230713 Oracle SQL 14 [INDEX, primary key, unique index, SYNONYM]
인덱스 리스트 확인하기
문제 581.
c##scott 유저가 소유하고 있는 인덱스 리스트를 확인하시오select * from user_indexes;select index_name, table_name, uniqueness from user_indexes;이렇게 봐도되고,
이렇게 봐도됨!
emp테이블에 emp_hiredate 인덱스가 존재하는지 확인 완료
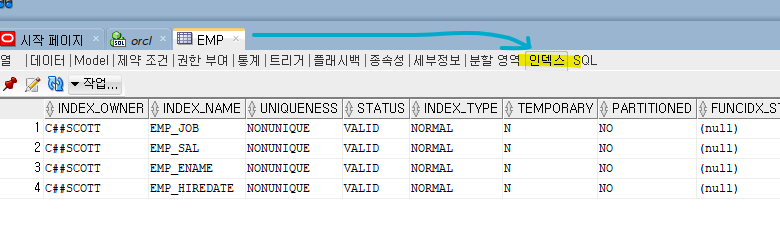
특정 테이블의 인덱스 리스트 확인
✔️오라클 -> 테이블 탐색기 -> emp -> 상단 인덱스
(uniqueness 가 더 좋은 인덱스,,?)
문제 582. 아래의 SQL을 튜닝하시오
- 튜닝전 (좌변이 가공됨. full scan)
select ename, hiredate from emp where to_char(hiredate,'RR/MM/DD') = '81/12/11';
- 튜닝후 (인덱스로 스캔)
select ename, hiredate from emp where hiredate = to_date('81/12/11','RR/MM/DD');✅ 위 : 좌변을 문자형으로 나타내겠다 (
to_char)
아래 : 우변을 날짜형으로 나타내겠다 (to_date)
요거 헷갈리지 말기!
❗where 절에 인덱스 컬럼을 가공하면 인덱스를 사용할 수 없고 full table scan 하게 된다.
인덱스의 구조
- 컬럼값 + rowid
- 컬럼값은 asc 으로 정렬이 됨
⬇️
오라클에서는 과도한 정렬작업을 수행하게 되면 성능이 느려진다.
오라클이 정렬작업을 하려면 별도의 메모리에서 정렬 작업을 수행한다.
근데 그 메모리 공간이 넉넉하지 않기 때문에 과도한 정렬 작업이 들어오면 성능이 느려진다.
정렬작업을 최소화 할 수 있게 sql을 재작성(튜닝) 해줘야 한다.
문제 583. 아래의 SQL을 튜닝하시오 (인덱스의 구조를 이해하기 위한 문제)
- 튜닝전
select ename, sal from emp order by sal asc;order by 절 때문에 성능을 느리게 한다.
실행계획에 'sort order by' 가 있으면 성능이 떨어진다!
- 튜닝후
select ename, sal from emp where sal >= 0;order by 절을 쓰지않고, 0보다 크거나 같은것 이라고 지정해주면, 자동 asc 된다 (인덱스의 구조)
만약에 자동 asc 되지 않는다면,select /*+ index_asc(emp emp_sal) */ ename, sal from emp where sal >= 0;로 힌트를 주면 된다
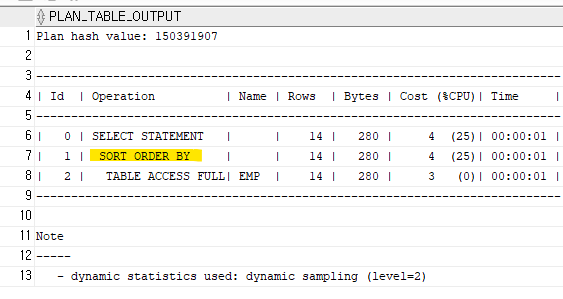
❗❗이미 인덱스는 데이터를 정렬해서 저장하고 있으므로,
인덱스에서 정렬된 데이터를 읽어오는게 더 성능이 좋다.
order by 를 수행하는 것보다 더 성능이 좋다!
인덱스 스캔 정렬하는 힌트
- 힌트 1. /+ index_asc(테이블명 인덱스이름) / : 인덱스를 ascending 하게 스캔
- 힌트 2. /+ index_desc(테이블명 인덱스이름) / : 인덱스를 descending 하게 스캔
질문!!🤔
위의 sql이 인덱스인지 어케아는거지??? 자동 asc는 인덱스의 구조인데,, 그냥 쿼리문과 인덱스의 차이점은?
