🎯 목표
- 쿠버네티스 Observablility에 대한 이해 확립
- Metric-server에 대한 이해 확립
- kwatch 또는 botkube를 통해 Slack으로 지표 전달
- Prometheus와 Grafa를 조합하여 오픈소스 모니터링 인프라 구축
🏃 진행
1. 실습을 위한 EKS 배포
- natgw, ebs addon, ec2 iam role add, irsa lb/efs, preCmd 추가 된 onclick.yaml 파일로 배포
- ExternalDNS, kube-ops-view, AWS LB Controller, EFS csi driver 설치
2. EKS console
- 쿠버네티스 API를 통해 리소스 및 정보를 확인 할 수 있음
kubectl get ClusterRole | grep eks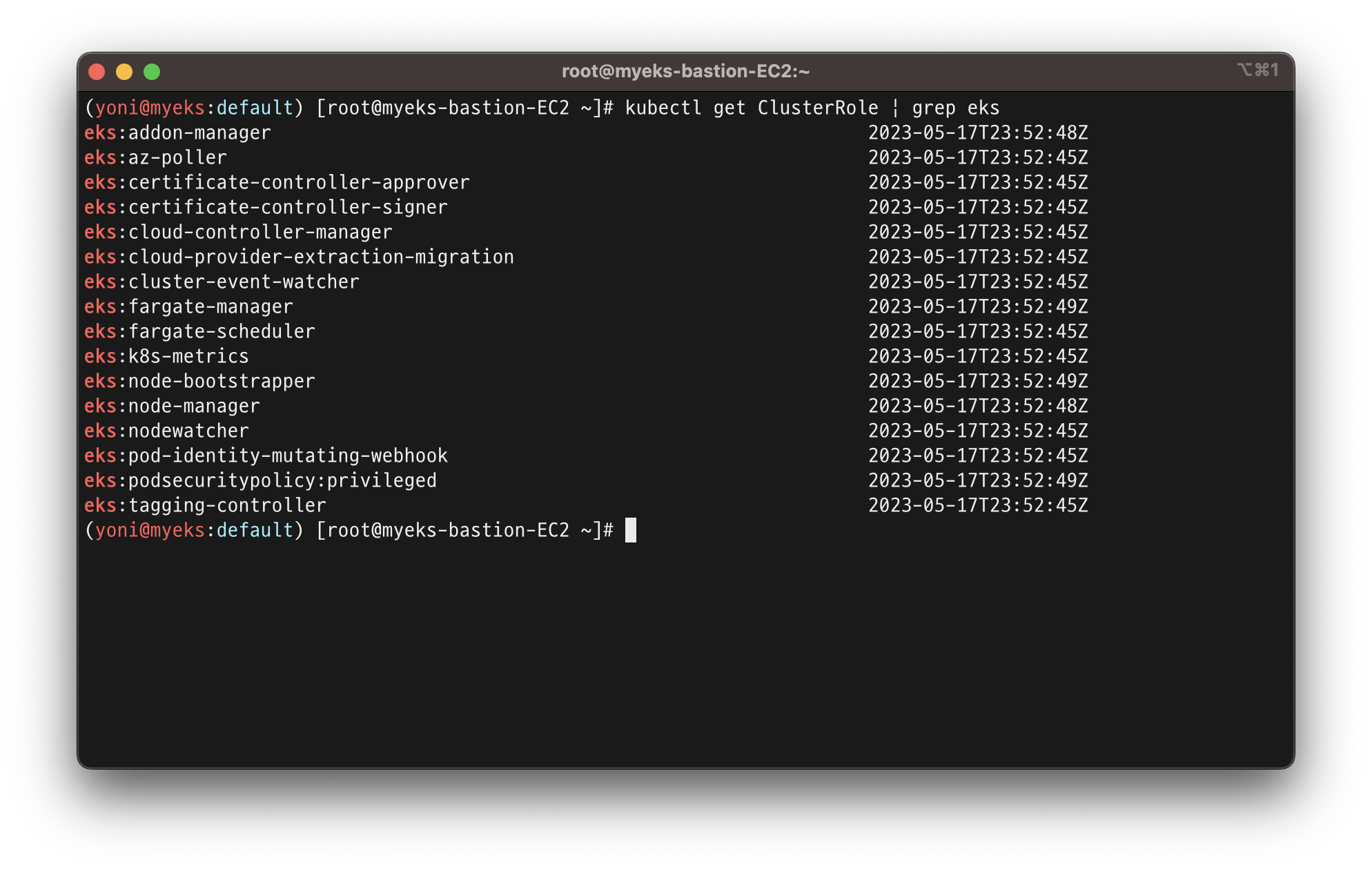
- AWS console에서도 EKS에 대한 내용 확인 할 수 있음
Console 각 메뉴 확인 : https://www.eksworkshop.com/docs/observability/resource-view/
3. Logging in EKS
👉 Control Plane logging
- 컨트롤 플레인의 모든 로깅 활성화
aws eks update-cluster-config --region $AWS_DEFAULT_REGION --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'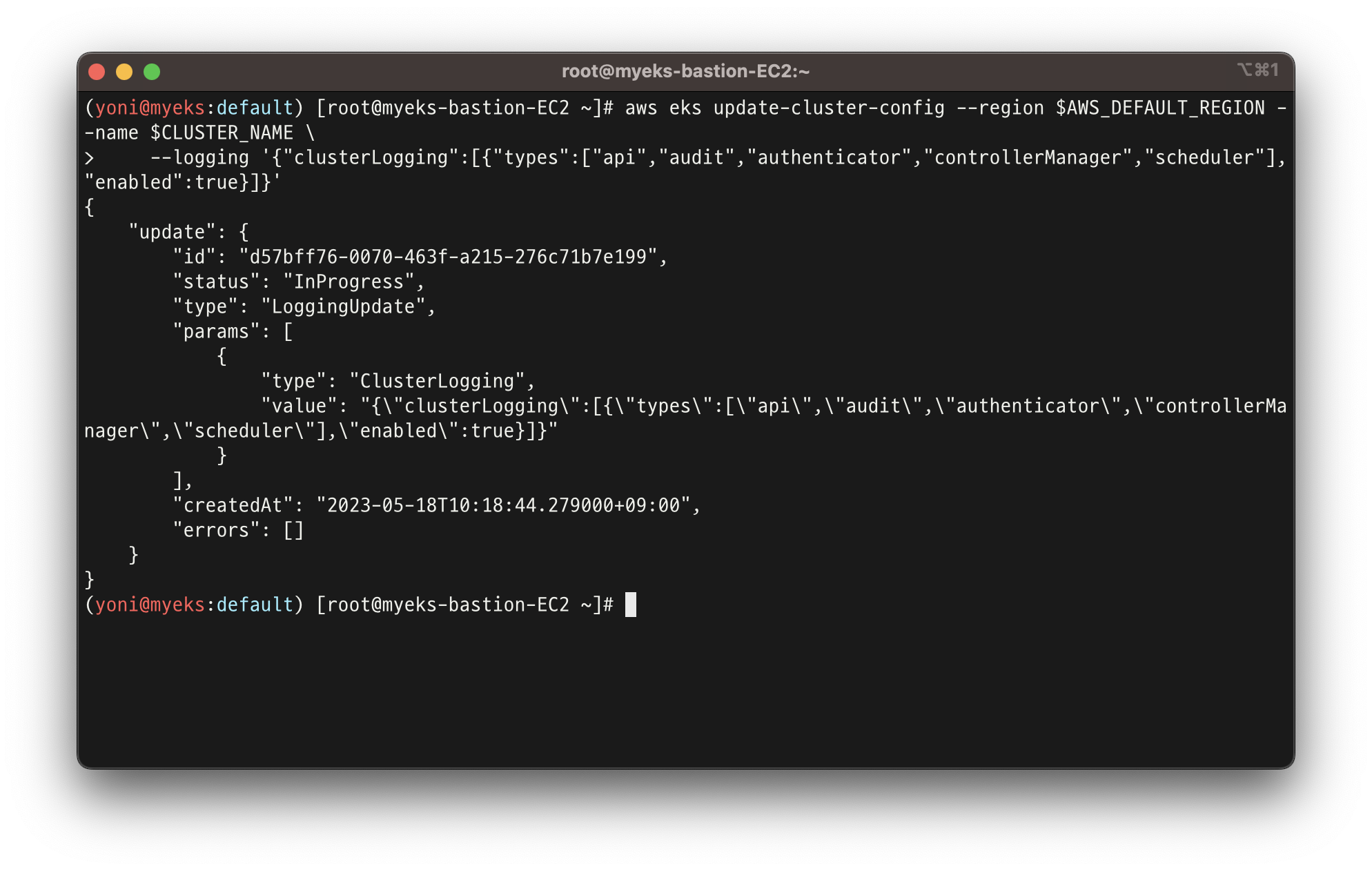
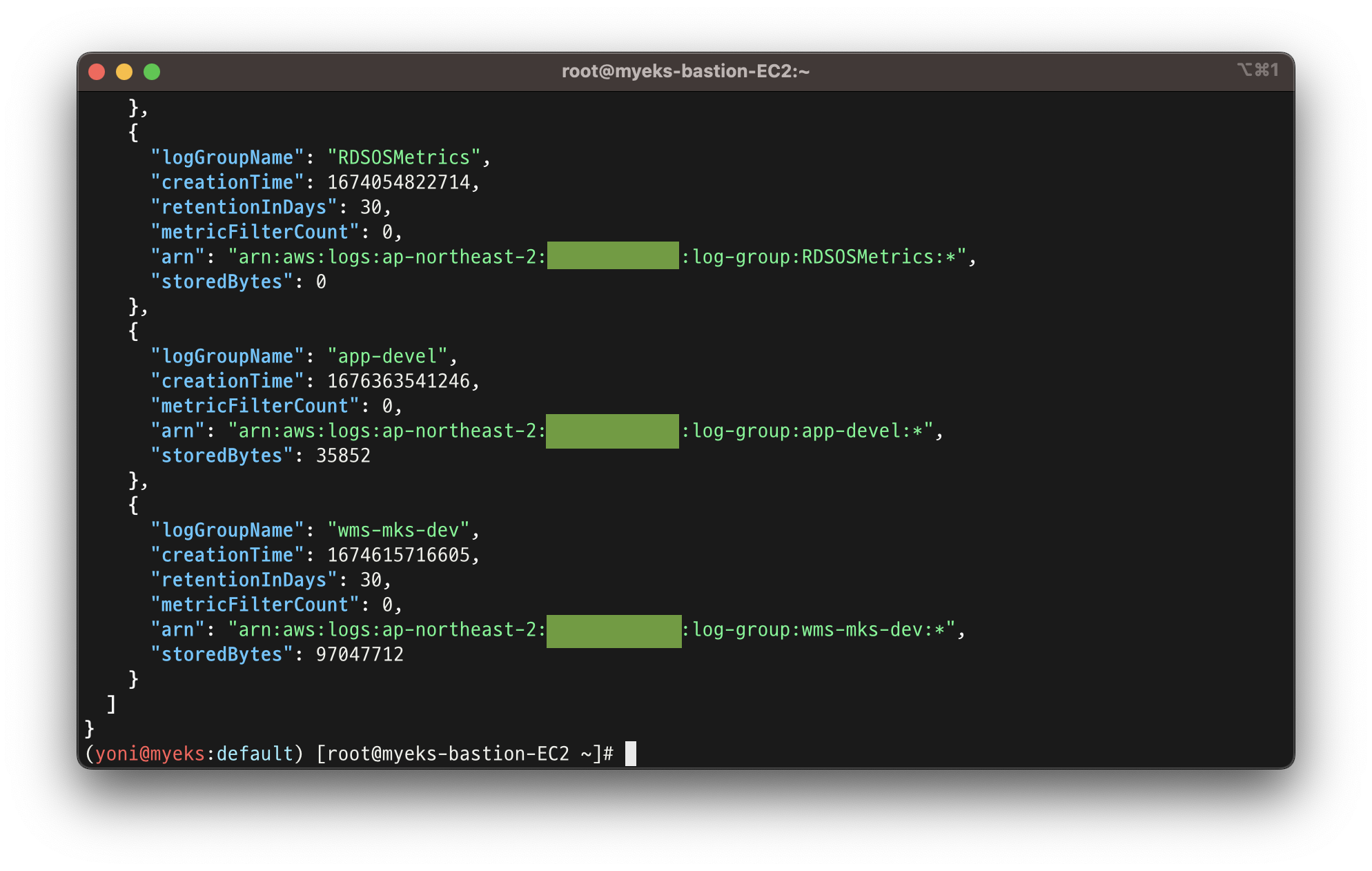
- 활성화 된 로그 그룹 확인
aws logs describe-log-groups | jq
- 이 외 활성화 된 로그에 대한 정보를 확인 할 수 있는 명령어들
# 로그 tail 확인 : aws logs tail help
aws logs tail /aws/eks/$CLUSTER_NAME/cluster | more
# 신규 로그를 바로 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --follow
# 필터 패턴
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --filter-pattern <필터 패턴>
# 로그 스트림이름
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix <로그 스트림 prefix> --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-controller-manager --follow
kubectl scale deployment -n kube-system coredns --replicas=1
kubectl scale deployment -n kube-system coredns --replicas=2
# 시간 지정: 1초(s) 1분(m) 1시간(h) 하루(d) 한주(w)
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m
# 짧게 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m --format short- 필터 패턴
default로 설정해봄
👉 cloudwatch Log insights
- 클라우드워치의 로그 인사이트를 사용하여 로그 검색
# EC2 Instance가 NodeNotReady 상태인 로그 검색
fields @timestamp, @message
| filter @message like /NodeNotReady/
| sort @timestamp desc
# kube-apiserver-audit 로그에서 userAgent 정렬해서 아래 4개 필드 정보 검색
fields userAgent, requestURI, @timestamp, @message
| filter @logStream ~= "kube-apiserver-audit"
| stats count(userAgent) as count by userAgent
