AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (Vision Transformer; ViT) 논문 요약
Transformer 관련 논문
Google Research가 ICLR 2021에 발표하였다. CNN을 사용하지 않고 Transformer 아키텍쳐만을 사용하여 이미지 분류 작업에서 매우 좋은 성능을 보인다.
적은 inductive bias 때문에 ImageNet과 같은 중간 크기의 이미지 분류 데이터셋에서는 비슷한 크기의 ResNet보다 좋은 성능을 보이지 않지만, 대규모 데이터셋에서는 더 좋은 성능을 보인다.
빠뜨린 내용이 많으니 다 읽고 논문을 참고하는 게 좋다.
방법
의 이미지를 의 patch들로 자른다.
여기서 와 는 이미지의 세로와 가로 길이고, 는 채널의 수이다.
은 patch의 수이고, 가 됨은 쉽게 알 수 있다.
Patch의 크기는 이다. 따라서 는 하나의 patch와 그에 따른 채널을 flatten 한 차원이 된다.
ViT는 D 차원의 latent vector size를 가지고 있다. 여기에 맞추기 위해, 를 로 trainable linear projection 해서 patch embeddings를 만든다.
이는 임베딩된 길이 의 embedded token들로 해석할 수 있다. 여기에 BERT의 [class] token과 유사하게 learnable embedding을 하나 앞에 추가하여 ViT의 input을 구성한다.
Position embeddings가 추가된다. 여기서는 표준적인 1D position embeddings을 사용했다. 더 발전된 2D-aware position embeddings를 실험해보았지만 눈에 띄는 성능 향상이 없었다고 한다.
그림을 보면 더 이해가 쉽다.
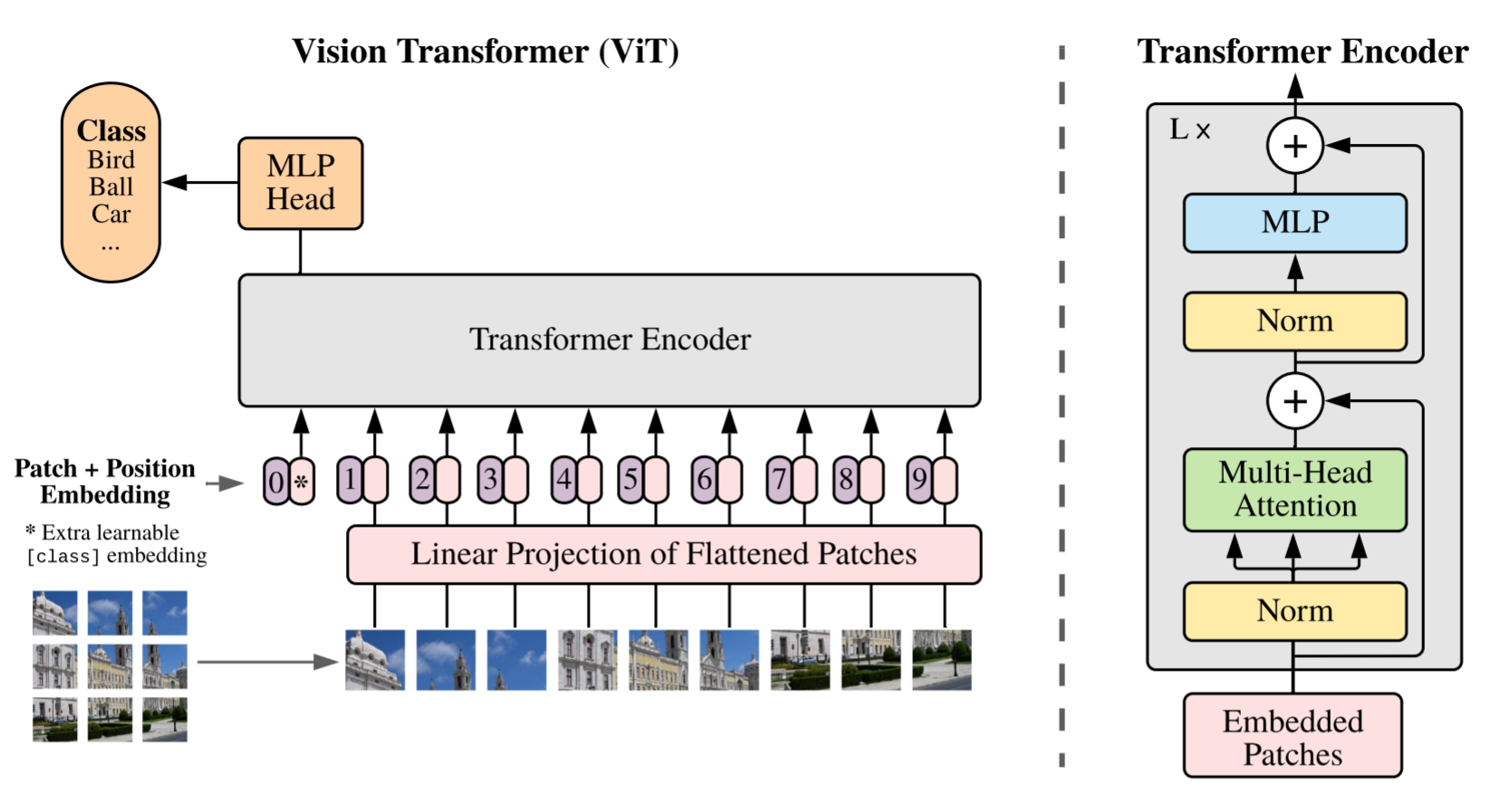
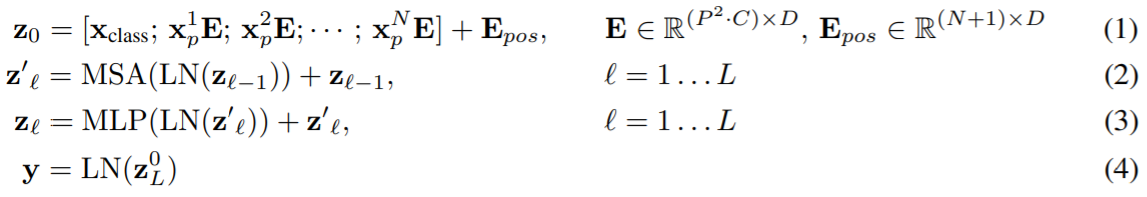
Transformer encoder는 layernorm, multi-headed attention, MLP 블록을 가지며, residual connection을 사용한다.
실험
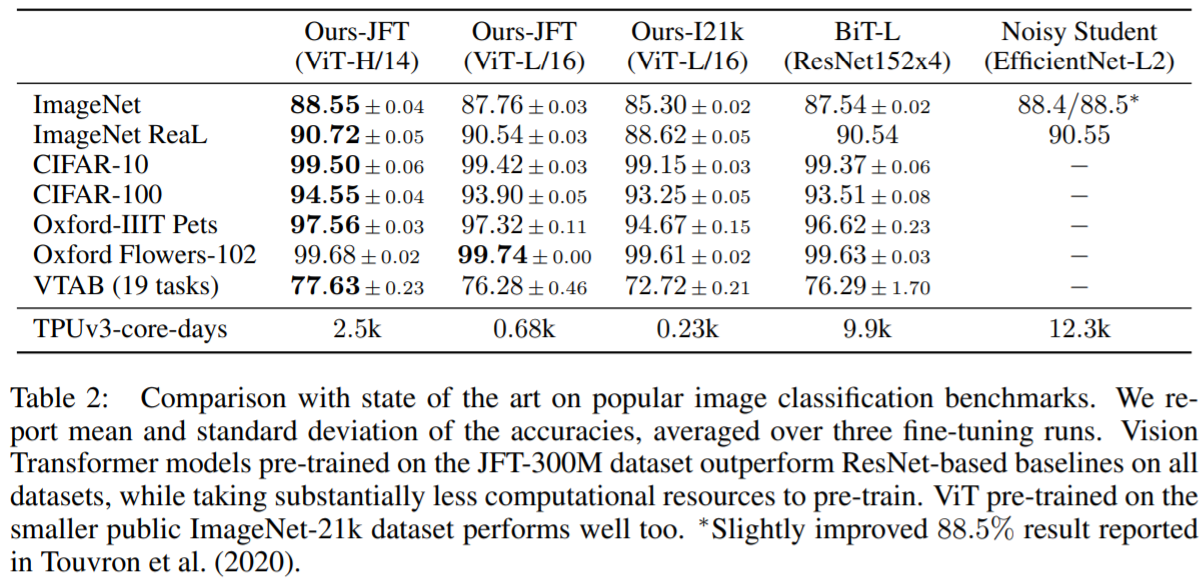
JFT-300M 데이터셋을 사용해 self-supervised 방법으로 pre-train 하고 각 데이터셋에 fine-tuning 한 결과이다. CNN 기반 타 모델보다 적은 학습 시간으로 좋은 성능을 보인다.
자세한 실험 내용은 논문에 있다. 또한, 다른 실험들도 논문에 있으니 꼭 논문을 참고하도록 하자.
참고