-> sal 에 월급을 미리 만들어놨어서 그런가봄..! 아닌가?
✅
PGA라는 공간이 협소하니까 temp라는 테이블 스페이스 디스크에 저장한다. (Disk I/O)
-> 성능을 떨어뜨린다.
(이 단어들 한번 더 검색해보기, 강사님이 그냥 지나가듯 하신..설명)
문제 584. 아래의 sql 을 튜닝하시오
- 튜닝전
select ename, job, sal from emp where job='SALESMAN' order by sal desc;
- 튜닝후
select /*+ index_desc(emp emp_sal) */ ename, job, sal from emp where sal>0 and job='SALESMAN';sal이 0보다 크다는 조건과 job이 salesman 이라는 조건 두가지를 줘서 sal을 자동 정렬하게끔 한다.
월급을 먼저쓰던 나중에 쓰던 상관없다.
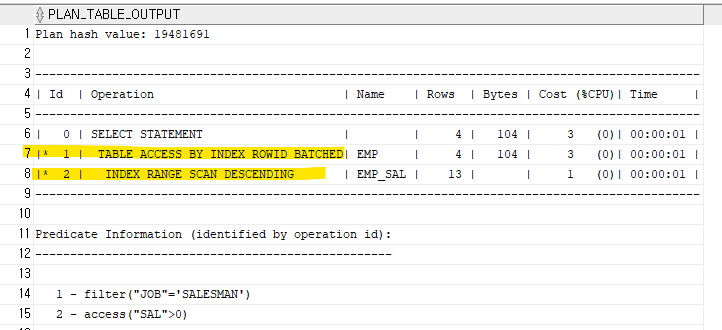
문제 585. 아래의 sql을 튜닝하시오
- 튜닝전
select ename, hiredate from emp order by hiredate desc;
- 튜닝후
select /*+ index_desc(emp emp_hiredate) */ ename, hiredate from emp where hiredate > TO_DATE('9999/12/31','RRRR/MM/DD'); -> 힌트에 사용한 인덱스 컬럼이 있어야함!!✔️ 힌트만 쓰면 안되고, where 절에 검색하고자 하는 컬럼명이 반드시 있어야 관련된 힌트가 작동한다.
인덱스의 형변환 데이터 스캔
- 문자 > ' '
- 숫자 >= 0
- 날짜 < to_date ('9999/12/31', 'RRRR/MM/DD')
✔️ 인덱스의 데이터를 스캔하기위해 WHERE 절에 해당 인덱스 컬럼이 있어야하는데,
인덱스의 데이터를 읽어오기 위한 조건들이다.
인덱스의 구조를 위한 SQL튜닝 방법
where절의 좌변을 가공하지 말아라order by절 대신에 인덱스 자동정렬을 이용해라
인덱스가 생성되는 방식
(책 pdf p11-36 참고)
- 수동: 행에 액세스하는 속도를 높이기 위해 유저가 열의 비고유 인덱스를 생성할 수 있습니다
create index emp_deptno
on emp(deptno);- 자동:
PRIMARY KEY또는UNIQUE제약 조건을 걸면 고유 인덱스가 자동으로 생성됩니다.
emp테이블 empno에
primary key제약을 생성해보자alter table emp add constraint emp_empno_pk primary key(empno);insert into emp(empno, ename, sal) values(null, 'jane', 4000);❗SQL 오류: ORA-01400: NULL을 ("C##SCOTT"."EMP"."EMPNO") 안에 삽입할 수 없습니다.
insert into emp(empno, ename, sal) values(7788, 'jack', 5000);❗ORA-00001: 무결성 제약 조건(C##SCOTT.EMP_EMPNO_PK)에 위배됩니다
✔️ 제약(contraint)은 테이블의 데이터의 품질을 높이기 위해서 반드시 필요한 db기능이다.
✔️ PRIMARY KEY 제약을 생성한 컬럼은 중복된 데이터와 null 값이 입력 안된다.
ex) 사원번호, 주민등록번호 등등 중복된 데이터가 없어야 하는 컬럼
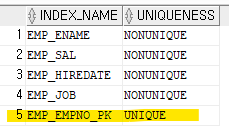
emp 테이블과 관련해서 생성된 인덱스를 확인해보시오
select index_name, uniqueness from user_indexs where table_name='EMP';
✔️ unique 인덱스는 중복된 데이터가 없어야 생성되는 인덱스
✔️ PRIMARY KEY 는 중복된 데이터가 없어야 걸리는 제약
✔️ PRIMARY KEY 를 걸면 자동으로 unique 인덱스가 만들어진다.