| sort count desc
#
fields @timestamp, @message
| filter @logStream ~= "kube-scheduler"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "authenticator"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "kube-controller-manager"
| sort @timestamp desc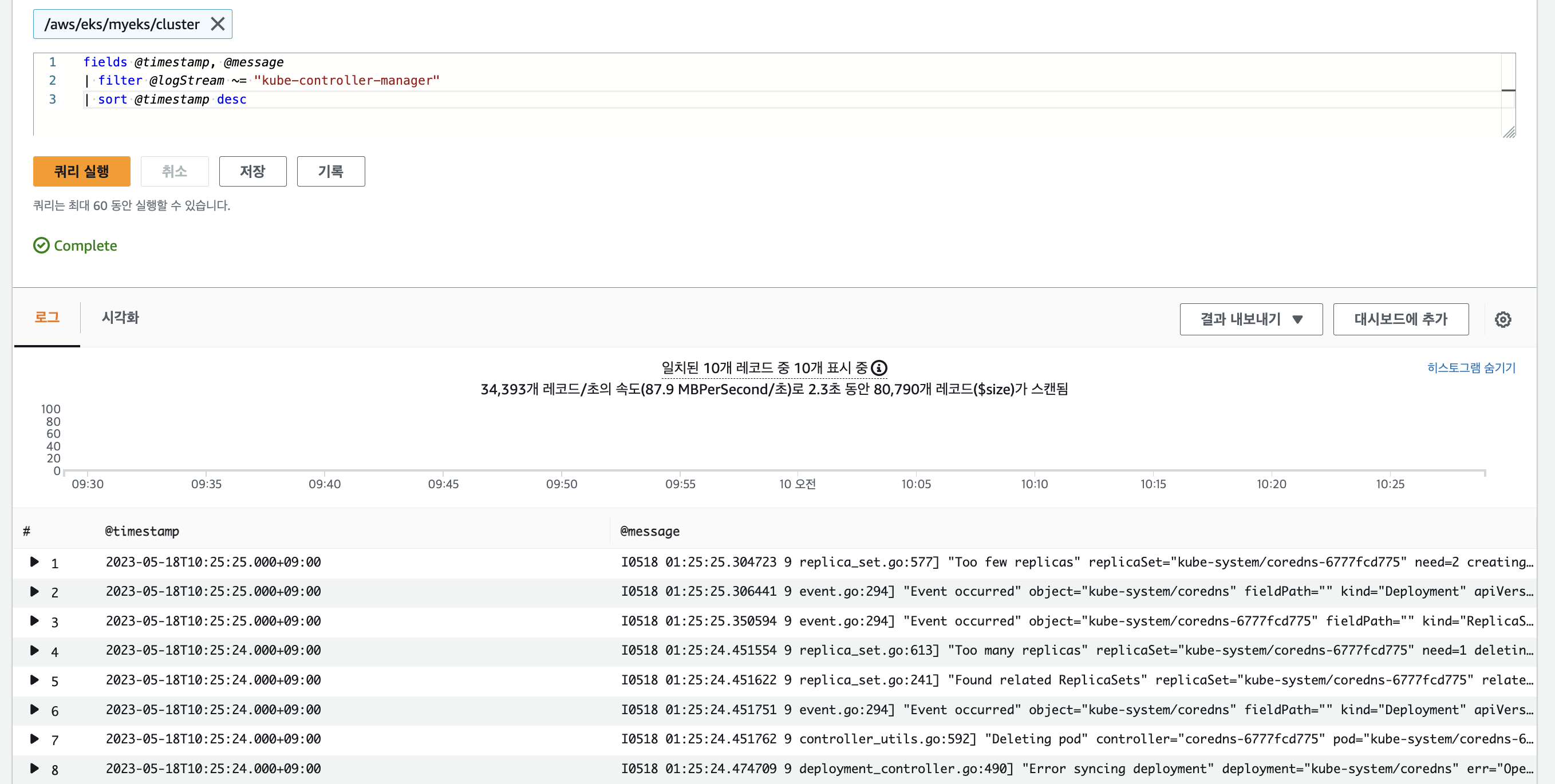
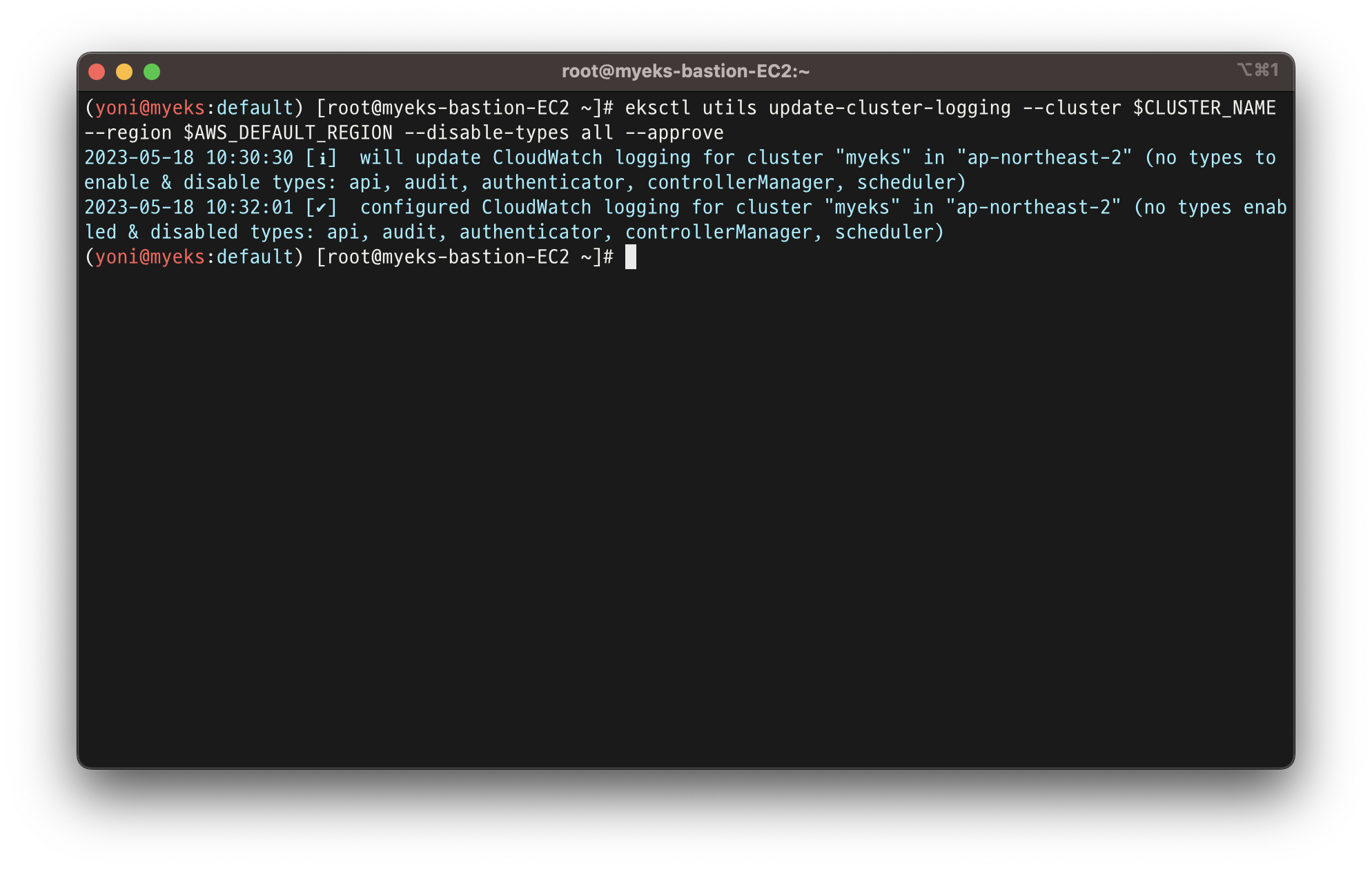
👉 로깅 끄기
- EKS Control Plane 로깅(CloudWatch Logs) 비활성화
👉 Control Plane metrics with Prometheus & CW Logs Insights 쿼리
- 메트릭 패턴 정보 : metric_name{"tag"="value"[,...]} value 확인
kubectl get --raw /metrics | more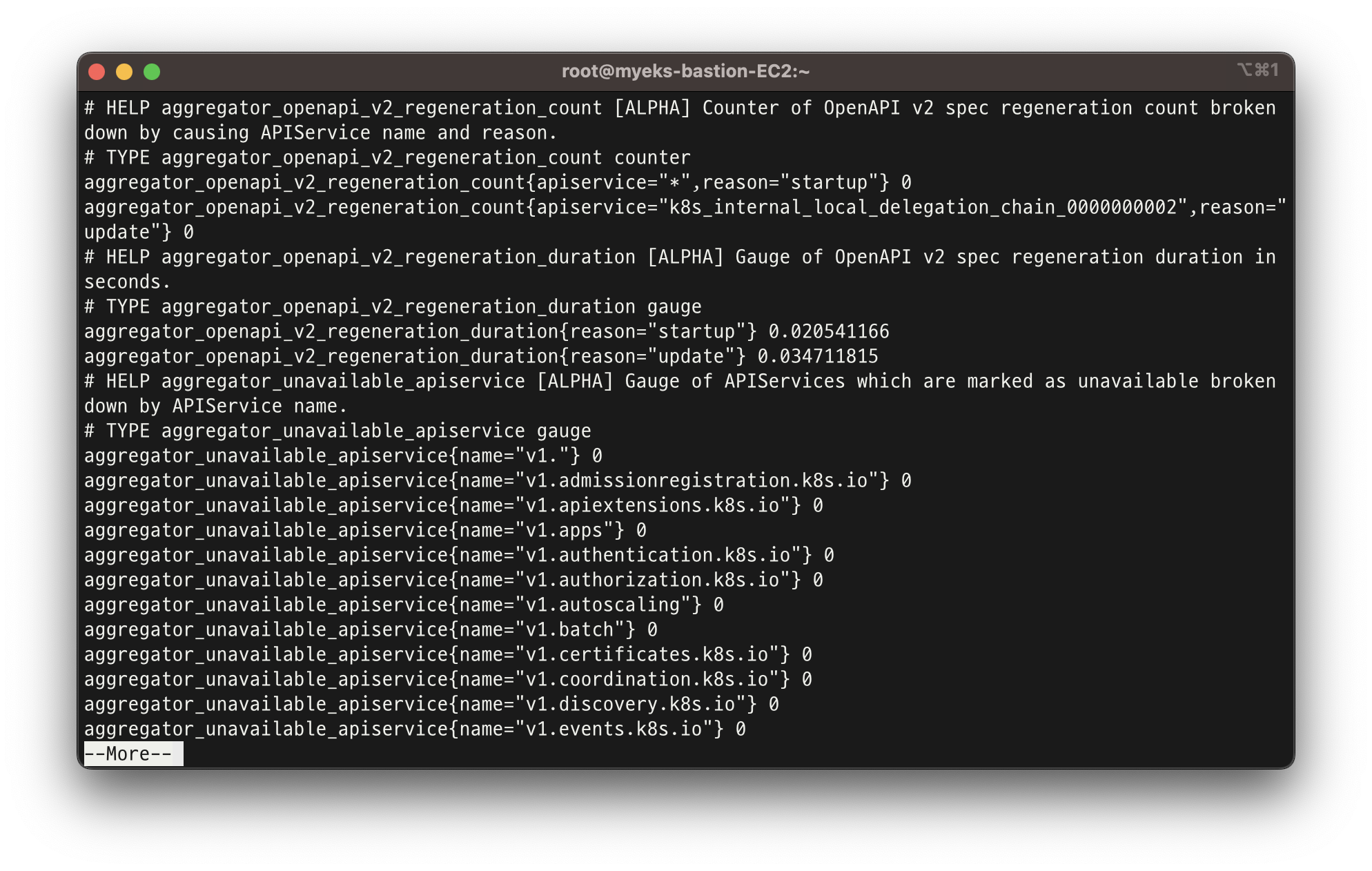
Managing etcd database size on Amazon EKS clusters
- etcd database total size 확인
kubectl get --raw /metrics | grep "etcd_db_total_size_in_bytes"
- 100보다 높은 apiserver_stroage_objects 확인
kubectl get --raw=/metrics | grep apiserver_storage_objects |awk '$2>100' |sort -g -k 2 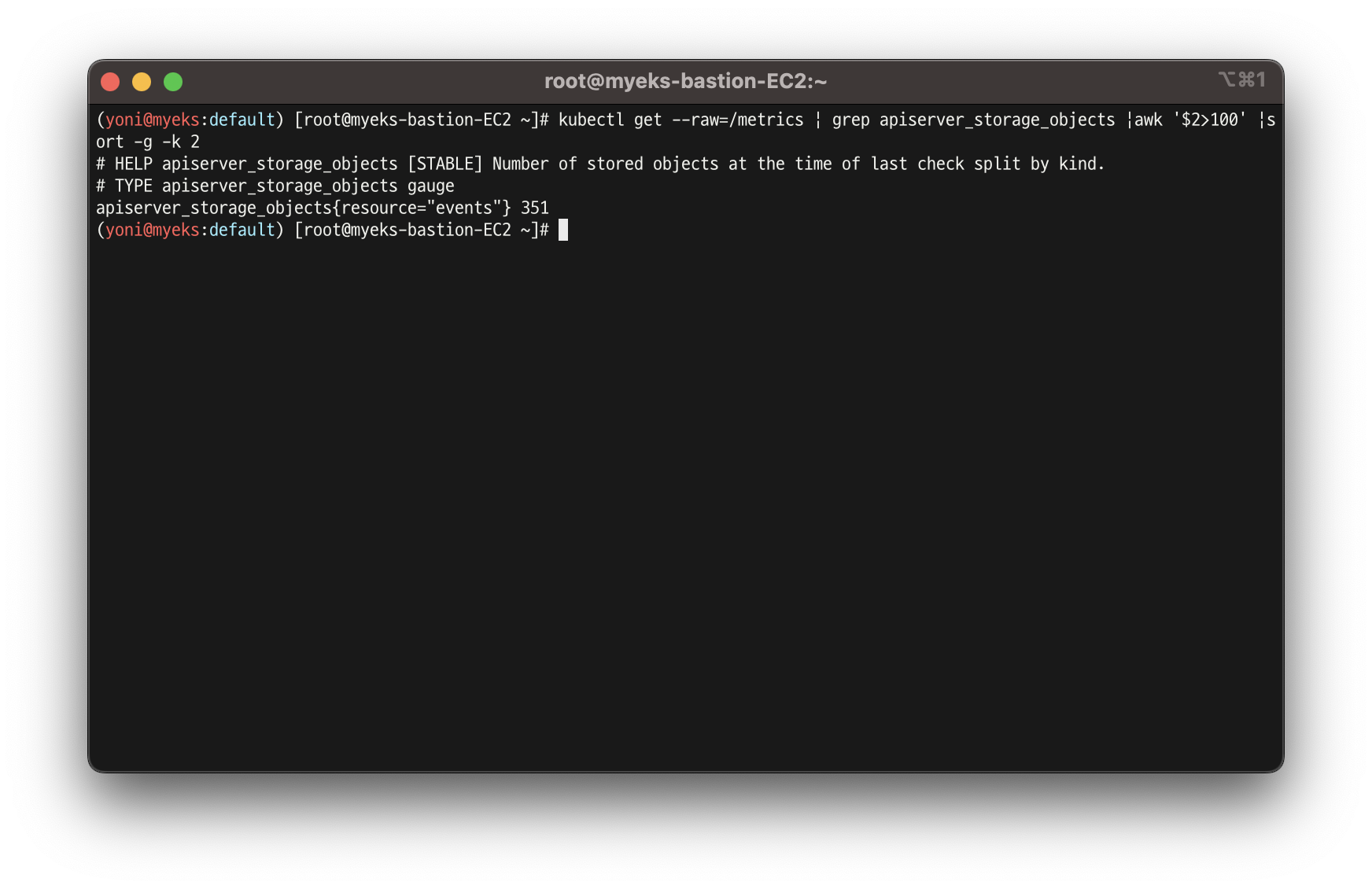
- AWS console에서도 확인 가능
fields @timestamp, @message, @logStream
| filter @logStream like /kube-apiserver-audit/
| filter @message like /mvcc: database space exceeded/
| limit 10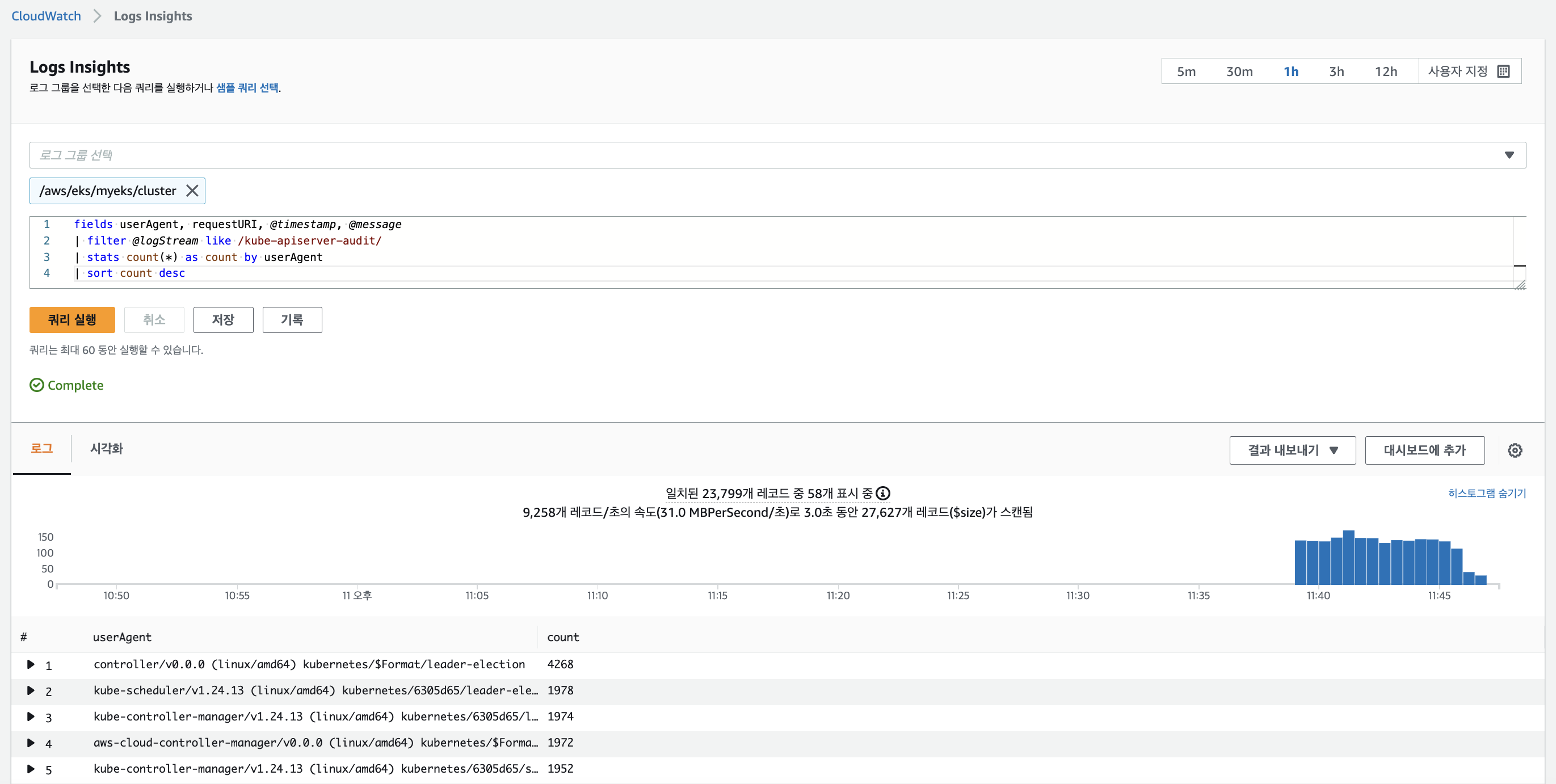
👉 컨테이너(파드) 로깅을 위한 NGINX 웹서버 배포
# NGINX 웹서버 배포
helm repo add bitnami https://charts.bitnami.com/bitnami
# 사용 리전의 인증서 ARN 확인
CERT_ARN=$(aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text)
echo $CERT_ARN
# 도메인 확인
echo $MyDomain
# 파라미터 파일 생성
cat <<EOT > nginx-values.yaml
service:
type: NodePort
ingress:
enabled: true
ingressClassName: alb
hostname: nginx.$MyDomain
path: /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
EOT
cat nginx-values.yaml | yh
# 배포
helm install nginx bitnami/nginx --version 14.1.0 -f nginx-values.yaml
# 확인
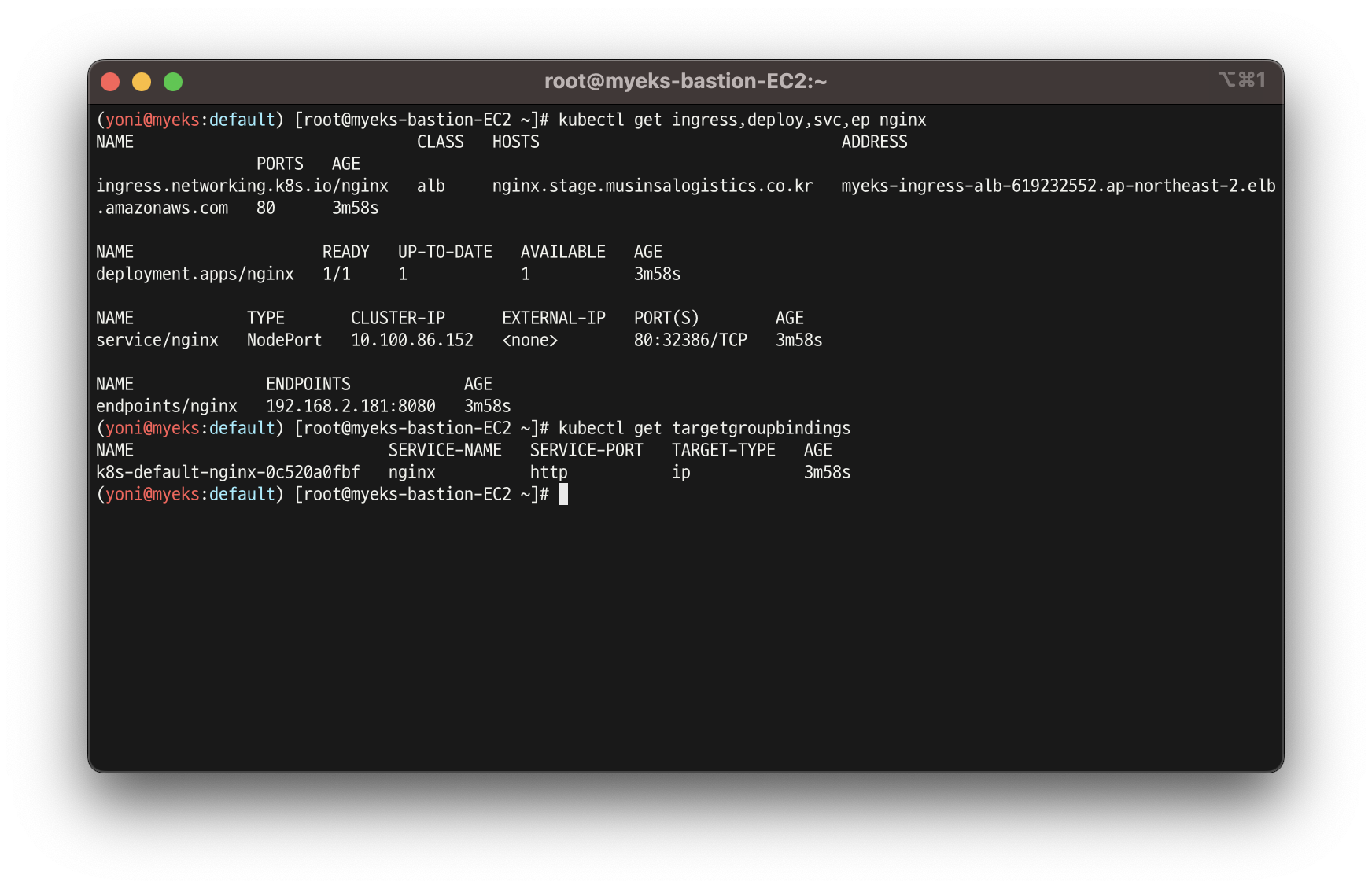
kubectl get ingress,deploy,svc,ep nginx
kubectl get targetgroupbindings # ALB TG 확인
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = https://nginx.$MyDomain"
curl -s https://nginx.$MyDomain
kubectl logs deploy/nginx -f
# 반복 접속
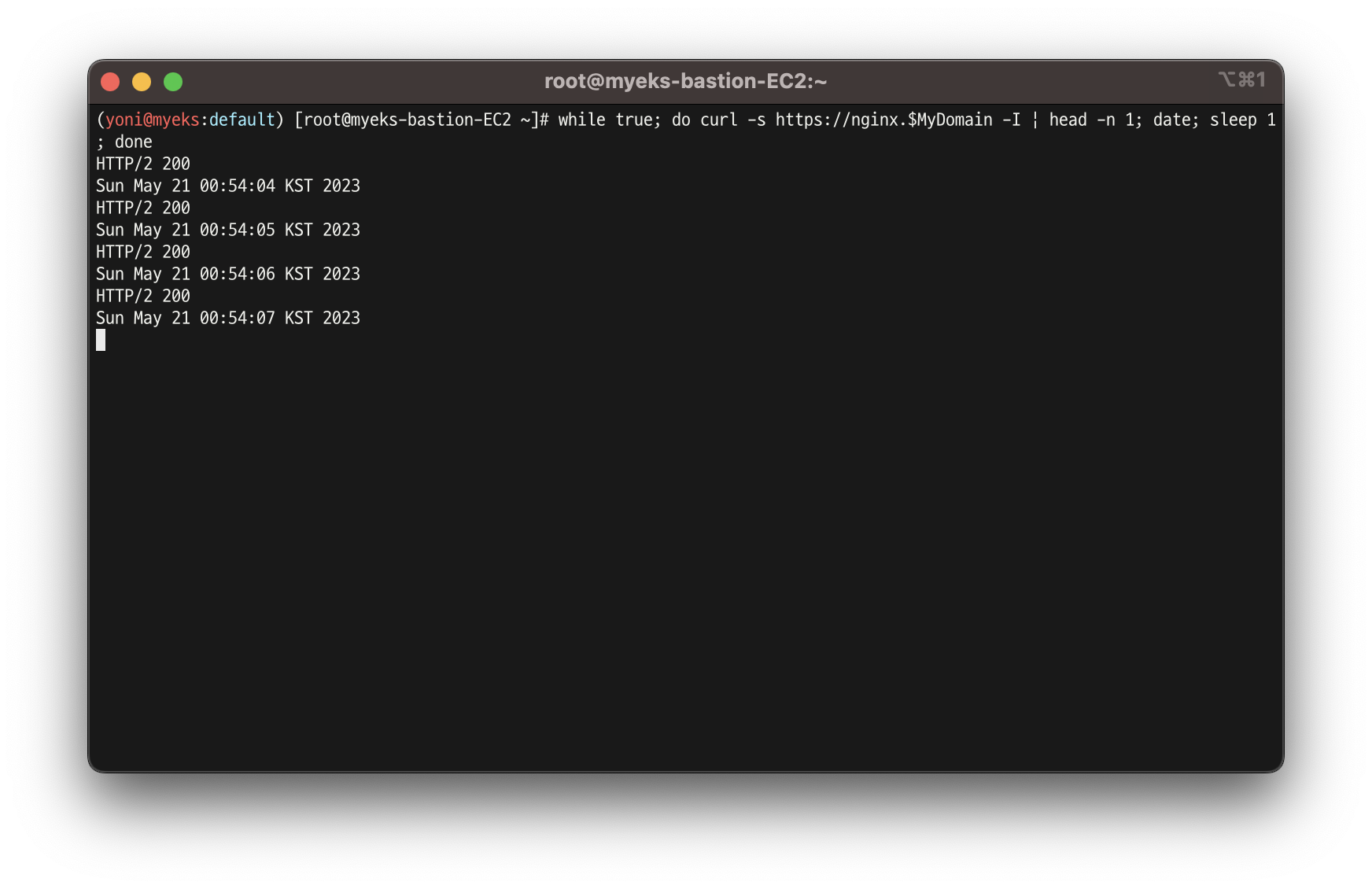
