230710 Oracle SQL 11 [계층형 질의문, 테이블 생성, 컬럼 관리, 데이터 입력]
089 계층형 질의문으로 서열을 주고 데이터 출력하기1 (start with)
KING 1
JONES 2
SCOTT 3
ADAMS 4
FORD 4
SMITH
BLAKE
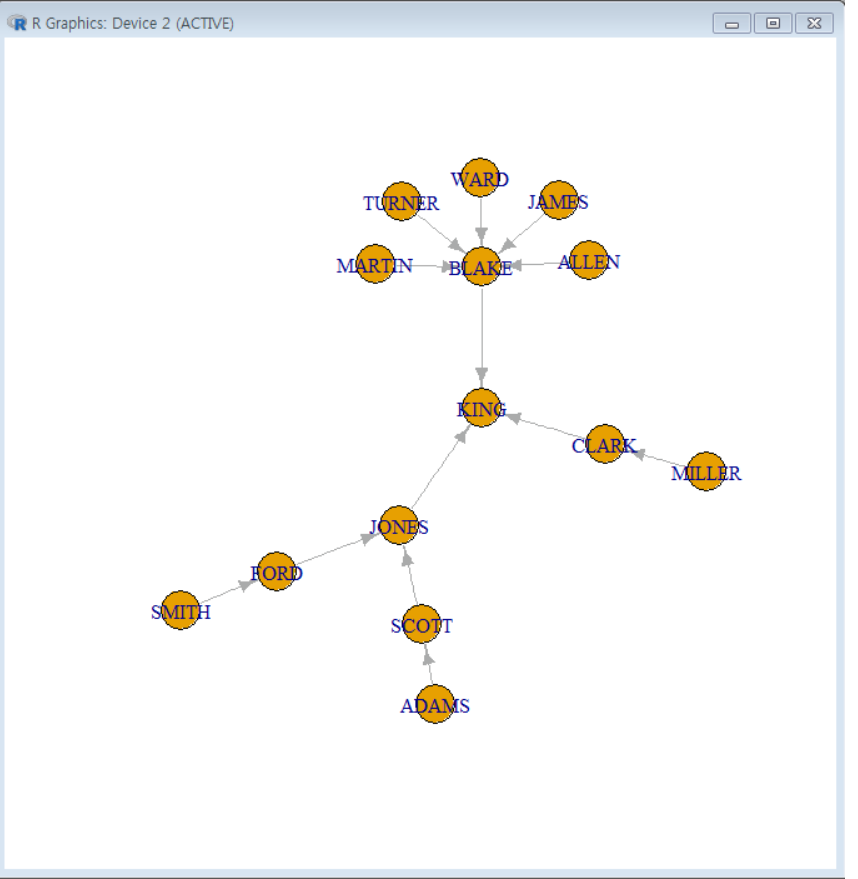
..-> 데이터를 시각화해서 보여주는 쿼리문 (계층형 시각화)
(보통 시각화는 파이썬이고 오라클은 데이터 위주인데 이런 쿼리문을 쓸수 있기도함)
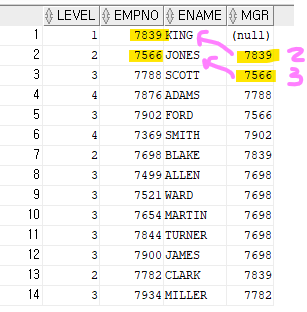
예제1. 사원 테이블의 서열을 계층형 질의문으로 출력하시오
select level, empno, ename, mgr (직속상사=관리자의 번호)
from emp
start with ename='KING' (-> 서열 1위를 결정하는 문법)
connect by prior empno = mgr; (-> 서열을 연결해주는 연결고리)start with 와 connect by 를 쓰게되면, select절에 level 넣어야함
서열 1위
start with (컬럼) = '__'
(start with mgr is null 로 써도됨) ( 관리자번호가 null인 사람은 서열1위니까!)
connent by prior 컬럼 = 컬럼;서열 연결고리 쓸 때 순서는,
empno = mgr 라면, empno 가 mgr 인 사원. 즉 그 다음 서열이 나오게된것.
