✍️ 26번 : 배치(Batch) 프로그램
배치(Batch) 프로그램에 대한 설명으로 가장 부적절한 것
- DW/OLAP 시스템에서 데이터를 집계하는 프로그램을 말한다. 👉 ❌
- 주로 대량 데이터를 처리한다. 👉 ⭕️
- 일련의 작업을 하나의 작업 단위로 묶어서 일괄 처리한다. 👉 ⭕️
- 정기적으로 반복 실행되거나 사전에 정의해 둔 조건을 충족할 때 자동 실행된다. 👉 ⭕️
🍋 기출 포인트
- ⭐️배치 프로그램은 DW/OLAP 시스템뿐만 아니라 OLTP(온라인 트랜잭션 처리) 시스템에서도 많이 활용한다.⭐️
- 실시간에 가까운(Near Real Time) 정보 서비스 요구가 늘면서 On-Demand 배치가 늘고, 트랜잭션을 일정량 모았다가 지연(deferred) 처리하는 배치 프로그램의 활용도 느는 추세다.
🍒 문제 해설
✅ 배치 프로그램
- 일련의 작업들을 하나의 작업 단위로 묶어 연속적으로 일괄 처리하는 것
- 온라인 프로그램에서도 여러 작업을 묶어 처리하는 경우가 있으므로 이와 구분하려면 '사용자와의 상호작용(Interaction) 여부' 특징을 더 추가해야한다.
- 사용자와의 상호작용 없이 대량의 데이터를 처리하는 일련의 작업들을 묶어 정기적으로 반복 수행하거나
- 사용자와의 상호작용 없이 대량의 데이터를 처리하는 일련의 작업들을 묶어 정해진 규칙에 따라 자동으로 수행한다.
- 기업마다 업무 요건이 워낙 복잡 다양하므로 이 외에도 여러 가지 형태가 존재할 수 있다.
- 정기 배치 형태가 가장 일반적이다.
- 배치 프로그램의 종류는 다음과 같다.
- On-Demand 배치 :: 배치 프로그램이 자동으로 수행되는 주기는 월단위, 주단위, 일단위가 보통이지만, 요즘은 주기가 점점 짧아져 종종 실시간이 요구되기도 한다. 사용자가 요청한 시점에 바로 작업을 시작한다
- 정기 배치 : 정해진 시점(주로 야간)에 실행된다.
- 이벤트성 배치 : 사전에 정의해 둔 조건이 충족되면 자동으로 실행
- 배치 프로그램은 DW/OLAP 시스템뿐만 아니라 OLTP(온라인 트랜잭션 처리) 시스템에서도 많이 활용한다.
- 실시간에 가까운(Near Real Time) 정보 서비스 요구가 늘면서 On-Demand 배치가 늘고, 트랜잭션을 일정량 모았다가 지연(deferred) 처리하는 배치 프로그램의 활용도 느는 추세다.
✍️ 27번 : 배치(Batch) 프로그램 튜닝
배치(Batch) 프로그램 튜닝에 대한 설명으로 가장 부적절한 것
- 최초 응답속도 최적화에 목표를 두고 튜닝할지, 전체 처리속도 최적화를 목표를 두고
튜닝할지를 개별 배치 프로그램 단위로 잘 결정해야 한다. 👉 ❌ - 병렬 프로세싱을 활용할 때 필요 이상의 병렬도(DOP)를 지정하지 않아야 한다. 👉 ⭕️
- 배치 윈도우(Batch Window)를 조절해서 프로그램 수행 시간대를 적절히 분산한다면, 개별 프로그램을 튜닝할 때보다 더 큰 효과를 얻을 수도 있다. 👉 ⭕️
- 야간 배치 프로그램을 튜닝할 때는 개별 프로그램 수행시간을 단축하기보다 전체 프로그램 수행시간을 단축하는 데 더 큰 목표를 두어야 한다. 👉 ⭕️
🍋 기출 포인트
- ⭐️야간 배치 프로그램을 튜닝할 때는 개별 프로그램 수행시간을 단축하기보다 전체 프로그램 수행시간을 단축하는 데 더 큰 목표를 두어야 한다⭐️
- ⭐️배치 프로그램은 항상 전체 처리속도 최적화에 목표를 두고 튜닝해야 한다.⭐️
- 개별 서비스 또는 프로그램을 가장 빠른 속도로 최적화하더라도 전체 배치 프로그램 수
행시간을 단축하지 못하면 무의미하다. 튜닝 대상을 선정할 때도 이런 기준을 갖고 선별해야 한다.
✍️ 28번 : 배치(Batch) 프로그램 튜닝
배치(Batch) 프로그램 튜닝에 대한 설명으로 가장 부적절한 것
- 총 소요시간을 단축할 수 있다면 병렬처리를 적절히 활용한다. 👉 ⭕️
- 임시 테이블을 잘 활용하는 것도 중요하다. 👉 ⭕️
- 할 수 있다면, Array Processing을 적극 활용한다. 👉 ⭕️
- 배치 프로그램을 튜닝할 때 인덱스는 중요하지 않다. 👉 ❌
🍒 문제 해설
✅ 배치 프로그램의 두 가지 스타일
- 절차형으로 작성된 프로그램
- SQL 결과집합을 루프 내에서 한건씩 Fetch한다.
- SQL을 반복해서 수행하는 형태
- 인덱스 구성이 중요하다.
- One SQL 위주로 작성된 프로그램
✍️ 29번 : 병렬 처리에서 QC
병렬 처리에서 QC의 역할과 거리가 먼 것
- 병렬 서버 집합(Server Set)을 할당한다. 👉 ⭕️
- 각 병렬 프로세스에 작업을 할당한다. 👉 ⭕️
- 병렬도(DOP)를 지정하지 않은 테이블을 직접 읽는다. 👉 ⭕️
- 다른 병렬 서버들이 작업 완료하기를 기다리면서 대기 중인 병렬 프로세스를 찾아 자원을 OS에 반환한다. 👉 ❌
🍋 기출 포인트
- ⭐️병렬 처리에 사용한 병렬 프로세스는 모든 처리를 종료(SELECT 문장은 커서를 닫거나 결과 집합을 모두 Fetch)한 후에 일괄 해제하고 자원을 OS(또는 서버 풀)에 반환한다.⭐️
✍️ 30번 : Intra Operation Parallelism
🍒 문제 해설
✅ Intra Operation Parallelism
- 병렬 처리에서 서로 배타적인 범위를 독립적으로 동시에 처리하는 것
- 한 병렬 서버 집합(Server Set)에 속한 여러 프로세스가 처리 범위를 달리하면서 병렬로 작업을 진행하는 것이므로 집합 내에서는 절대 프로세스 간 통신이 발생하지 않는다.
- 예시 : 첫 번째 서버 집합(P000~P003)에 속한 4개의 프로세스가 범위를 나눠 고객 데이터를 읽는 작업
✅ Inter-Operation Parallelism
- 한편의 서버집합에 속한 프로세스들이 읽은 데이터를 반대편 서버집합(또는 QC)에 전송하는
작업을 병렬로 동시에 진행하는 것- 서로 배타적인 범위를 독립적으로 동시에 처리하는 것
- 항상 프로세스 간 통신이 발생한다.(메시지 또는 데이터를 전송하기 위한 통신 채널이 필요)
✍️ 31번 : P->P(PARALIEL_TO_PARALIEL) 오퍼레이션
P->P(PARALIEL_TO_PARALIEL) 오퍼레이션에 대한 설명과 가장 거리가 먼 것
- 프로세스 간 통신이 발생한다. 👉 ⭕️
- 서버 프로세스가 병렬도(DOP)의 2배수로 생성된다. 👉 ⭕️
- 테이블 큐(Queue)가 필요하다. 👉 ⭕️
- Intra-Operation Parallelism에 해당한다. 👉 ❌
🍋 기출 포인트
- P - P(PARALLELTO_PARALLEL) 오퍼레이션은 데이터를 재분배(redistribution)하는 오퍼레이션이다.
