230705 Oracle SQL 8 [서브쿼리 EXISTS, DB link]
(7월 5일 점심시간 문제)
우리반 테이블에서 남양주에서 사는 학생들과 나이가 같고 통신사가 같은 학생들의 이름과 나이와 통신사를 출력하시오. (출력하고 결과가 같은지 짝꿍과 비교해보세요)
- non pairwise 방식
select ename, age, telecom
from emp17
where age in ( select age
from emp17
where substr(address, 1, 3) = '남양주'
and telecom in (select telecom
from emp17
where substr(address, 1, 3) = '남양주';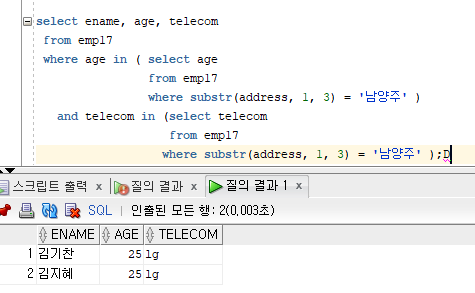
- pairwise 방식
select ename, age, telecom
from emp17
where ( age, telecom ) in ( select age, telecom
from emp17
where substr(address, 1, 3) = '남양주') ;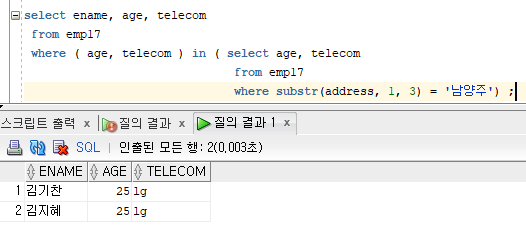
복습
※ 서브쿼리 사용시 not in 사용하면 서브쿼리에서 메인쿼리로 null 값이 리턴되지 않도록 주의해야한다.
074. 서브쿼리 사용하기 4 (EXISTS와 NOT EXISTS)
짝꿍의 emp 테이블에는 존재하는데 나의 emp 테이블에는 존재하지 않는 데이터가 무엇인지 확인하고 싶다면?
- minus
- exists 와 not exists
예제. minus 를 이용해서 부서 테이블에는 존재하는데 사원테이블에는 존재하지 않는 부서번호를 출력하시오
dept - emp
10 10
20 20
30 30
40
select deptno from dept
minus
select deptno from emp;
- minus 는 위와 같이 두 테이블의 데이터의 차이를 확인하고 싶을 때 사용한다.
(운영 DB와 테스트 DB)
※ db link 이름 확인하는법 : select * from dba_db_links;
문제 386. (테스트db쪽에서)
운영 DB의 테이블을 엑세스 하기 위한 db링크를 생성하시오create public database link dblink_swk connect to c##scott identified by tiger using '192.168.19.24:1521/xe' ; -> 운영 db의 아이피주소:포트번호/db이름
※ db link 된 테이블들 확인하는법 : select * from tab@dblink_swk;
문제 387. (테스트db쪽에서)
운영 db쪽에 있는 emp 테이블을 테스틑 db에 다음과 같이 생성하시오create table emp_swk as select * from emp@dblinks_swk;
select * from emp_swk;
>
>
문제 388. (테스트db쪽에서)
테스트db에 emp 테이블과 운영 db의 emp 테이블의 차이를 확인하시오
**(운영 DB 에는 존재하는 데이터인데, 테스트 DB 에는 존재하지 않는 데이터를 검색하시오)**select from emp@dblink_swk
minus
select from emp;
>
>
문제 389. (테스트db쪽에서)
운영 db emp 테이블에는 존재하는데, 테스트 db의 emp 테이블에는 존재하지 않는 데이터를 운영 db의 emp 테이블에 입력하시오.insert into emp
select from emp@dblink_swk
minus
select from emp;
commit;
insert 밑에 values 쓰면 X
truncate, insert into (다른 테이블 데이터로 교체하기)
문제 390. (테스트db쪽에서)
테스트 db에 emp 테이블을 truncate 하세요.