-> empno : pk 부모키
-> mgr : fk 자식키
예제2. employees 테이블에서 level, employee_id, first_name, manager_id 를 출력하시오. 서열 1위를 maneger_id 가 null 인 사원으로 하시오
select level, employee_id, first_name, manager_id
from employees
start with manager_id is null
connect by prior employee_id = manager_id; 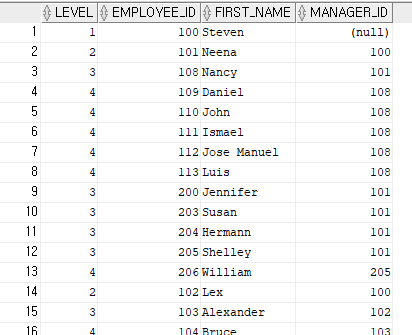
계층형 질의문 시각화
예제3. 아래의 rpad 함수를 이용한 SQL을 수행하시오
select rpad( ename, 10, '*')
from emp;
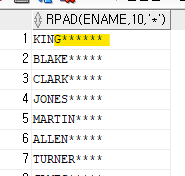
- 전체 열자리로 만드는데 알파벳말고 남은 자리는 '* ' 로 채워라!
select rpad (' ', level*3)-> rpad 함수 옆에 괄호안에 3개 쓸수도 있고 2개 쓸 수도 있다.
공백을 채워넣는데, 레벨의 값에 따라서 넣게 하는 문법
select rpad(' ', level*3) || ename as employee, level, ename, sal, job
from emp
start with ename = 'KING'
connect by prior empno=mgr;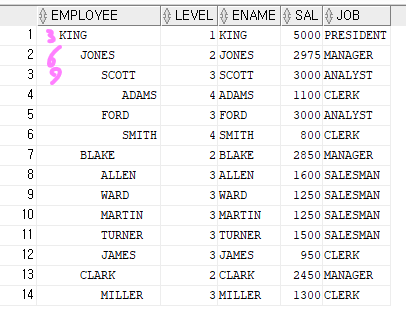
KING 은 3개의 공백
JONES 는 6개의 공백
SCOTT 은 9개의 공백
문제 501. employees 테이블에서 first_name, level, salary, job_id 를 출력하는데
앞에 first_name 앞에 level 의 2배로 공백을 넣어서 출력하시오select rpad(' ', level*2) || first_name, level, salary, job_id from employees start with manager_id is null connect by prior employee_id = manager_id;
- start with 와 connect by 절을 사용해야 level 컬럼을 볼 수 이싿!!
계층형 질의문에서 where 절
문제 502. 월급이 2400 이상인 사원들의 이름과 월급을 출력하는데,
계층형 질의문을 이용해서 이름앞에 level 의 2배로 공백을 줘서 출력하시오select rpad(' ',level*2)||ename as name, sal from emp where sal >= 2400 start with ename = 'KING' connect by prior empno=mgr;
- select 절에 level 안써도 rpad 공백 사용가능하넹
문제 503. 위의 SQL의 실행순서를 확인하기 위해서 실행 계획을 확인하시오
select * from table (dbms_xplan.display);
- 실행 순서 : from 절 먼저 실행 후 계층형 질의문인 start with와 connect by 를 수행하고나서 마지막에 where 절 수행함

실행계획 보는 법
오라클 DBMS_XPLAN 실행계획 보는법
https://blog.naver.com/clipper0317/222958385951
090. 계층형질의문으로 서열을 주고 데이터 출력하기 2
: 계층형 질의문 결과에서 검색조건을 주는 방법을 배웁니다.
