
🚦 시작하며
이 글은
RxJS 반응형 프로그래밍을 보고 느낀 점을 제 생각대로 풀어쓴 글입니다.
오늘은 RxJS를 통한 반응형 프로그래밍을 살펴보겠습니다.
지난 글에서 설명했던 스트림을 알아보며, 또한 옵저버블을 살펴보도록 하겠습니다.
🚀 본론
함수형 프로그래밍과 반응형 프로그래밍
반응형 프로그래밍은 데이터를 스트림 관점에서 생각합니다.
따라서 데이터는 업스트림에서 다운스트림으로 데이터를 flow하며 동적으로 데이터 소스를 변경합니다.
그리고 RxJS에서는 이러한 흐름에 있어서의 안정성을 유지하기 위해 파이프라인을 구축하는데요. 이러한 파이프라인을 순수함수를 기반으로 한 함수형 프로그래밍으로 구축하기 때문에, RxJS가 말하는 반응형 프로그래밍에는 함수형 프로그래밍이 basis가 됩니다.
실제로 ReactiveX의 사이트에서는 다음과 같이 설명되어 있네요.
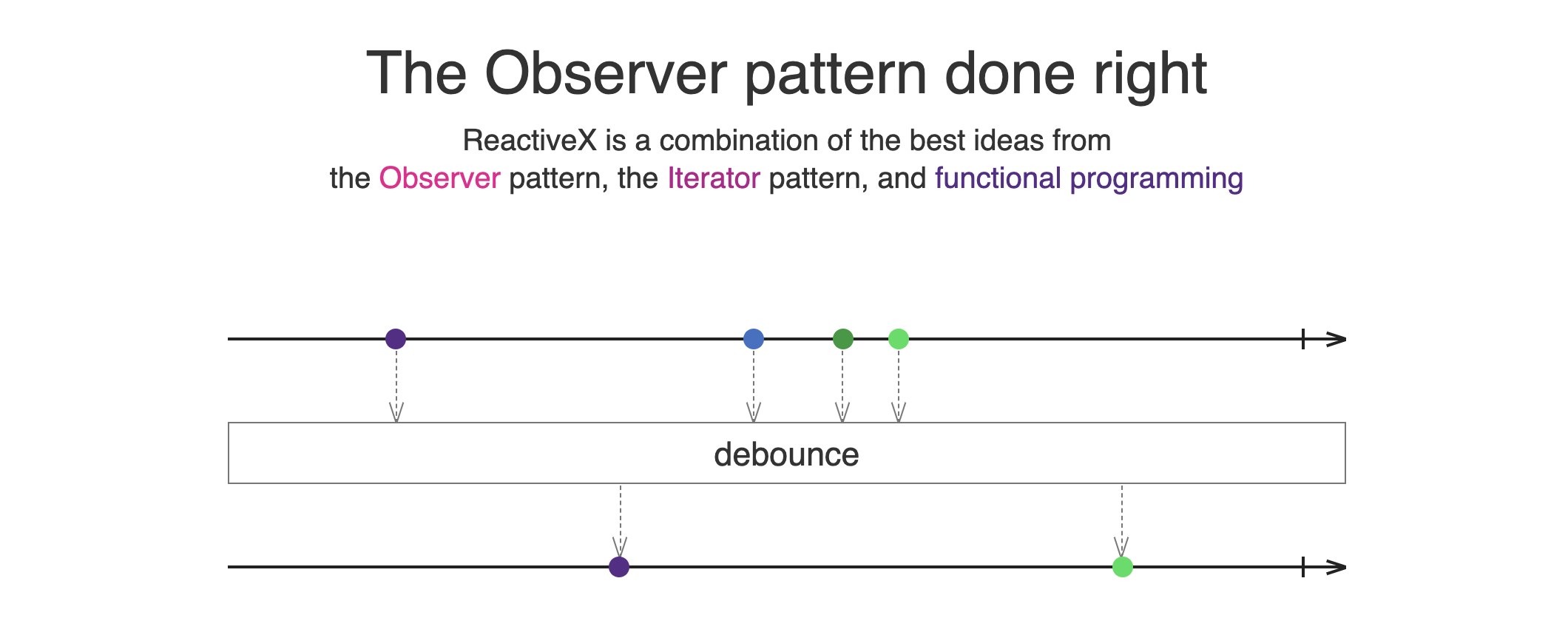
즉 RxJS를 제대로 이해하기 위해서는 함수형 프로그래밍을 이해할 수 있어야 합니다.