우리반 테이블의 ename 에 unique 제약을 거시오
alter table emp17 add constraint emp17_ename_un unique(ename);이미 중복된 이름이 없어야 생성된다.
우리반 테이블에 ename 에 인덱스가 있는지 확인하시오
select index_name, uniqueness from user_indexes where table_name='EMP17';
문제 586.
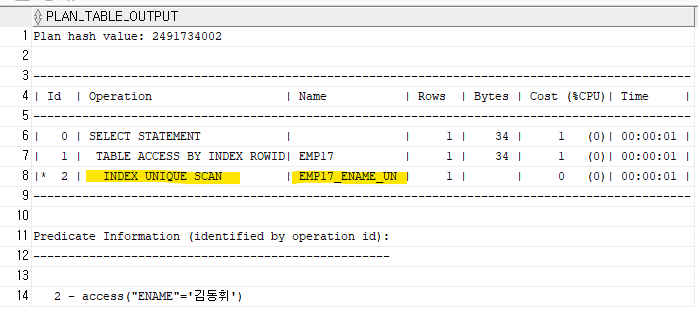
우리반 테이블에서 이름이 김동휘 학생의 이름과 나이와 주소를 출력하고 그 쿼리문의 실행계획을 확인하시오explain plan for select ename, age, address from emp17 where ename ='김동휘'; select * from table(dbms_xplan.display);
인덱스에서 먼저 스캔한 것을 확인할 수 있다.
근데 index range scan 이 아니고 index unique scan이다.
age 와 address 를 찾기 위해서 테이블주소를 통해 바로 들어가서 뽑아냈다.
unique index 라서 밑의 목록의 사람들까지 스캔하지 않고
어차피 중복된 데이터가 없으니 확실히 보장된 데이터만 바로 출력한다.
✅ 강사님 정리
unique 인덱스는 이름의 중복된 데이터가 없음이 확실히 보장된 인덱스 이므로,
김동휘 하나의 인덱스 행만 검색하고 바로 테이블 엑세스를 하러가고 끝난다.
그러나 non unique 인덱스이면 그 다음 행인 김정명 행을 엑세스 한다.
그래서 옵티마이저가 아래와 같은 sql 이 있고 2개의 인덱스가 있으면 unique 인덱스를 선호한다.
create index emp17_age
on emp17(age);
alter table emp17
add constraint emp17_un unique(ename);이렇게 만들고,
select ename, age, address
from emp17
where age=33 and ename='김동휘'찾는다면,
'김동휘'를 찾을 수 있는 목차(인덱스)가 두개가 된것
옵티마이저는 이름에 대한 유니크 인덱스를 탄다.
문제 587.
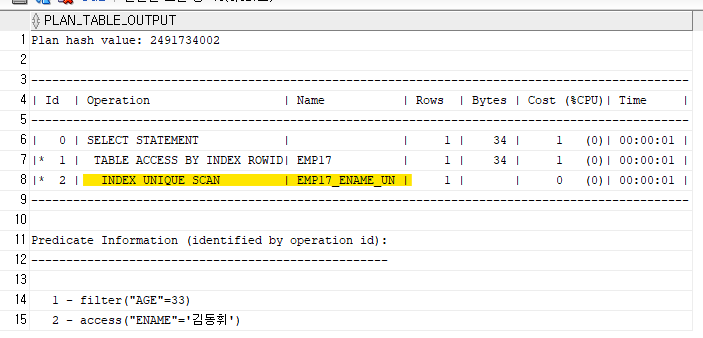
여러분 자리에 옵티마이저가 똑똑한 옵티마이져인지 확인하시오
(위의 설명에서 실행계획 확인!)create index emp17_age on emp17(age); alter table emp17 add constraint emp17_un unique(ename); explain plan for select ename, age, address from emp17 where age=33 and ename='김동휘'; select * from table(dbms_xplan.display);
❗유니크 인덱스에서 출력했다는 것 확인!
✅ 옵티마이져는 더 좋은 인덱스를 엑세스를 하는데,
만약 덜 좋은 인덱스를 엑세스 했다면 dba가 힌트를 줘서 튜닝을 해주면 됩니다.