특정 분기를 제거하는 방법
예제1. 앞의 예제에서 출력하는 사원 테이블 전체의 서열을 출력하시오
select rpad(' ',level*2)||ename as name, level, sal
from emp
start with ename = 'KING'
connect by prior empno=mgr;계층형 질의문에서 제외하고 출력하기 (connect by)
문제 504. 위의 결과에서 이름이 BLAKE 인 사원은 제외하고 출력하시오
select rpad(' ',level*2)||ename as name, level, sal from emp where ename !='BLAKE' start with ename = 'KING' connect by prior empno=mgr;blake는 빠지고, blake 의 팀원은 남아있다.
문제 505. 이번에는 BLAKE 뿐만 아니라 BLAKE의 팀원들도 전부 안나오게 하시오
select rpad(' ',level*2)||ename as name, level, sal from emp start with ename = 'KING' connect by prior empno=mgr and ename !='BLAKE';
- 부모키 (empno) 와 자식키 (mgr) 가 관계를 맺을때, BLAKE를 제외시켜서 BLAKE 의 사원번호를 mgr 번호로 하고 있는 사원들이 모두 출력되지 않는것.
- where 절보다 계층형질의문이 먼저 수행되기 때문에 connect by 절에 미리 적어준다.
문제 506.
employees 테이블에서 위와 똑같은 결과를 출력하는데,
first_name 이 'ADAM' 과 'ADAM' 의 팀원들을 전부 안나오게 하시오select rpad(' ',level*2)||first_name as first_name, level, salary, job_id from employees start with manager_id is null connect by prior employee_id = manager_id and first_name !='Adam';
091. 계층형 질의문으로 서열을 주고 데이터 출력하기 3 (Order by)
: 계층형 질의문에서 서열의 틀을 깨트리지 않으면서, 데이터를 정렬하려면
order by 할 때 특별한 키워드를 써야한다.
-> SIBLINGS
예제1. 다음과 같이 사원테이블의 전체의 서열을 출력하시오 (앞에 했던거)
select rpad(' ',level*2)||ename as name, level, sal
from emp
start with ename = 'KING'
connect by prior empno=mgr;예제2. 위의 결과를 다시 출력하는데 월급이 높은 사원부터 출력하시오
select rpad(' ',level*2)||ename as name, level, sal
from emp
start with ename = 'KING'
connect by prior empno=mgr
order by sal desc;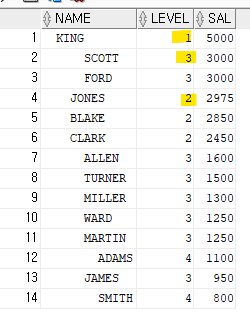
order by 를 사용하면서 누가 누구의 팀원인지, 또는 누가 누구의 팀장인지를 알수가 없게 되었다. 서열순서가 꼬이게 됨
-> order by 는 항상 마지막에 수행되기 때문에 앞에서 다 수행된걸 다 꼬이게 만들었음
SIBLINGS
예제3. 누가 누구의 팀원인지에 대한 서열 구조는 그대로 유지하면서 월급이 높은 사원부터 출력되게 하시오
select rpad(' ',level*2)||ename as name, level, sal
from emp
start with ename = 'KING'
connect by prior empno=mgr
order siblings by sal desc; order 랑 by 사이에 siblings 를 사용하게 되면,
서열은 그대로 유지하면서 월급이 높은 순서대로 나오게 됨.
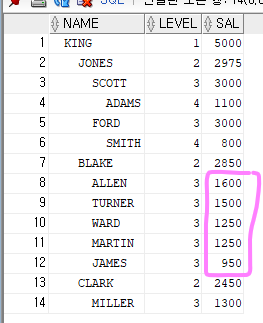
-> 같은 서열 내에서 월급이 높은 순으로 나오게
문제 507.
위의 결과를 employees 테이블로 출력하시오select rpad(' ',level*2)||first_name as first_name, level, salary, job_id from employees start with manager_id is null connect by prior employee_id = manager_id order siblings by salary desc;
092. 계층형 질의문으로 서열을 주고 데이터 출력하기 4 (sys_connect_by_path)
계층형질의문 가로출력 (sys_connect_by_path)
: 계층형 질의문에 유일한 짝꿍 함수 sys_connect_by_path
이 함수는 가로로 데이터를 출력하는 함수이다.