- 실행계획에 P → P 오퍼레이션이 나타나는 구간은 두 개의 서버 집합(Server Set)이 처리한다.따라서 사용자가 지정한 병렬도의 2배수만큼 병렬 프로세스가 필요하다.
- 데이터 재분배 과정에 테이블 큐(Queue)를 사용한다.
- ⭐️병렬 프로세스 간 통신이 발생하므로 Inter-Operation Parallelism에 속
한다.⭐️
🍒 문제 해설
✅ 병렬 프로세스간 통신이 발생하는 경우( P - P(PARALLELTO_PARALLEL) )
- 데이터를 정렬(order by) 또는 그룹핑(group by)하거나 조인을 위해 동적으로 파티셔닝할때
- 첫 번째 병렬 서버 집합이 읽거나 가공한 데이터를 두 번째 병렬 서버 집합에 전송하는 과정
✍️ 32번 : 프로세스 간 통신이 발생하지 않는 오퍼레이션
- PARALLEL_COMBINED_WITH_PARENT 👉 ⭕️
- PARALLEL FROM SERIAL 👉 ❌
- PARALLEL TO SERIAL 👉 ❌
- PARALLEL_TO_PARALLEL 👉 ❌
🍋 기출 포인트
- PARALLEL_COMBINED_WITH_PARENT과 PARALLEL_COMBINED_WITH_CHILD 오퍼레이션에서는 프로세스 간 통신이 발생하지 않는다.
✅ 병렬 처리에서의 IN-OUT 오퍼레이션
- PARALLEL_FROM_SERIAL(S → P) : QC가 읽은 데이터를 테이블 큐를 통해 병렬 서버 프로세스에게 전송
- PARALLEL_TO_SERIAL(P → S) : 각 병렬 서버 프로세스가 처리한 데이터를 QC에게 전송
- PARALLEL_TO_PARALLEL(P → P) : 한 서버 집합(Server Set)이 반대편 서버 집합에 데이터를 전송
- PARALLEL_COMBINED_WITH_PARENT(PCMP) : 한 병렬 프로세스가 현재 스텝과 부모 스텝을 모두 처리
- PARALLEL_COMBINED_WITH_CHILD(PCWC) : 한 병렬 프로세스가 현재 스텝과 자식 스텝을 모두 처리
✍️ 33번 : 데이터 재분배(Redistribution)
병렬 처리에서 사용하는 데이터 재분배(Redistribution)에 대한 설명으로 가장 부적절한것
✅ 데이터 재분배 방식의 종류
- 데이터 재분배는 병렬 서버 프로세스 간에 데이터를 재분배하는 방식이다.
- RANGE 방식
- order by 또는 sort group by를 병렬로 처리할 때 사용된다.
- 첫 번째 서버 집합은 데이터를 읽어 각 프로세스마다 처리 범위(예를 들어, A~G, H~M, N~S, T~Z)를 지정하여 그 두 번째 서버 집합의 정해진 프로세스에게 “정렬 키 값에 따라 분배한다.
- 두 번째 서버 집합은 정렬 작업을 맡는다.
- QC는 각 서버 프로세스에게 작업 범위를 할당하고 정렬 작업에는 직접 참여하지 않는다.
정렬이 완료되고 나면 순서대로 결과를 받아서 사용자에게 전송한다.- BROADCAST 방식
- QC 또는 첫 번째 서버 집합에 속한 프로세스들이 각각 읽은 데이터를 두 번째 서버 집합에 속한 “모든” 병렬 프로세스에게 전송하는 방식이다.
- 병렬 조인에서 크기가 매우 작은 테이블이 있을 때 사용한다.
- KEY 방식
- 특정 칼럼(들)을 기준으로 테이블 또는 인덱스를 파티셔닝할 때 사용하는 분배 방식이다.
- ROUND-ROBIN 방식
- 파티션 키, 정렬 키, 해시 함수 등에 의존하지 않고 반대편 병렬 서버에 무작위로 데이터를 분배할 때 사용한다.
- HASH 방식
- 조인이나 hash group by를 병렬로 처리할 때 사용된다.
- 조인 키나 group by 키 값을 해시 함수에 적용하고 리턴된 값에 따라 데이터를 분배하는 방식이다.
- RANGE : ORDER BY 또는 SORT GROUP BY를 병렬로 처리할 때 👉 ⭕️
- HASH : 조인이나 HASH GROUP BY를 병렬로 처리할 때 👉 ⭕️
- ROUND-ROBIN : 데이터를 고르게 분배하고자 할 때 👉 ⭕️
- BROADCAST : 대량 데이터를 분배할 때 👉 ❌
✍️ 34번 : DOP 개수
데이터가 1,000만 건인 주문 테이블을 16개 파티션으로 분할했고 파티션간 데이터 편차가 없는 상황에서 아래 병렬 쿼리를 서버 리소스의 불필요한 없이 가장 빠르게 처리할 수 있는 DOP 개수
[ 테이블 파티션 ]
주문일시 기준 Range 파티션 (16개 파티션)
[인덱스 구성 ]
주문 PK : 계좌번호 + 주문일시 (-> Local 파티션)
SELECT /*+ INDEX(O , 주문PK) PARALLEL_INDEX(O, 주문 PK, ? ) */
COUNT(*)
FROM 주문 O
WHERE 계좌번호 = 'ABC123';[내 풀이]
- 조건절에 파티셔닝에 관련한 게 없다.(주문일시)
- 해당 계좌번호를 검색하려면 16개의 파티션을 모두 탐색해야한다.
- 따라서 병렬도는 16이 적합하다.
답 : 16
🍋 기출 포인트
- ⭐️Index Range Scan을 병렬로 처리할 때는 파티션 Granule이다.⭐️
- 파티션 개수보다 많은 병렬도를 지정하면 서버 리소스를 낭비하게 된다.
🍒 문제 해설
✅ 병렬처리에서의 Granule
- 데이터를 병렬로 처리할 때 일의 최소 단위를 'Granule'이라고 한다.
- 병렬 서버는 한 번에 하나의 Granule씩만 처리한다.
- 블록 기반 Granule(=블록 범위 Granule)
- QC가 테이블로부터 읽어야 할 일정 범위(Range)의 블록을 각 병렬 프로세스에게 할당한다.
- 병렬 프로세스가 한 Granule에 대한 일을 끝마치면 이어서 다른 Granule을 할당한다.
- 따라서 프로세스 간 처리량에 편차가 거의 발생하지 않는다.
- ⭐️파티션 여부, 파티션 개수와 무관하게 병렬도를 지정할 수 있다.⭐️
- ⭐️병렬 Full Table Scan은 블록 기반 Granule이므로 파티션 개수보다 큰 병렬도를 지정해도 상관없다.⭐️
- 파티션 기반 Granule(파티션 Granule)
- 한 파티션에 대한 작업을 한 프로세스가 모두 처리한다.
- Partition-Wise 조인 시
- 파티션 인덱스를 병렬로 스캔할 때(Index Range Scan, Index Full Scan)
- 파티션 인덱스를 병렬로 갱신할 때
- 파티션 테이블 또는 파티션 인덱스를 병렬로 생성할 때
- 한 파티션을 두 개 프로세스가 함께 처리할 수 없다.
- 병렬도를 파티션 개수보다 크게 지정하면 서버 리소스를 낭비하게 된다.
- 병렬도를 파티션 개수 이하로 지정할 때는 블록 기반 Granule과 마찬가지로 먼저 일을 마친 프로세스에게 다음 파티션을 할당한다.
- 처리할 파티션이 없을 때 먼저 일을 끝마친 프로세스는 다른 프로세스가 일을 마칠 때까
지 기다리게 되므로 파티션간 데이터양에 편차가 심할 때 리소스를 낭비하게 된다.
