✍️ 18번 : 하드 파싱 과정에 일어나는 작업
하드 파싱 과정에 일어나는 작업과 가장 거리가 먼 것을 고르시오.
- 옵티마이저 관련 파라미터를 참조한다. 👉 ⭕️
- 테이블 구성, 인덱스 구성, 컬럼 구성에 관한 정보를 조회한다. 👉 ⭕️
- 조인 순서, 조인 메소드, 테이블 액세스 방식, 인덱스 스캔 방식, 사용 인덱스 등을 결정한다. 👉 ⭕️
- 테이블 통계, 인덱스 통계, 컬럼 통계를 수집해서 딕셔너리에 저장한다. 👉 ❌
🍋 기출 포인트
- 테이블 통계, 인덱스 통계, 컬럼 통계는 하드 파싱 과정에 수집하는 것이 아니라 DBA가 설정한 주기(보통 일, 주, 월 단위)에 따라 미리 수집해 둔다.
1.물론, 다이나믹 샘플링이 필요한 상황이면 하드 파싱 과정에 통계정보를 수집하기도 하지만, 이를 딕셔너리에 저장하지는않는다.
✅ SQL을 최적화하는 동안 옵티마이저가 사용하는 정보
■ 테이블, 컬럼, 인덱스 구성에 관한 기본 정보
■ 오브젝트 통계 : 테이블 통계, 인덱스 통계, (히스토그램을 포함한) 컬럼 통계
■ 시스템 통계 : CPU 속도, Single Block I/O 속도, Multiblock I/O 속도 등
■ 옵티마이저 관련 파라미터
✍️ 19번 : 공유 가능한 SQL
아래 7개 SQL 중 공유 가능한 경우 고르기
가) SELECT * FROM emp WHERE emono = 7998;
나) select from EMP where EMPNO = 7990;
다) select from emp where empno = 7999;
라) select from scott.emp where empno=7900;
마) select /* comment */ * from emp where empno = 7900;
바) select /*+ first_rows */ * from emp where empno = 7900;
사) select from emp where empno = :empno; -- :empno에 7900 입력해서 실행- 없다. 👉 ⭕️
🍋 기출 포인트
- SQL은 이름이 따로 없다.
- SQL은 전체 SQL 텍스트가 이름 역할을 한다.
- SQL은 딕셔너리에 저장하지도 않는다. 처음 실행할 때 최적화 과정을 거쳐 동적으로 생성한 내부 프로시저를 라이브러리 캐시에 적재함으로써 여러 사용자가 공유하면서 재사용한다.
- SQL은 캐시 공간이 부족하면 버려졌다가 다음에 다시 실행할 때 똑같은 최적화 과정을 거쳐 캐시에 적재된다.
- SQL은 의미적으로 100% 같은 SQL이더라도 텍스트 중 일부가 다르면, 각각 최적화를 진행하고 라이브러리 캐시에서 별도 공간을 사용한다.
✍️ 20번 : 바인드 변수
바인드 변수에 대한 설명으로 가장 부적절한 것을 고르시오.
- 바인드 변수를 사용하면 한 SQL에 다른 값을 입력하면서 반복 재사용할 수 있다. 👉 ⭕️
- 바인드 변수를 사용하면 한 SQL에 대한 실행계획을 여러 프로세스가 사용할 수 있다. 👉 ⭕️
- 바인드 변수를 사용하면 최적화 과정에 컬럼 히스토그램을 사용하지 못한다. 👉 ⭕️
- 바인드 변수를 사용하면 상수 값을 사용할 때보다 쿼리 성능이 더 좋다. 👉 ❌
🍋 기출 포인트
- 조건절에 상수 값을 사용하면 컬럼 히스토그램을 사용할 수 있어 SQL 최적화에 도움이 된다.
- 소프트 파싱 시에도 최적화 과정을 거친다!! 즉 , '바인드 변수를 사용하면 최적화 과정에 컬럼 히스토그램을 사용하지 못한다.'는 옳은 선지이다.
🍒 문제 해설
- 바인드 변수를 사용하면 컬럼 히스토그램을 사용하지 못하므로 상수 값을 사용할 때보다 다소 안 좋은 실행계획을 수립할 가능성이 있다.
✍️ 21번 : 라이브러리 캐시 최적화 방안
라이브러리 캐시 최적화 방안과 가장 거리가 먼 것을 고르시오.
- 커서를 공유할 수 있는 형태로 SQL을 작성한다. 👉 ⭕️
- 세션 커서 캐싱 기능을 활용한다. 👉 ⭕️
- 애플리케이션 커서 캐싱 기능을 활용한다. 👉 ⭕️
- open_cursors 파라미터를 높게 설정한다. 👉 ❌
🍋 기출 포인트
- open_cursors 파라미터는 세션 당 Open 할 수 있는 커서 개수를 '제한'하는 파라미터다. 즉 , 세션 커서 캐싱,애플리케이션 커서 캐싱에서의 '커서'와는 상관없다.