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; sleep 1; done
# (참고) 삭제 시
helm uninstall nginx-
배포 확인
-
접속 주소 확인 및 접속
-
반복 접속
-
컨테이너 로그 환경의 로그는 표준 출력 stdout과 표준 에러 stderr로 보내는 것을 권고
https://docs.docker.com/config/containers/logging/
해당 권고에 따라 작성된 컨테이너 애플리케이션의 로그는 해당 파드 안으로 접속하지 않아도
사용자는 외부에서 kubectl logs 명령어로애플리케이션 종류에 상관없이,
애플리케이션마다로그 파일 위치에 상관없이, 단일 명령어로 조회 가능
- 로그 모니터링
kubectl logs deploy/nginx -f
#❗️ 종료된 파드의 로그는 kubectl logs로 조회 할 수 없음
- 컨테이너 로그 파일 위치 확인
kubectl exec -it deploy/nginx -- ls -l /opt/bitnami/nginx/logs/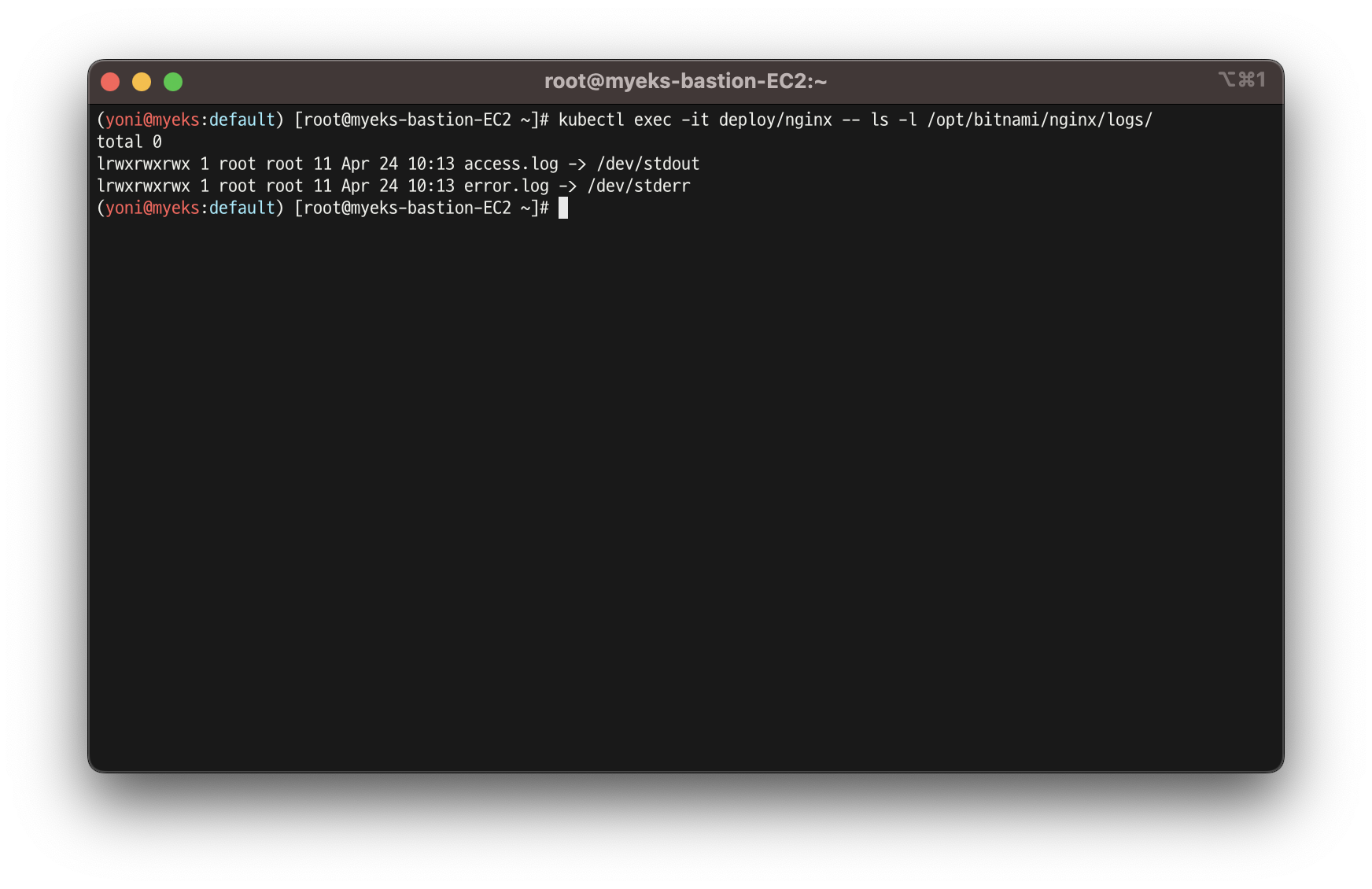
- ❗️ kubelet 기본 설정은 로그 파일의 최대 크기가 10Mi로 10Mi를 초과하는 로그는 전체 로그 조회가 불가능함
- 최대 파일 크기를 확인 하려고 했으나, 실제 노드에서 확인 할 수 없었음
- 이 부분에 대해 추가로 정리할 예정
cat /etc/kubernetes/kubelet/kubelt-config.json
4. Container Insights metrics in Amazon CloudWatch & Fluent Bit (Logs)
👉 Fluent Bit
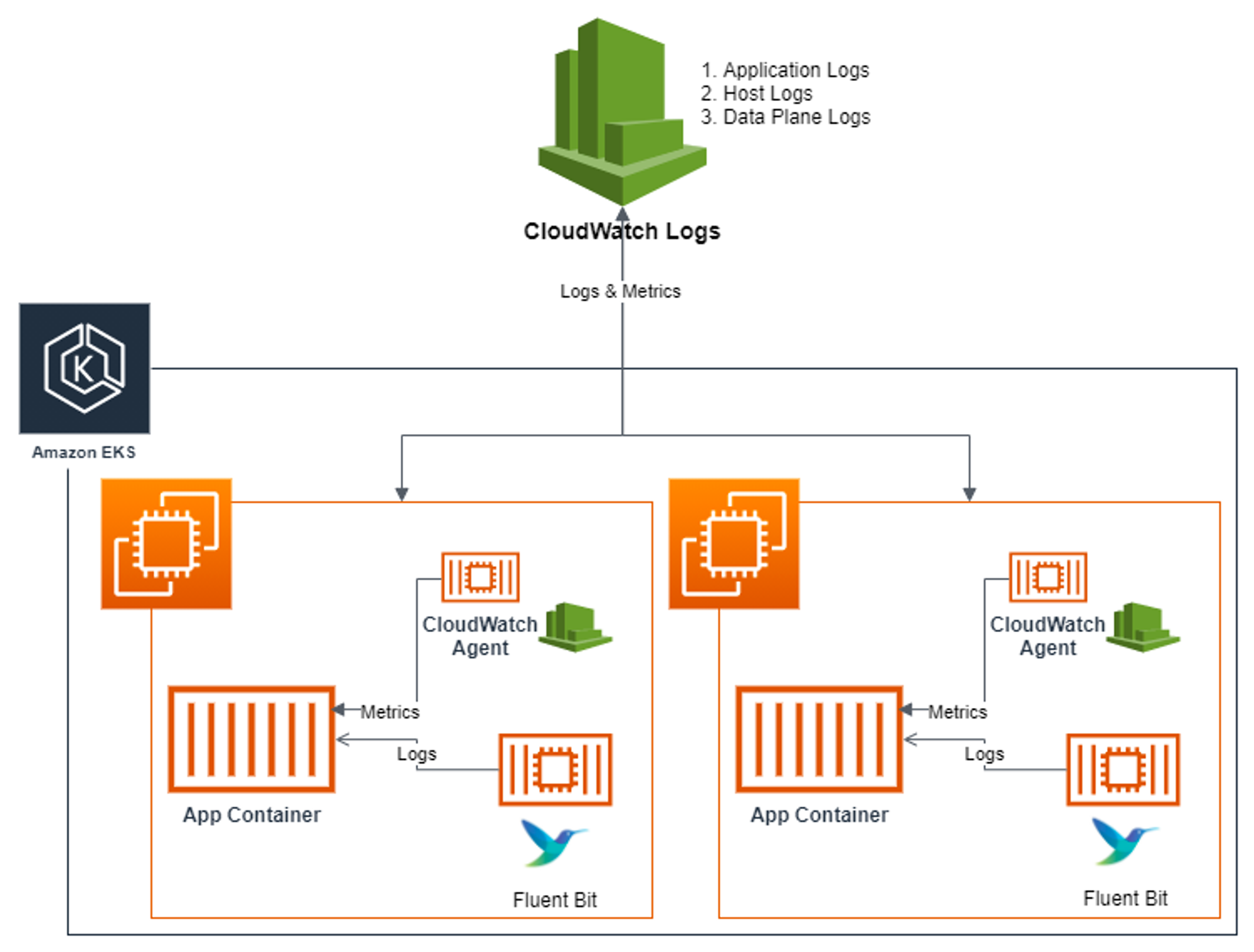
- [수집] 플루언트비트 Fluent Bit 컨테이너를 데몬셋으로 동작시키고, 아래 3가지 종류의 로그를 CloudWatch Logs 에 전송
- /aws/containerinsights/
Cluster_Name/application : 로그 소스(All log files in/var/log/containers), 각 컨테이너/파드 로그 - /aws/containerinsights/
Cluster_Name/host : 로그 소스(Logs from/var/log/dmesg,/var/log/secure, and/var/log/messages), 노드(호스트) 로그 - /aws/containerinsights/
Cluster_Name/dataplane : 로그 소스(/var/log/journalforkubelet.service,kubeproxy.service, anddocker.service), 쿠버네티스 데이터플레인 로그
- /aws/containerinsights/
- [저장] : CloudWatch Logs 에 로그를 저장, 로그 그룹 별 로그 보존 기간 설정 가능
- [시각화] : CloudWatch 의 Logs Insights 를 사용하여 대상 로그를 분석하고, CloudWatch 의 대시보드로 시각화한다
- (참고) Fluent Bit is a lightweight log processor and forwarder that allows you to collect data and logs from different sources, enrich them with filters and send them to multiple destinations like CloudWatch, Kinesis Data Firehose, Kinesis Data Streams and Amazon OpenSearch Service.
👉 CloudWatch Container Insight(CCI)
-
노드에 CW Agent 파드와 Fluent Bit 파드가 데몬셋으로 배치되어 Metrics 와 Logs 수집
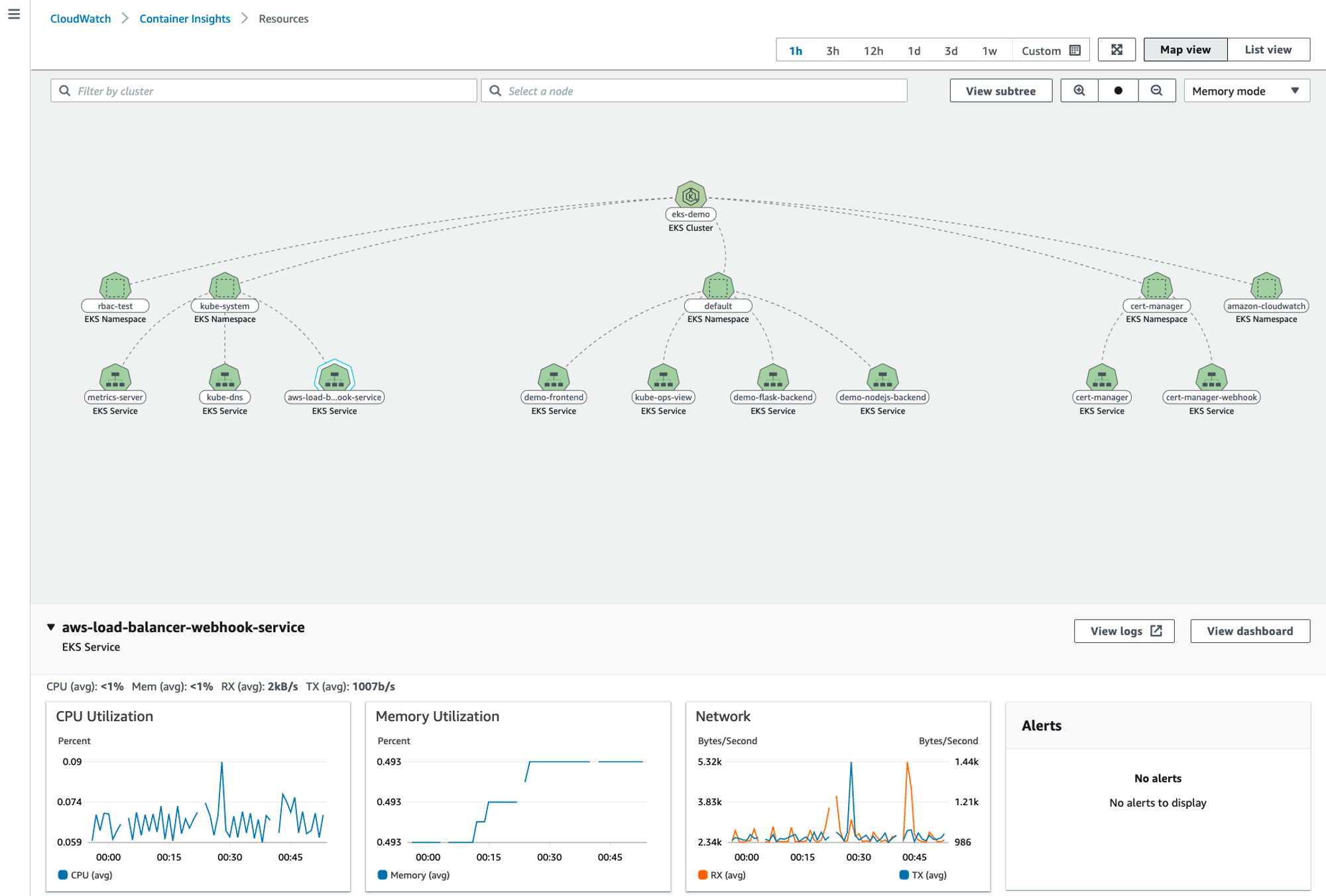
-