예제1.
다음과 같이 'sys_connect_by_path' 함수를 이용한 SQL을 작성하시오
select ename, sys_connect_by_path( ename, ',' )
from emp
start with ename ='KING'
connect by prior empno=mgr;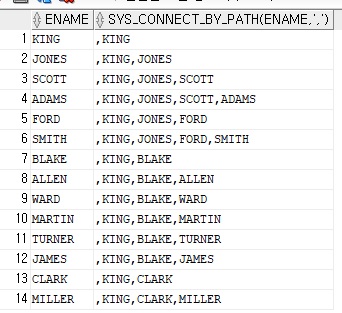
-> 팀내에서 서열상의 위치가 어떻게 되는지 보고 싶을 때 사용
문제 508.
위의 결과에서 ADAMS 만 출력하시오select ename, sys_connect_by_path( ename, ',' ) from emp start with ename ='KING' connect by prior empno=mgr and ename='ADAMS';라고 했는데 오답
select ename, sys_connect_by_path( ename, ',' ) from emp where ename = 'ADAMS' start with ename ='KING' connect by prior empno=mgr;connect 절에 쓰는거 아니고 where 절에 사용!
문제 509. (오라클 교제 연습문제)
위의 결과를 아래와 같이 출력하시오
ADAMS KING/JONES/SCOTT/ADAMSselect ename, substr(sys_connect_by_path( ename, '/' ) , 2, 10000) as 이름 from emp where ename = 'ADAMS' start with ename ='KING' connect by prior empno=mgr;
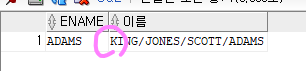
select ename, LTRIM(sys_connect_by_path( ename, '/' ), '/') as 이름
from emp
where ename = 'ADAMS'
start with ename ='KING'
connect by prior empno=mgr; LTRIM 사용해도 ㄱㅊ
※ 시험에서는 sys_connect_by_path 를 고르는 문제가 주로 나오니까 암기 하기
계층형 질의문에서 반드시 암기해야할 2가지 키워드
- order siblings by
- sys_connect_by_path
※ SQLD 기출문제에서 한번 언급된 계층형 질의문에 대한 함수 (기출문제 33회 출제)
connect_by_isleaf 함수? : 말단 사원인지 아닌지를 출력하는 함수
select level, rpad(' ',level*2) || ename, sal, connect_by_isleaf as isleaf
from emp
start with ename = 'KING'
connect by prior empno=mgr; 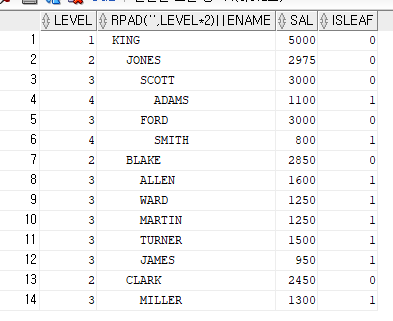
말단사원이면 1로 출력되고 아니면 0으로 출력된다. (그 소속에서 말단)
093. 일반 테이블 생성하기 (CREATE TABLE)
테이블의 종류 2가지
- 영구히 data를 저장하는 테이블
- 임시로 data를 저장하는 테이블
문법 : create table 테이블명
(컬럼명 데이터유형,
컬럼명 데이터유형 );
테이블명과 컬럼명 지을 때 주의사항
- 테이블명과 컬럼명은 반드시 문자로 시작해야 합니다.
- 테이블명의 길이는 30자를 넘을 수 없습니다.