✍️ 35번 : DOP 개수
데이터가 1,000만 건인 주문 테이블을 8개 파티션으로 분할한 상황에서 아래 병렬 쿼리를 서버 리소스의 불필요한 낭비없이 가장 빠르게 처리할 수 있는 DOP 개수
[테이블 파티션 ]
주문일시 기준 Range 파티션 (8개 파티션)
[인덱스 구성 ]
주문_PK : 계좌번호 + 주문일시 (→ Local 파티션)
SELECT /*+ INDEX_FFS(O 주문_PK) PARALLEL_INDEX(O, 주문_PK, ?) */
TO_CHAR(주문일시, 'YYYYW') 주문월, COUNT(*) 주문건수
FROM 주문 O
GROUP BY TO_CHAR(주문일시, 'YYYYMM');🍒 문제 해설
- 조건절에 파티셔닝에 관련한 게 없다.(주문일시)
- 주문일시별로 그룹핑 하려면 8개의 파티션을 모두 탐색해야한다.
- index fast full scan은 블록 단위로 병렬처리하므로 병렬도가 높을 수록 좋다.
- 따라서 병렬도는 16이 적합하다.
답 : 16
✍️ 36번 : 병렬 SQL 튜닝의 핵심 원리
병렬 SQL 튜닝의 핵심 원리와 가장 거리가 먼 것
- 데이터를 병렬로 처리하는 중에 생기는 병목 구간을 해소한다. 👉 ⭕️
- 병렬 프로세스 간 통신량을 최소화한다. 👉 ⭕️
- 성능 향상 효과를 체감할 수 있는 최소한의 병렬 프로세스를 할당한다. 👉 ⭕️
- 인덱스를 활용해 소트 연산을 생략하게 한다. 👉 ❌
🍋 기출 포인트
- 인덱스를 활용해 소트 연산을 생략하게 하는 튜닝 기법의 주목적은 부분범위 처리를 활용하는 데 있다.
🍒 문제 해설
- 병렬 SQL은 대용량 배치 프로그램 튜닝에 주로 사용하므로 부분범위 처리를 출
용할 이유가 없다.
1.소트 연산을 인덱스로 대체하려면 Index Range Scan 또는 Index Full Scan을 사용해야 하는데, 일반적으로 이는 병렬 처리에 효과적이지 못한 스캔 방식이다.. - 병렬 처리에는 Table Full Scan 또는 Index Fast Full Scan이 효과적이다.
✍️ 37번 : 병렬 쿼리 튜닝
병렬 쿼리를 튜닝할 때 체크해야 할 항목과 가장 거리가 먼 것
- 대형 테이블을 Broadcast 방식으로 분배하는지 확인한다. 👉 ⭕️
- 병렬로 처리하는 중간 단계에 PARALLEL_TO_SERIAL 오퍼레이션이 나타나는지 확인한다. 👉 ⭕️
- 큰 테이블을 PARALLEL_FROM_SERIAL 방식으로 읽는지 확인한다. 👉 ⭕️
- 병렬로 Full Table Scan 할 때 파티션 개수보다 큰 병렬도를 지정했는지 확인한다. 👉 ❌
🍋 기출 포인트
- ⭐️병렬 Full Table Scan은 블록 기반 Granule이므로 파티션 개수보다 큰 병렬도를 지정해도 상관없다.⭐️
- 병렬로 처리하는 중간 단계에 PARALLEL_TO_SERIAL 오퍼레이션이 나타나면 병목 구간으로 작용한다.
- 병렬로 처리하는 과정에 큰 테이블을 단일 프로세스로 읽으면 병목 구간이 될 수 있다.
작은 테이블은 단일 프로세스로 읽어도 성능에 큰 영향을 주지 않는다. - 대형 테이블을 Broadcast 방식으로 분배하면 프로세스 간 통신에 따른 부담이 줄 뿐만
아니라 읽은 데이터를 프로세스 개수만큼 복제하는 결과를 초래하므로 메모리와 디스크
자원을 많이 사용한다.
✍️ 38번 : Inter-Operation Parallelism
지정한 병렬도의 2배수로 병렬 프로세스를 할당하는 경우가 아닌 것
- 병렬 Order By 및 병렬 Group By 👉 ⭕️
- Broadcast 방식의 데이터 분배 👉 ⭕️
- Partial Partition Wise 조인 👉 ⭕️
- Full Partition Wise 조인 👉 ❌
🍒 문제 해설
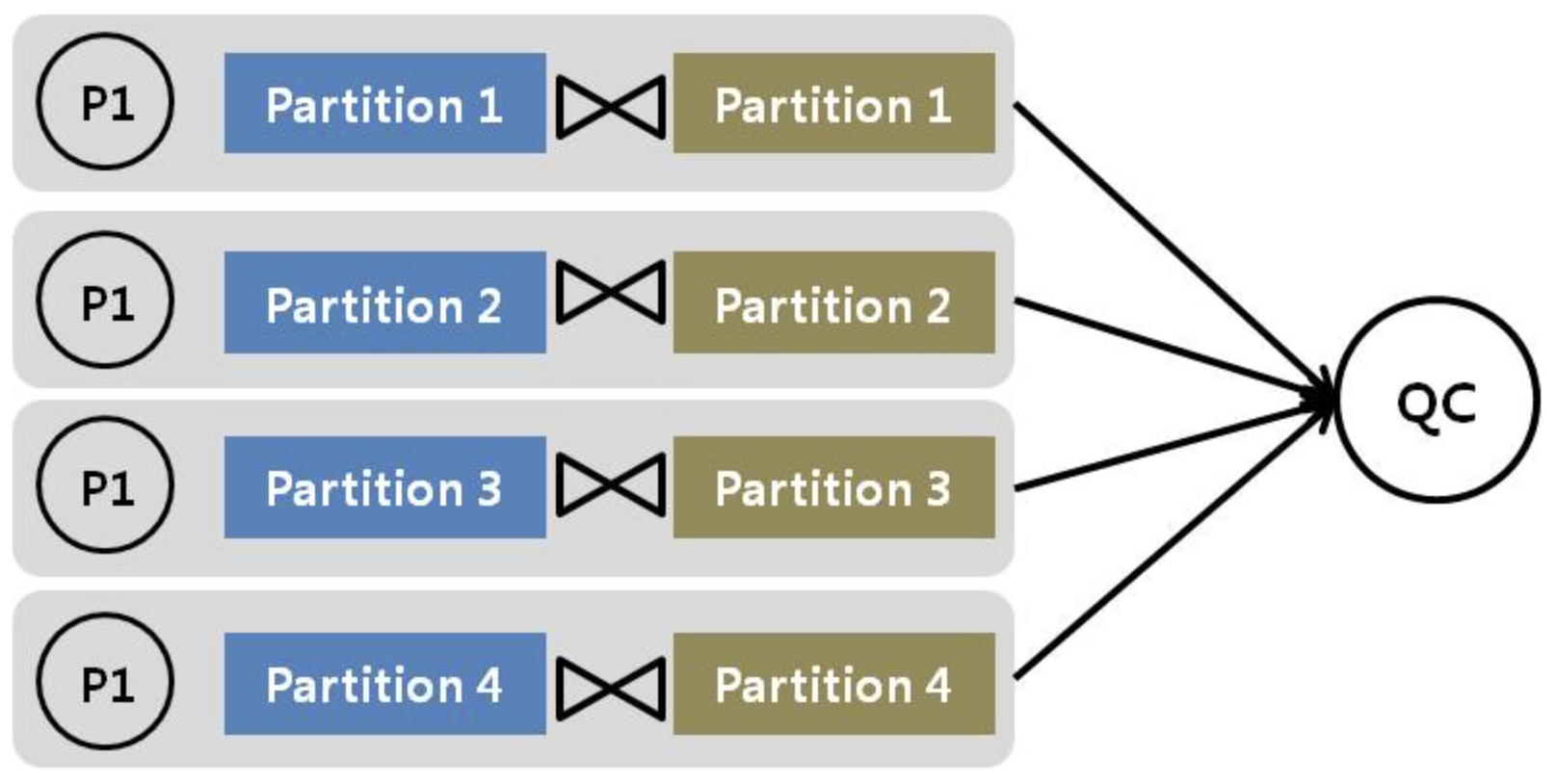
✅ Full Partition Wise 조인
- 같은 기준으로 파티션된 두 테이블을 조인할 때 사용하는 병렬 조인 방식
- 양쪽 테이블을 같은 기준으로 파티션하기 위해 데이터를 재분배할 필요가 없다.
