[Data Mining] 범죄량에 따른 아파트 실거래가 분석 📉
범죄량에 따른 아파트 실거래가 분석 과정 🏡
- 서울시 5개 구에 대한 실거래가 데이터 정제
- 서울시 5개 구에 대한 5대 범죄 발생 데이터 정제
- 1, 2번에서 정제된 데이터로 데이터 분석
- 실거래가와 범죄량과의 상관관계 분석
- 최종적인 결과와 해당 요인 분석
💻 사용 tool: Anaconda 가상환경, VS CODE, Pandas library
1. 서울시 5개 구에 대한 실거래가 데이터 정제
사용할 공공데이터 셋
서울시 부동산 실거래가 정보 👈 서울 부동산 정보광장에서 제공하는 서울특별시 부동산 실거래가 정보이다.
제공되는 Data: 접수년도, 자치구 코드, 자치구명, 법정동명, 지번구분명, 본번, 부번, 건물명, 계약일, 물건금액(만원), 건물면적(m^2), 토지면적(m^2), 층, 권리구분, 건축년도, 건물용도, 신고구분, 신고한 개업공인중개사 시군구명
📊 필요한 Data: 접수년도, 자치구명, 물건금액, 건물면적, 건물용도
서울시 강남, 구로, 종로, 마포, 강북 총 5개의 구에 대하여 분석을 실행함으로 자치구명이 필수적으로 필요하다.
상가나 주택 등 토지면적이 물건금액에 영향을 끼치는 Data가 다수 있으므로 아파트에 대해서만 분석을 진행하였다. -> 건물용도:"아파트"로 정제
21, 20, 19년도에 Data에 대해서만 분석을 진행한다. -> 접수년도로 정제
💾 추가적으로, 실거래가/건물면적 의 Data도 해당 추출 행에 추가하였다.
1. pandas를 이용하여 실거래가 Data를 DataFrame에 저장하기
import pandas as pd
data=pd.read_csv('data\서울시 부동산 실거래가 정보.csv')pandas 라이브러리를 import하여 read_csv 함수를 통해 csv 형태의 데이터를 읽어와 pandas DataFrame에 저장한다.
이때, 오류가 발생했다.
🚨 UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc1 in position 1: invalid start byte
-> 현재 데이터가 저장된 csv 파일에서 한글을 사용하고 있어서 발생하는 문제이다.
🚨 DtypeWarning: Columns (5,17,18) have mixed types. Specify dtype option on import or set low_memory=False.
-> column type을 추론할 때 여러 data type이 섞여있는 경우에 발생하는 문제이다.
첫번째 에러는 read_csv 수행 시에, encoding type을 지정함으로써 해결할 수 있다.
두번째 에러는 컴파일러가 추천해준 대로 low_memory=False로 지정함으로써 해결할 수 있다.
🚩 두번째 에러를 해결하기 위한 올바른 방법은 모든 data type을 명시하는 것인데 컬럼의 수가 너무 많아서 굳이 시도하진 않았다. 만약 중요한 데이터라면 data type을 명시하여 사용하는 것이 올바르다.
import pandas as pd
data=pd.read_csv('data\서울시 부동산 실거래가 정보.csv', encoding='cp949', low_memory=False)결과적으로 위와 같은 형태로 data를 읽어올 수 있다.
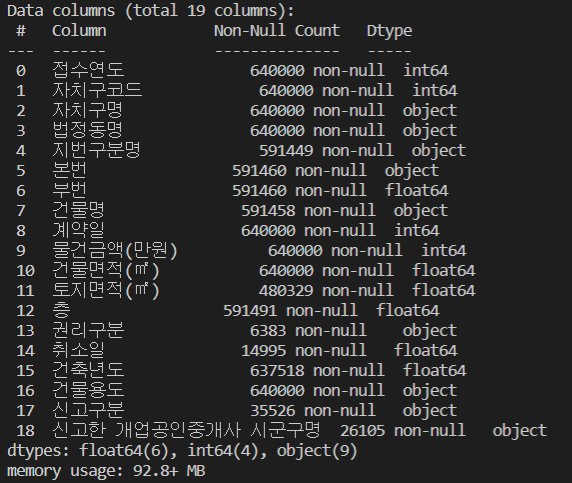
info 함수를 이용하여 컬럼 정보를 출력하면 위와 같이 확인할 수 있다.
