Q: Sigmoid와 tanh의 Vanishing Gradient 문제를 수식과 함께 설명 & 해결 방법
Sigmoid, tanh 등 활성화함수에 관한 자세한 내용은 여기서 보실 수 있습니다.
수식을 통한 설명
Sigmoid의 미분
- 전개

- Sigmoid의 도함수 그래프
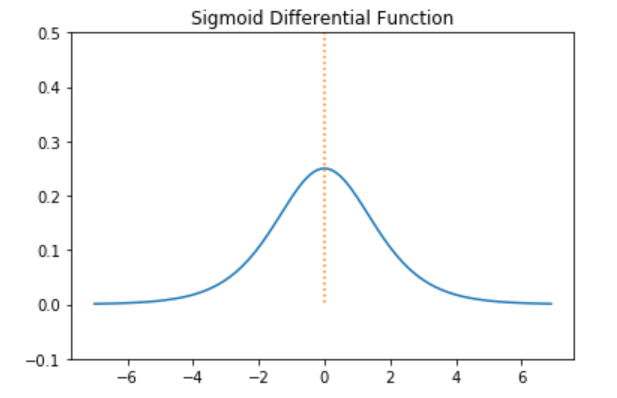
- Sigmoid 미분값 범위 : (0, 0.25]
tanh의 미분
- 전개
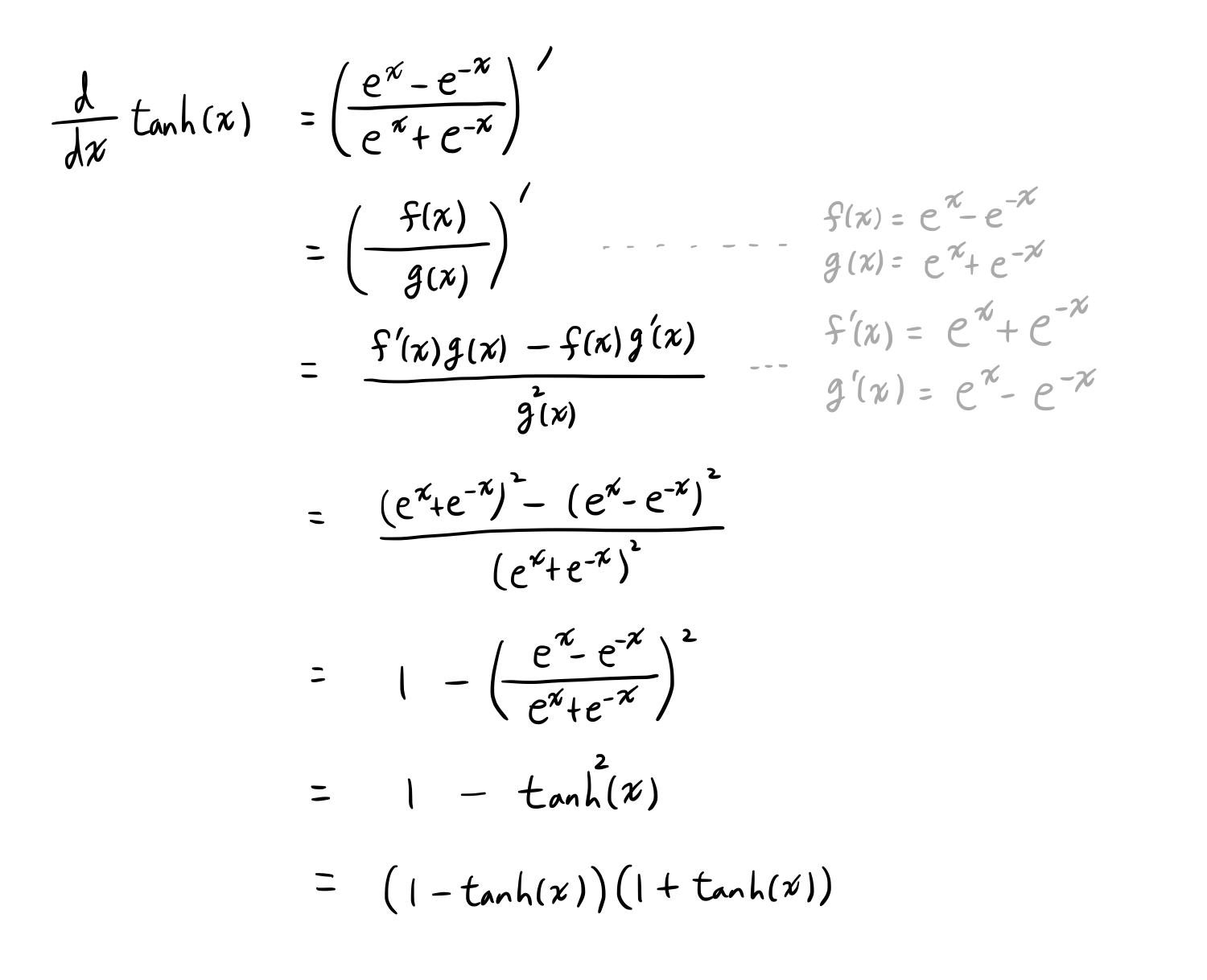
- tanh의 도함수 그래프
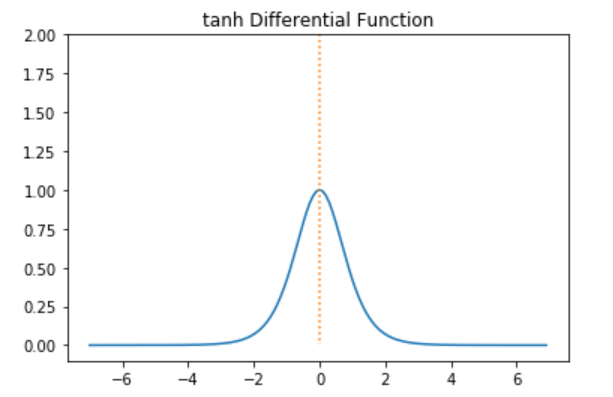
- tanh의 미분값 범위 : (0, 1]
back propagation 과정에서 연쇄적으로 활성화함수의 미분값을 곱해야 하는데, Sigmoid와 tanh은 미분 최대값이 작기 때문에 층이 깊을수록 값이 작아져 최소까지 업데이트할 수 없는 문제가 발생한다. 이를 기울기 소실, Vanishing Gradient라고 한다.
이 문제를 ReLU 활성화함수를 통해 해결할 수 있다.