- 병렬 프로세스를 2배수로 할당하지 않는다. 즉 , 하나의 서버집합만 필요하다.
- 파티션 기반 병렬처리이므로 파티션 갯수 이하로 병렬도를 제한한다.
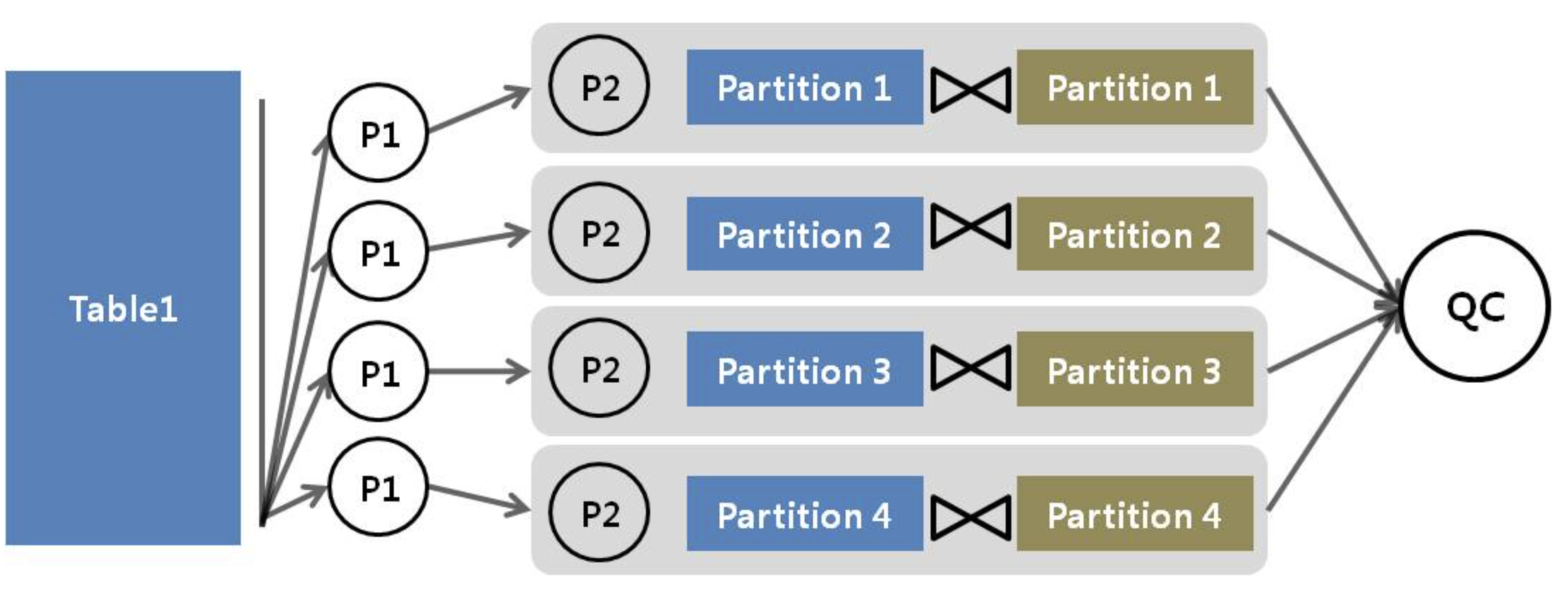
✅ Partial Partition Wise 조인
- 첫 서버 집합이 비 파티션 테이블을 파티션 테이블 기준으로 동적 파티셔닝한다.
- 두 개의 서버집합이 필요하다.(Partition degree * 2 개 Process)
- 각 서버집합 간 데이터 통신이 발생한다.
✍️ 39번 : Broadcast 방식의 데이터 재분배
아래 5개 테이블을 병렬로 조인할 때 Broadcast 방식의 데이터 재분배가 가장 효과적인 경우
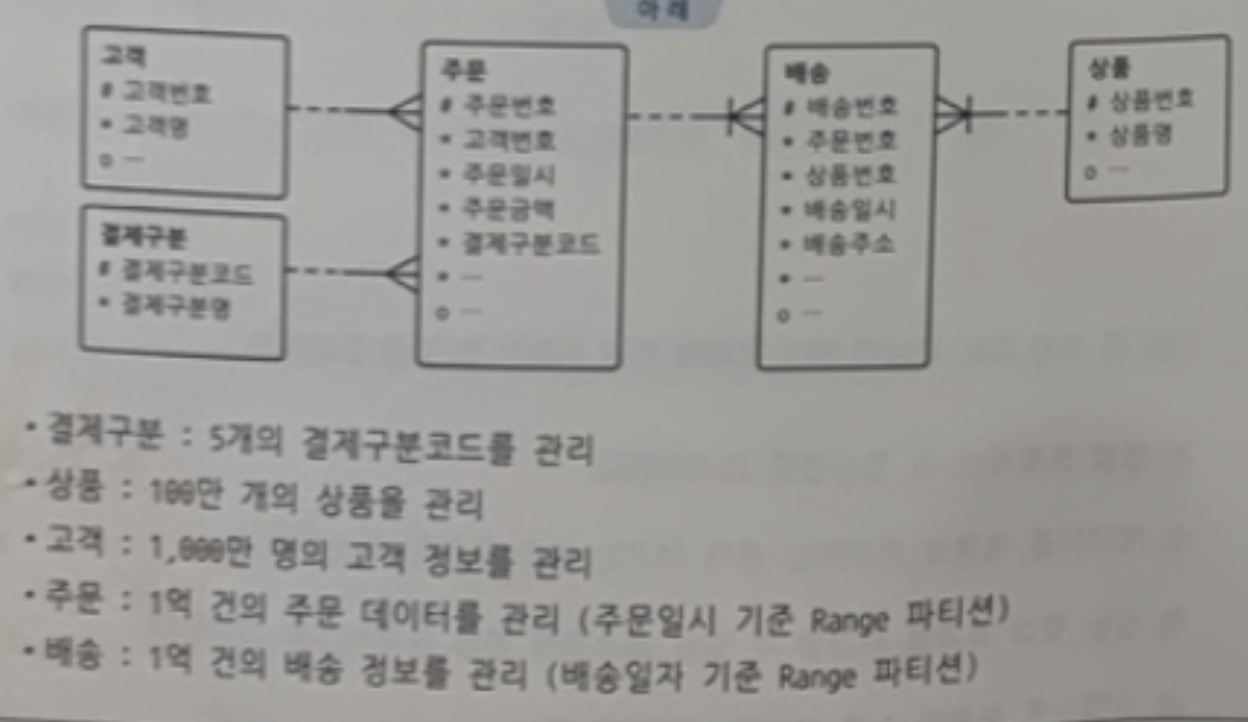
1. 결제구분과 주문을 조인 👉 ⭕️
1. 상품과 배송을 조인 👉 🔺
1. 고객과 주문을 조인 👉 🔺
1. 주문과 배송을 조인 👉 ❌
🍋 기출 포인트
- ⭐️Broadcast는 QC 또는 첫 번째 서버 집합에 속한 프로세스들이 각각 읽은 데이터를 두 번째 서버 집합에 속한 "모든" 병렬 프로세스에게 전송하는 방식이므로 데이터 크기가 작을수록 효과적이다.⭐️
✍️ 40번 : Hash 방식의 데이터 재분배
아래 5개 테이블을 병렬로 조인할 때 Hash 방식의 데이터 재분배가 가장 효과적인 경우를 고르시오
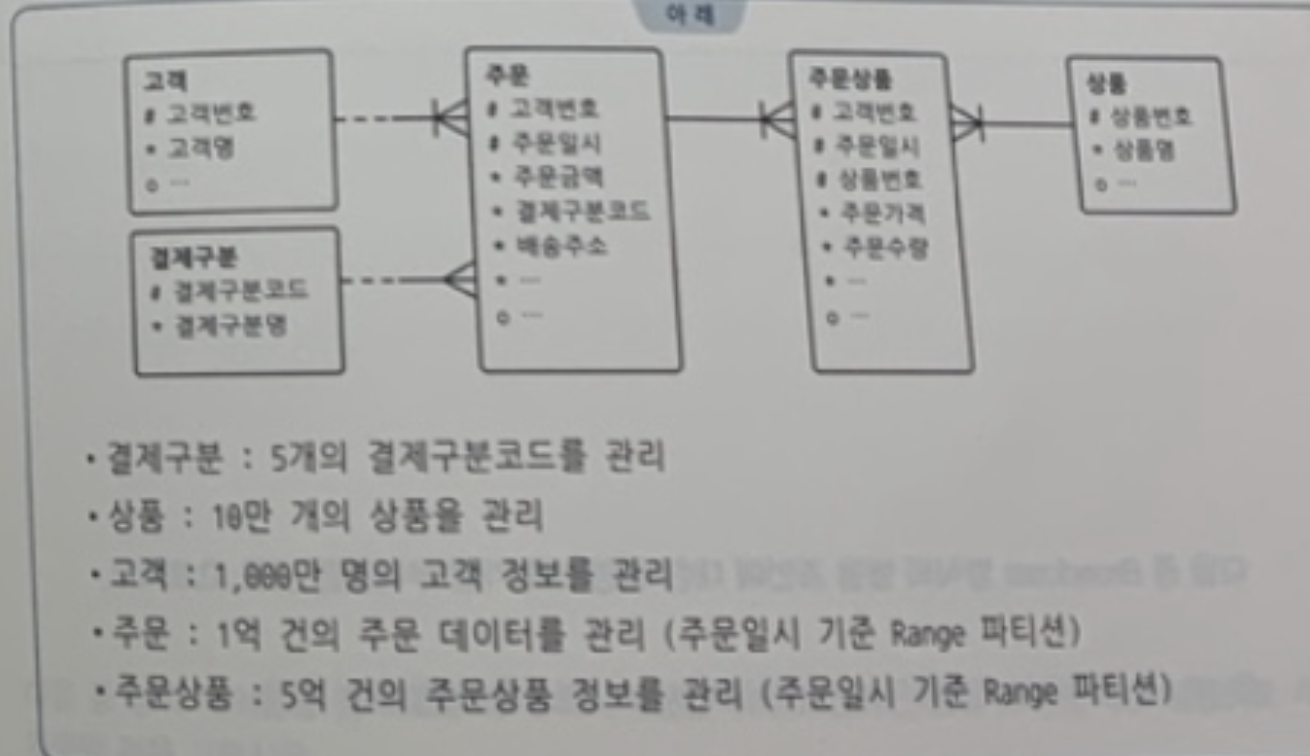
[내풀이]
- HASH 조인이 필요한 곳 : 과도한 NL조인이 일어나는 곳
- 고객과 주문 조인 : 주문 1억건 -> 고객 1000만 건 : NL조인 1억건 시도
- 주문 테이블은 주문일시 기준으로 파티션되어있다.
- 상품과 주문상품을 조인 : 주문상품 5억건 -> 상품 10만 개 : NL조인 5억건 시도
- 주문 상품이 파티션되어있다.
- Hash 방식으로 데이터 재분배를 할 수도 있지만..
- ⭐️10만 건과 5억 건을 조인하는 경우라면 상품을 Broadcast 방식으로 재분배하는 것이 훨씬효과적이다.⭐️