✍️ 22번 : 커서
커서에 대한 설명으로 가장 부적절한 것을 고르시오.
- 공유 커서 : 라이브러리 캐시에 공유된 Shared SQL Area 👉 ⭕️
- 세션 커서 : PGA에 할당된 Private SQL Area 👉 ⭕️
- 애플리케이션 커서 : 세션 커서를 제어하는 클라이언트 측 핸들 👉 ⭕️
- 묵시적 커서 : 라이브러리에서 SQL을 찾는 작업을 생략하고 반복 수행할 수 있는 커서 👉 ❌
🍋 기출 포인트
- 명시적 커서는 DECLARE 문으로 SQL 문을 정의하고, 커서의 Open, Fetch, Close를 명시적으로 처리하는 개발 패턴을 말한다.
- 묵시적 커서는 DECLARE 문을 생략하고, 커서의 Open, Fetch, Close DBMS가 자동으로 처리하는 개발 패턴을 말한다.
- 라이브러리에서 SQL을 찾는 작업을 생략하고 반복 수행하는 기능은 '애플리케이션 커서 캐싱'에 대한 설명이다.
✍️ 23번 : 트레이스 결과 - 커서 캐싱
아래 트레이스 결과에 대한 설명으로 적절한 것을 고르시오.
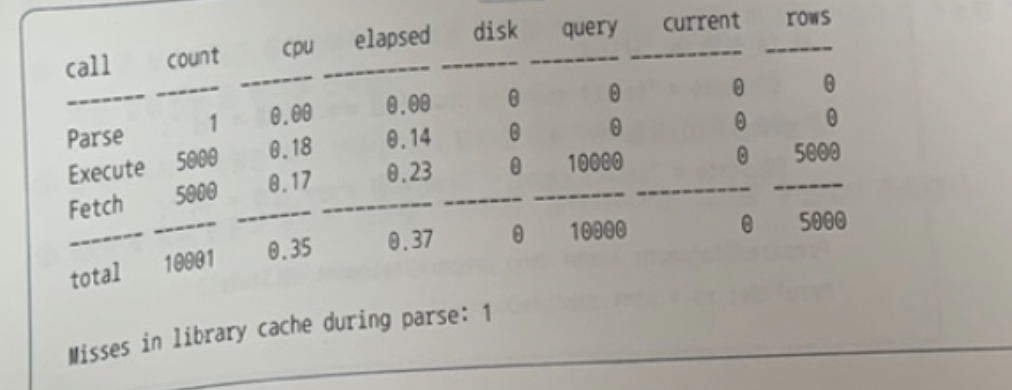
1. 애플리케이션 커서 캐싱 기능이 작동했다. 👉 ⭕️
1. 하드 파싱하지 않았다. 👉 ❌
1. SQL에 바인드 변수를 사용했다. 👉 ❌
1. 세션 커서 캐싱 기능이 작동했다. 👉 ❌
🍋 기출 포인트
- 5,000번 실행(Execute Call = 5000)했는데 Parse Call은 단 1회만 발생한 사실을 통해 애플리케이션 커서를 캐싱한 상태에서 반복 실행했음을 알 수 있다.
🍒 문제 해설
- 'Misses in library cache during parse: 1'을 통해 최초 1회 하드 파싱이 일어난 사실을 알 수 있다.
- 바인드 변수를 사용하면 커서를 공유할 수 있으므로 하드 파싱이 한번만 일어난다.
하지만, 아래와 같이 상수 조건으로 반복 실행해도 커서를 공유할 수 있으므로 현재의 트레
이스 결과만으로는 바인드 변수 사용 여부를 알 수 없다.
SELECT COUNT(*) FROM 주문 WHERE 주문상태코드 = 'ABC'; - 세션 커서 캐싱의 작동 여부는 트레이스 결과로 알 수 없다.
v$open_cursor 뷰에서 해당 SQL의 CURSOR_TYPE이 `SESSION CURSOR CACHED'인지를 통해 확인 가능하다.
✍️ 24번 : Static SQL vs. Dynamic SQL
아래 SOL 수행방식에 대한 설명으로 올바른 것을 고르시오
(가) 토드, 오렌지, SQL*Plus 같은 쿼리 툴에서 아래 SQL을 실행했다.
select count(*) from 사원 where 성별 = '남' :
(나) 토드, 오렌지, SQL*Plus 같은 쿼리 툴에서 ip_성별 변수에 '남'을 입력하고, 아래
SQL을 실행했다.
select count(*) from 사원 where 성별 = p_성별 :
(다) JAVA에서 아래와 같이 코딩하고 SQL을 실행했다.