⬇️ 힌트주는 방법 설명
문제 588.
아래의 SQL의 실행계획이 emp17_age 인덱스를 엑세스 하도록 힌트를 주고 실행계획을 확인하시오select /*+ index(emp17 emp17_age) */ ename, age, address from emp17 where age=33 and ename='김동휘';index 힌트
/*+ index(테이블명 인덱스이름) */여러개의 인덱스중에 특정 인덱스를 사용하게 하고 싶을 때,
아래의 index 힌트를 이용합니다.
index 와 full table 정리
내가 걍 정리해봄 틀릴수도ㅎ
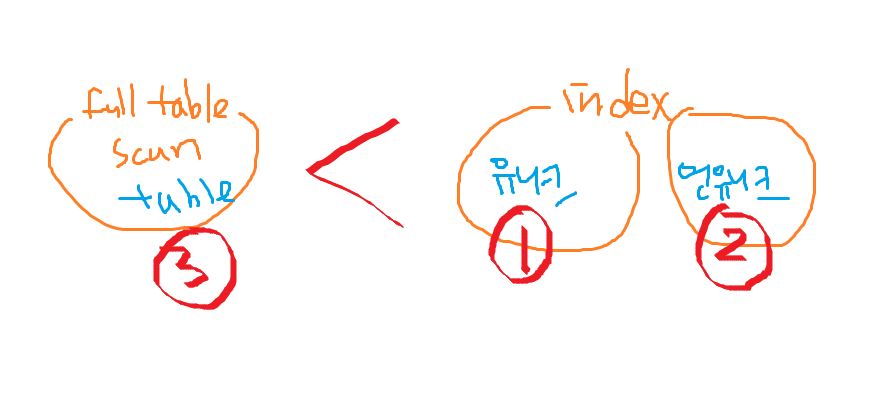
✅ 좋은 순위
1. unique index : index unique scan
2. nonunique index : index range scan
3. table : full table scan
논유니크 인덱스 만들때는 그냥
create index emp_deptno
on emp(deptno); 로 하면 되는데, (디폴트는 논유니크)
유니크 인덱스 만들때는
alter table emp
add constraint emp_empno_pk primary key(empno); 로 하는 이유는,
어차피 프라이머리키 설정하면 유니크 인덱스가 되니까!! ( +null값X 설정까지)
create unique index emp_deptno
on emp(deptno);로 해도 된다!
인덱스 생성과 나눠지는 기준 (p11-37)
🟥 데이터의 값이 unique 한지 unique 하지 않은지에 따라 2가지로 나눈다.
1. unique index : primary key 제약 또는 unique 제약을 걸었을 때 (자동)
또는,
create unique index emp17_empno
on emp17(empno);- non unique index :
create index emp_job
on emp(job);🟥 인덱스를 구성하려는 컬럼의 갯수에 따라서도 2가지로 나뉜다
1. 단일 컬럼 인덱스 : 인덱스를 구성하는 컬럼의 갯수 1개
create index emp_sal
on emp(sal);- 결합 컬럼 인덱스 : 인덱스를 구성하는 컬럼의 갯수 2개 이상
create index emp_job_sal
on emp(job, sal);전에 스크립트 저장해서 바로 쓰는 방법 했던거 해본다.
SQL> @init_emp.sql -> 스크립트 수행해서 emp 테이블이 drop 되니까,
emp 테이블과 연관된 인덱스들도 다 drop 된다. (오라클에서 확인가능!)
결합컬럼 인덱스
예제. 아래의 결합 컬럼 인덱스를 생성하고 이 결합 컬럼 인덱스의 구조를 확인하시오
create index emp_job_sal on emp(job, sal);

예제. 위의 결합 컬럼 인덱스의 구조를 확인하시오
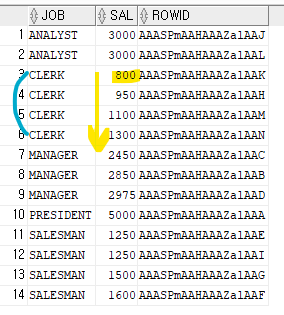
- 인덱스 구조 : 컬럼값 + rowid , 컬럼값이 ascending 하게 정렬
select job, sal, rowid from emp where job > ' ';
✔️ job을 먼저 asc 정렬하고 그중에서 sal 이 정렬되었음
drop 시키구~
문제 589. emp테이블의 job컬럼에 인덱스를 생성하시오
( 인덱스 이름은 emp_job으로 하세요)create index emp_job on emp(job);->
단일컬럼인덱스
문제 590.