- 주문과 주문상품 조인 : 주문상품 5억건 -> 주문 1억건
- Full Partition Wise 조인이 효과적이다.
- 상품과 주문상품을 조인 👉 ⭕️
- 주문과 주문상품 조인 👉 ❌
- 고객과 주문 조인 👉 ❌
- 결제구분과 주문을 조인 👉 ❌
🍋 기출 포인트
- 1,000만 명 고객과 1억 건의 주문 데이터를 조인할 때는 Hash 방식의 데이터 재분배가 효과적이다.
- ⭐️Hash 방식의 데이터 재분배와 HASH 조인이랑은 엄연히 다르다 ! 헷갈리지 말것⭐️
✍️ 41번 : 병렬처리 힌트
아래 실행계획으로 정확히 유도하기 위해 필요한 힌트를 모두 기술
SELECT *
FROM 상품 A, 주문상품 B
WHERE A. 상품번호 = B. 상품번호
AND (이하 생략) 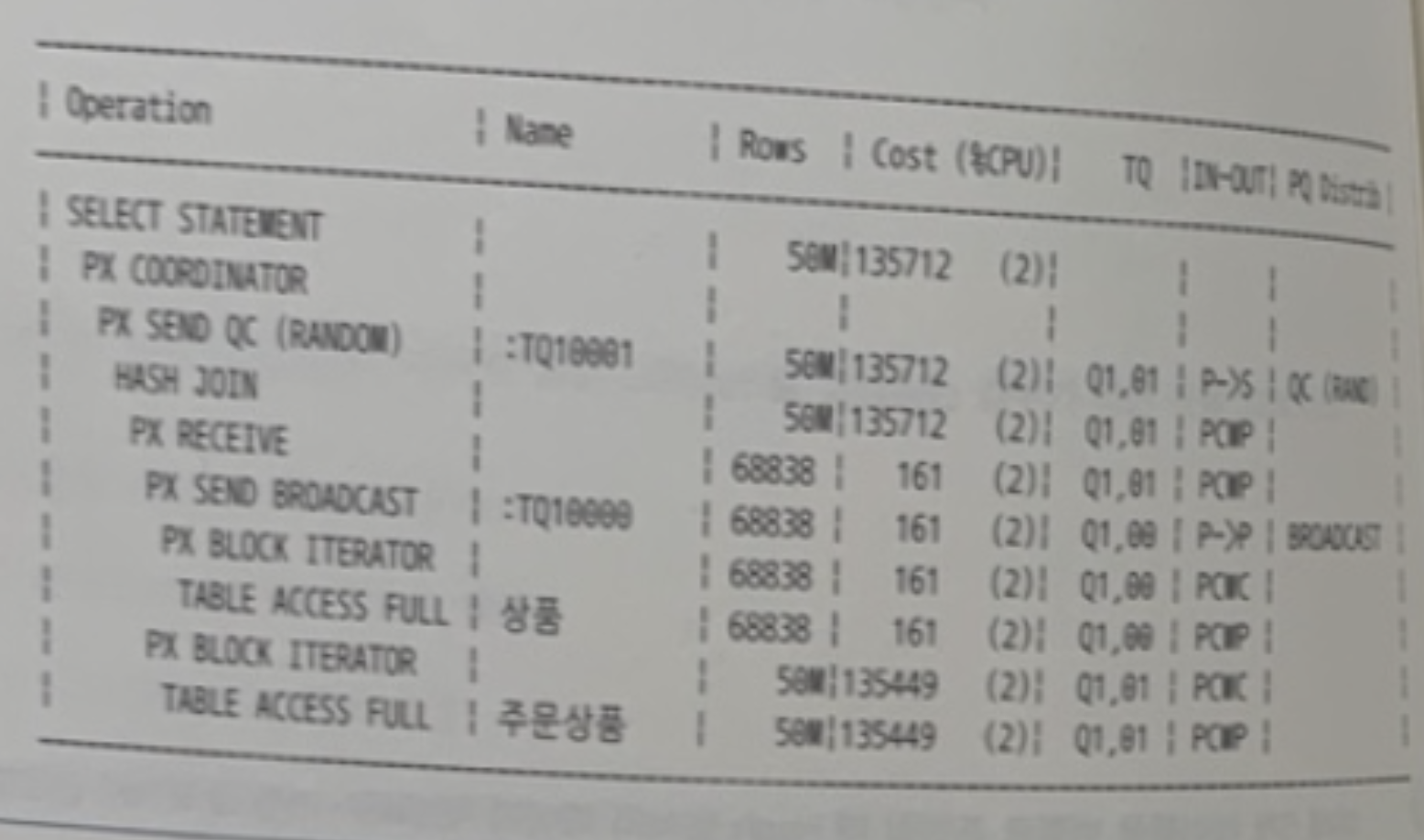
내 풀이
- 쿼리 작동 순서
- 상품 테이블 Full Scan
- 블록 단위 Granule 2개
- 브로드캐스트 방식으로 데이터 재분배
- LEADING(A) FULL(A) PARALLEL(A 2)
- 상품 테이블의 데이터를 브로드 캐스트 방식으로 두번째 서버 집합이 받음
- PQ_DISTRIBUTE(B,BROADCAST,NONE)
- 주문상품 테이블 Full Scan
- 블록 단위 Granule 2개
- FULL(B) PARALLEL(B 2)
- 각 서버집합에서 상품과 주문 테이블 해시 조인
- USE_HASH(B)
- 조인된 결과를 QC로 보냄
- 상품 테이블 Full Scan
답
/*+ LEADING(A) USE HASH(B)
FULL(A) FULL(B) PARALLEL(A 2) PARALLEL(B 2)
PO_DISTRIBUTE(B, BROADCAST, NONE) */🍒 문제 해설
✅ pq_distribute 사용법
- pq_distribute(inner, none, none)
- Full-Partition Wise Join으로 유도할 때 사용
- 당연히, 양쪽 테이블 모두 조인 칼럼에 대해 같은 기준으로 파티셔닝(equi-partitioning) 돼 있을 때만 작동한다.