truncate 를 수행하면 데이터는 다 지워지고 테이블 구조만 남습니다.)
truncate table emp; select * from emp;
문제 391. (테스트db쪽)
운영 db의 emp 테이블을 테스트 db 의 emp 테이블에 입력하시오insert in emp select * from emp@dblink_swk; select * from emp; commit;
문제 392.
dept 테이블에서 부서번호를 출력하는데, emp 테이블에 존재하는 부서번호들만 출력하시오select deptno from dept d where exists ( select 'X' from emp e where e.deptno = d.deptno );
exists 의 작동원리
- 메인쿼리의 table 을 먼저 select (dept 테이블)
- 10번이 emp 테이블에 존재하는지 찾아본다. where e.deptno = 10 으로 수행
처음 찾게되면 그 이후에는 안찾는다. -> 그래서 속도가 빠름
그 다음 20,30... 찾는다.
-
위와 같이 exists문을 사용하게 되면 메인쿼리의 테이블부터 먼저 엑세스를 하면서 부서번호가 10번이 emp 테이블에 존재하는지 찾아보게 되는데,
존재하면 더이상 스캔하지 않고 멈춘다. 20번과 30번, 40번 도 마찬가지로 존재하는걸 발견하면 멈춘다. -
그래서 검색 성능이 좋은데, 그냥 다 좋은건 아니고 '메인쿼리의 데이터의 건수가 몇건 되지 않을 때' 좋은 검색 속도를 보인다.
-
서브쿼리에서는 원래 테이블 별칭 (e, d) 쓰지 않는데, exists 는 사용한다.
메인 쿼리의 컬럼이 서브쿼리에 들어간다. -
where 절에 컬럼이름 안쓰는 유일한 sql -> exists
-
'X' 자리에 컬럼명이던 다른 문자던 아무거나 적어도 상관없음
문제 393.
telecom_table 에서 통신사를 출력하는데
우리반 emp17 테이블에 존재하는 통신사만 출력하시오select telecom from telecom_table t where exists ( select * from emp17 e where e.telecom = t.telecom) ;(질문)!! where 에 emp17에 있는 통신사가 더 적으니까,
e.telecom (+) 해야하는거 아닌가요? -> 중복되면 되는거같음
not exists
문제 394.
telecom_table 에는 존재하는 통신사인데
emp17에는 존재하지 않는 통신사를 출력하시오select telecom from telecom_table t where not exists ( select * from emp17 e where e.telecom = t.telecom) ;
문제 395. 운영db의 emp테이블에는 존재하는 사원번호인데
테스트 db의 emp테이블에는 존재하지 않는 사원번호가 무엇인가?select empno from emp@dblink_swk e2 where not exists ( select * from emp17 e1 where e1.empno = e2.empno);(운영 db (짝꿍) : emp@dblink_swk
테스트 db (나) : 내 emp 테이블)
문제 397. (OCP 시험용 테이블)
HR 계정에 departments 테이블에는 있는 department_id 인데,
employees 테이블에는 존재하지 않는 department_id 를 출력하시오select department_id from hr.departments d where not exists ( select * from hr.employees e where d.department_id = e.department_id );
문제 398. dept 테이블에서 부서번호를 출력하는데
emp 테이블에 있는 부서번호만 출력하시오
(exists를 이용해서 수행하고, in 을 이용해서 수행)
1.existsselect deptno from dept d where exists ( select * from emp e where d.deptno = e.deptno);
inselect deptno from dept where deptno in (select deptno from emp);
exists 와 in 의 차이
exists 는 메인쿼리에서 발견하고 나면 바로 스캔 멈춘다.
in 은 서브쿼리부터 시작해서 메인쿼리까지 다 스캔한다.
exists 가 훨씬 속도가 빠르다.