소개: collect, aggregate, and summarize metrics and logs from your containerized applications and microservices - 링크 Docs- CloudWatch Container Insight는 컨테이너형 애플리케이션 및 마이크로 서비스에 대한 모니터링, 트러블 슈팅 및 알람을 위한 완전 관리형 관측 서비스.
- CloudWatch 콘솔에서 자동화된 대시보드를 통해 container metrics, Prometeus metrics, application logs 및 performance log events를 탐색, 분석 및 시각화할 수 있음
- CloudWatch Container Insight는 CPU, 메모리, 디스크 및 네트워크와 같은 인프라 메트릭을 자동으로 수집
- EKS 클러스터의 crashloop backoffs와 같은 진단 정보를 제공하여 문제를 격리하고 신속하게 해결할 수 있도록 지원
- 이러한 대시보드는 Amazon ECS, Amazon EKS, AWS ECS Fargate 그리고 EC2 위에 구동되는 k8s 클러스터에서 사용 가능
노드 로그 확인
- 로그 위치 확인
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo tree /var/log/containers; echo; done
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo ls -al /var/log/containers; echo; done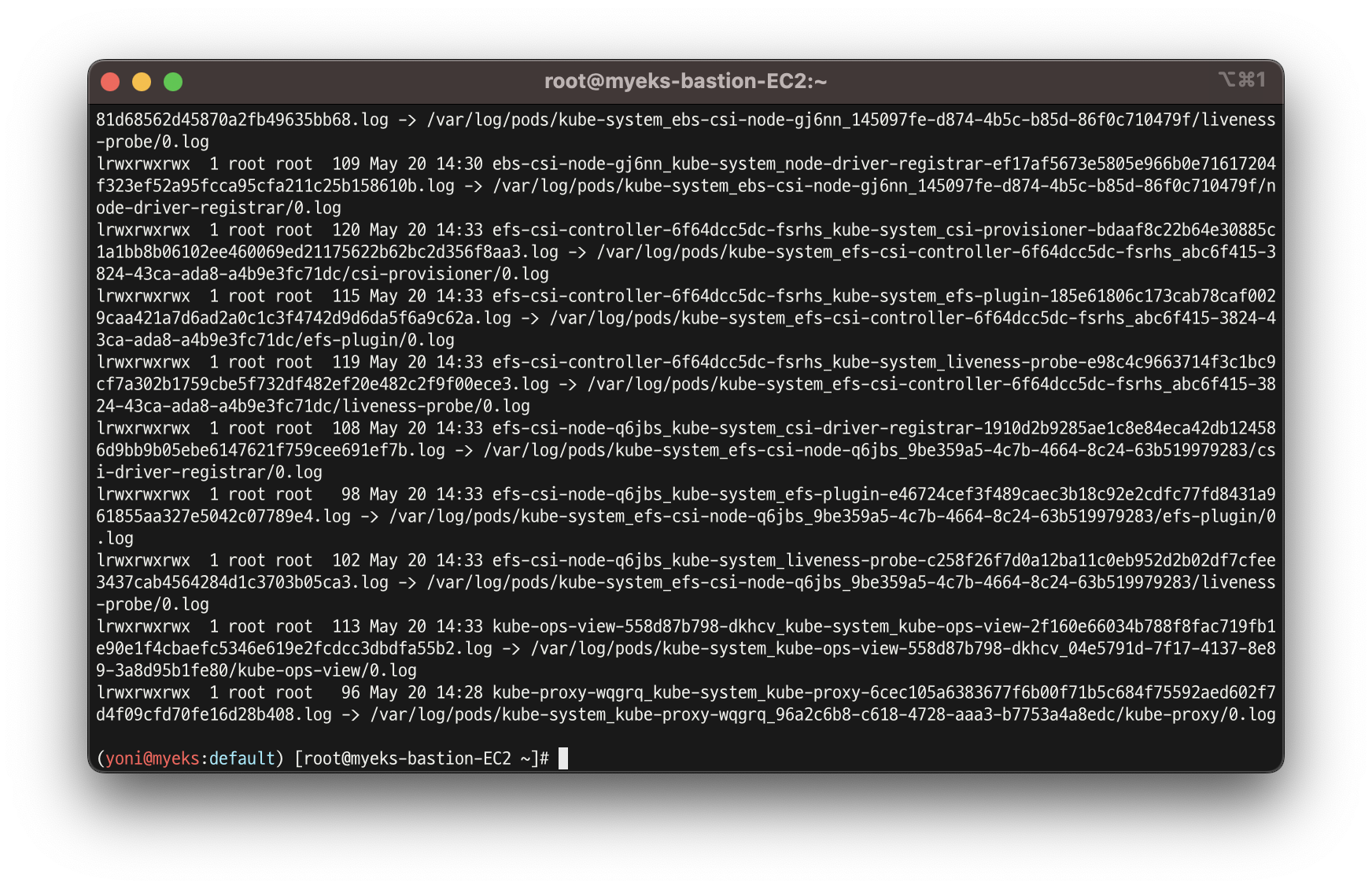
- 개별 파드 로그 확인
ssh ec2-user@$N2 sudo tail -f /var/log/pods/default_nginx-<컨테이너>/nginx/0.log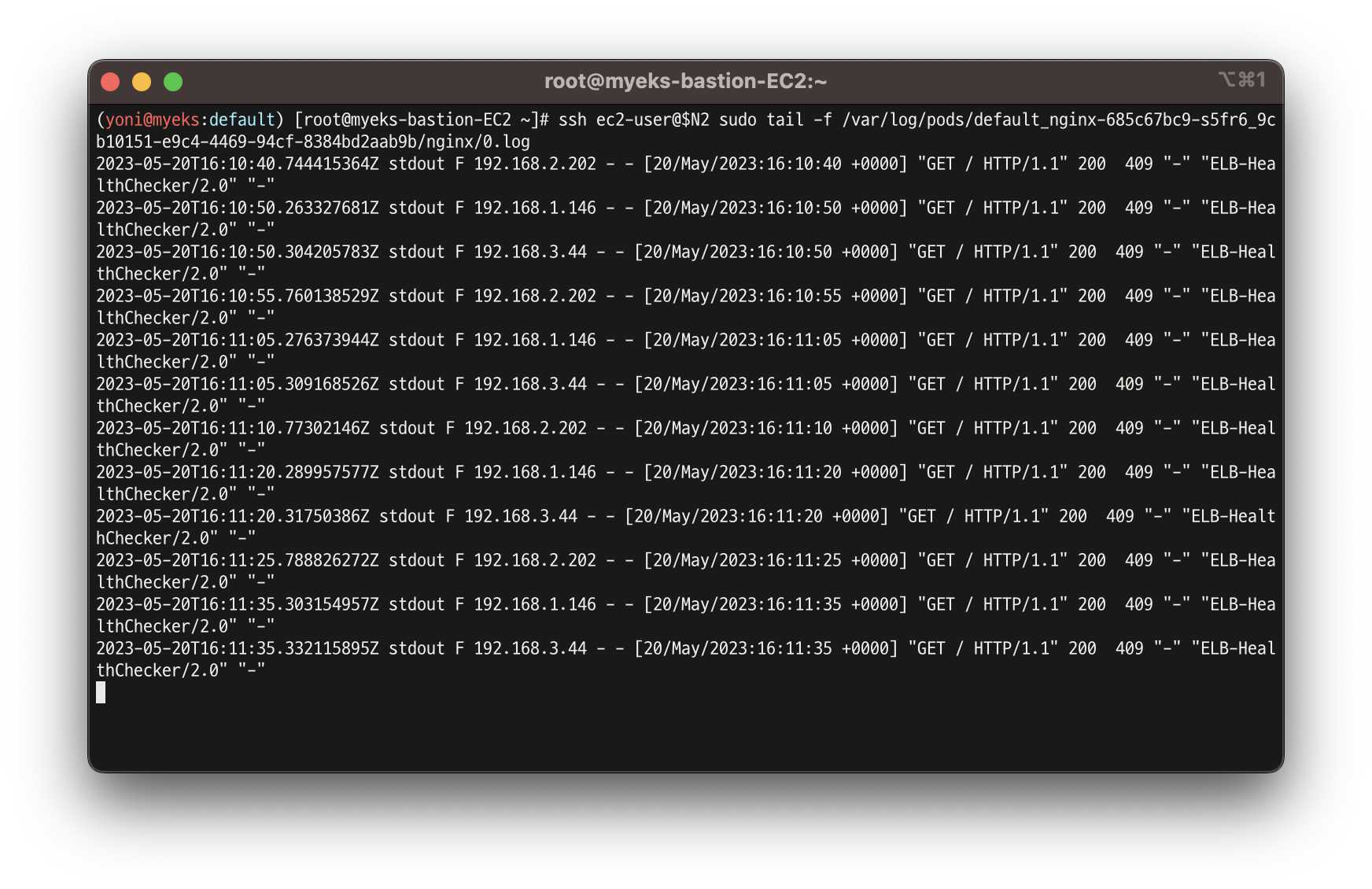
host 로그 소스
- 로그 위치 확인
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo tree /var/log/ -L 1; echo; done
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo ls -la /var/log/; echo; done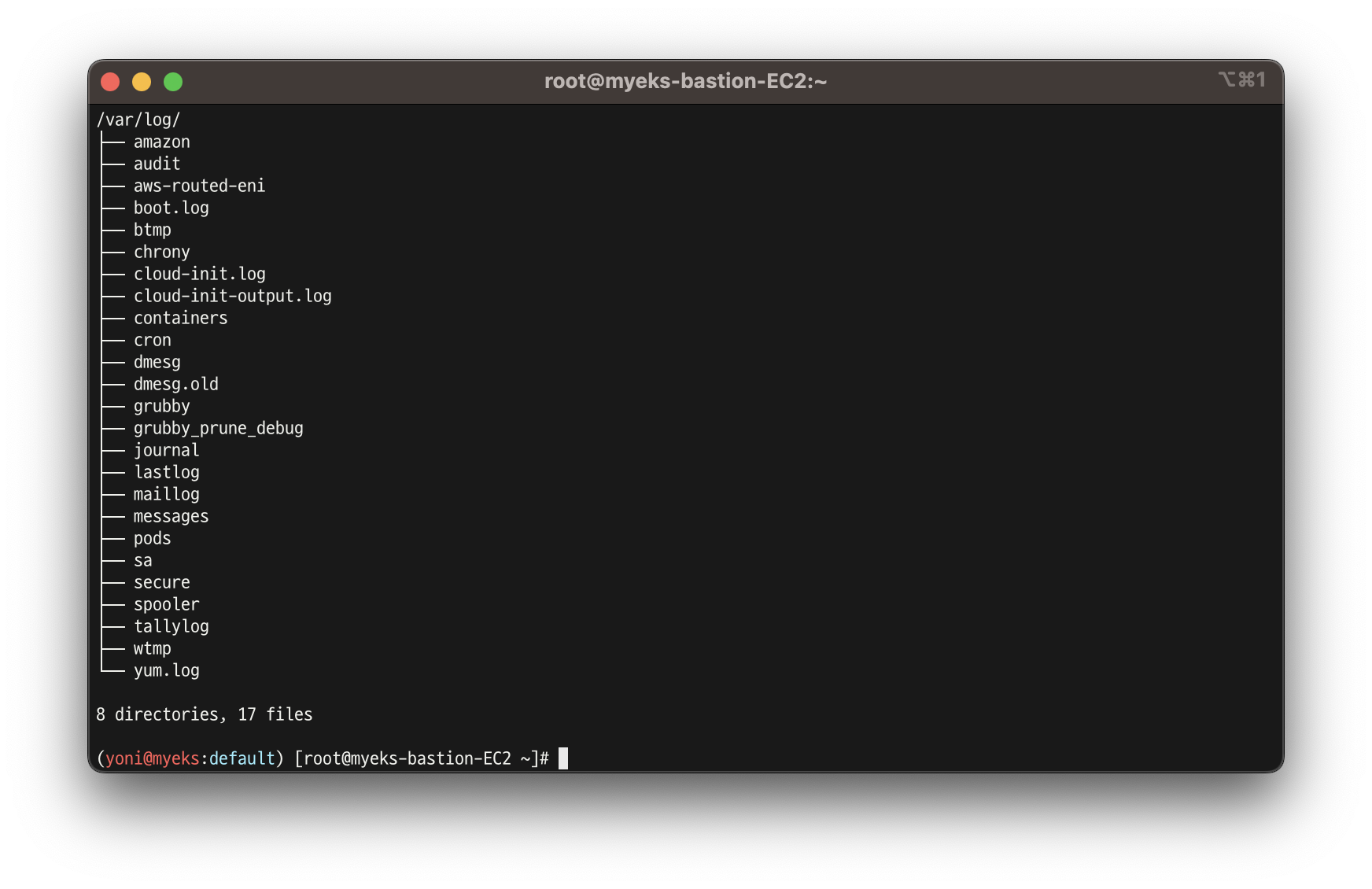
- 호스트 로그 확인
for log in dmesg secure messages; do echo ">>>>> Node1: /var/log/$log <<<<<"; ssh ec2-user@$N1 sudo tail /var/log/$log; echo; done
for log in dmesg secure messages; do echo ">>>>> Node2: /var/log/$log <<<<<"; ssh ec2-user@$N2 sudo tail /var/log/$log; echo; done
for log in dmesg secure messages; do echo ">>>>> Node3: /var/log/$log <<<<<"; ssh ec2-user@$N3 sudo tail /var/log/$log; echo; done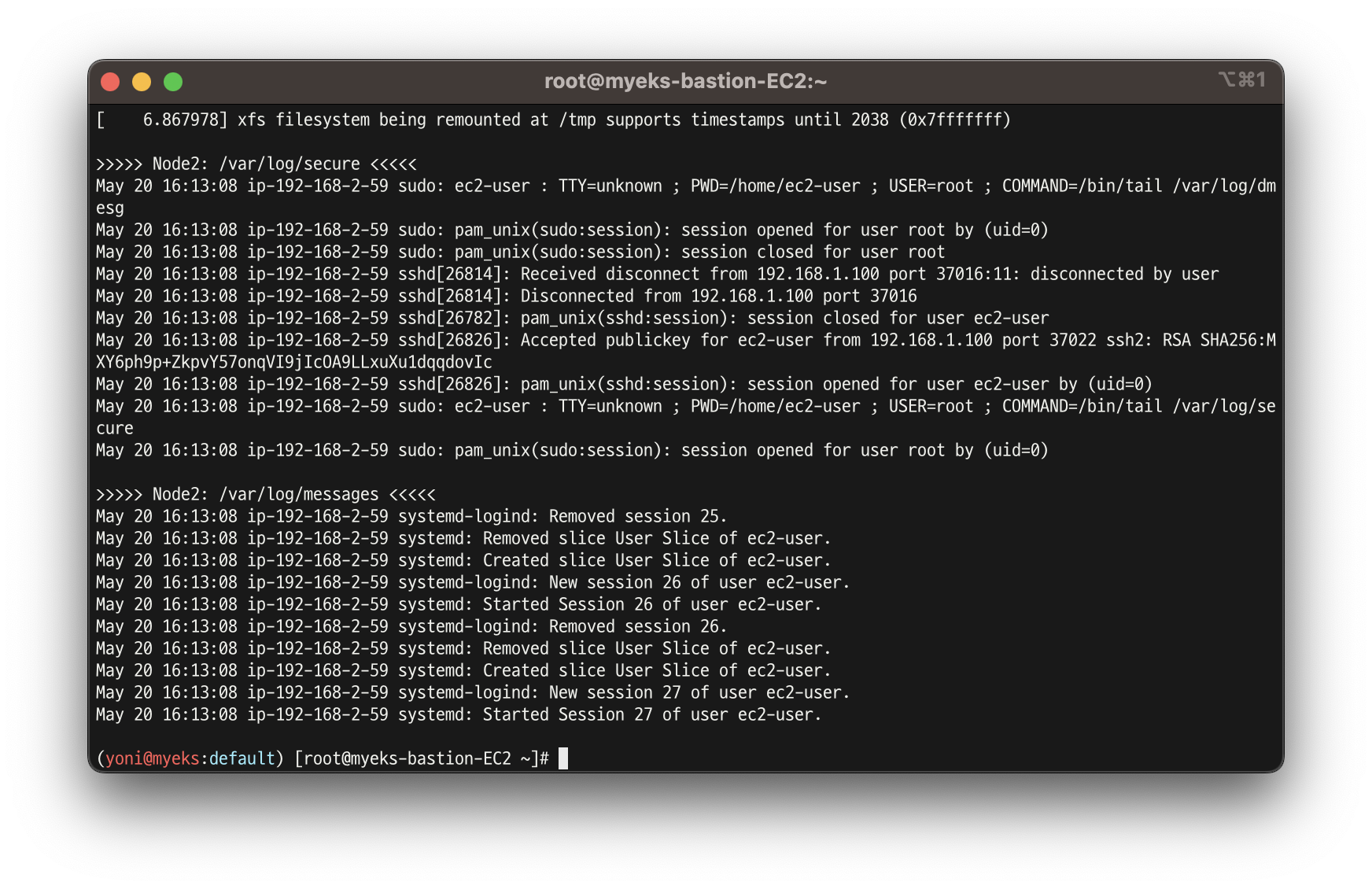
dataplane 로그 소스
-
(/var/log/journal for kubelet.service, kubeproxy.service, and docker.service), 쿠버네티스 데이터플레인 로그
-
로그 위치 확인
(/var/log/journal for kubelet.service, kubeproxy.service, and docker.service), 쿠버네티스 데이터플레인 로그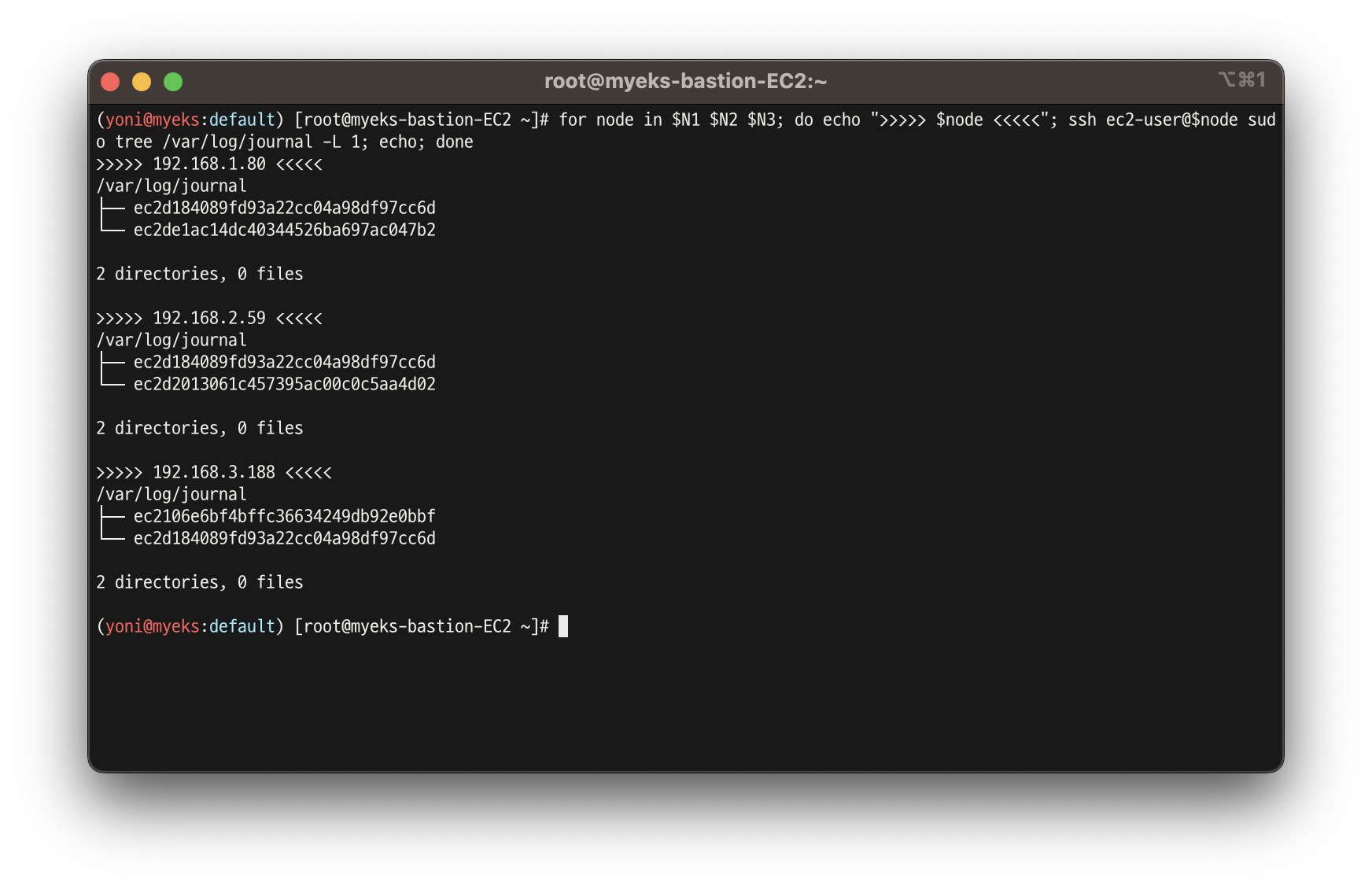
- 저널 로그 확인
(/var/log/journal for kubelet.service, kubeproxy.service, and docker.service), 쿠버네티스 데이터플레인 로그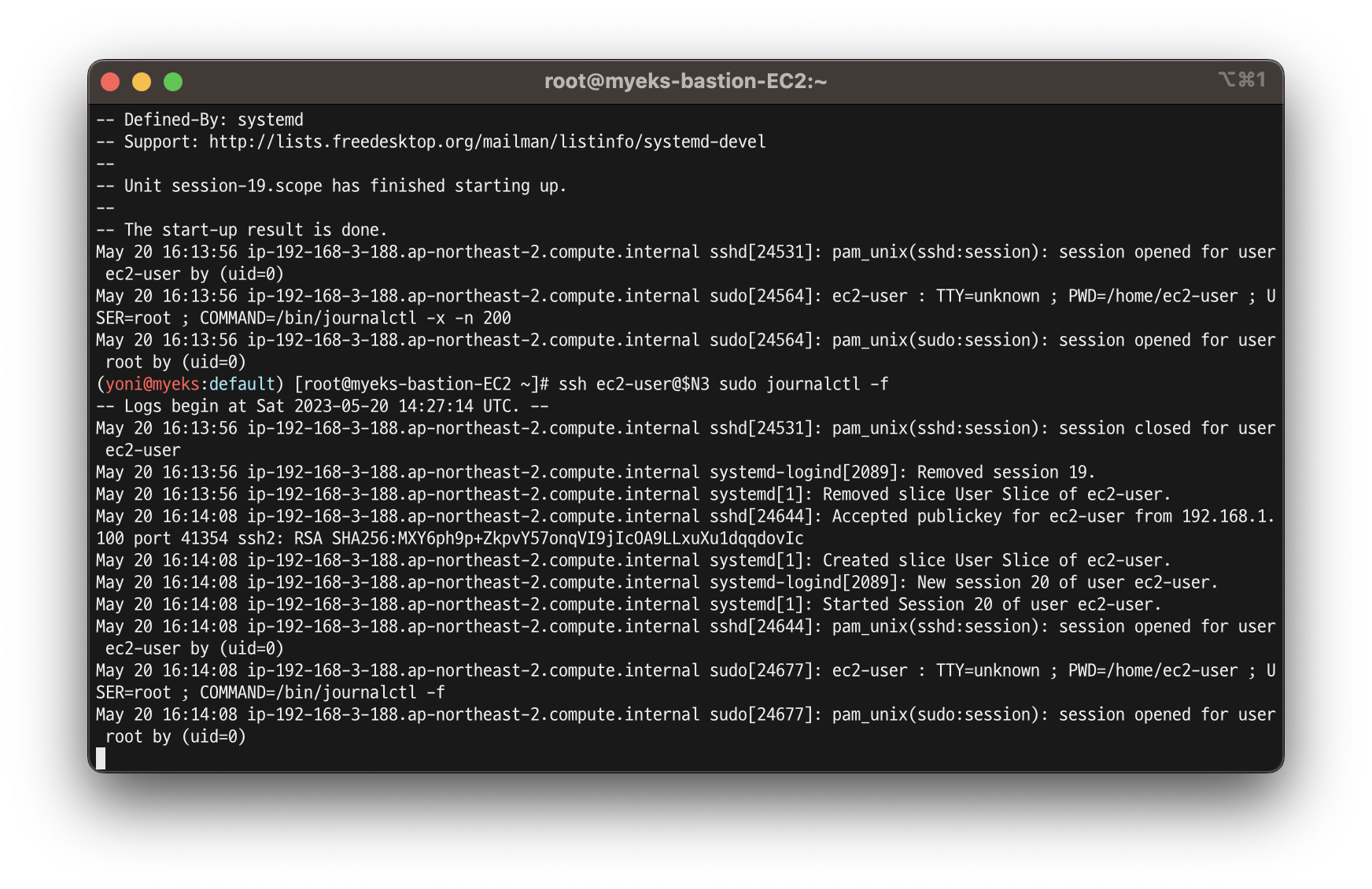
👉 CloudWatch Container Insight 설치 : cloudwatch-agent & fluent-bit & Setting up Fluent Bit
