리자면 카프카에서 파티션의 수의 증가는 필요한 경우에 아무때나 가능하지만 반대로 파티션의 수를 줄이는 방법은 없다. 너무 과도하게 파티션 수를 늘려놓고 난 후에 파티션 수를 줄이고 싶으면 토픽을 삭제하는 방법 말고는 없다. 그러므로 병목 현상이 일어날 때마다 조금씩 파티션 수와 프로듀서 또는 컨슈머 수를 늘려가는 방법으로 파티션 수를 할당하는게 좋다.
Apache Kafka High Availability and Replication
카프카는 분산 애플리케이션으로 서버의 물리적 장애가 발생하는 경우에도 높은 가용성을 보장한다.
이를 위해 카프카는 리플리케이션 기능을 제공한다. 카프카의 리플리케이션은 토픽 자체가 아니라 토픽을 이루는 파티션 단위로 이뤄진다.
리플리케이션 팩터와 리더, 팔로워의 역할
카프카에서는 리플리케이션 팩터 라는 것이 있다. 카프카의 기본 값 설정은 1로 되어 있으며, 이는 카프카 설정 파일에서 수정할 수 있다.
server.properties 설정 파일을 열고 난 후 default.replication.factor 항목을 찾은 뒤 2 또는 3 등 원하는 숫자로 변경하면 된다.
이 설정 값은 아무런 옵션을 주지 않고 토픽을 생성할 때 적용되는 값이다.
카프카에서는 리더(원본)과 팔로워(복제본)이라는 개념이 있다. 리더와 팔로워는 각자 역할이 있는데 가장 중요한 핵심은 모든 읽기와 쓰기가 리더를 통해서만 일어난다는 점이다.
즉 팔로워는 리더의 데이터를 그대로 리플리케이션만 하고 읽기와 쓰기에는 관여하지 않는다. 리더와 팔로워는 저장된 데이터의 순서도 일치하고 동일한 오프셋과 메시지들을 갖게 된다.
카프카를 운영하다 보면 생성된 토픽의 리더가 어느 브로커에 위치하는지 팔로워는 어느 브로커에 위치하는지 궁금할 수 있다.
이를 조회하는 명령은 다음과 같다.
/kafka/bin/kafka-topics.sh --zookeeper [ZOOKEEPER_NAME] --topic [TOPIC NAME] --describe
리플리케이션 기능은 유용한 기늠이기도 하지만 단점도 존재한다. 리플리케이션 팩터 수 만큼 더 많은 저장 공간을 필요로 한다.
리더와 팔로워의 관리
분산 애플리케이션은 각자의 방식으로 리플리케이션 작업을 처리한다. 카프카에서는 앞서 설명한 리더와 팔로워라 불리는 구성으로 리더와 팔로워가 각자의 역할을 맡아 리플리케이션 작업을 처리한다.
리더는 모든 데이터의 읽기 쓰기에 대한 요청에 응답하면서 데이터를 저장해나가고 팔로워는 리더를 주기적으로 보면서 자신에게 없는 데이터를 리더로부터 주기적으로 가져오는 방법으로 리플리케이션을 유지한다.
리더와 팔로워 모두 주어진 역할에 맞게 잘 동작하고 있다면 문제가 없지만 팔로워에 문제가 있어 리더로부터 데이터를 가져오지 못한다면 정합성이 맞지 않게 된다.
이 경우 리더가 다운된다면 팔로워가 새로운 리더로 승격하게 되는데 데이터가 일치하지 않는 문제가 발생할 수 있다.
카프카에서는 이를 방지하고자 ISR(In Sync Replica)라는 개념을 도입했다. ISR이라는 건 리더와 팔로워의 데이터 동기화 작업을 처리하도록 만드는 그룹이다.
필로워는 매우 짧은 주기로 리더에 새로운 메시지가 저장된 것이 없는지 확인하고 리더는 팔로워들이 주기적으로 데이터를 확인하고 가져가는지 체크한다. 만약 replica.lag.time.max.ms 만큼 확인 요청이 오지 않는다면 리더는 해당 팔로워의 이상을 감지하고 팔로워를 ISR 그룹에서 추방시킨다.
모든 브로커가 다운된다면
지금까지 나온 기능들을 봤을 때 카프카의 브로커가 1대 정도 장애가 일어나도 별 무리는 없이 진행할 수 있다.
이제 그러면 우리는 모든 브로커가 다운되는 경우를 생각해봐야 한다. 이 경우에 어떻게 우리가 대응해야 하는지 알아보자.
앞에서 설명한 내용들의 상황을 먼저 보고 최악의 시나리오를 만들어보자.