-> in 사용했다가 느리면 exists 로 튜닝하면 됨
문제 399.
dept 테이블에서 deptno 를 출력하는데,
dept 테이블에는 존재하는데 emp 테이블에는 존재하지 않는 deptno 를 출력하시오
(exists 와 not in 둘다 해보기)
1. existsselect deptno from dept d where not exists ( select * from emp e where d.deptno = e.deptno);
- not in
select deptno from dept where deptno not in ( select deptno from emp where deptno is not null) ;`not in` 을 사용할때는 nulls 값 처리를 위해 is not null 붙여주기!
※ (dba 관점에서 sql 을 사용할 때) 두 테이블 사이에 차이가 나는 데이터가 무엇인지 확인하고 싶을 때 사용하는 SQL은?
차이나는 데이터 찾기
- exists 와 not exists
- minus
select deptno from dept
minus
select deptno from emp;로도 사용가능
테이블 백업 (backup)
문제 400.
emp 테이블을 백업을 하시오 (emp_backup)create table emp_backup as select * from emp; select * from emp_backup;
문제 401.
emp 테이블의 데이터중 부서번호가 20번인 사원들을 지우고 commit 하시오delete from emp where deptno = 20; commit;
문제 402.
emp 테이블과 emp_backup의 데이터의 차이를 확인하시오
( minus, exists, not exists 중..)select * from emp_backup minus select * from emp;select * from emp minus select * from emp_backup;둘다 빼서 확인하기!
복구하기
insert into emp
select * from emp_backup
minus
select * from emp;관련된 19C OCP SQL 시험문제 (1z0-082-1)
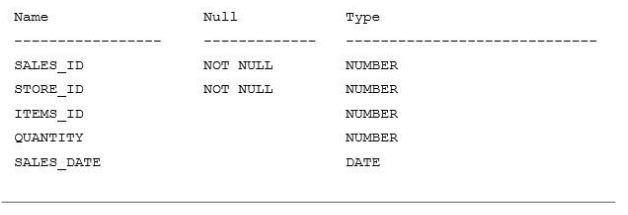
NO.48 Examine the description of the SALES1 table
SALES2 is a table with the same description as SALES1.
Some sales data is duplicated in both tables.
You want to display the rows from the SALES1 table which are not present in the SALES2 table.
Which set operator generates the required output?SALESS2 표에 없는 SALES1 표의 행을 표시하려고 합니다. 필요한 출력을 생성하는 세트 연산자는 무엇입니까?A. INTERSECT
B. UNION ALL
C. UNION
D. SUBTRACT
E. MINUS-> NOT EXISTS 혹은 MINUS 사용해야 하기 때문에 E!
075. 서브쿼리 사용하기 5 (HAVING 절의 서브쿼리)
select 문의 6가지 절에서 서브쿼리를 쓸 수 있는 절?
select 서브쿼리 사용 가능 (scalar subquery)
from 서브쿼리 사용 가능 (in line view)
where 서브쿼리 사용 가능 subquery
group by
having 서브쿼리 사용 가능 (scalar subquery)
order by 서브쿼리 사용 가능 (scalar subquery)
- group by 만 빼고는 다 사용 가능하다.
- scalar subquery : 확장된 서브쿼리 (where 절에만 쓸수 있는게 아니라 확장해서 쓸수 있다는 의미)
문제 403.
직업, 직업별 토탈월급을 출력하시오select job, sum(sal) from emp group by job;
문제 404.
직업과 직업별 토탈월급을 출력하는데, 직업이 SALESMAN 인 사원들의 토탈월급보다 더 큰 사원들만 출력하시오select job, sum(sal) from emp where sum(sal) > (select sum(sal) from emp where job = 'SALESMAN') group by job;
- where 절에는 그룹함수로 검색조건을 줄 수 없다.

그룹함수 서브쿼리 (having 절)
select job, sum(sal)
from emp
group by job
having sum(sal) > (select sum(sal)
from emp
where job ='SALESMAN') ;문제 405.