- 테이블명 이름에 특수문자는 $, _, # 만 포함할 수 있습니다.
create table emp907
( empno number(10), -> 숫자를 10자리 허용하겠다
ename varchar2(20), -> 영문자 20자를 허용하겠다
sal number(10) );-
varchar 뒤에 2는 오라클에서 기본임
-
각 나라의 언어에 맞춰서 지원하는 문자형 데이터 유형 :
nvarchar(길이), ncahar(길이)
데이터 유형의 종류 3가지
- 문자형 : char , varchar2 , long , clob , blob
- 숫자형 : number
- 날짜형 : date
char 와 varchar2 의 차이 ☆★
char(10) varchar2(10)
M I R A C L 0 0 0 0 M I R A C L 0 0 0 0- CHAR : 고정형 데이터 유형
VARCHAR : 가변형 데이터 유형
모르고 E 못 넣었을때!
char는 뒤에 0000을 공백으로 채워진다.
varchar2 는 공백을 회수해간다. (공간절약)
그렇다고 다 varchar2 로 하는게 좋은건 아니다.
어느날 E가 빠졌다는걸 알게됐을때,
char 는 E 를 업데이트 할 수 있다.
varchar2 는 바로 업데이트가 아니라 row 를 이전(이사) 시키는 현상이 나타난다. (=row migration)
=> 즉, 업데이트가 자주 일어날 것 같은 데이터라면 char 로 하는것이 좋고
그런 것이 아니라면 varchar2 를 사용하는 것이 좋다!
(최초 결정자는 data modeler (DBA출신))
근데 현업에서는 char 는 거의 없다. 왜? 이슈가 있었다! ★
char(10) varchar2(10)
1 0 □ □ □ □ □ □ □ □ 1 0 (공백회수)
그대로 char(10) -> varchar2(2) 가 된다.이렇게 되면 join 할 때 문제가 생긴다.
- 예시를 보기위한 테스트 스크립트 만들기
create table emp600
( ename varchar2(10),
sal number(10),
deptno varchar2(10) );
create table dept600
( deptno char(10),
loc varchar2(10) );
문제 510.
dept600 테이블에서 deptno 가 10번인 deptno 와 loc를 출력하시오
(dept600 의 deptno 는 char(10)로 만듬)select deptno, loc from dept600 where deptno = '10';여기서 '10'은 char(2) 인데,
'10□□□□□□□□' 로 작성하지 않아도 결과 나옴 => 내부적으로 공백을 채워서 결과를 출력했다.
문제 511.
emp600 테이블에서 deptno 가 10번인 사원들의 ename, sal 을 출력하시오
(emp600의 deptno 는 varchar(10) 로 만듬)select ename, sal from emp600 where deptno = '10';공백을 자동으로 회수해갔기 때문에 결과값 제대로 나온다.
문제 512.
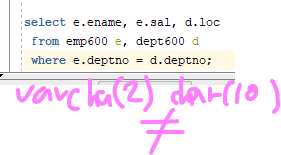
dept600 테이블과 emp600 테이블을 서로 조인해서 ename, sal, loc를 출력하시오select e.ename, e.sal, d.loc from emp600 e, dept600 d where e.deptno = d.deptno;데이터 아무것도 결과 나오지 않았다.
왼쪽이 공백회수되어, varchar2(2) 가 되었기 때문에!!
※ varchar2, char 정리!! ※
emp600 에서 deptno 번호 10번은 잘 조회되고, dept600에서 deptno 번호 10번은 잘조회가 되지만,
조인을 했을 때는 결과가 안나온다.
왜냐면 varchar2(2) 가 char(10)을 맞춰주기 위해서 공백 8개를 채우지 않는다.
그래서 위와같은 현상이 일어나지 않게 하려고 대부분 varchar2 로 테이블 설계를 한다.
그러면, row migration 현상은???
데이터가 조인되어서 안보이는 문제가 더 심각하지 이런 작은 성능상의 이슈보다는 데이터를 출력하는게 더 중요하기 때문에 크게 신경쓰지 않는다.