직업이 CLERK 인 사원들의 직업과 월급을 출력하는 쿼리문의 실행계획을 확인하시오explain plan for select job, sal from emp where job='CLERK'; select * from table(dbms_xplan.display);
❗ 위와같이 sql을 만들면, JOB만 출력했으면 INDEX 에서만 읽었을텐데, sal까지 뽑아야하니까 (sal은 인덱스에 없음) 테이블 엑세스까지 간다.
-> 그래서 sal 까지 묶어서 결합컬럼 인덱스 를 만들어서 sal 까지 다 인덱스에 구성
문제 591.
emp테이블에 job과 sal에 다음과 같이결합컬럼 인덱스를 생성하시오create index emp_job_sal on emp(job,sal);
문제 592.
아래의 sql의 실행계획을 다시 확인하시오! (문제 590 의 sql)explain plan for select job, sal from emp where job='CLERK'; select * from table(dbms_xplan.display);
✅ 당연히 옵티마이져는 결합컬럼 인덱스를 탔다!!
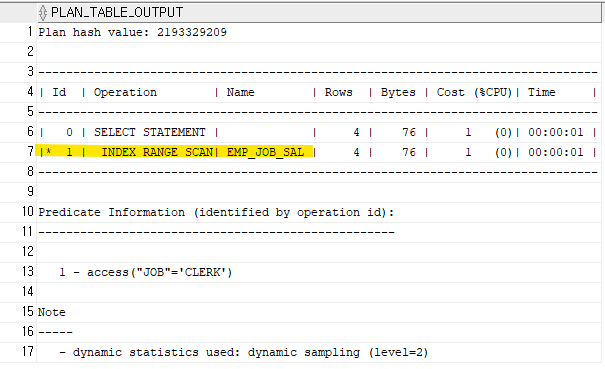
❗❗emp_job_sal 결합컬럼 인덱스에서 job과 sal에 대한 data를 다 얻어냈기 때문에
emp 테이블을 엑세스 하지 않는 실행 계획이 나왔다!
❗결합컬럼 인덱스의 컬럼 갯수는 상관없다. 많이 해도 됨
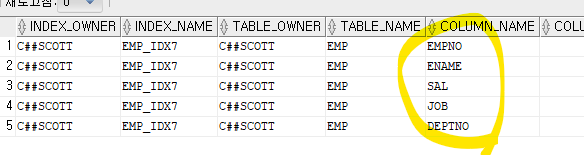
create index emp_idx7
on emp(empno, ename, sal, job, deptno);문제 593. emp테이블과 관련된 인덱스를 조회하시오
눌러서 결합컬럼인덱스 라는걸 확인할 수 있다.
문제 594.
아래의 sql을 튜닝하시오 (order by 안쓰고 나오게)
- 튜닝전
select ename, job, sal from emp where job='CLERK' order by sal desc;
- 튜닝후
select /*+ index_desc(emp emp_job_sal) */ ename, job, sal from emp where job='CLERK'✅ where job=' ' > 0 안해도됨!! 결합컬럼인덱스라서!
문제 595.
deptno 와 sal 을 결합컬럼인덱스로 생성하시오
(인덱스 이름은 emp_deptno_sal 로 하시오)create index emp_deptno_sal on emp(deptno, sal);
문제 596.
emp_deptno_sal 인덱스의 구조를 확인하시오
✔️인덱스의 구조: 컬럼값 + rowid / 컬럼값이 asc 정렬select deptno, sal, rowid from emp where deptno >= 0;
문제 597. 아래의 sql을 튜닝하시오
- 튜닝전
select ename, deptno, sal from emp where deptno = 20 order by sal desc;
- 튜닝후
select /*+ index_desc(emp emp_deptno_sal) */ ename, deptno, sal from emp where deptno = 20;결합컬럼인덱스라서 20으로 뽑은다음에 그중에서 sal을 정렬
인덱스 생성지침
🟥인덱스 생성 경우
- 테이블의 크기가 클때 : emp 테이블처럼 작은 테이블은 인덱스가 필요없다.