- 설치
FluentBitHttpServer='On'
FluentBitHttpPort='2020'
FluentBitReadFromHead='Off'
FluentBitReadFromTail='On'
curl -s https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/quickstart/cwagent-fluent-bit-quickstart.yaml | sed 's/{{cluster_name}}/'${CLUSTER_NAME}'/;s/{{region_name}}/'${AWS_DEFAULT_REGION}'/;s/{{http_server_toggle}}/"'${FluentBitHttpServer}'"/;s/{{http_server_port}}/"'${FluentBitHttpPort}'"/;s/{{read_from_head}}/"'${FluentBitReadFromHead}'"/;s/{{read_from_tail}}/"'${FluentBitReadFromTail}'"/' | kubectl apply -f -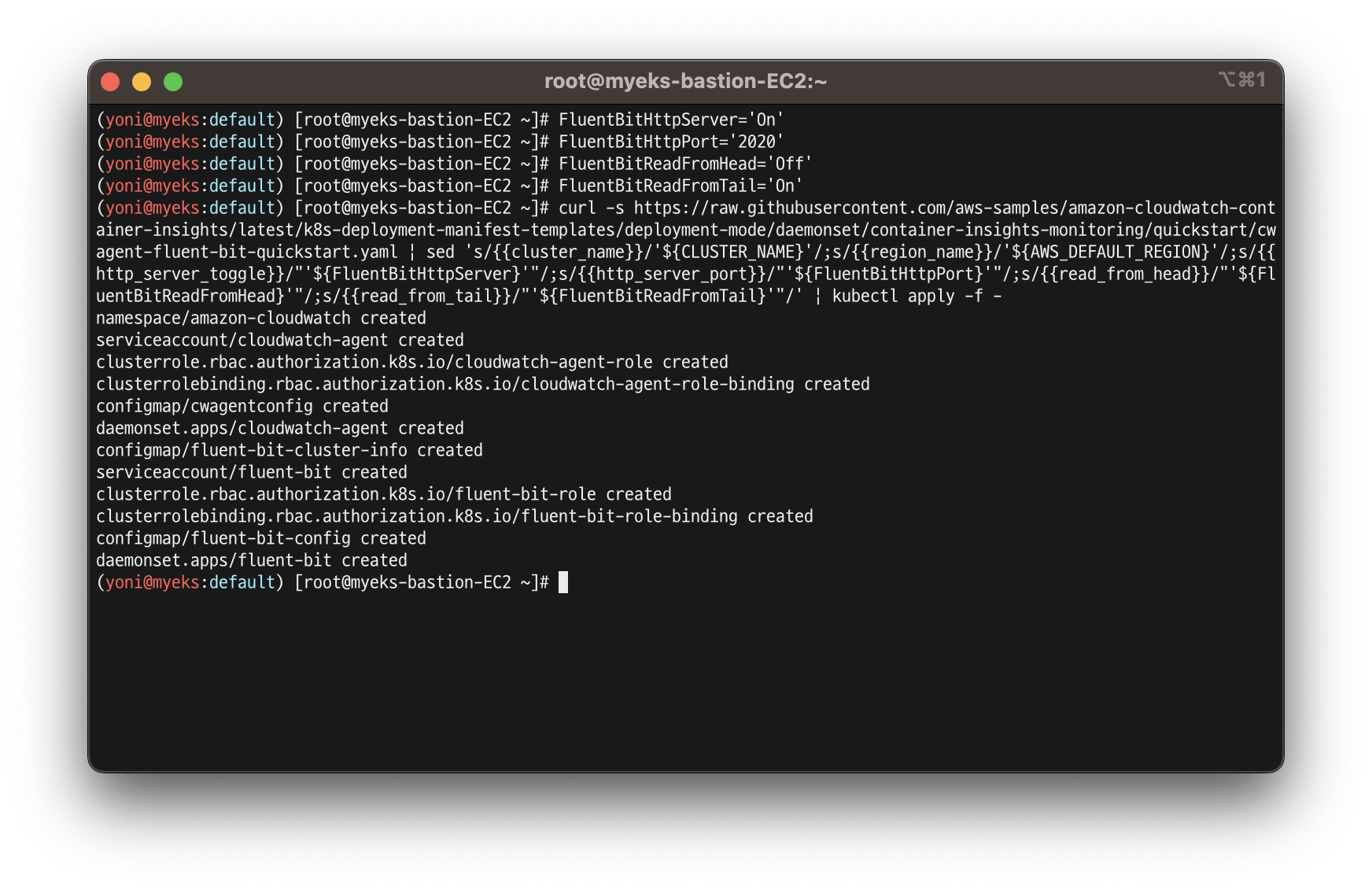
- 설치 확인 및 파드 로그 확인
# 설치 확인
kubectl get-all -n amazon-cloudwatch
kubectl get ds,pod,cm,sa -n amazon-cloudwatch
kubectl describe clusterrole cloudwatch-agent-role fluent-bit-role # 클러스터롤 확인
kubectl describe clusterrolebindings cloudwatch-agent-role-binding fluent-bit-role-binding # 클러스터롤 바인딩 확인
kubectl -n amazon-cloudwatch logs -l name=cloudwatch-agent -f # 파드 로그 확인
kubectl -n amazon-cloudwatch logs -l k8s-app=fluent-bit -f
# 파드 로그 확인
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo ss -tnlp | grep fluent-bit; echo; done
- cloudwatch-agent 설정 확인
kubectl describe cm cwagentconfig -n amazon-cloudwatch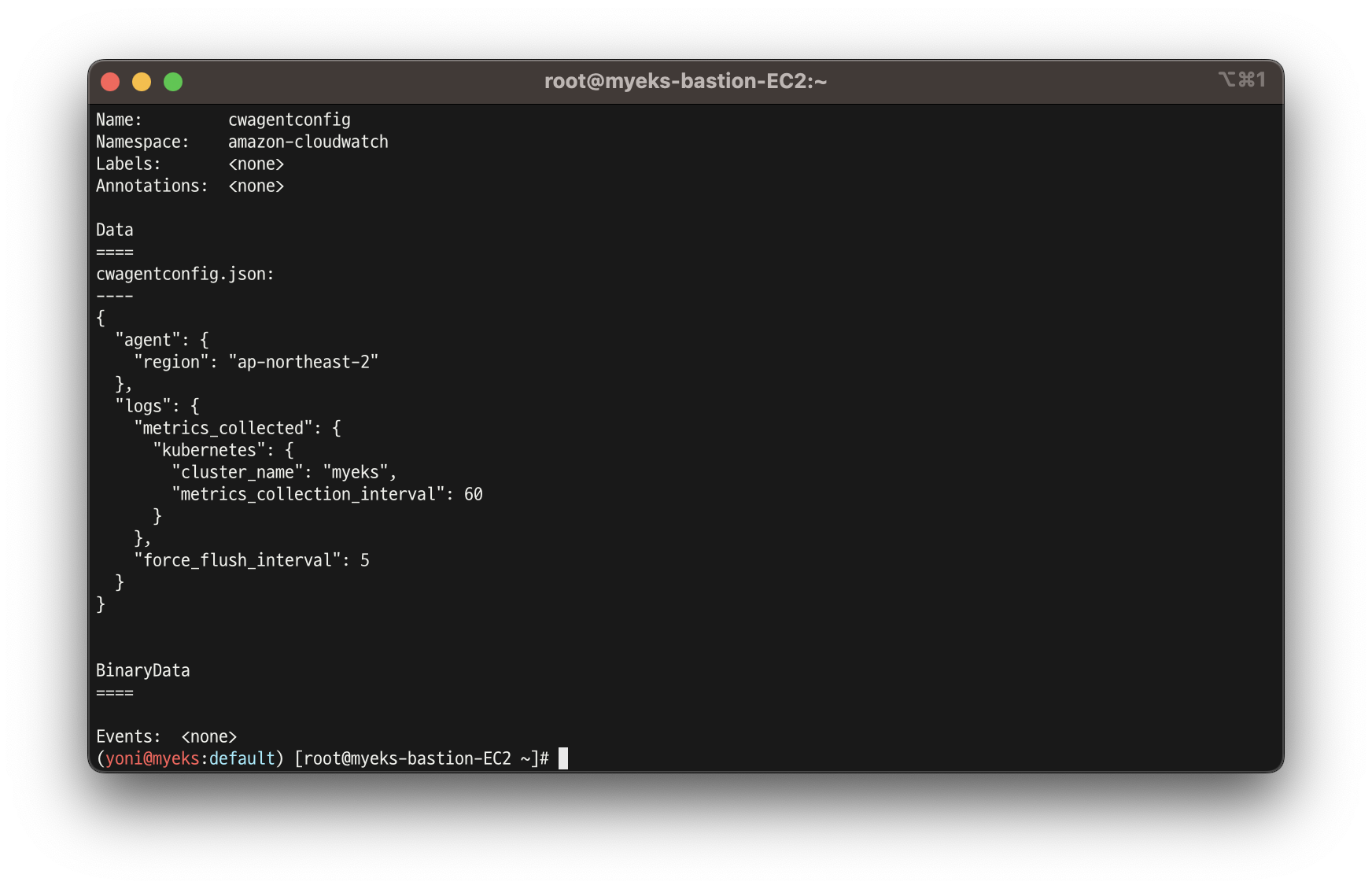
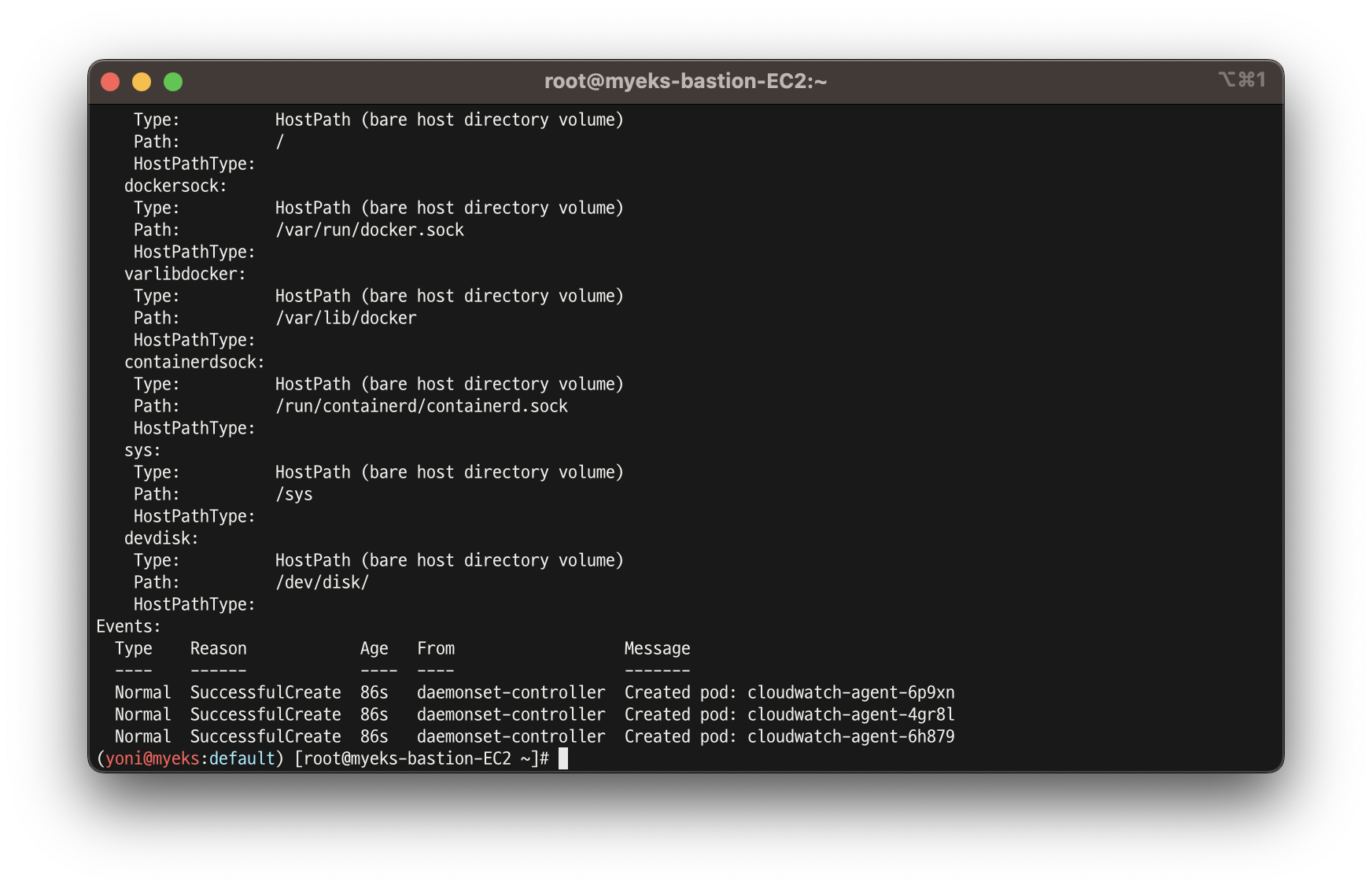
- CW 파드가 수집하는 방법 : Volumes에 HostPath를 살펴보자! >> / 호스트 패스 공유??? 보안상 안전한가? 좀 더 범위를 좁힐수는 없을까요? ✅ 고민해보기
kubectl describe -n amazon-cloudwatch ds cloudwatch-agent
...
ssh ec2-user@$N1 sudo tree /dev/disk
...
-
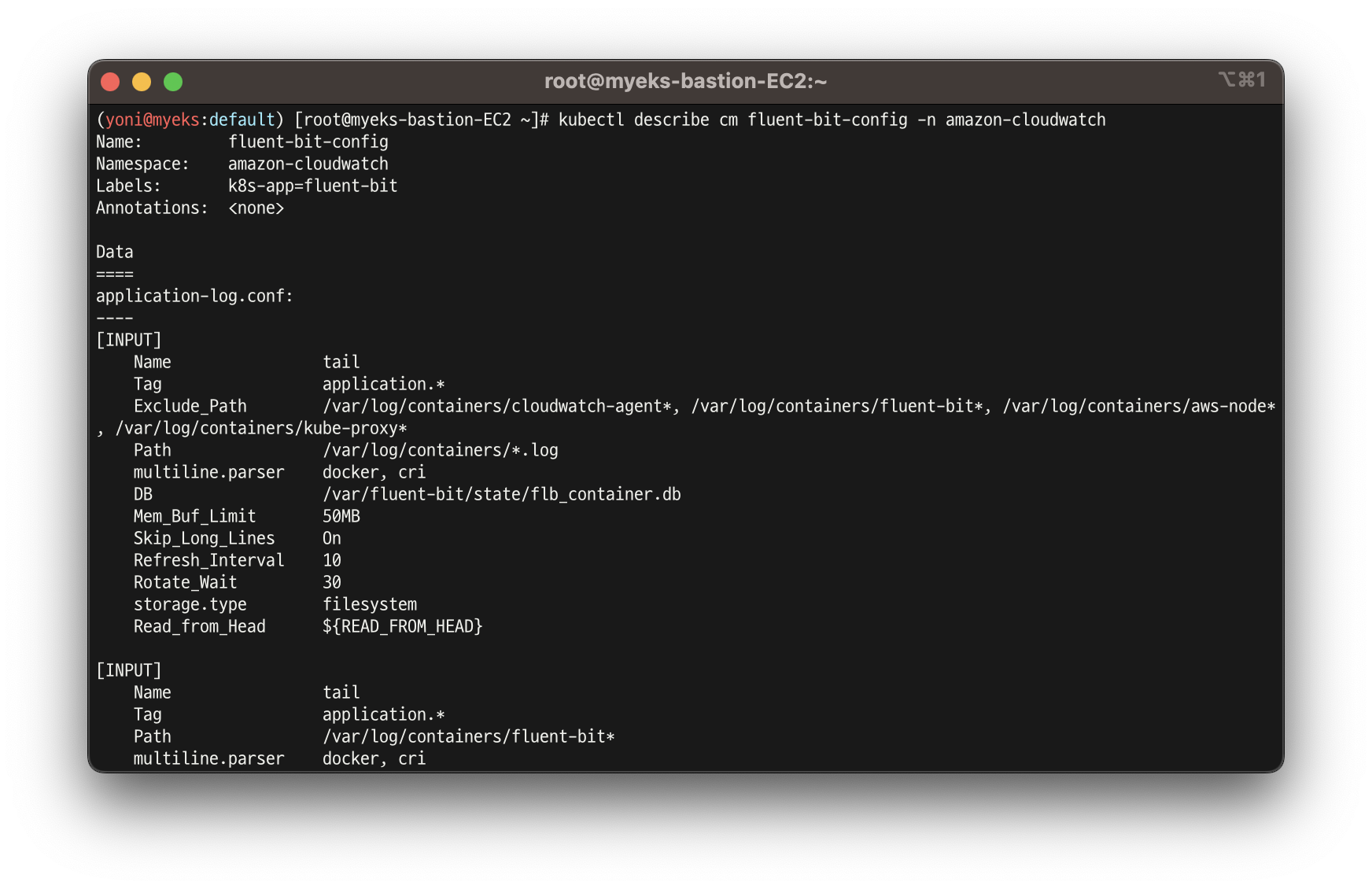
Fluent Bit Cluster Info 확인
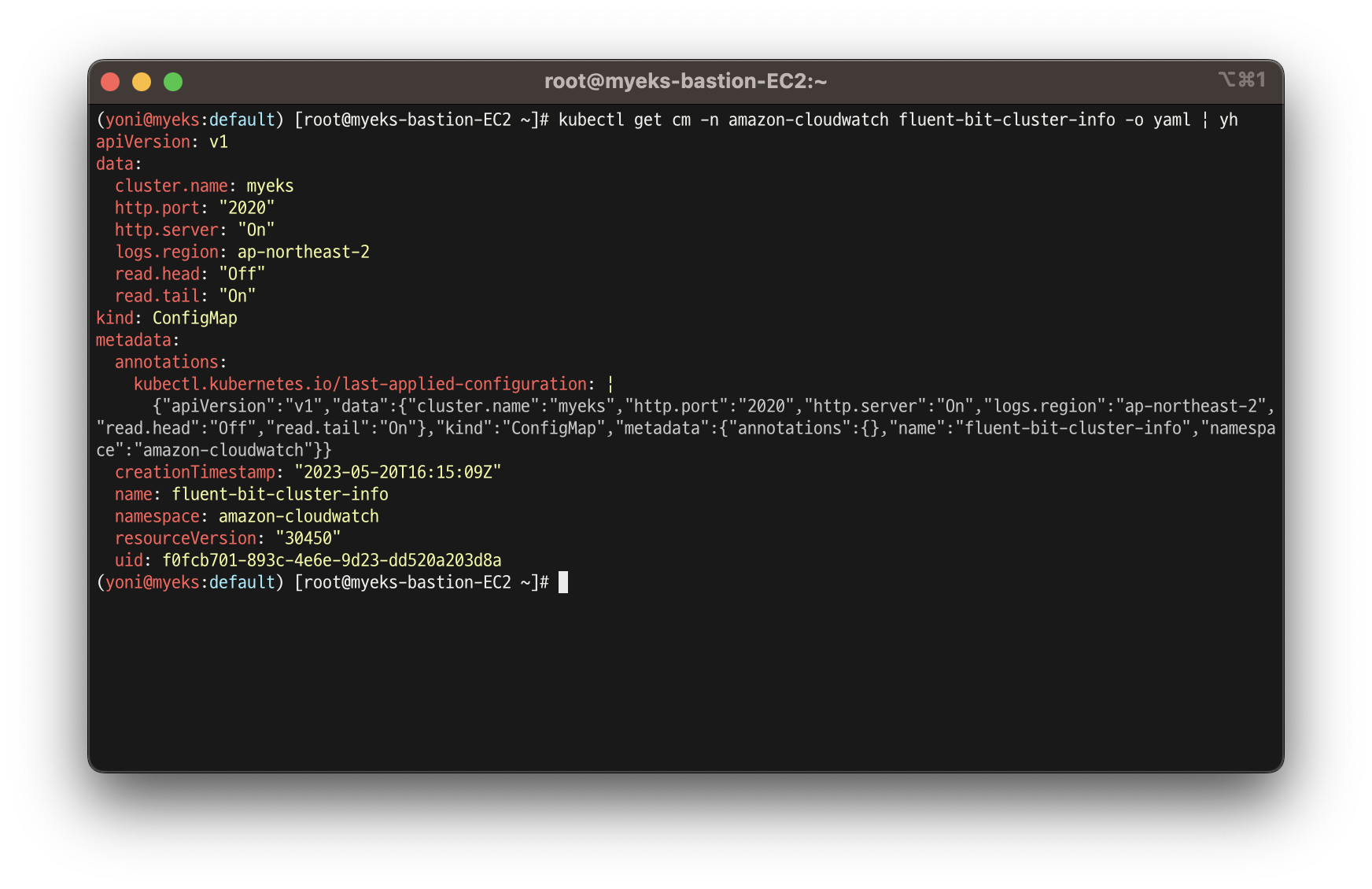
-
Fluent Bit 로그 INPUT/FILTER/OUTPUT 설정 확인
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/Container-Insights-setup-logs-FluentBit.html#ContainerInsights-fluentbit-multiline
설정 부분 구성 : application-log.conf , dataplane-log.conf , fluent-bit.conf , host-log.conf , parsers.conf
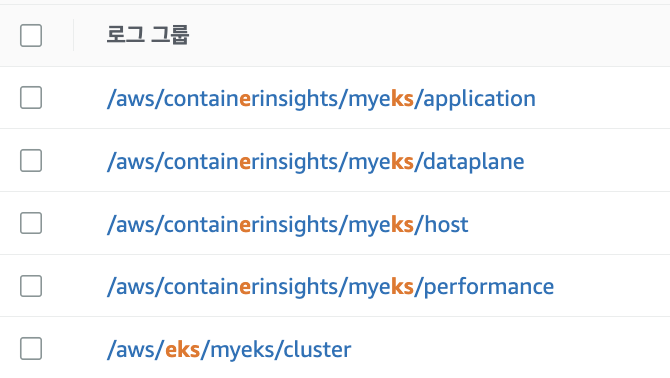
-
로깅 확인 : CloudWatch -> 로그 그룹
-
메트릭 확인 : CloudWatch -> 인사이트 -> Container Insights