데이터 유형 (책에있음)
char: 고정길이 문자 데이터 유형, 최대 길이는 2000varchar: 가변길이 문자 데이터 유형, 최대길이는 4000long: 가변길이 문자 데이터 유형, 2gb의 문자 데이터 허용clob: 문자 데이터 유형이며 최대 4gb의 바이너리 데이터 허용blob: 바이너리 데이터 유형이며 최대 4gb의 바이너리 데이터 허용number: 숫자데이터 유형의 십진 숫자의 자리수는 최대 38자리까지 허용, 소숫점 이하 자리 -84 ~ 127까지 허용date: 날짜 데이터 유형, 기원전 4712년 1월 1일부터 기원후 9999년 12월 31일까지의 날짜를 허용
괄호열고 써주는건 char(), varchar2() , number()밖에 없음!
데이터 마이그레이션 할 때 중요하게 생각해야하는 것이 long, clob 임. (데이터 이행을 위해 알아두어야 함)
char, varchar2는 데이터 모델링할 때 알아두어야하는것이 좋다.
책 참고해서 풀기!
문제 513. 스티브 잡스 연설문을 db에 저장하기 위해, 아래와 같이 테이블을 생성하시오
create table steve_jobs ( s_text long);
문제 514. steve_jobs테이블에 스티브 잡스 연설문을 입력하시오
연설문 다운
새로고침

- 안들어가서 drop했음!
clob으로 다시생성 -> 근데 이것도 안됨
create table steve_jobs
(s_text clob);
----------------------------------
create table steve_jobs
(s_text varchar(4000) ); ---> 이거로 넣었음※ 큰 텍스트 데이터를 입력할 때는 long, clob, varchar2(4000) 중 하나를 선택해서 오류가 없는것으로 데이터를 넣으면 된다.
문제 515. 우리반 데이터를 입력하기 위한 테이블을 emp17_my로 생성하기
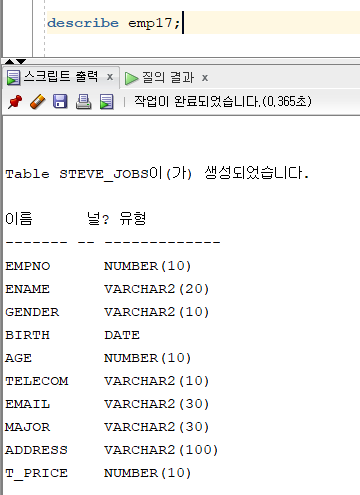
create table emp17_my ( EMPNO number(10), ENAME varchar2(10), GENDER varchar2(5), BIRTH date, AGE number(10), TELECOM varchar2(10), EMAIL varchar2(100), MAJOR varchar(50), ADDRESS varchar(200) );
- 보통 아래처럼 테이블정의서를 받게되는데 보고 그대로 만들어주면 된다.
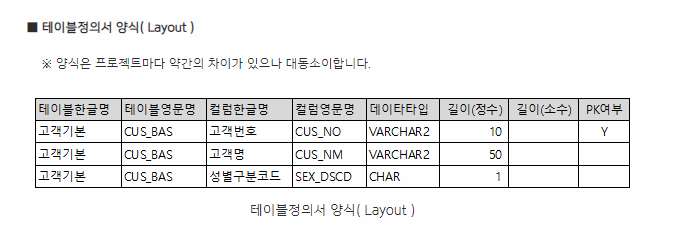
문제 516. 위 emp17_my 테이블에 emp17 테이블의 데이터를 입력하시오(t_price빼고) -> sub query insert 사용
insert into emp17_my(empno, ename, gender, birth, age, telecom, email, major, address) select empno, ename, gender, birth, age, telecom, email, major, address from emp17; commit;
- 서브쿼리 사용하면 values 쓰지 않고 넣을 수 있다.