통신사, 통신사별 인원수를 출력하는데 통신사별 인원수가 lg의 인원수보다 큰 것만 출력하시오.select telecom, count(*) from emp17 group by telecom having count(*) > ( select count(*) from emp17 where telecom ='lg');
문제 406. (복습문제)
직업, 직업별 최대월급, 직업별 최소월급, 직업별 토탈월급, 직업별 인원수를 출력하시오select job, max(sal), min(sal), sum(sal), count(*) from emp group by job;
문제 407. 이름, 월급, 월급에 대한 순위를 출력하시오
select ename, sal, dense_rank() over (order by sal desc) as 순위 from emp;
문제 408. 위의 결과에서 순위가 3등과 5등을 출력하시오
select ename, sal, dense_rank() over (order by sal desc) as 순위 from emp where 순위 in (3,5);
실행순서때문에 에러 (식별자 : 컬럼), 순위라는 컬럼이 더 늦게 만들어져서.select * from ( select ename, sal, dense_rank() over (order by sal desc) as 순위 from emp ) where 순위 in (3,5) ;from 절에서 먼저 '순위' 라는 컬럼이 만들어지게 한다음에 검색 조건을 실행되게 하는 것. (from 절 서브쿼리 사용)
문제 409.
직업, 이름, 월급, 순위를 출력하는데 순위가 직업별로 각각 월급이 높은 순서대로 순위를 부여하시오select job, ename, sal, dense_rank() over (partition by job order by sal desc) as 순위 from emp;group by 안써도됨!
순위 같은 데이터 분석함수를 쓸때는 over 뒤의 괄호안에 (partition by ) 필수!
문제 410.
위의 결과를 다시 출력하는데 순위가 1등인 사원들만 출력하시오.select * from ( select job, ename, sal, dense_rank () over (partition by job order by sal desc) 순위 from emp );
문제 411.복습 문제)
사원테이블의 평균월급을 출력하시오
select avg(sal)
from emp;
문제 412. 사원테이블에서 이름, 월급, 사원테이블의 평균월급을 출력하시오
select ename, sal, avg(sal) from emp;ORA-00937: 단일 그룹의 그룹 함수가 아닙니다
select ename, sal, avg(sal) over () as 평균월급 from emp;
문제 413. 위의 결과를 다시 출력하는데,
자기의 월급이 사원테이블의 평균월급보다 더 큰 사원들만 출력하시오select ename, sal, 평균월급 from ( select ename, sal, 평균월급 from emp ) where avg > 평균월급
문제 144. (복습문제)
부서번호, 부서번호별 평균월급을 출력하시오selete deptno, agv(sum) from emp group by deptno;
문제 145.
부서번호, 이름, 월급, 자기가 속한 부서번호의 평균 월급을 출력하시오.select deptno, ename, avg(sal) over (partition by deptno) 부서평균 from emp;
문제 416.
위의 결과를 다시 출력하는데, 자기의 월급이 자기의 부서번호의 평균월급들 보다큰 사원들만 출력해주세요select ename, sal, 부서평균 from ( select deptno, ename, sal, avg(sal) over (partition by deptno) 부서평균 from emp ) where sal > 부서평균;
문제 417. 위의 결과를 보기 위해서 다른 튜닝전 SQL로 출력하시오
select e.deptno, e.ename, e.sal, v.부서평균 from emp e, ( select deptno, avg(sal) 부서평균 from emp group by deptno ) v where e.deptno = v.deptno and e.sal > v.부서평균 ;
077. 서브쿼리 사용하기 7 (select 절의 서브쿼리)
-
from 절과 where 절 서브쿼리 다음으로 가장 많이씀
문제 418. 토탈월급을 출력하시오
select sum(sal) from emp;
문제 419. 이름, 월급, 토탈월급을 출력하시오
select ename, sal, sum(sal) from emp;ORA-00937: 단일 그룹의 그룹 함수가 아닙니다
select ename, sal, sum(sal) over () from emp;
over ()
: 확장해라
문제 420.