👉 로그 확인 : nginx 웹서버
- 부하 발생 및 파드 직접 로그 모니터링
# 부하 발생
curl -s https://nginx.$MyDomain
yum install -y httpd
ab -c 500 -n 30000 https://nginx.$MyDomain/
# 모니터링
kubectl logs deploy/nginx -f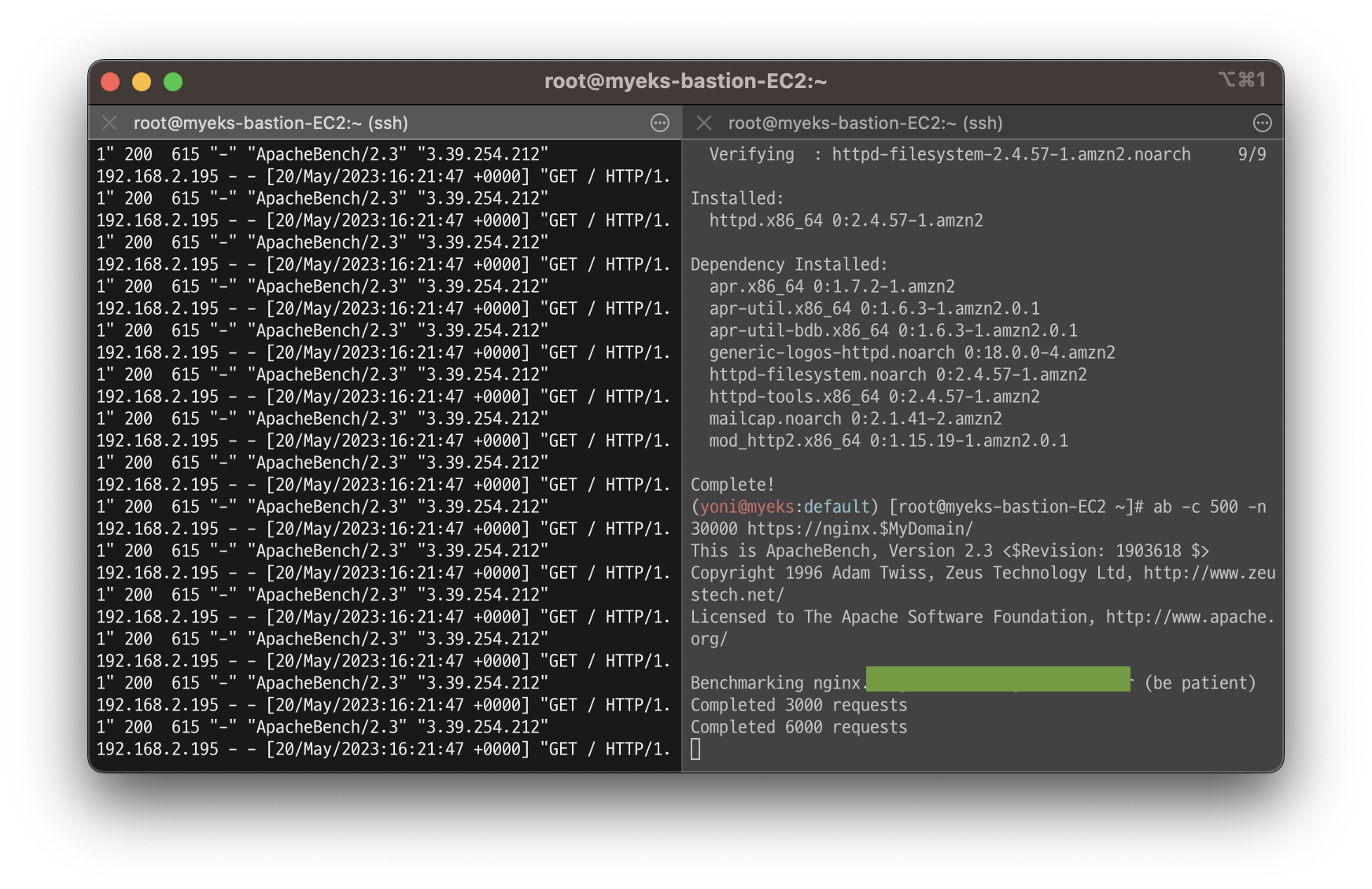
-
CloudWatch 로그 그룹에서도 확인 가능 : 로그 그룹 → application → 로그 스트림 : nginx 필터링 ⇒ 클릭 후 확인 ⇒ ApacheBench 필터링 확인
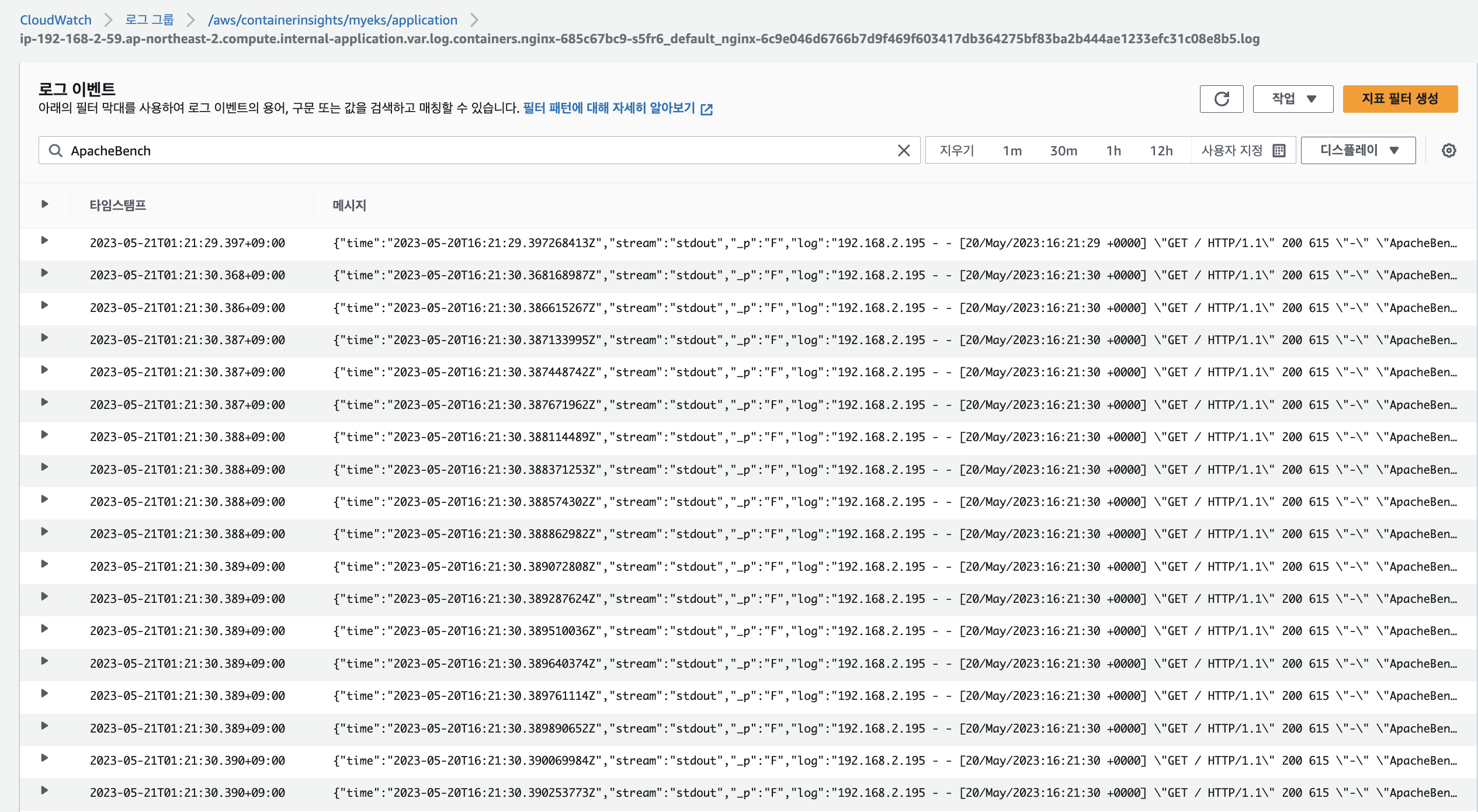
-
로그 인사이트에서도 확인
# Application log errors by container name : 컨테이너 이름별 애플리케이션 로그 오류
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/application
stats count() as error_count by kubernetes.container_name
| filter stream="stderr"
| sort error_count desc
# All Kubelet errors/warning logs for for a given EKS worker node
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/dataplane
fields @timestamp, @message, ec2_instance_id
| filter message =~ /.*(E|W)[0-9]{4}.*/ and ec2_instance_id="<YOUR INSTANCE ID>"
| sort @timestamp desc
# Kubelet errors/warning count per EKS worker node in the cluster
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/dataplane
fields @timestamp, @message, ec2_instance_id
| filter message =~ /.*(E|W)[0-9]{4}.*/
| stats count(*) as error_count by ec2_instance_id
# performance 로그 그룹
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/performance
# 노드별 평균 CPU 사용률
STATS avg(node_cpu_utilization) as avg_node_cpu_utilization by NodeName
| SORT avg_node_cpu_utilization DESC
# 파드별 재시작(restart) 카운트
STATS avg(number_of_container_restarts) as avg_number_of_container_restarts by PodName
| SORT avg_number_of_container_restarts DESC
# 요청된 Pod와 실행 중인 Pod 간 비교
fields @timestamp, @message
| sort @timestamp desc
| filter Type="Pod"
| stats min(pod_number_of_containers) as requested, min(pod_number_of_running_containers) as running, ceil(avg(pod_number_of_containers-pod_number_of_running_containers)) as pods_missing by kubernetes.pod_name
| sort pods_missing desc
# 클러스터 노드 실패 횟수
stats avg(cluster_failed_node_count) as CountOfNodeFailures
| filter Type="Cluster"
| sort @timestamp desc