조건은 다음과 같다.
- 카프카 클러스터는 3대의 브로커로 구성되어 있음
- 토픽은 리플리케이션 펙터 3 옵션으로 생성함
- 프로듀서가 데이터를 보내는 중 브로커가 1대씩 다운됨
- 최종적으로 카프카 클러스터내 모든 브로커가 다운된 상황이 발생함
시나리오는 다음과 같다.
- 프로듀서가 A메시지를 전송하고 리더워 팔로워들은 모두 A메시지를 저장했다.
- 프로듀서가 B메시지를 보내기 전에 급작스럽게 팔로워2가 있는 브로커 1대가 다운되었고 리더는 팔로워 2를 ISR에서 지운다. 프로듀서는 B메시지를 전송하고 리더와 팔로워1은 메시지를 저장한다.
- 프로듀서가 C메시지를 전송하기 전에 급작스럽게 팔로워1이 있는 브로커가 다운되었고 리더는 팔로워1를 ISR에서 지운다. 프로듀서는 C메시지를 전송하고 리더는 C메시지를 저장한다.
- 프로듀서가 D메시지를 전송하기 직전에 리더가 있는 브로커가 다운되면서 클러스터 내 모든 브로커가 다운되었고 프로듀서는 더 이상 리더가 존재하지 않기 때문에 메시지를 보낼 수 없다.(장애)
이 때 우리가 선택할 수 있는 방법은 두 가지가 있다.
- 마지막 리더가 살아나서 기다린다. (이유 제일 최신의 데이터까지 저장하고 있기 때문에)
- ISR에서 추방되었지만 먼저 살아나는 팔로워 브로커가 리더가 된다. (이유: 정상적인 서비스를 다시 운영할 수 있기 때문에)
이 두 가지 방안 모두 장단점이 분명하다. 카프카 0.11.0.0 이하 버전에서는 기본값으로 2번 방안을 선택해 일부 데이터 손실을 감수하더라도 빠르게 서비스를 제공해줄 수 있다.
하지만 0.11.0.0 이후 버전에서는 1번 방안을 선택해서 데이터 손실 없이 마지막 리더가 살아나기를 기다린다.
이런 방법은 설정 파일에서 변경할 수 있다
unclean.leader.election.enable 을 true 로 설정한다면 빠른 서비스를 제공하는 방법인 2번이고 false 로 설정한다면 마지막 리더를 기다리는 방법이다.
카프카에서 사용하는 주키퍼 지노드 역할
카프카에서 사용하는 주키퍼의 중요 지노드들을 살펴보자.
/controller
현재 카프카 클러스터의 컨트롤러 정보를 확인할 수 있다. 브로커의 실패 등으로 리더가 변경될 경우 파티션마다 리더 선출작업이 있는 리더를 선정하는 프로세스가 있다.
카프카에서는 클러스터 내 브로커 중 하나를 컨트롤러로 선정해 컨트롤러는 브로커 레벨에서 실패를 감지하고 실패한 브로커에 의해 영향받는 모든 파티션의 리더 변경 책임을 지고 있다.
컨트롤러를 통해 많은 수의 파티션들에 대해 매우 빠르게 리더를 변경할 수 있다.
/brokers
브로커 관련된 정보들이 저장되며 카프카를 설치할 때 브로커 컨피그에서 수정한 broker.id 를 확인할 수 있다.
브로커는 시작시 /brokers/ids 에 broker.id 로 지노드를 작성해 자신을 등록한다.
추가로 /brokers/topics 라는 지노드의 정보를 확인해보면 클러스터 내 토픽 정보들도 확인할 수 있다. 토픽의 파티션 수 ISR 구성 정보 , 리더 정보 등을 확인할 수 있다.
/consumers
컨슈머 관련 정보들이 저장되고 컨슈머가 각각의 파티에 대해 어디까지 읽었는지를 기록하는 오프셋 정보가 여기에 저장된다.
오프셋 정보는 지워지면 안되기 떄문에 주키퍼의 영구노드로 저장된다.
카프카 0.9 버전 이후 부터는 컨슈머 오프셋 저장 장소를 주키퍼 또는 카프카의 토픽울 선택할 수 있도록 제공하지만 향후 카프카의 릴리스 버전에는 주키퍼에 오프셋은 저장하지 않는다.
/config
토픽의 상세 설정 정보를 확인할 수 있다. 토픽 생성 시 기본값으로 생성한 작업 외에 상세 설정 추가를 통해 retention.ms 등을 별도로 설정한 경우 해당 옵션을 확인할 수 있다.