이름, 월급, 토탈월급을 출력하는데 select 절의 서브쿼리인 스칼라 서브쿼리를 이용해서 출력하시오select ename, sal, ( select sum(sal) from emp) as 토탈값 from emp;※ select 절의 서브쿼리인 스칼라 서브쿼리는 emp 테이블의 건수만큼
반복되면 수행 됩니다.
여기서부터 조퇴함
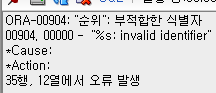
select ename, sal, ( select sum(sal) from emp ) as 토탈값
from emp
where job='SALESMAN'; 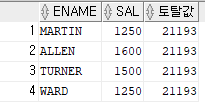
-> 이름, 월급, 토탈월급 출력 + 직업이 salesman 인 사람들
아래의 2개의 SQL의 버퍼의 갯수를 각각 확인하시오 !
튜닝전:select /*+ gather_plan_statistics */ ename, sal, ( select sum(sal) from emp ) as 토탈값 from emp; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));버퍼의 갯수 : 6개
튜닝후:select /*+ gather_plan_statistics */ ename, sal, sum(sal) over () as 토탈값 from emp; SELECT * FROM TABLE(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));버퍼의 갯수 : 6개
select ename, sal, ( select sum(sal) from emp ) as 토탈값
from emp;
select ename, sal, sum(sal) over () as 토탈값
from emp;
결과값, 버퍼값 똑같이 나옴
문제 421. 직업이 SALESMAN 인 사원들의 토탈월급을 출력하시오
select sum(sal) from emp where job='SALESMAN' ;
문제 422.
이름, 월급, 직업이 SALESMAN인 사원들의 토탈월급을 출력하시오select ename, sal ( select sum(sal) from emp where job='SALESMAN' ) as "SALES토탈" from emp;
- 이 코드는 튜닝을 할 수 없다. WHERE절이 있어서 그런가?
아래 코드는 튜닝후 코드인데 여기 아래코드에서 where 절을 쓸 자리가 없다.select ename, sal, sum(sal) over() as 토탈값 from emp; ----------------------------------------- select ename, sal, sum(sal) over() as 토탈값 from emp where job = 'SALESMAN'; // 이거 안됨
문제 423. 이름, 월급, 직업이 SALESMAN 인 사원들의 토탈월급,
직업이 SALESMAN 인 사원들의 최대월급,
직업이 SALESMAN 인 사원들의 최소월급을 출력하시오select ename, sal, ( select sum(sal) from emp where job='SALESMAN' ), ( select max(sal) from emp where job='SALESMAN' ), ( select min(sal) from emp where job='SALESMAN' ) from emp;
** 위의 SQL의 문제점은 emp 테이블의 건수만큼 스칼라 서브쿼리의 select 문장이 반복된다는 것 입니다. emp 테이블을 각각 3번을 엑세스를 하고있습니다.
select sum(sal), max(sal), min(sal)
from emp
where job='SALESMAN'; 위에 SQL처럼 emp 테이블을 3번 엑세스해서 데이터를 조회하지말고
다음과 같이 1번만 엑세스해서 데이터를 조회하시오
select ename, sal, ( select sum(sal), max(sal), min(sal)
from emp
where job='SALESMAN' )
from emp;- ORA-00913: 값의 수가 너무 많습니다
※ 스칼라 서브쿼리의 특징 ? 하나의 값만 출력할 수 있습니다.
무조건 출력되어야함 (null 값도?!)
select ename, sal, ( select sum(sal) || max(sal) || min(sal)
from emp
where job='SALESMAN' )
from emp;이렇게 넣으면 에러가 난다. 왜!?
★스칼라 서브쿼리의 특징임. 스칼라 서브쿼리는 하나의 값만 출력할 수 있다 !!!!★
문제424.
