Text의 Semantic 의미를 잘 보존할 수 있는 Sentence Transformers의 몇가지 모델을 활용해서 다국어를 임베딩하고 유사도를 계산해보았다.
sbert documents에 나와있는 성능비교표는 다음과 같다.
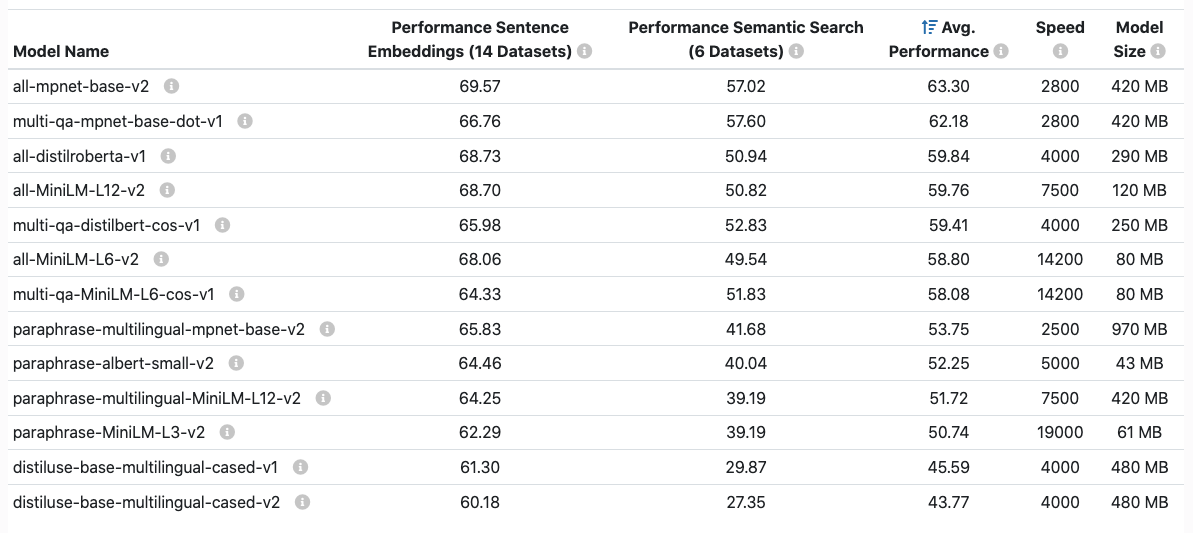
가장 위에 있는 all-mpnet-base-v2나 이보다 5배 빠른 all-MiniLM-L6-2v 모델은 다국어에 적합하지 않다.
영어 성능이 좋은 모델들이다.
따라서 multilingual 문서에 적합한 모델을 아래 예시 문장들간의 cosine similarity를 구해 성능을 비교해볼 것이다.
sentences = ["안녕 나는 게임을 좋아해", # Source Sentence
"hello i like to play games" , "こんにちは私はゲームが好きです", "嗨,我喜欢这个游戏", # 같은 의미 다국어 문장
"嗨,我喜欢读书", "こんにちは私は読書が大好き", "안녕 나는 책을 좋아해", # 다른 의미의 다국어 문장
"hi i like playing games and reading"]성능 비교
모델은 위 성능표에서 하위 모델부터 작성하겠다.
- 언어: 한국어, 영어, 일본어, 중국어(간체)
- source sentence: "안녕 나는 게임을 좋아해"
1. distiluse-base-multilingual-cased-v1
Execute time: 1.225
같은 의미
hello i like to play games: 0.856
こんにちは私はゲームが好きです: 0.793
嗨,我喜欢这个游戏: 0.751
다른 의미
안녕 나는 책을 좋아해: 0.564
嗨,我喜欢读书: 0.461
こんにちは私は読書が大好き: 0.453
같은 의미와 다른 내용이 포함된 문장
hi i like playing games and reading: 0.701
2. distiluse-base-multilingual-cased-v2
Execute time: 1.193
같은 의미
こんにちは私はゲームが好きです: 0.957
hello i lie to play games: 0.895
嗨,我喜欢这个游戏: 0.758
다른 의미
안녕 나는 책을 좋아해: 0.684
こんにちは私は読書が大好き: 0.652
嗨,我喜欢读书: 0.583
같은 의미와 다른 내용이 포함된 문장
hi i like playing games and reading: 0.749
3. paraphrase-multilingual-MiniLM-L12-v2
Execute time: 2.962
같은 의미
嗨,我喜欢这个游戏: 0.918
こんにちは私はゲームが好きです: 0.907
hello i like to play games: 0.818
다른 의미
嗨,我喜欢读书: 0.585
こんにちは私は読書が大好き: 0.537
안녕 나는 책을 좋아해: 0.505
같은 의미와 다른 내용이 포함된 문장
hi i like playing games and reading: 0.701
4. paraphrase-multilingual-mpnet-base-v2
Execute time: 4.404
같은 의미
こんにちは私はゲームが好きです: 0.986
hello i like to play games: 0.951
嗨,我喜欢这个游戏: 0.885
다른 의미
嗨,我喜欢读书: 0.566
안녕 나는 책을 좋아해: 0.517
こんにちは私は読書が大好き: 0.504
같은 의미와 다른 내용이 포함된 문장
hi i like playing games and reading: 0.836
결론
확실히 4번 paraphrase-multilingual-mpnet-base-v2 모델의 performance가 가장 좋았다. 하지만 속도가 다른 모델에 비해 느리다.
3번 paraphrase-multilingual-MiniLM-L12-v2 모델은 1,2에 비해 확실히 성능이 좋지만 4번보다 속도가 빠르다.
-> multilingual semantic search나 clustering을 해야 한다면 나는 3번 paraphrase-multilingual-MiniLM-L12-v2을 활용할 것 같다.

이런 유용한 정보를 나눠주셔서 감사합니다.