- pq_distribute(inner, partition, none)
- Partial-Partition Wise Join으로 유도할 때 사용
- outer 테이블을 inner 테이블 파티션 기준에 따라 파티셔닝하라는 뜻이다.
- 당연히, inner 테이블이 조인 키 칼럼에 대해 파티셔닝 돼 있을 때만 작동한다.
- pq_distribute(inner, none, partition)
- Partial-Partition Wise Join으로 유도할 때 사용
- inner 테이블을 outer 테이블 파티션 기준에 따라 파티셔닝하라는 뜻이다.
- 당연히, outer 테이블이 조인 키 칼럼에 대해 파티셔닝 돼 있을 때만 작동한다.
- pq_distribute(inner, hash, hash)
- 조인 키 칼럼을 해시 함수에 적용하고 거기서 반환된 값을 기준으로 양쪽 테이블을 동적으로 파티셔닝하라는 뜻이다.
- 조인되는 테이블을 둘 다 파티셔닝해서 파티션 짝(Partition Pair)을 구성하고서 Partition Wise Join을 수행한다.
- pq_distribute(inner, broadcast, none)
- outer 테이블을 Broadcast 하라는 뜻이다.
- pq_distribute(inner, none, broadcast)
- inner 테이블을 Broadcast 하라는 뜻이다.
✍️ 42번 : Broadcast 방식의 병렬 조인
Broadcast 방식의 병렬 조인에 대한 설명으로 가장 부적절한 것
- Broadcast 되는 테이블에는 반드시 PARALLEL 힌트를 지정해야 한다. 👉 ❌
- 매우 큰 데이터 집합을 Broadcast하면 Temp 테이블스페이스 공간을 많이 사용하게 되므로 성능이 느려질 수 있다. 👉 ⭕️
- Broadcast를 완료하고 난 후의 조인 방식은 NL조인, 소트머지 조인, 해시 조인 중 어떤 것이든 사용할 수 있다. 👉 ⭕️
- Broadcast되는 데이터 집합은 전체범위처리가 불가피하지만, 반대쪽 테이블은 부분범위 처리가 가능하다. 👉 ⭕️
🍋 기출 포인트
- Broadcast 되는 데이터 집합이 작을수록 유용한 병렬 조인 방식이다. 따라서 작은 데이터를 Broadcast 할 때는 굳이 Parallel 힌트를 쓰지 않아도 상관 없다.
✍️ 43번 : 병렬처리 힌트
아래 실행계획으로 정확히 유도하기 위해 필요한 힌트를 모두 기술
SELECT *
FROM 고객 A, 주문 B
WHERE A. 고객번호 = B. 고객번호
AND (이하 생략)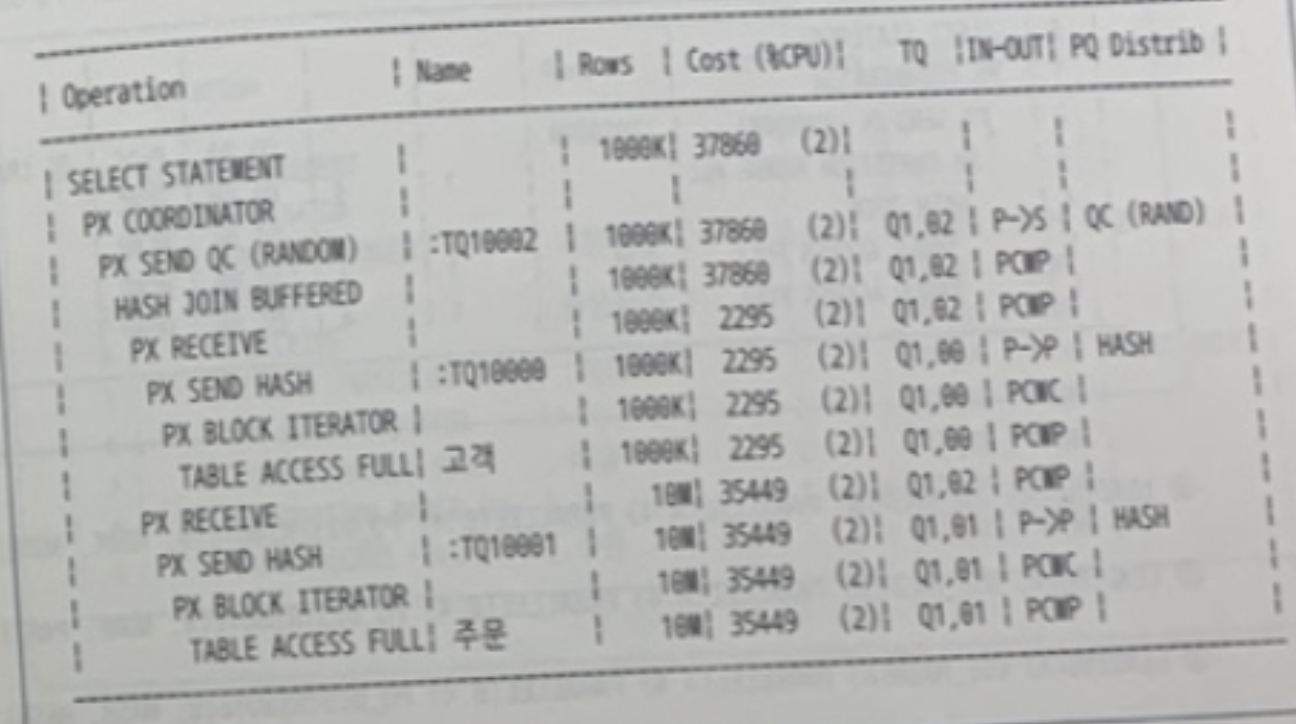
내 풀이
- 쿼리 작동 순서
- 고객 테이블 Full Scan
- 블록 단위 Granule 2개
- 해시 데이터 재분배
- FULL(A) PARALLEL(A 2) LEADING(A)
- 주문 테이블 Full Scan
- 블록 단위 Granule 2개
- 해시 데이터 재분배
- FULL(B) PARALLEL(B 2) USE_HASH(B)
- 고객,주문 테이블의 데이터를 해시 데이터 재분배 방식으로 두번째 서버 집합이 받음
- PQ_DISTRIBUTE(B,HASH,HASH)
- 고객 테이블 Full Scan
답
FULL(A) PARALLEL(A 2) LEADING(A) FULL(B) PARALLEL(B 2) USE_HASH(B)
PQ_DISTRIBUTE(B,HASH,HASH)✍️ 44번 : 병렬 조인
양쪽 테이블을 동적으로 해시 파티셔닝한 후에 조인하는 병렬 조인에 대한 설명으로 가장 부적절한 것
- 두 개의 서버집합이 필요하다. 👉 ⭕️
- 조인 컬럼의 데이터 분포가 균일하지 않을 때 병렬 처리 효과가 크게 반감된다. 👉 ⭕️
- 두 테이블을 파티셔닝하는 과정에 Temp 테이블스페이스 공간을 많이 사용한다. 👉 ⭕️
- 파티셔닝할 때는 해시 방식을 사용하므로 조인 방식도 해시 조인만 사용할 수 있다. 👉 ❌
🍋 기출 포인트
- 양쪽 테이블을 동적으로 해시 파티셔닝한 후에 조인하는 병렬 조인은 큰 두 개의 테이블을 조인하는데, 두 테이블 모두 파티션되지 않았거나 서로 다른 기준으로 파티션됐을 때 주로 사용한다.