String SQLState = "select count(*) from 사원 where 성별 = ?";
PreparedStatement stmt= conn.prepareStatement(SQLState);
stnt.setString(1, "남");
ResultSet rs = stmt.executeQuery();
(라) JAVA에서 아래와 같이 코딩하고 SQL을 실행했다.
String p_성별 = "";
String SQLState = "select count(*) from 사원 where 성별 = " + p_성별;
PreparedStatement stnt=conn.prepareStatement(SQLState);
ResultSet rs = stmt.executeQuery();
(마) JAVA에서 아래와 같이 코딩하고 SQL을 실행했다.
if (p_성별 = '남') {
SQLState = "select count(*) from 사원 where 성별 = '남'";
} else if (p_성별 = "여') {
SQLState = "select count(*) from 사원 where 성별 = '여'";
}
PreparedStatement stat= conn.prepareStatement(SQLState);
ResultSet rs = stmt.executeQuery();- 모두 Dynamic SQL이다. 👉 ⭕️
- (라)는 Dynamic SQL이고, 나머지는 Static SQL이다. 👉 ❌
- (나)와 (다)는 Static SQL이고, 나머지는 Dynamic SQL이다. 👉 ❌
- 모두 Static SOL이다. 👉 ❌
🍋 기출 포인트
✅ Static SQL
- String형 변수에 담지 않고 코드 사이에 직접 기술한 SQL문을 말한다.
- 다른 말로 'Embedded SQL'이라고도 한다.
- Static(=Embedded) SQL을 지원하는 개발 언어로는 PowerBuilder, PL/SQL, Pro*C, SQLJ 정도가 있다.나머지 개발 언어에서 수행하는 SQL은 모두 Dynamic SQL이다.
✅ Dynamic SQL
- String형 변수에 담아서 기술하는 SQL문을 말한다.
- String 변수를 사용하므로 조건에 따라 SQL문을 동적으로 바꿀 수 있고, 또는 런타임 시에 사용자로부터 SQL문의 일부 또는 전부를 입력 받아서 실행할 수도 있다.
- Static, Dynamic SQL은 애플리케이션 개발 측면에서의 구분일 뿐이며, DBMS 입장에서는 차이가 없다.
- Static SQL를 사용하든 Dynamic SQL를 사용하든 DBMS 입장(오라클,Mysql..)에서는 전달받은 SQL문 그 자체만 인식할 뿐이다.
- JAVA 언어는 Static SQL을 지원하지 않는다. 쿼리 툴에서 수행하는 SQL은 모두 Dynamic SQL이다.
✍️ 25번 : CURSOR_SHARING 파라미터의 개념 및 활용 기준
CURSOR_SHARING 파라미터의 개념 및 활용 기준으로 가장 부적합한 것을 고르시오.
- FORCE로 설정하면, SQL에 사용한 상수 값이 바인드 변수로 자동 변환된다. 👉 ⭕️
- EXACT로 설정하면, SQL 문장이 100% 일치할 때만 캐싱된 커서를 공유 및 재사용한다. 👉 ⭕️
- FORCE로 설정하면, 바인드 변수를 사용하지 않음으로 인한 SQL 하드파싱 부하를 줄이는 데 도움을 준다. 👉 ⭕️
- EXACT로 설정하면, SQL 하드파싱 부하를 유발하므로 가급적 FORCE로 설정하는 것이 좋다. 👉 ❌
🍋 기출 포인트
- CURSOR_SHARING 파라미터를 FORCE로 설정하면, SOL에 사용한 상수 값을 바인드 변수로 강제변환해 줌으로써 "상수 값만 다른 동일 SQL"을 반복해서 하드파싱하는 데 따른 부하를 줄여준다.
🍒 문제 해설
- 일반적인 상황에서 CURSORSHARING 파라미터를 FORCE로 설정하는 건 금물이다.
기본 값인 EXACT로 설정했을 때 발생할 수 있는 하드파싱 부하를 우려하기보다 정상적인 방법으로 바인드 변수 처리하는 것이 올바른 접근방법이다.
✅ CURSOR_SHARING 파라미터의 대표적인 부작용
- 첫째, SQL을 실행할 때마다 상수 값을 바인드 변수로 변환하는 과정에 불필요한 CPU
자원을 소모하게 된다.
- 문장이 전혀 바뀌지 않는 SOL을 반복 실행하는 데도 매번 상수 값을 바인드 변수로 변환한 후 값을 대입해서 실행하기 때문에 파싱 시간이 더 오래 걸릴 수 있다.
- 둘째, 컬럼 히스토그램이 도움이 되는 상황에서도 상수 값을 강제 바인드 변수 처리함으로 인해 비효율적인 실행계획이 수립될 수있고, 이는 I/O 증가 및 성능 저하로 이어질 수 있다.

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’