인덱스 없이도 검색속도가 빠름 - null 값이 많은 컬럼에 : 인덱스 구성시 null 값은 구성되지 않는다. (ex 책의 빈페이지는 목차에 나오지 않는 것)
- where 절에 자주 검색되는 컬럼에! :
- 검색하려는 데이터의 행이 전체테이블의 2~4% 미만인 컬럼에
🟥다음의 경우에는 인덱스를 생성하지 마세요
-
where절에 자주 검색되지 않는 컬럼
-
테이블이 작거나 검색하는 행이 테이블 전체의 2~4% 이상의 컬럼
-
테이블이 자주 갱신되는 컬럼 ★★ : 테이블의 데이터를 변경하면 인덱스도 같이 변경해줘야합니다.
-
인덱스화 된 열이 표현식의 일부로 참조되는 경우 : 좌변 가공 내용!! where sal*12 = 36000;
❗테이블의 데이터를 변경하면 인덱스도 같이 변경해줘야 한다. 책의 내용을 변경하면 목차도 다시 변경하듯.. 그런데 책음 그냥 변경하면 간단하지만 목차는 ㄱㄴㄷ 순서이기 때문에 변경할 때 시간이 많이 걸린다.
index가 있는 테이블에 insert, update 를 하면 insert, update 속도가 느려진다.
문제 598.
인덱스가 생성되어 있는 테이블과 생성되어있지 않은 테이블에 대량의 데이터를 insert 할 때 속도를 확인하시오1) 다음 2개의 테이블을 생성합니다.
create table sales_no_index as select * from sales where 1=2;create table sales_with_index as select * from sales where 1=2;2) 위의 2개의 테이블중에 sales_with_index 테이블에만 인덱스를 생성하시오
create index sales_index_1 on sales_with_index(amount_sold, promo_id);3) 아래와 같이 대량의 데이터를 2개 테이블에 각각 입력하고 속도를 비교하시오
set timing on insert into sales_no_index select * from sales;-> 0.4초 정도
insert into sales_with_index select * from sales;-> 1.6초 정도
✅ 테이블에 인덱스가 있으면 insert 가 느려진다
index drop
인덱스 이름 조회
select index_name from user_indexes (사전) where table_name='EMP'; (대문자로!)drop
✅ drop index (인덱스이름);
문제 599. emp 테이블에 관련된 인덱스가 무엇인지 조회하시오
select index_name from user_indexes where table_name='EMP'; (대문자로!)
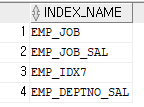
문제 600. emp 테이블과 관련된 모든 인덱스를 다 삭제하시오
drop index emp_job; drop index emp_job_sal; drop index emp_idx7; drop index emp_deptno_sal;
✔️ 인덱스는 수정할 수 없습니다. 인덱스를 변경하려면 인덱스를 삭제한 다음 다시 생성해야 합니다.
인덱스 문제 하나 풀기 (교제문제)
Indexes must be created manually and serve to speed up
access to rows in a table. -> false
099. 동의어 (synonym) (교재 p11 - 41)
🟥 동의어란? 특정 객체에 대한 다른 이름
c##scott (dba) <- 테이블을 만든 사람은 해당 테이블의 drop 권한도 있다.
c##smith (개발자) <- 테이블에 대해서 select, update, insert 정도의 권한만 줘야합니다.
(delete, drop X)문제 601.
c##scott 유저에서 c##smith 유저를 만들고,
접속할 수 있는 권한을 부여하고 c##smith 유저로 접속하시오create user c##smith identified by tiger; grant connect to c##smith; grant select on emp to c##smith;
- c## 붙인 이유는 보안강화때문에 오라클에서 그렇게 만든거임
✅ select from emp 라고 조회하면 안되고,
select from c##scott.emp; 라고 조회해야 나온다.
그런데, 이렇게 되면 유저 이름을 알게 되니까, 숨겨야한다
-> 그래서 synonym 을 사용!create public synonym emp for c##scott.emp;emp라는 이름으로도 c##scott.emp 에 접속할 수 있게된다!
✔️ 개발 dba 가 emp 테이블을 생성했으면 위와같이 synonym 도 생성해놓는다.
✔️ synonym 을 만들어야 c##smith 유저가 emp 테이블을 select 등을 할 때,
테이블명 앞에 c##scott 을 접두어로 안붙여도 되기 때문이다.
문제 602.
c##smith 유저가 다음과 같이 dept 테이블과 salgrade 테이블을 조회할 수 있게 하시오select * from dept; select * from salgrade;grant select on dept to c##smith; grant select on salgrade to c##smith; create public synonym dept for c##scott.dept; create public synonym salgrade for c##scott.salgrade;❗권한을 먼저 준다음에 synonym 지정까지!
synonym 생성
- 짧은 이름으로 생성하기
문제 603.