문제 517.
dept테이블의 data를 입력하기 위한 dept_my테이블을 생성하고, dept의 모든 데이터를 dept_my 테이블에 입력하시오
describe dept; -> dept테이블 확인해서 컬럼명 보기
create table dept_my -> dept_my테이블 생성 ( DEPTNO NUMBER(10), DNAME VARCHAR2(10), LOC VARCHAR2(20) );insert into dept_my (DEPTNO, DNAME, LOC) select DEPTNO, DNAME, LOC from dept;
- VARCHAR2처럼 NUMBER도 가변형이다. 글자수 넉넉히 주자

문제 518. 아래의 데이터를 dept_my 데이터에 입력하세요
부서번호 : 50
부서명 : hr
부서위치 : Chaubunagungamaug
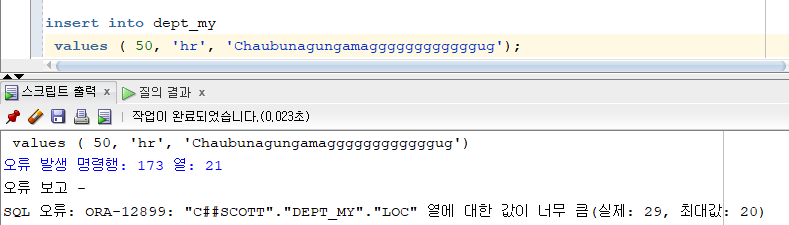
- 만약 내가 만든 길이보다 데이터가 길면 이렇게 에러가 난다.
dba가 반드시 알아야할 컬럼 추가/변경 명령어
1. 컬럼 추가 (add)
예제. emp 테이블에 email 라는 컬럼 추가
alter table emp
add email varchar2(30);2. 컬럼 삭제 (drop column)
예제. emp 테이블에 sal 컬럼을 삭제
alter table emp
drop column sal;★ 컬럼삭제는 한번 삭제되면 flashback이나 rollback이 안된다. 조심하기!!!! ★
3. 컬럼 변경 (modify)
예제. emp 테이블의 job의 컬럼의 길이를 varchar2(50)로 늘리시오
alter table emp modify job varchar2(50);
- 늘리는것은 잘 되지만, 줄이는것은 데이터가 자리를 확보하고 있으면 줄일 수 없다.
문제 519. (dba에게 들어오는 요청) dept_my 테이블 loc 컬럼의 길이를 varchar2(50) 으로 늘리시오!
-> 얘도 테이블정의서처럼 온다.
문법
alter table dept_my // alter + table + 컬럼명 modify loc varchar2(50); // modify + 컬럼명 + 데이터유형
- 주의사항 !!! 위 alter문을 이용한 변경작업은, dba가 낮에 업무시간(한참 바쁠 때) 수행하면 안된다. db가 한가한 밤이나 주말에 수행해야 한다. -> 낮에하면 db엄청 느려짐. -> 크론이라고 예약어쩌고 처럼 몇시에 되도록 설정해놓는 경우가 많음
문제 520. emp테이블에 enmae에 문자의 길이를 varchar2(60)으로 변경해보기
alter table emp modify ename varchar2(60);
- dba는 위와 같은 변경사항에 대한 이력은 별도의 테이블로 만들어서 관리하면 나중에 db쪽 감사가 있거나 이력을 확인하고 싶을 때 쉽게 확인이 가능하다. SI프로젝트시 주로 감사는 받는데, 테이블 정의서 (엑셀파일) 와 실제 DB가 일치하는지 확인을 한다.