- 양쪽 모두 큰 테이블일 때 사용하므로 두 테이블을 파티션하는 과정에 많은 Temp 테이블스페이스 공간을 사용한다.
- 파티셔닝할 때는 해시 방식을 사용하지만, 조인 방식은 NL 조민, 소트머지 조인, 해시 조인 중 어떤 것이든 사용할 수 있다.
✍️ 45번 : FULL PARTITION WISE JOIN 실행계획
병렬 조인 실행계획으로 유도하는 힌트를 고르시오.
SELECT *
FROM 주문 A, 주문상품 B
WHERE ( 이하 생략 ) 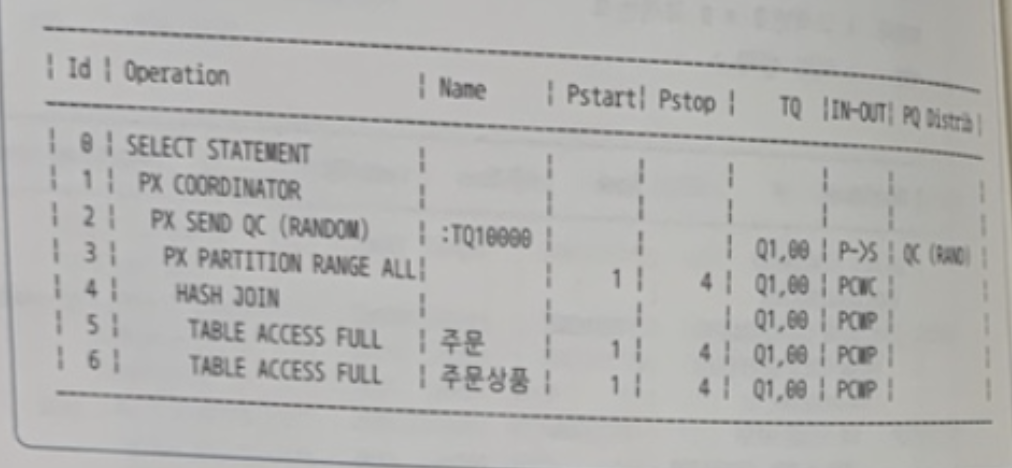
내 풀이
- 쿼리 작동 순서
- 주문 테이블 Full Scan
- 블록 단위 Granule 4개
- FULL(A) PARALLEL(A 4) LEADING(A)
- 주문상품 테이블 Full Scan
- 블록 단위 Granule 4개
- FULL(B) PARALLEL(B 4) USE_HASH(B)
- 고객,주문 테이블의 데이터를 같은 기준으로 각각 파티셔닝하여 각 범위에 맞게 해시조인 수행
- PQ_DISTRIBUTE(B,NONE,NONE)
- 주문 테이블 Full Scan
답
FULL(A) PARALLEL(A 4) LEADING(A) FULL(B) PARALLEL(B 4) USE_HASH(B)
PQ_DISTRIBUTE(B,NONE,NONE)🍋 기출 포인트
- ⭐️HASH JOIN 오퍼레이션 위쪽에 "PX PARTITION RANGE ALL' 오퍼레이션이 나타난다면 FULL
PARTITION WISE JOIN 할 때의 실행계획이다.⭐️
✍️ 46번 : FULL PARTITION WISE JOIN
FULL PARTITION WISE JOIN에 대한 설명으로 가장 부적절한 것
- 파티션 개수보다 작거나 같은 개수의 DOP를 지정해야 한다. 👉 ⭕️
- 테이블 파티션 방식은 Range, List, Hash 어떤 것이든 상관없이 작동한다. 👉 ⭕️
- 조인 방식으로 일반적으로 해시조인을 사용하지만, NL 조인이든 또는 소트머지 조인도 사용할 수 있다. 👉 ⭕️
- 두 개의 서버집합이 필요하다. 👉 ❌
🍋 기출 포인트
- 다른 병렬 조인은 두 개의 서버집합이 필요한 반면, FULL PARTITION WISE JOIN에서는 하나
의 서버집합만 필요하다.
✍️ 47번 : PARTIAL PARTITION WISE JOIN
병렬 조인 실행계획으로 유도하는 힌트를 고르시오.
SELECT *
FROM 주문 A, 배송 B
WHERE A.주문번호 = B. 주문번호
AND A. 주문일자 = B. 주문일자
AND (이하 생략 ) 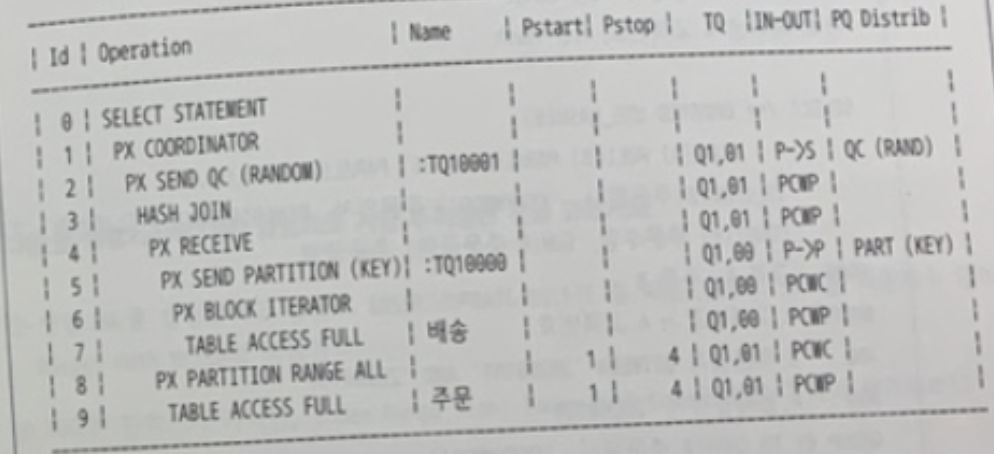
내 풀이
- 쿼리 작동 순서
- 주문 테이블 Full Scan
- 블록 단위 Granule 4개
- FULL(A) PARALLEL(A 4) LEADING(A)
- 주문상품 테이블 Full Scan
- 블록 단위 Granule 4개
- FULL(B) PARALLEL(B 4) USE_HASH(B)
- 고객 테이블을 주문 테이블 기준으로 파티셔닝한다.