그래서 함수형 프로그래밍이란
불변성을 지향한다
객체지향 프로그래밍의 중심에는 상태(프로퍼티)가 존재했습니다.
우리는 이 상태를 관리함에 있어서, 메서드라는 동작을 통해 프로퍼티를 변경시키는 과정을 수행하죠.
함수형에서는 불변성이라는 키워드를 토대로 다음과 같은 의문을 던집니다.
"그렇군요. 그런데, 그것은 과연 항상 같은 결과를 보장하나요?"
예를 들면 sort를 사용하는 예시를 들어보죠.
const arr = [3,2,5,4];
const sortArr = (arr) => arr.sort();
console.log(sortArr(arr)) // [2,3,4,5];
console.log(arr) // [2,3,4,5]불변성을 지키지 못한다는 것은, 언제든지 이를 의존하고 있는 다른 상태나 동작에 대해 영향을 준다는 것입니다. 그렇기에 '무언가가 변경되었다'는 것은 예기치 않은 오류가 발생하더라도 '어디서 문제가 발생했는지' 쉽게 찾을 수 없도록 합니다. 즉 A에서 상태가 변경된 것이 원인인데, 엉뚱한 Z에서 원인을 찾게 되는 것이죠.
따라서 함수형 프로그래밍은 불변성을 지향합니다. 그리고 불변성을 위해 어떤 특정한 인풋이 주어진다면, 일정한 로직을 거쳐 아웃풋이 나올 수 있는 순수함수를 사용합니다.
부가 작용이 없다
부가작용이 없다는 것은, 의존성이 없다는 것을 의미합니다.
그렇다면 생각해봅시다. 함수가 의존성이 왜 없어야 할까요?
함수 몸체 내부의 변수가 아닌, 외부의 변수를 가져다 쓴다는 것은, 상태에 대한 추적을 어렵게 하여 신뢰성을 떨어뜨리고, 결과적으로 유지보수를 힘들게 하기 때문입니다.
특히 이러한 부가작용은 scope의 depth가 깊을 수록, 지역 변수에 쉐도잉된 변수가 많아질 수록 더욱 심해집니다.
따라서 함수형 프로그래밍은 이러한 부가작용(side effect)를 최소화하며 문제를 해결해나갑니다.
명령을 최소화한다
함수형 프로그래밍에서 명령은 추상화됩니다.
이 책에서는 용도가 아닌 기능을 설명하는 선언적 코딩 스타일을 장려한다라는 말로 설명합니다.
참 말이 어려운데요. 이걸 어떻게 해석하면 좋을까요?
이 말을 이해하기 위해 저는 2시간을 고민해야 했습니다.
용도: 쓰이는 곳. 쓰임새.
기능: 기술적 재능. 특징.
"비슷한 거 같은데...😖 도대체 용도와 기능의 차이가 뭐야!"
구체적인 것보다, 깔끔한 요약이 좋다
저는 이 말로 마침내 납득할 수 있었습니다.
때로는 한 줄의 카피가 열 줄의 웅변보다 가슴을 떨리게 만들듯이 말이죠.
그 이유는, 바로 명확성 때문입니다. 에둘러 장황하게 말하는 것이 아니라 핵심을 담아서 말하는 것이 더욱 명료하게 상대방에게 목적을 인지시키기 때문이에요.