# 파드별 CPU 사용량
stats pct(container_cpu_usage_total, 50) as CPUPercMedian by kubernetes.container_name
| filter Type="Container"
| sort CPUPercMedian desc-
에러 발생 횟수 확인
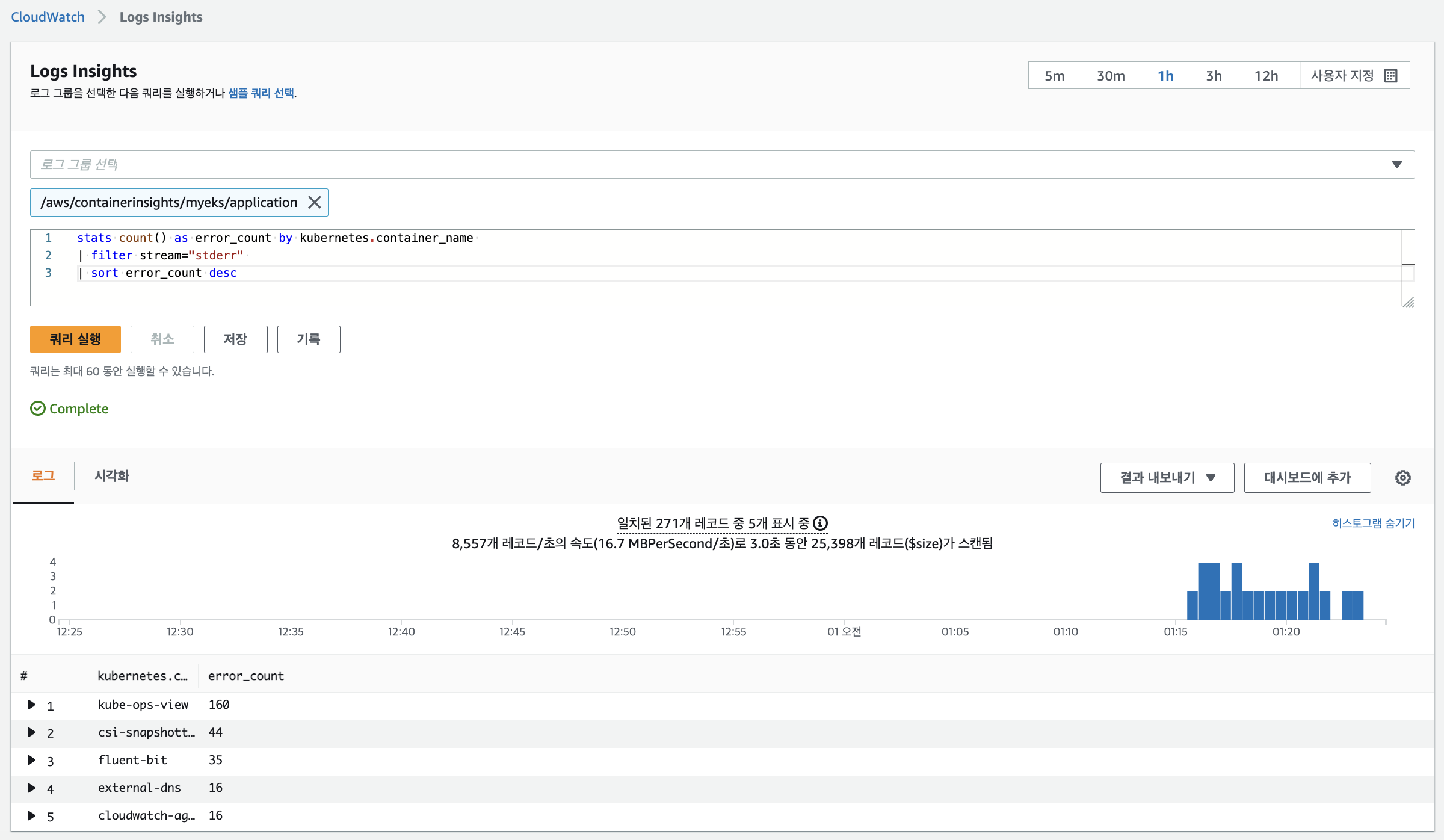
-
노드별 평균 CPU 사용률 확인
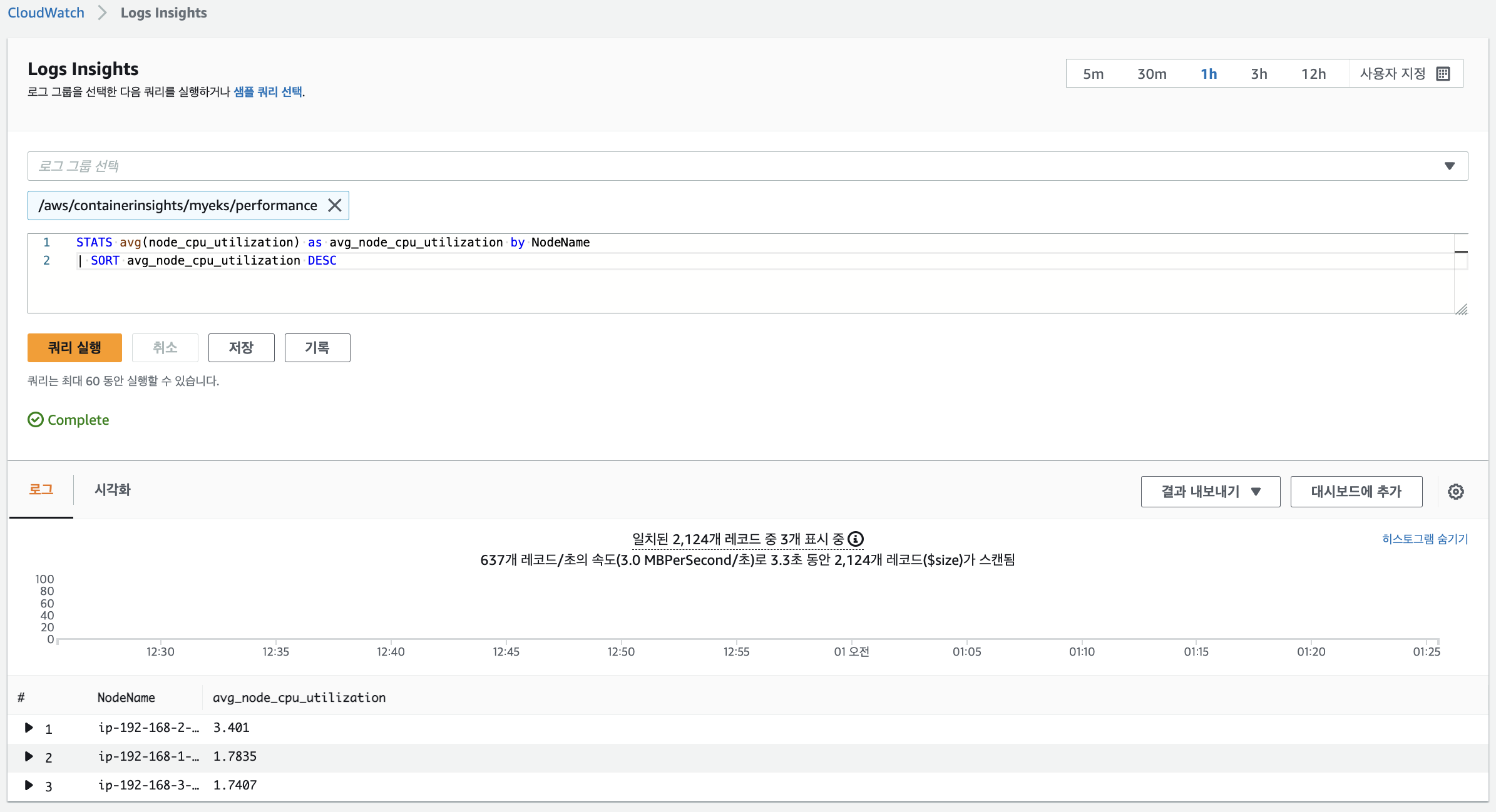
👉 메트릭 확인
-
CloudWatch → Insights → Container Insights : 우측 상단(Local Time Zone, 30분) ⇒ 리소스 : myeks 선택
-
Container map
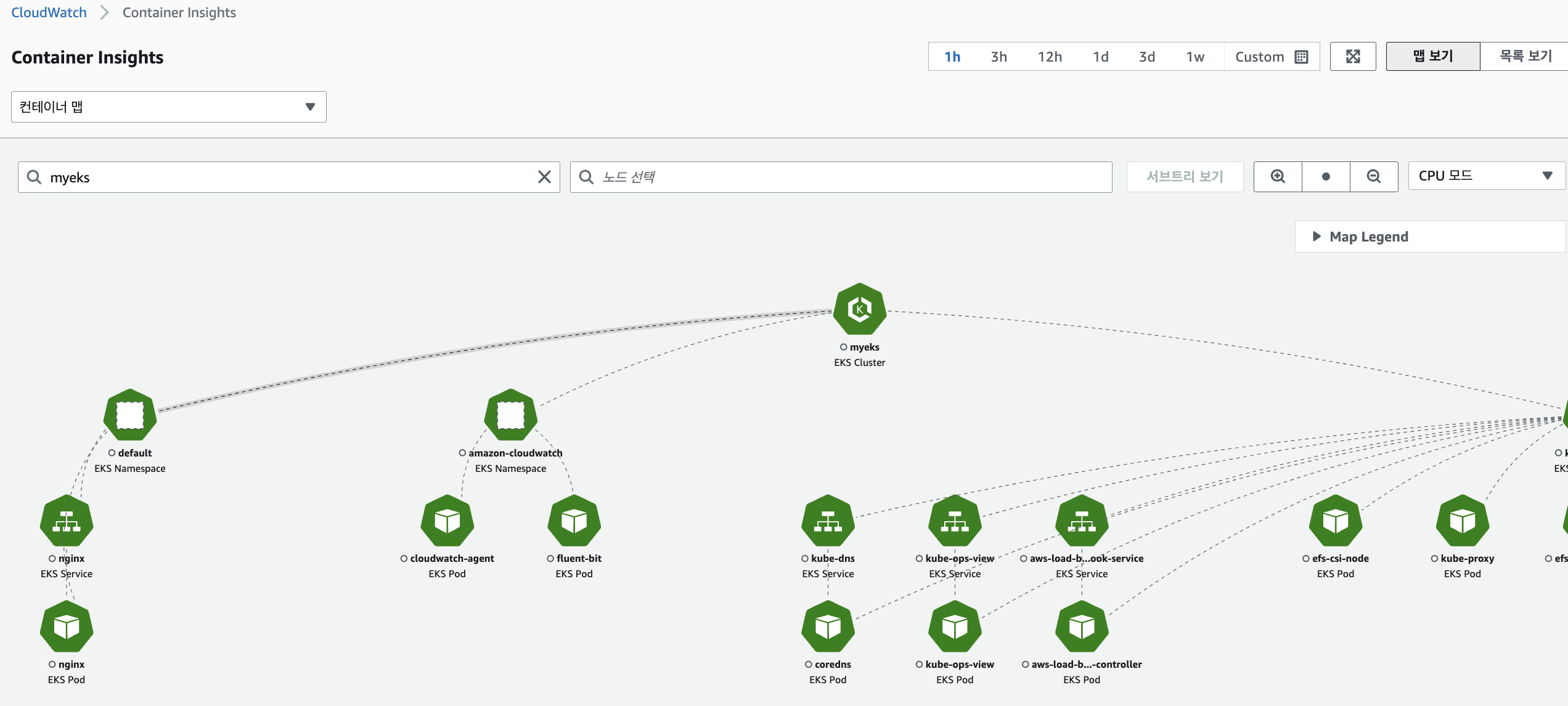
-
성능 모니터링
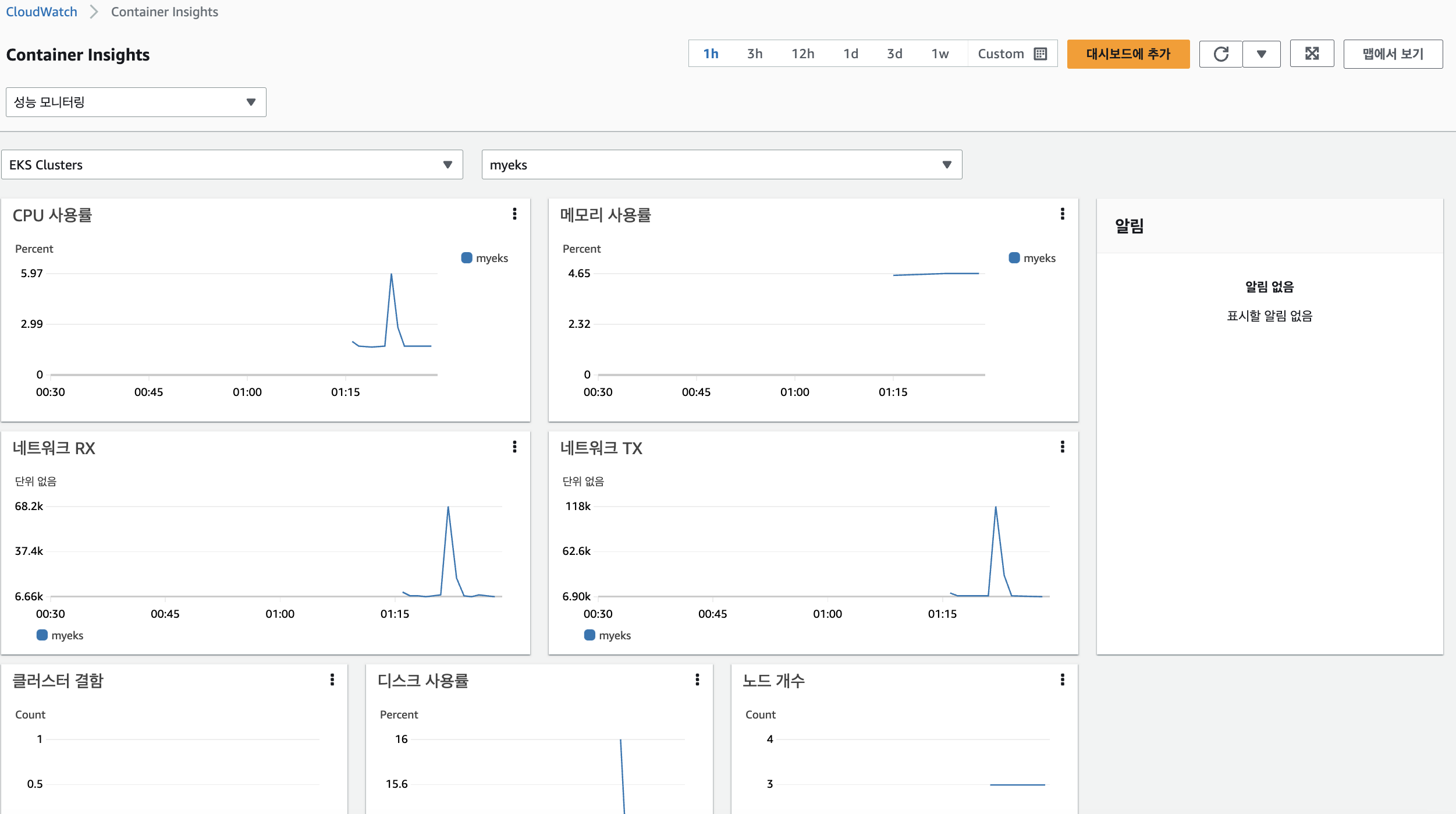
5. Metrics-server & kwatch & botkube
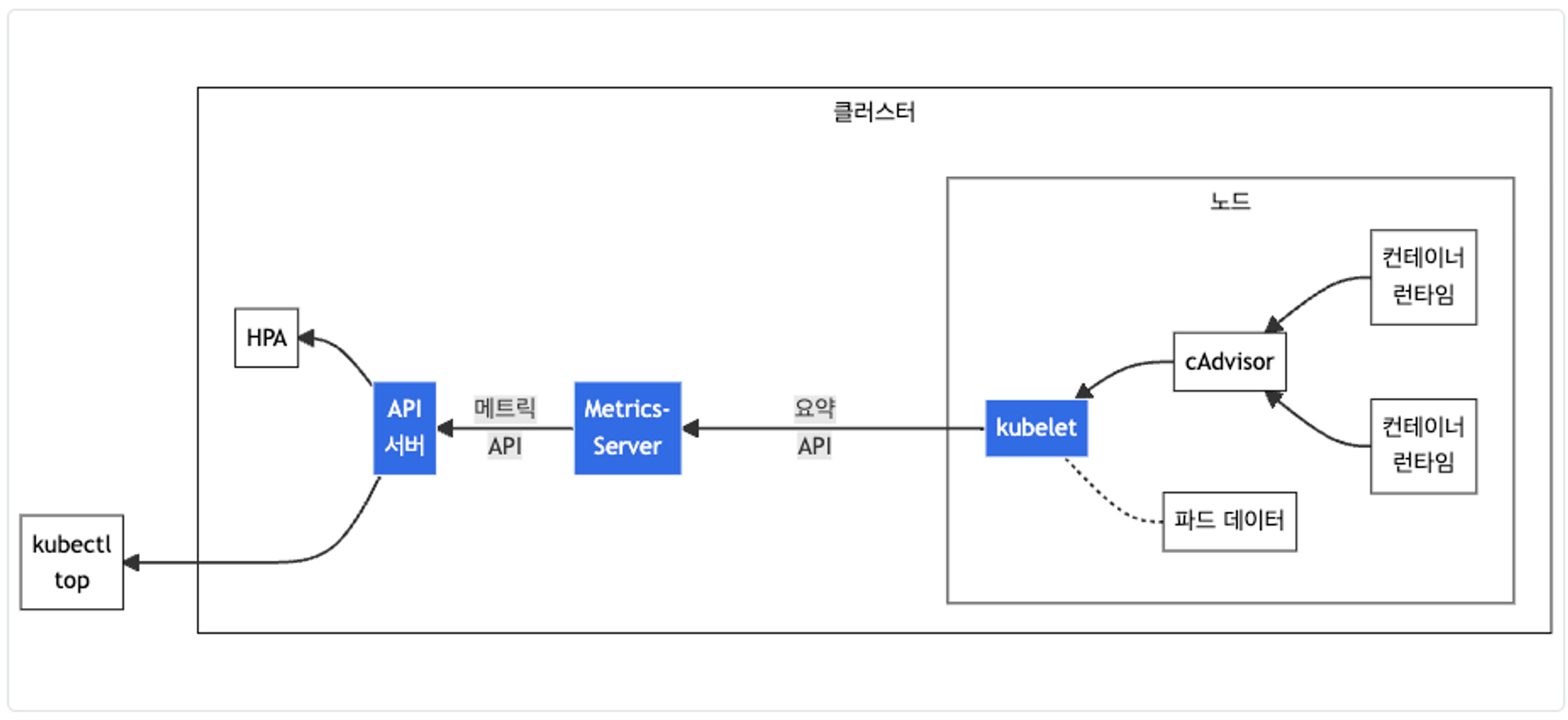
👉 Metrics-server
- kubelet으로부터 수집한 리소스 메트릭을 수집 및 집계하는 클러스터 애드온 구성 요소
참고 링크
-
cAdvisor : kubelet에 포함된 컨테이너 메트릭을 수집, 집계, 노출하는 데몬
-
배포
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml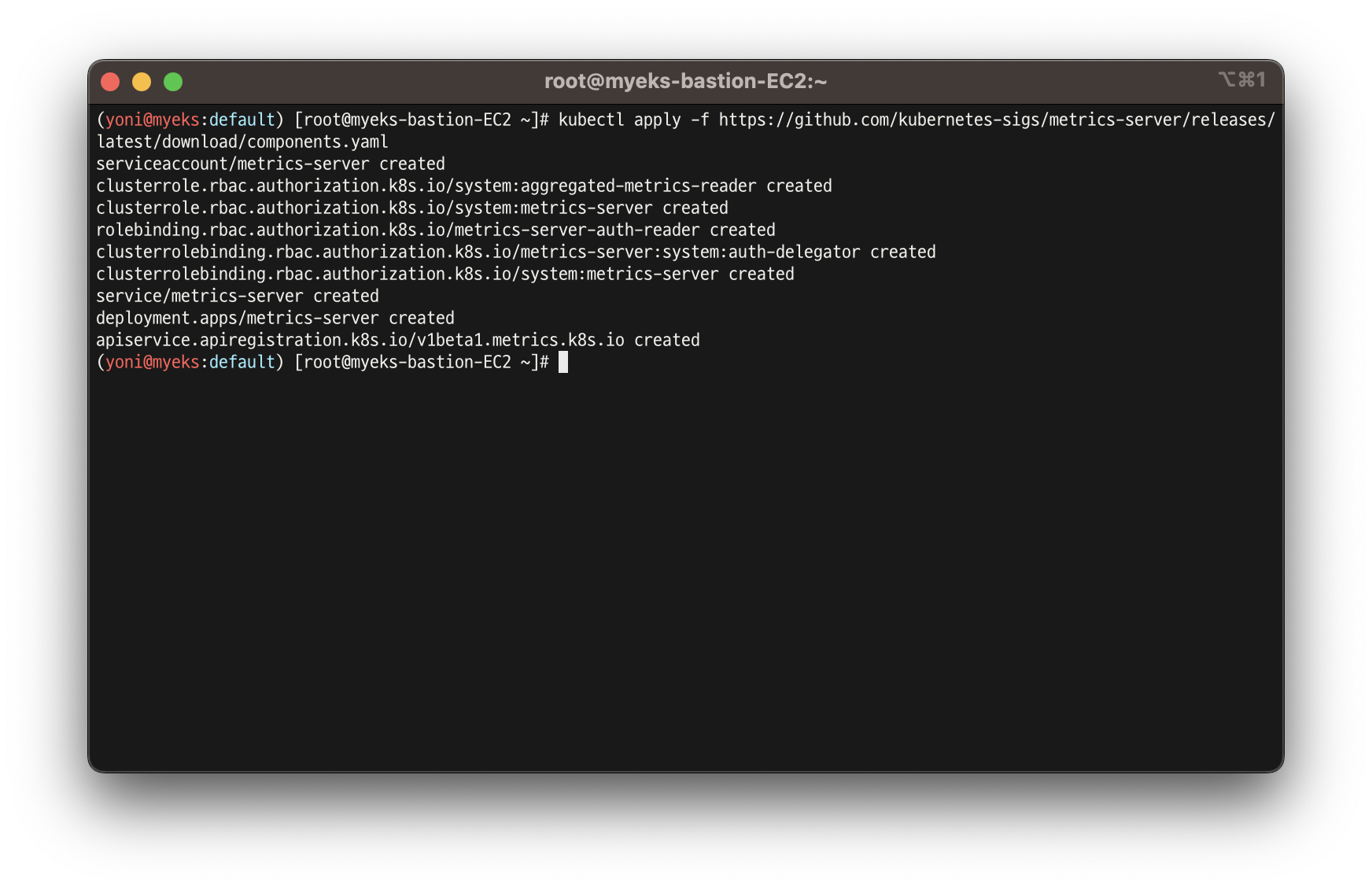
- 메트릭 서버 확인 및 노드 메트릭 확인
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
kubectl get pod -n kube-system -l k8s-app=metrics-server
kubectl api-resources | grep metrics
kubectl get apiservices |egrep '(AVAILABLE|metrics)'
# 노드 메트릭 확인
kubectl top node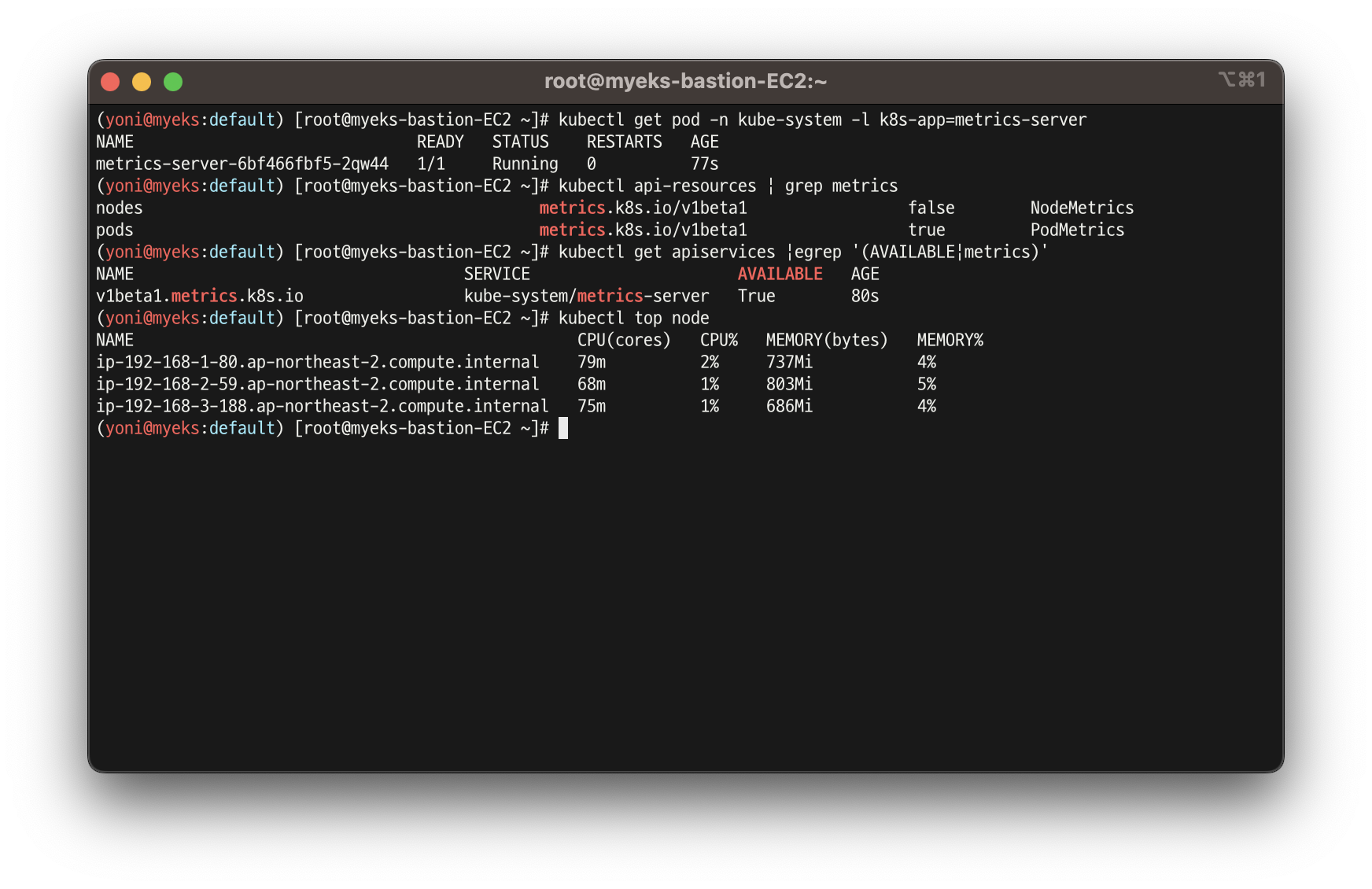
- 파드 메트릭 확인
kubectl top pod -A
kubectl top pod -n kube-system --sort-by='cpu'
kubectl top pod -n kube-system --sort-by='memory'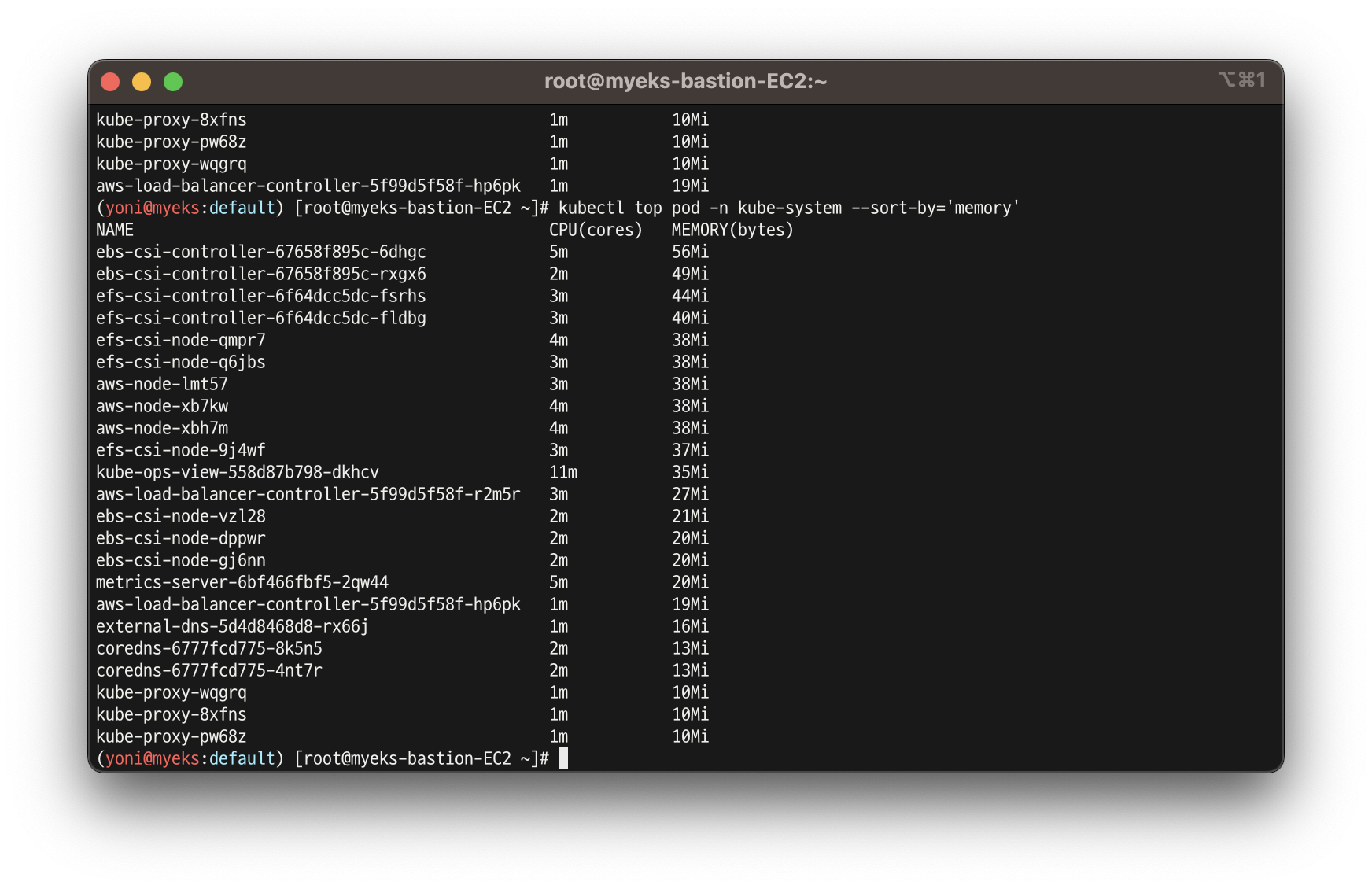
👉 Kwatch
- kwatch helps you monitor all changes in your Kubernetes(K8s) cluster, detects crashes in your running apps in realtime, and publishes notifications to your channels (Slack, Discord, etc.) instantly
- Kwatch를 이용하여 지표의 상태나 알람을 Slack으로 쉽게 전달 가능
참고 링크
- configmap 생성
- ❗️ 토큰은 민감정보 이므로 실습 화면 생략
cat <<EOT > ~/kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'https://hooks.slack.com/services/<webhook 주소>'
title: $NICK-EKS
#text:
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOT
kubectl apply -f kwatch-config.yaml
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.3/deploy/deploy.yaml- 잘못된 이미지 파드 배포 및 확인
# 터미널1
watch kubectl get pod
# 잘못된 이미지 정보의 파드 배포
kubectl apply -f https://raw.githubusercontent.com/junghoon2/kube-books/main/ch05/nginx-error-pod.yml