시너님을 생성하는데 employees 를 e 로 생성하시오create synonym e for employees;✔️ 나 혼자 (c##scott) 쓸거면 public 안써도 된다!
✔️ 별도의 테이블이 생성되는게 아니라 employees 테이블에 대한 다른 이름이 생성되는 것입니다
🟥 개발 DBA로 일할 때 synonym 생성 tip
hr 계정이 가지고 있는 모든 테이블들을 c##smith 유저가 select 할 수 있게 하시오
예제1. hr 계정이 소유하고 있는 테이블 리스트를 확인하시오
select table_name from dba_tables where owner='HR';
⬇️ 연결연산자를 사용해서 grant(권한주는)문 을 문구로 생성한다!
예제2. hr 계정의 7개의 테이블을 select 할 수 있는 권한을 c##smith에게 부여하는 스크립트를 생성하시오
select 'grant select on hr.'||table_name||' to c##smith;' from dba_tables where owner='HR';완성본
grant select on hr.REGIONS to c##smith; grant select on hr.COUNTRIES to c##smith; grant select on hr.LOCATIONS to c##smith; grant select on hr.DEPARTMENTS to c##smith; grant select on hr.JOBS to c##smith; grant select on hr.EMPLOYEES to c##smith; grant select on hr.JOB_HISTORY to c##smith;
⬇️ 연결연산자 사용해서 public synonym 문구 만들기
예제3. 이번에는 public synonym 을 생성하시오
select ' create public synonym '||table_name|| ' for hr.'||table_name||';' from dba_tables where owner='HR';
완성본create public synonym REGIONS for hr.REGIONS; create public synonym COUNTRIES for hr.COUNTRIES; create public synonym LOCATIONS for hr.LOCATIONS; create public synonym DEPARTMENTS for hr.DEPARTMENTS; create public synonym JOBS for hr.JOBS; create public synonym EMPLOYEES for hr.EMPLOYEES; create public synonym JOB_HISTORY for hr.JOB_HISTORY;
drop synonym
문제 604. employees 시너님을 삭제하시오
drop public synonym employees;
- public synonym 으로 만들었기 때문에~!
플레쉬백쿼리 말고 제약 먼저 하신다구함!
104. 데이터의 품질 높이기 1(PRIMARY KEY)
제약 (CONSTRAINT)
✔️ 테이블의 data의 품질을 높이기 위해서 제한을 거는 기능
ex) 데이터가 함부로 엉뚱한 데이터로 입력되지 않게하고,
null 값이나 중복된 data를 허용하지 못하게 막는 기능
제약의 종류 5가지
primary key: 중복된 data 와 null 을 허용하지 못하게 막는 제약unique: 중복된 data 를 허용하지 못하게 막는 제약not null: null 값을 허용하지 못하게 막는 제약check: 지정된 data 만 입력되고 수정될 수 있도록 막는 제약foreign key: 자식키에 해당하는 컬럼에 거는 제약
나머지 내용은 내일~
마지막 문제 풀기 위한 환경 구성하기!
명령프롬포트창 열고 @init_emp.sql 을 돌려서 emp 초기화 스크립트 작동시킨다.
문제 605.
사원 테이블의 월급이 인덱스를 걸고 아래의 SQL의 MAX 함수 사용하지 말고 결과를 출력하시오
(order by 뿐만 아니라 max와 min은 정렬작업이 내부적으로 발생하므로)create index emp_sal on emp(sal);
- 튜닝전
select max(sal) from emp;
- 튜닝후
select /*+ index_desc(emp emp_sal)*/ sal from emp where sal >= 0 and rownum =1;
문제 606. (오늘의 마지막 문제)
아래의 sql을 튜닝하시오
- 튜닝전
select ename, sal from emp where sal = (select max(sal) from emp);
/*+ gather_plan_statistics */추가해서 버퍼 개수 봐보기
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
- 튜닝후
select /*+ gather_plan_statistics index_desc(emp emp_sal) */ ename, sal from emp where sal >=0 and rownum =1; select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));ename 이 컬럼명 앞쪽이라고 앞에다 쓰는거아니구 ename, sal 일케 쓰는게 맞댕!
버퍼개수 확인 힌트
/*+ gather_plan_statistics */
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));