2. 필요한 column에 대하여 data 추출
필요한 column: 접수연도, 자치구명, 물건금액(만원), 건물면적, 건물용도
baseData=data[['접수연도','자치구명','물건금액(만원)','건물면적(㎡)','건물용도']]3. 읽어온 DataFrame에서 데이터 정제
🚦 정제 조건
1. 접수연도가 19~21년인 데이터
2. 자치구명이 강남구, 구로구, 종로구, 마포구, 강북구인 데이터
3. 건물용도가 아파트인 데이터
target=['강남구','구로구','종로구','마포구','강북구']
refinedData=baseData[(baseData['자치구명'].isin(target))&(baseData['건물용도']=='아파트')\
&(baseData['접수연도']>=2019)&(baseData['접수연도']<=2021)]🚨 warning
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
로 데이터를 정제하는 과정에서 baseData['자치구명'] 이런 식으로 하는 표현은 Data를 복사해온다. 이 과정에서 Data를 수정한다면 어떠한 Data(원본 or 복사된)가 수정될지 몰라 warning을 보내는 것이다.
Data를 수정할 건 아니라 warning은 무시했다.
만약 Data를 수정해야 한다면 copy하여 사용하는 것이 올바르다.
4. 평당 거래가 column 추가
거래가를 계산하기 위해서는 평당 거래가를 알아야 하기 때문에 모든 행에 평당 거래가 column을 추가하였다.
refinedData['평당가격(만원)']=refinedData['물건금액(만원)']/refinedData['건물면적(㎡)']5. 1~4까지의 과정을 거친 Data를 내보내기
to_csv 를 이용하여 Data를 csv 파일로 내보냈다.
refinedData.to_csv('data\서울시 5개구 정제 실거래가 데이터.csv',index=False,encoding='cp949')index는 필요하지 않아서 추가하지 않았다.
6. 5개의 구에서 년도별 평균 실거래가 데이터 추출
1~4번까지의 정제를 거친 Data를 바탕으로 5개 구의 년도별 평균 실거래가 Data를 생성한다.
averageData=pd.DataFrame(refinedData.groupby(['자치구명','접수연도'])['평당가격(만원)'].mean()).sort_values(by='접수연도',ascending=True)
averageData.rename(columns={'평당가격(만원)':'평균평당가격(만원)'},inplace=True)groupby 함수를 이용하여 '자치구명', '접수연도'로 Data를 묶고 '평당가격(만원)'의 평균을 계산한다. 이를 접수연도에 따라 내림차순으로 Data를 구성한다.
7. 6번의 결과 Data 내보내기
5번과 마찬가지로 to_csv 함수를 이용하여 내보내기를 수행하였다.
🚨 여기서 주의점은, groupby로 묶었기 때문에 index=True의 조건이 있어야 한다. 그렇지 않으면 평균평당가격에 해당하는 column 값만 내보내게 된다.
위와 같은 과정을 거쳐
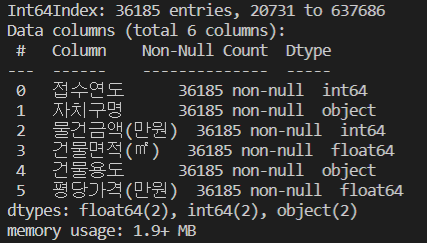
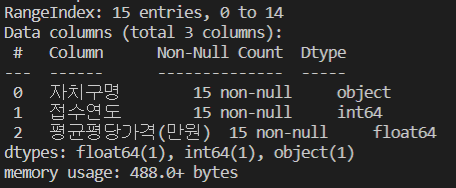
데이터 정제의 수행 결과이다.
pandas library가 워낙 잘 되어있어 특별히 사용한 함수가 없어도 간단하게 데이터를 정제할 수 있었다.
87,034KB의 원본 데이터를 1,794KB로 정제하였다.
😺 데이터 갯수가 100만개가 넘지 않아 raw하게 코드를 작성하여 수행하였는데 100만개가 넘는 대용량 데이터의 경우 멀티코어를 사용하여 수행하면 효과적으로 수행할 수 있을 것이다.