예컨대, 짝수를 가져오는 예제로 설명을 해볼게요.
const arr = [1,2,3,4]
let result = [];
for (let i = 0; i < arr.length; i += 1) {
if (arr[i] % 2 === 0) {
result.push(arr[i]);
}
}명령형에서는 다음과 같이 쓸 수 있겠네요. (아무래도 직접 만들어 설명한 거라 틀린 부분이 있다면 지적해주세요) 이것은 마치, 우리에게 짝수를 가져오는 방법을,
즉 어떻게 코드로 다루는 건지 그 용도를 우리에게 설명하는 것처럼 보여요.
- 반복문에서 "너 배열을 일단 순회해"라고 말하고 있어요.
- 짝수가 요구하는 조건인 2로 나눴을 때의 나머지가 0임을 만족하냐고 조건을 묻고 있어요.
- 결과적으로 2를 만족하면 어떤 결과 배열에 담으라고 명령하고 있어요.
이를, 함수형에서는 어떻게 해결할까요?
const arr = [1,2,3,4];
const isEven = v => (v % 2 === 0)
const result = arr.filter(isEven);어때요. 느껴지나요? 뭔가 코드가 해당 캐싱될 값의 두드러진 특징만 딱! 설명한 것 같지 않나요?
그저 "result는 arr에서 짝수만 필터링한 결과를 받는다"라는 말을 하고 있지 않나요? 그렇기 때문에 반복문과 같은 명령문이 줄어든 것 같지 않나요?
이처럼 함수형 프로그래밍에서는 일련의 명령 코드들의 구성을 최소화하고, 선언적으로 추상화시켜요. 그렇기 때문에 코드는 항상 높은 가독성을 유지할 수 있어요. 구체적으로 이 코드가 어떻게 쓰여지는지 그 쓰임새를 살피지 않더라도, 그 특징이 제대로 기술되어 있기 때문입니다.
그렇다면 왜 이러한 선언적 프로그래밍이 가능할까요?
사실 이 부분은 책에는 안 나와있는 스스로에 대한 질문인데요.
저라면 이렇게 답할 것 같습니다.
"함수형 프로그래밍은 사이드 이펙트가 존재하지 않기 때문에, 선언한 정의의 로직이 틀리지 않는 이상 주어진 데이터에 대한 기댓값을 만족할 수 있습니다. 따라서 가독성 높게 선언적으로 단언할 수 있는 것입니다"
결과적으로 데이터는 흐른다
RxJS에서 결국 스트림은 이러한 불변성과 안정성을 토대로 호출이 되면 함수형 프로그래밍이 받쳐주는 파이프라인을 타고, 업스트림에서 다운스트림으로 이동합니다.
도중에 변경은 불가능합니다. 오로지 위에서 아래로, 동적으로 데이터 소스를 함수에 전파시키며 업데이트하여 파이프라인의 마지막 함수에서 결과를 가져옵니다.
파이프라인은 도중에 의존성이 없는 순수함수들만으로 구성되어 있습니다.
따라서 아무리 복잡한 연산들과 로직들이 들어가도, 데이터의 스트림은 오직 함수내의 로직들만으로 처리되고, 원하는 기댓값을 얻을 수 있습니다.
🎉 마치며
항상 "무엇을"과 "어떻게"만으로 명령형과 함수형을 구분하려 했습니다.
그런데 이 책에서는 "기능"과 "용도"라고 서술되어 있어 참 어려웠어요.
그렇지만 그렇게 2시간을 고민하면서, 더 차이점을 이해하게 된 것 같아요.
저번에 글을 쓰는데 반나절이 걸렸습니다. 그리고 이 글을 쓰는 데 2시간 반이 걸렸구요.아무래도 한 장을 다 넣을 필요는 없는 것 같아요. 그저, 제가 이 책을 읽으면서 뱉은 호흡이, 다른 분들에게도 온전히 닿을 수 있게 나누어 서술하는 것이 더 적절한 방식인 듯 합니다.
다들, 그럼 즐거운 공부하시길 바라요. 이상 🌈
.jpg)