이름, 성별, 나이, 남자 나이의 평균값, 여자 나이의 평균값을 출력하시오 !select ename, gender, age, ( select avg(age) from emp17 where gender='남' ) 남자평균, ( select avg(age) from emp17 where gender='여' ) 여자평균, from emp17;
문제 425.
이름, 주소, 나이, 서울에서 사는 학생들의 평균나이,
서울이 아닌 곳에서 사는 학생들의 평균나이를 출력하시오select ename, address, age, ( select avg(age) from emp17 where address like '%서울%' ) as 서울평균, ( select avg(age) from emp17 where address not like '%서울%' ) as 외평균 from emp17;
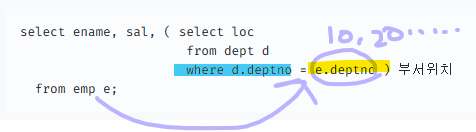
문제 426. 이름, 월급, 부서위치를 출력하시오
★스칼라 서브쿼리 가장 많이 쓰는 경우 - 약간어려움★
join 하지 않고 아래처럼 출력 가능select ename, sal, ( select loc from dept d where d.deptno = e.deptno ) 부서위치 from emp e;-> 다른 테이블에 있는 컬럼이랑 같이 출력하고 싶을떄?
- 스캇 월급 3000 뽑고 웨어절에서 스캇의 부서번호 뽑고 그 부서번호에 해당하는 부서위치를 출력한다.
아까는 그냥 독단적인데 위 경우는 메인테이블의 컬럼이 (emp table이 where절에 e.deptno 에 들어가서 데이터 검색하고 출력한다.)- 이경우 굳이 이렇게 스칼라 서브쿼리로 안하고 join이 낫다 !
★ 노란색을 먼저 메인쿼리의 from 절에서 뽑은 다음에, 서브쿼리 안의 where 절에 있는 deptno 랑 비교해서 뽑는.. 느낌! (이해됨?)ㅠㅠ
실행순서가 가장 밖에 있는 from 절이 먼저이다!
문제 427. 부서번호, 이름, 월급, 자기가 속한 부서번호의 평균월급을 출력하시오
select deptno, ename, sal, ( select avg(sal) from emp s where s.deptno = e.deptno ) 부서평균 from emp e;
문제 428.
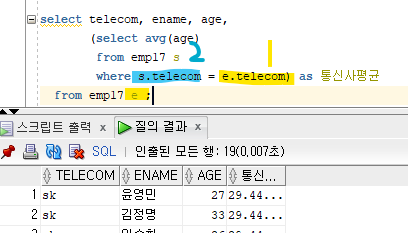
통신사, 이름, 나이, 자기가 속한 통신사의 평균나이를 출력하시오 !
( 스칼라 서브쿼리로 수행하세요 )
튜닝전select telecom, ename, age, (select avg(age) from emp17 s where s.telecom = e.telecom) as 통신사평균 from emp17 e ;
버퍼갯수 -> 20개
문제 429.
위의 SQL 을 스칼라 서브쿼리를 이용하지말고 데이터 분석 함수로 수행하시오
over (partition by __)
튜닝후select telecom, ename, age, avg(age) over (partition by telecom) as 통신사평균 from emp17;버퍼 갯수 -> 11개 로 더 적음
★ 스칼라 서브쿼리 (where = )
와 데이터 분석함수 avg() over (partition by )
구분 잘해서 써야할듯!? ㅠㅠ 비교 해보기
문제430. (오늘의 마지막 문제)
우리반 테이블에서 이름, 나이, 통신사, 성별,
자기가 속한 통신사의 평균나이, 자기의 성별의 평균나이를 출력하시오
( 스칼라 서브쿼리로 하세요 )select ename, age, telecom, gender, ( select round(avg(age)) from emp17 s where s.telecom = e.telecom ) 통신사별평균, ( select round(avg(age)) from emp17 s where s.gender = e.gender ) 성별별평균 from emp17 e;