일치하는지 확인 ----> PL/SQL, 파이썬 엑셀 테이블 정의서 ------------------------------------------- 물리적 db 설계
문제 521. emp table에 address라는 컬럼을 varchar2(30)으로 추가
alter table emp add address varchar2(30);
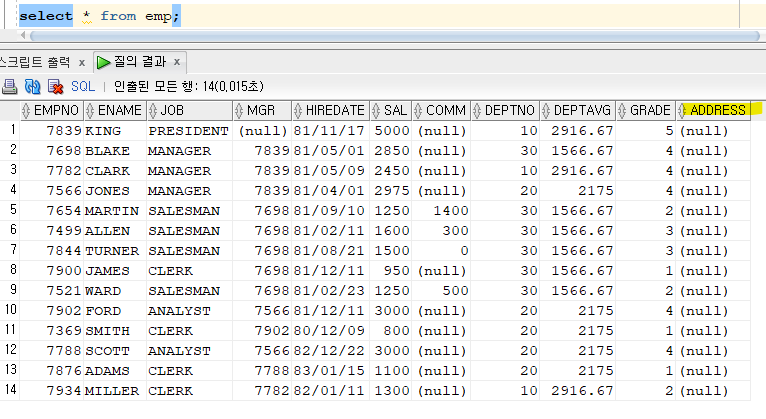
문제 522. 위에서 추가한 address 컬럼을 삭제
alter table emp drop column address;
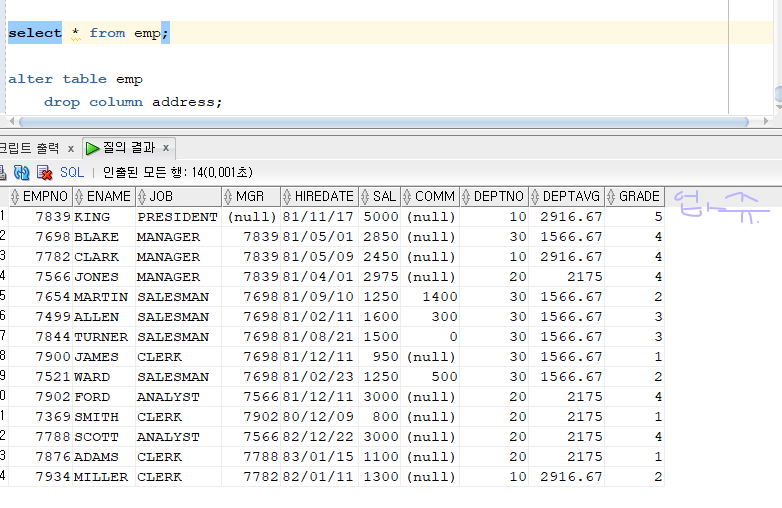
문제 523. emp 테이블의 sal 컬럼을 삭제해보기 (sal은 데이터가 있었음)
alter table emp drop column sal;
- rollback; 이랑 flashback도 불가
alter table emp enable row movement; flashback table emp to timestamp ( systimestamp - interval '5' minute);
- 해결방법 : 백업 솔루션에서 받은 백업본으로 복구를 하면 됩니다. 백업 솔루션을 안쓰는 회사는, 수업 때 배운
백업과 복구방법으로 복구하면 됨!
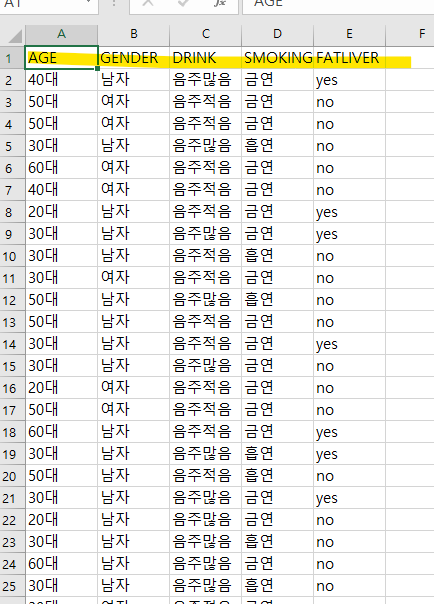
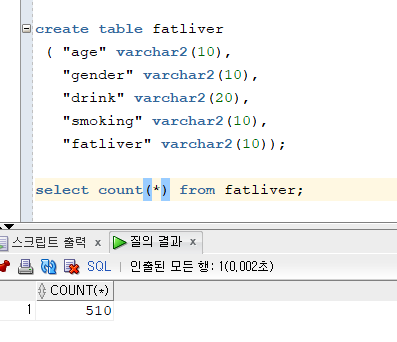
문제 524. (마지막 문제) 데이터 게시판의 388번의 지방간 데이터를 저장할 테이블을 생성하고, 데이터를 입력하시오. (테이블명: fatliver, 컬럼명 알아서)
자료 다운
create table fatliver ( "age" varchar2(10), "gender" varchar2(10), "drink" varchar2(20), "smoking" varchar2(10), "fatliver" varchar2(10));