Rectified Linear Unit (ReLU)
{kind=link}
{kind=link}
ReLU의 미분
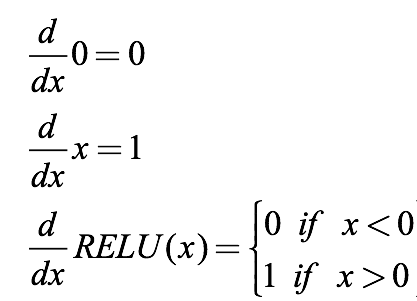
- ReLU의 도함수 그래프
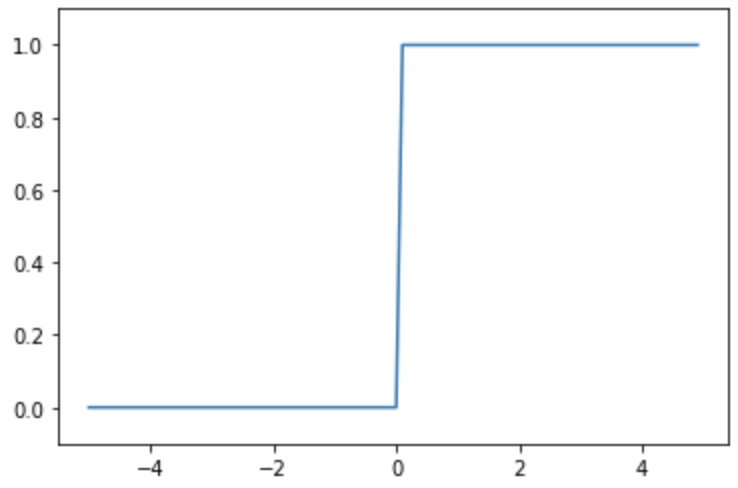
미분을 해도 값이 그대로 유지된다.
+) RNN에서 ReLU 대신 Sigmoid나 tanh 쓰는 이유 :
RNN은 CNN과 달리 이전 step의 값을 가져와서 사용하므로 ReLU를 쓰게되면 이전 값이 커짐에 따라 전체적인 출력이 발산하는 문제가 생길 수 있다. 따라서 과거의 값들을 재귀적으로 사용하는 RNN 모델에서는 이를 normalizing 하는 것이 필요하며 이를 위해 sigmoid보다 기울기의 역전파가 더 잘되는 tanh를 사용함으로써 좋은 결과를 볼 수 있다고 한다.
reference
https://limitsinx.tistory.com/62

NLP Researcher / Information Retrieval / Search