- PQ_DISTRIBUTE(B,PARTITION,NONE)
- 주문 테이블 Full Scan
답
FULL(A) PARALLEL(A 4) LEADING(A) FULL(B) PARALLEL(B 4) USE_HASH(B)
PQ_DISTRIBUTE(B,PARTITION,NONE)✍️ 48번 :
통계정보를 재수집한 이후에 아래 병렬 쿼리를 실행하는 배치(Batch) 프로그램이 평소보다 오래 걸렸고, 실행계획은 아래와 같았다. 튜닝을 위해 추가해야 할 힌트로 가장 적절한 것은 ?
[ 고객 테이블 ]
등록 고객 수 = 300만 명
[ 주문 테이블 ]
월 평균 주문 레코드 = 1,000만 건
주 파티션 : 주문일자 기준 Range
서브 파티션 : 고객번호 기준 Hash
SELECT /*+ ORDERED USE_HASH(B) FULL(A) FULL(B) PARALLEL(A 16) PARALLEL(B 16) */
TO_CHAR(B.주문일시, 'YYYYMMDD') 주문일자, MIN(DISTINCT A.고객번호) 고객수
, COUNT(*) 주문수량, SUM(B. 주문금액) 주문금액
FROM 고객 A, 주문 B
WHERE B.고객번호 = A. 고객번호
AND B.주문일자 BETWEEN '20200101' AND '20200131'
AND A.등록일자 < '20200101'
GROUP BY TO_CHAR(B.주문일시, 'YYYYMMDD')
ORDER BY 1;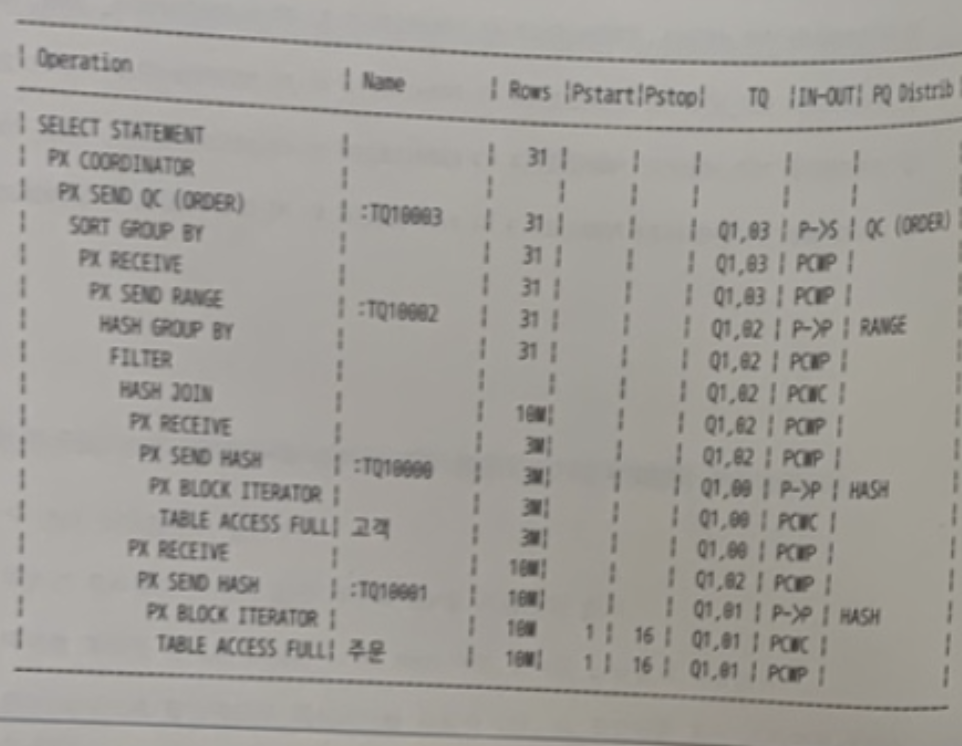
내 풀이
- 쿼리 작동 순서
- 고객 테이블 Full Scan
- 블록 단위 Granule 16개
- '고객번호'기준 해시 데이터 재분배
- FULL(A) PARALLEL(A 16) LEADING(A)
- 주문상품 테이블 Full Scan
- 블록 단위 Granule 16개
- FULL(B) PARALLEL(B 16) USE_HASH(B)
- 고객 테이블을 파티셔닝된 주문 데이터에 맞춰 해시 데이터 재분배 후 두번째 서버 프로세스에서 해시조인을 수행한다.왜냐하면 주문 테이블이 고객번호별로 서브 파티셔닝이 되어있기 때문이다.
- PQ_DISTRIBUTE(B,PARTITION,NONE)
- 고객 테이블 Full Scan
답
PQ_DISTRIBUTE(B,PARTITION,NONE)🍋 기출 포인트
- 고객 테이블을 Broadcast 하는 것도 고려해 볼 수 있으나, 현재 병렬도가 16인 점을 고려해
야 한다. 300만 고객 데이터를 16개 병렬 프로세스에 Broadcast 하는 과정에 많은 프로세스간 통신이 발생하고, 메모리 자원이 부족하면 Temp 테이블스페이스를 사용하게 될 수도 있다.
✍️ 49번 : 병렬처리
병렬처리에 대한 설명으로 가장 부적절한 것
- 쿼리문에 ROWNUM을 사용하면 병렬 처리 과정에 병목이 발생한다. 👉 ⭕️
- 병렬 DML을 활성화하고 병렬로 INSERT/UPDATE/DELETE 할 때는 별도의 힌트를 지정하지 않아도
Direct Path Write가 작동한다. 👉 ⭕️ - 파티션 인덱스가 아니면, Index Range Scan, Index Full Scan은 병렬 처리가 불가능하다. 👉 ⭕️
- NL 조인은 병렬 처리가 불가능하다. 👉 ❌
🍋 기출 포인트
- ⭐️병렬 DML을 활성화하고 병렬로 INSERT/UPDATE/DELETE 할 때는 별도의 힌트를 지정하지 않아도
Direct Path Write가 작동한다.⭐️
✍️ 50번 : 병렬처리
병렬처리를 사용할 때 주의사항으로 가장 부적절한 것
- 온라인 트랜잭션을 처리하는 시스템에서는 주간 업무 시간대의 병렬 처리를 제한하거나 최소화해야 한다. 👉 ⭕️
- 온라인 트랜잭션이 발생하는 테이블에 병렬 DML을 사용해선 안 된다. 👉 ⭕️
- 쿼리 틀에서 대량 데이터를 병렬로 조회한 후에 끝까지 Fetch 하지 않았다면,작은 테이블을
조회하는 쿼리를 수행함으로써 기존 병렬 쿼리의 커서가 닫히도록 조치해야 한다. 👉 ⭕️ - PARALLEL 힌트를 사용하면 어차피 테이블을 Full Scan 하므로 FULL 힌트를 사용할 필요가 없
다. 👉 ❌
🍋 기출 포인트
- ⭐️⭐️
- 병렬 DML 수행 시 Exclusive 모드 테이블 Lock이 걸리므로 업무 트랜잭션이 발생하는 주간
에 사용하는 것은 금물이다. - PARALLEL 힌트를 사용할 때는 FULL 힌트도 함께 사용하는 것이 바람직하다.옵티마이저가
인덱스 스캔을 선택할 경우 PARALLEL 힌트가 무시됨으로인해 배치 프로그램의 수행 성능이
평소보다 많이 느려지기 때문이다. - parallel_index 힌트를 사용할 때는 반드시 INDEX 또는 INDEX_FFS 힌트를 함께 사용하는 것이 바람직하다.
- 쿼리 틀에서 대량 데이터를 병렬로 조회한 후에 끝까지 Fetch 하지 않고 놔두면, 자원을 해
제하지 않은 채 프로세스가 계속 더 있게 된다. 따라서 작은 테이블을 조회하는 쿼리를 수
행함으로써 기존 병렬 쿼리의 커서가 닫히도록 조치하는 것이 바람직하다.
✍️ 번 :
- **** 👉 ⭕️
- **** 👉 ⭕️
- **** 👉 ⭕️
- **** 👉 ❌
🍋 기출 포인트
- ⭐️⭐️
🍒 문제 해설
- ⭐️⭐️

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’