kubectl get events -w
# 이미지 업데이트 방안2 : set 사용 - iamge 등 일부 리소스 값을 변경 가능!
kubectl set
kubectl set image pod nginx-19 nginx-pod=nginx:1.19
# 삭제
kubectl delete pod nginx-19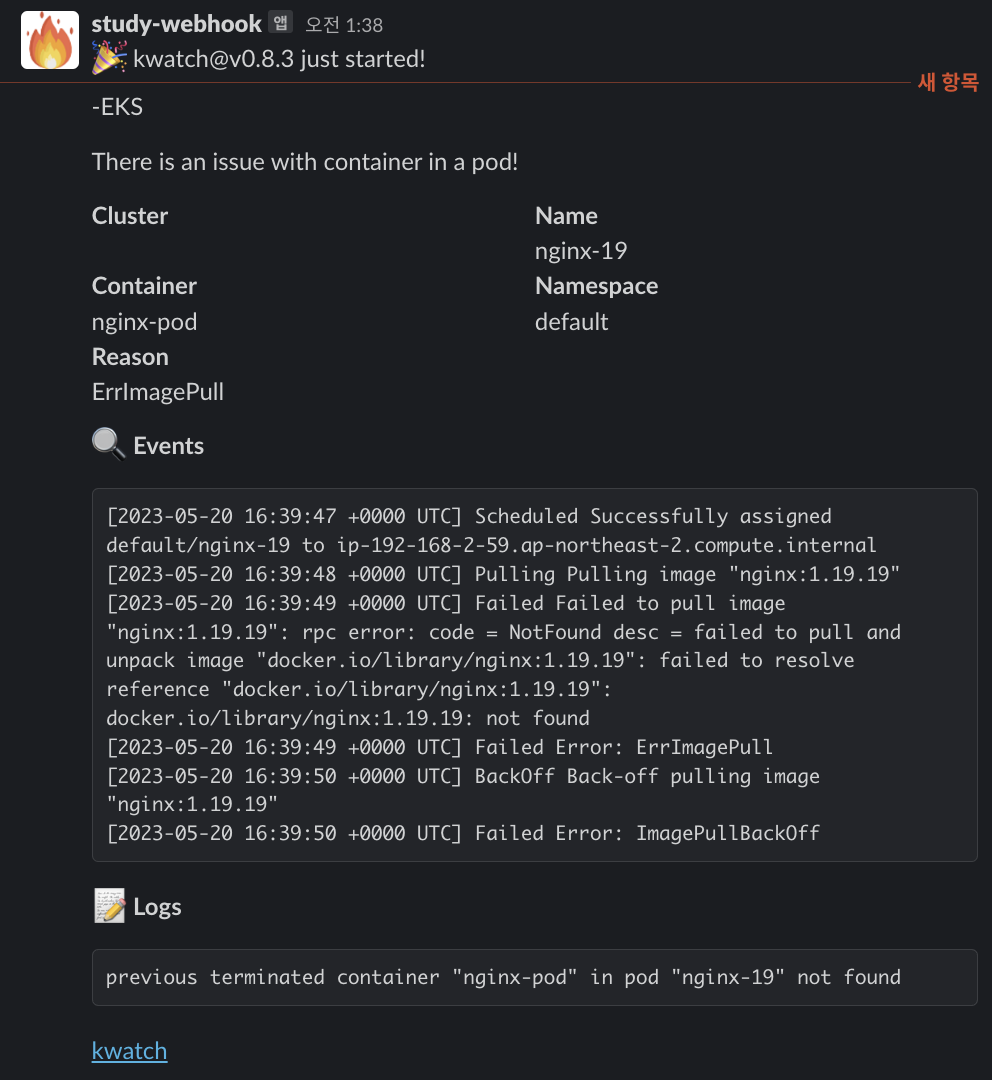
- kwatch 삭제
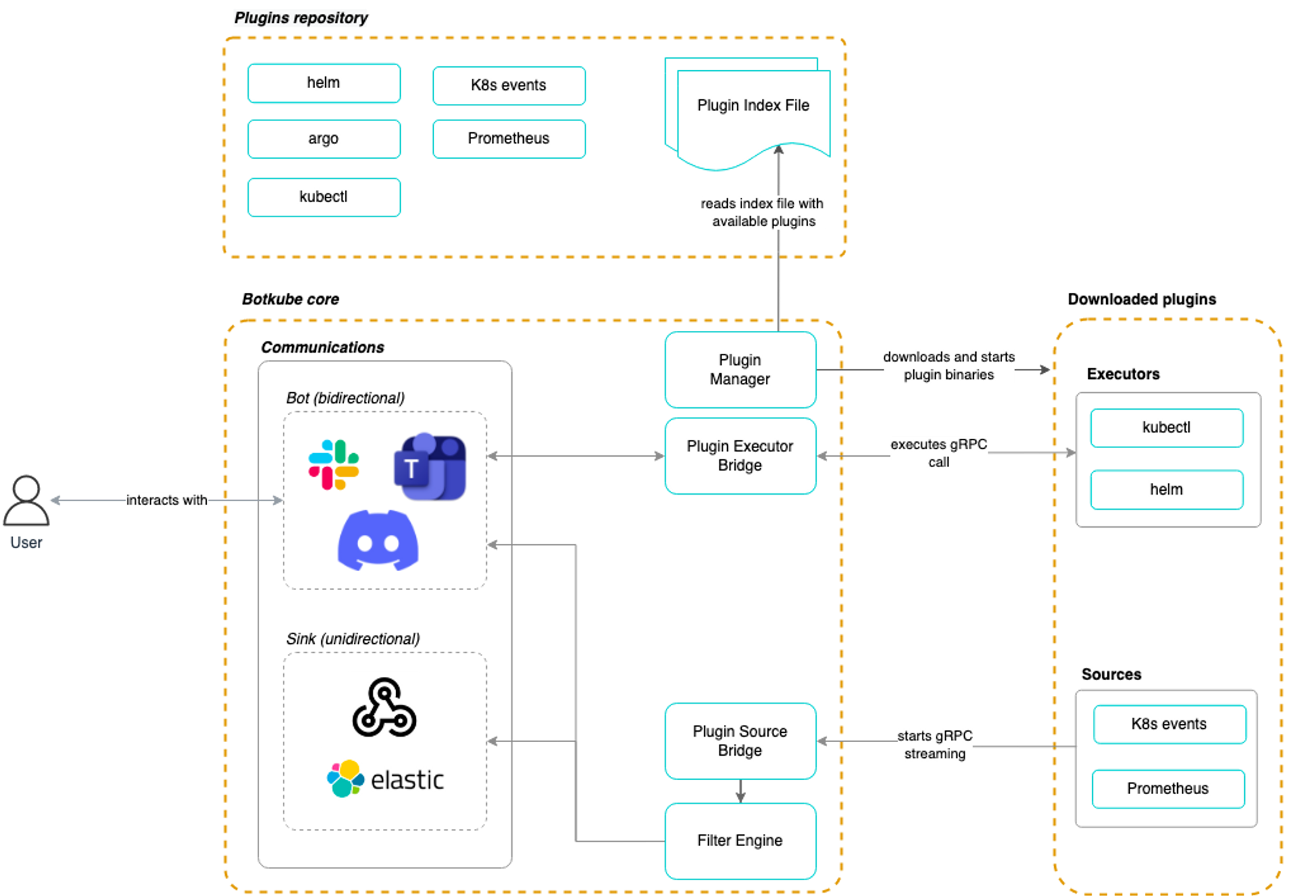
kubectl delete -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.3/deploy/deploy.yaml👉 Botkube
-
다양한 협업 도구의 BOT 기능을 연동하여 지표의 상태를 모니터링 하고, BOT을 이용한 kubectl 명령어 기능을 협업 도구에서 사용할 수 있도록 함
-
회사 내부 규정 상 도입하기 힘들 것 같아 개념만 정리
6. 프로메테우스-스택
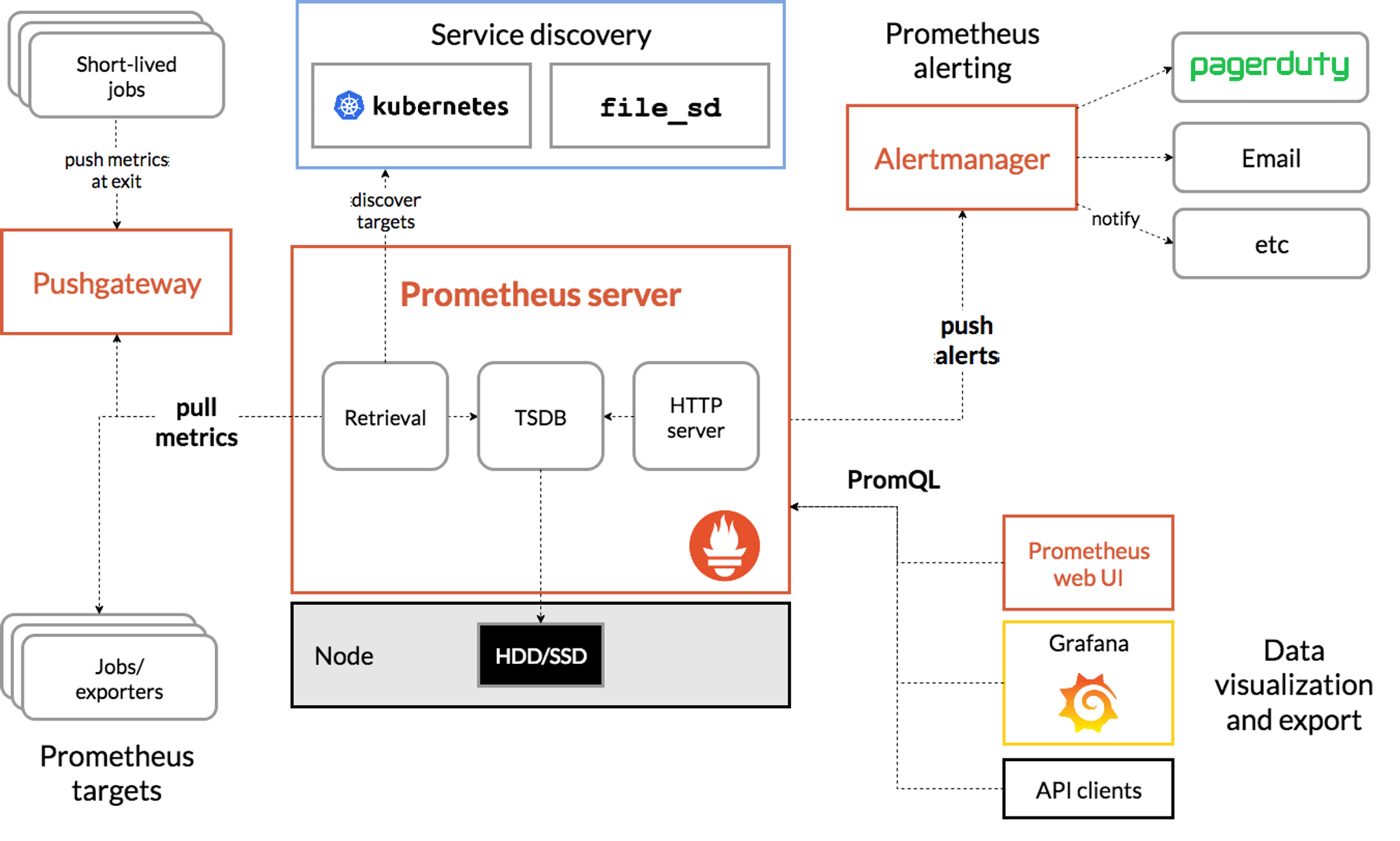
👉 Prometheus란?
- SoundCloud에서 개발한 오픈소스
- 대상 시스템의 지표를 수집하여 저장하고 검색할 수 있는 프로그램
👓 프로메테우스 기능
- a multi-dimensional data model with time series data(=TSDB, 시계열 데이터베이스) identified by metric name and key/value pairs
- PromQL, a flexible query language to leverage this dimensionality
- no reliance on distributed storage; single server nodes are autonomous
- time series collection happens via a pull model over HTTP
- pushing time series is supported via an intermediary gateway
- targets are discovered via service discovery or static configuration
- multiple modes of graphing and dashboarding support
👉 프로메테우스-스택 설치
: 모니터링에 필요한 여러 요소를 단일 차트(스택)으로 제공 ← 시각화(그라파나), 이벤트 메시지 정책(경고 임계값, 경고 수준) 등
참고 링크
https://artifacthub.io/packages/helm/prometheus-community/kube-prometheus-stack
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo $CERT_ARN
# repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > monitor-values.yaml
prometheus:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
defaultRules:
create: false
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
alertmanager:
enabled: false
# alertmanager:
# ingress:
# enabled: true
# ingressClassName: alb
# hosts:
# - alertmanager.$MyDomain
# paths:
# - /*
# annotations:
# alb.ingress.kubernetes.io/scheme: internet-facing
# alb.ingress.kubernetes.io/target-type: ip
# alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
# alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
# alb.ingress.kubernetes.io/success-codes: 200-399
# alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
# alb.ingress.kubernetes.io/group.name: study
# alb.ingress.kubernetes.io/ssl-redirect: '443'
EOT
cat monitor-values.yaml | yh
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.27.2 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring
# 확인
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
kubectl get pod,svc,ingress -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,servicemonitors -n monitoring
kubectl get crd | grep monitoring-
파라미터 파일 생성 후 배포 및 모니터링
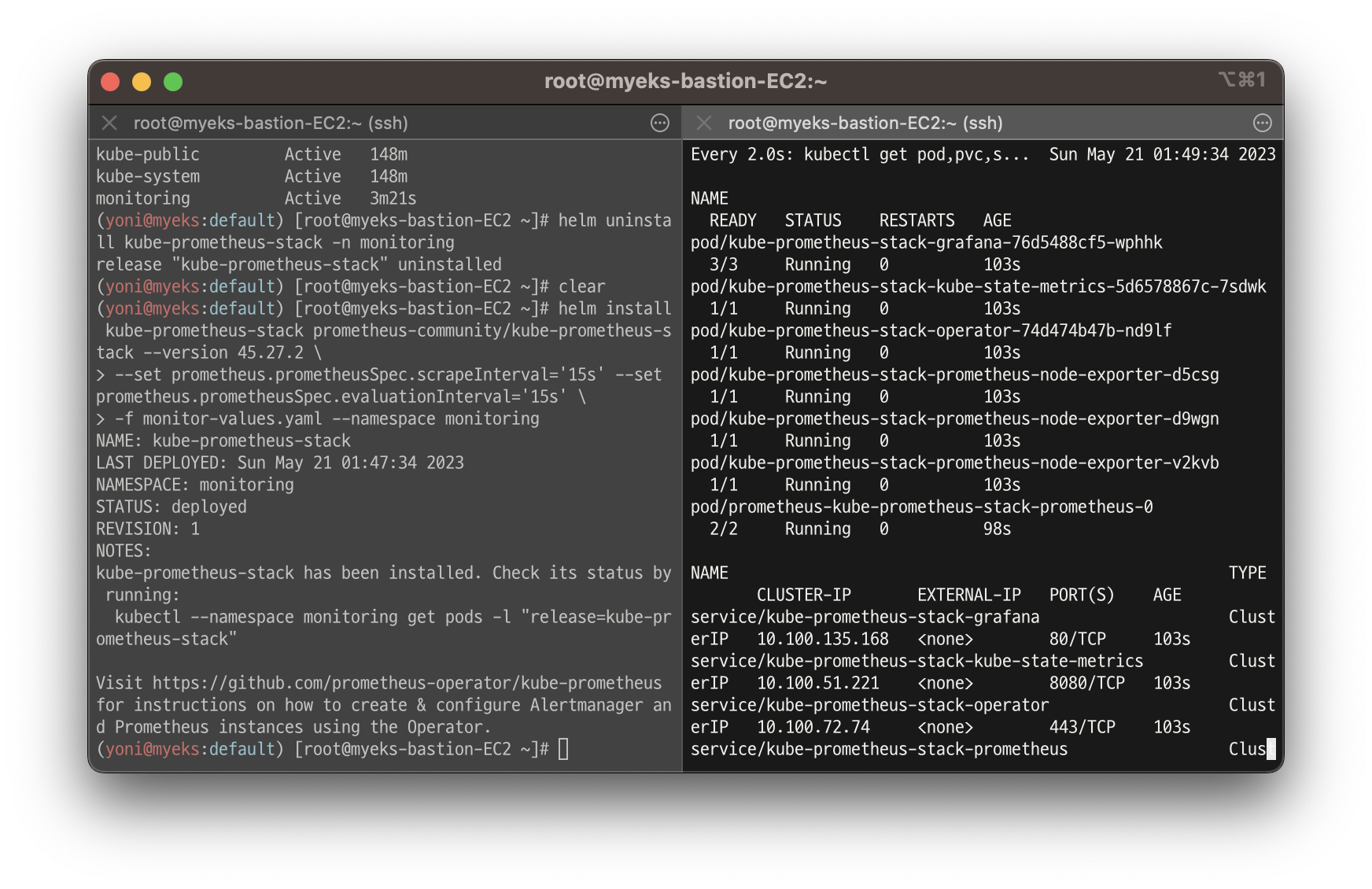
-
kubectl get prometheus, servicemonitors -n monitoring
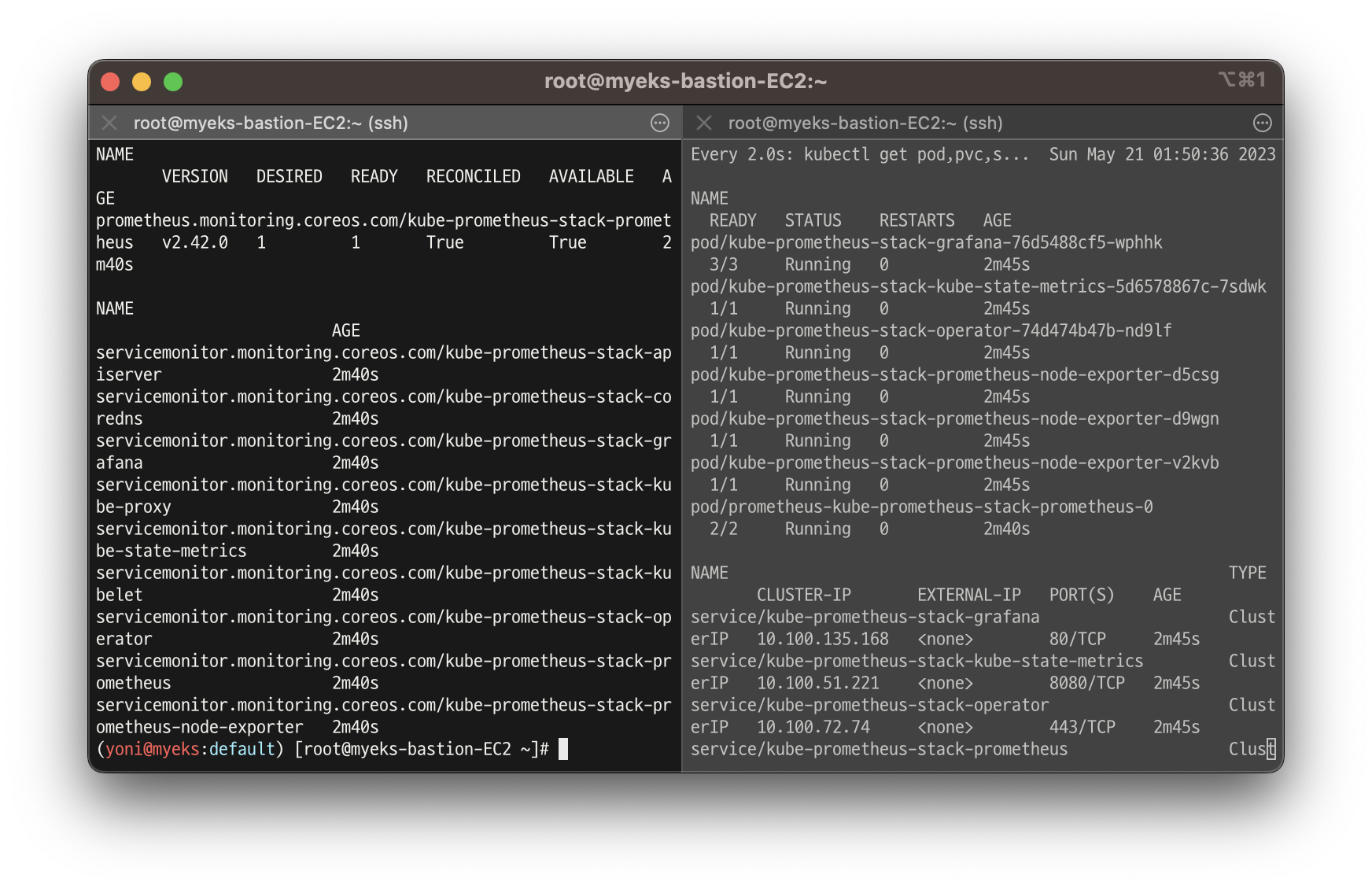
-
실습 종료 후 삭제
# helm 삭제
helm uninstall -n monitoring kube-prometheus-stack
# crd 삭제
kubectl delete crd alertmanagerconfigs.monitoring.coreos.com
kubectl delete crd alertmanagers.monitoring.coreos.com
kubectl delete crd podmonitors.monitoring.coreos.com
kubectl delete crd probes.monitoring.coreos.com
kubectl delete crd prometheuses.monitoring.coreos.com
kubectl delete crd prometheusrules.monitoring.coreos.com
kubectl delete crd servicemonitors.monitoring.coreos.com
kubectl delete crd thanosrulers.monitoring.coreos.com👉 프로메테우스 기본 사용 : 모니터링 그래프
-
모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출
-
이후 프로메테우스는 해당 경로에 http get 방식으로 메트릭 정보를 가져와 TSDB 형식으로 저장
-
9100에 접속하여 메트릭 정보 수집
kubectl get node -owide
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter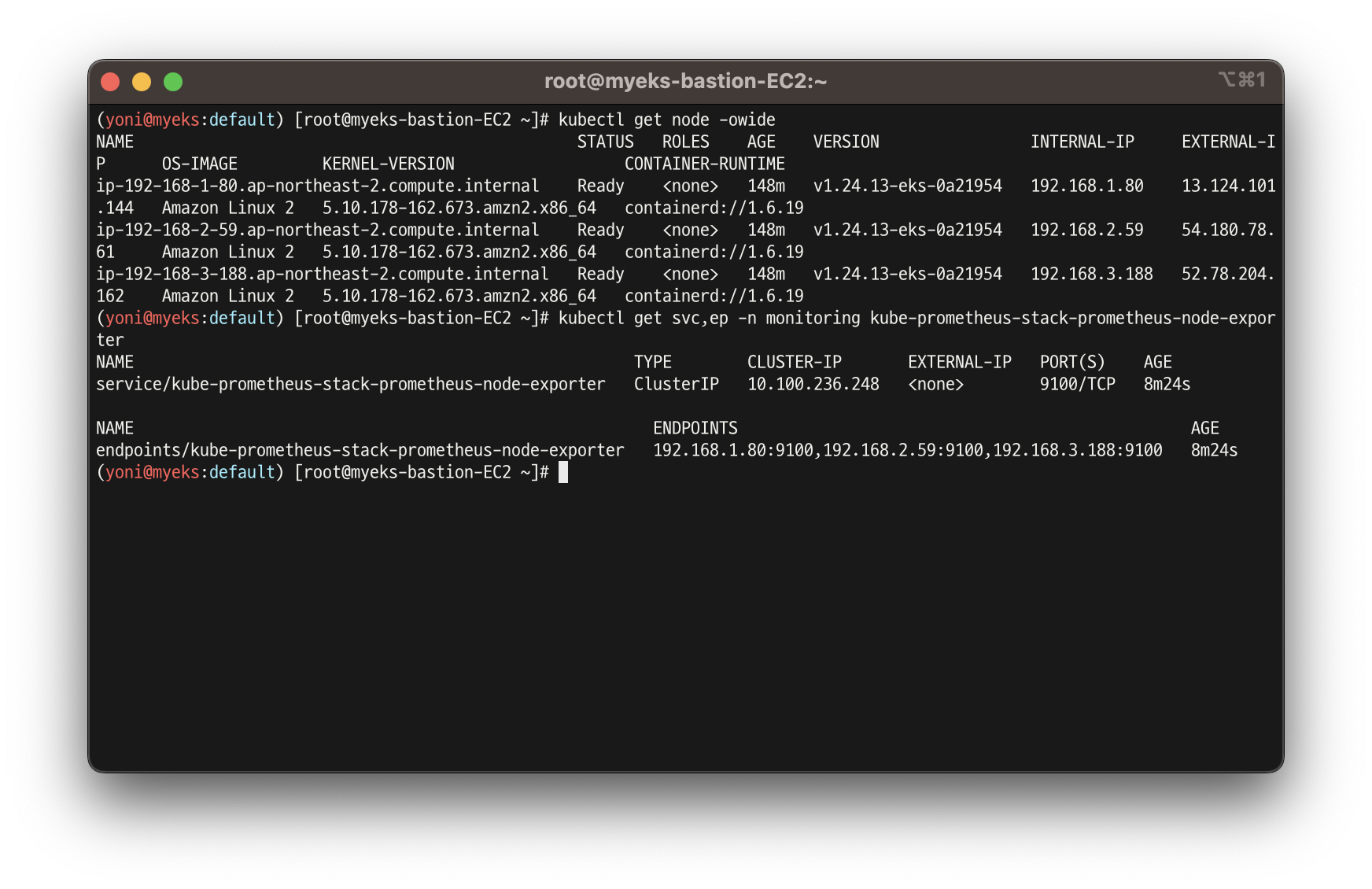
- 마스터 이외에 워커노드 확인
ssh ec2-user@$N1 curl -s localhost:9100/metrics
👉 프로메테우스 인그레스 도메인으로 웹 접속
- 인그레스 확인
kubectl get ingress -n monitoring kube-prometheus-stack-prometheus
kubectl describe ingress -n monitoring kube-prometheus-stack-prometheus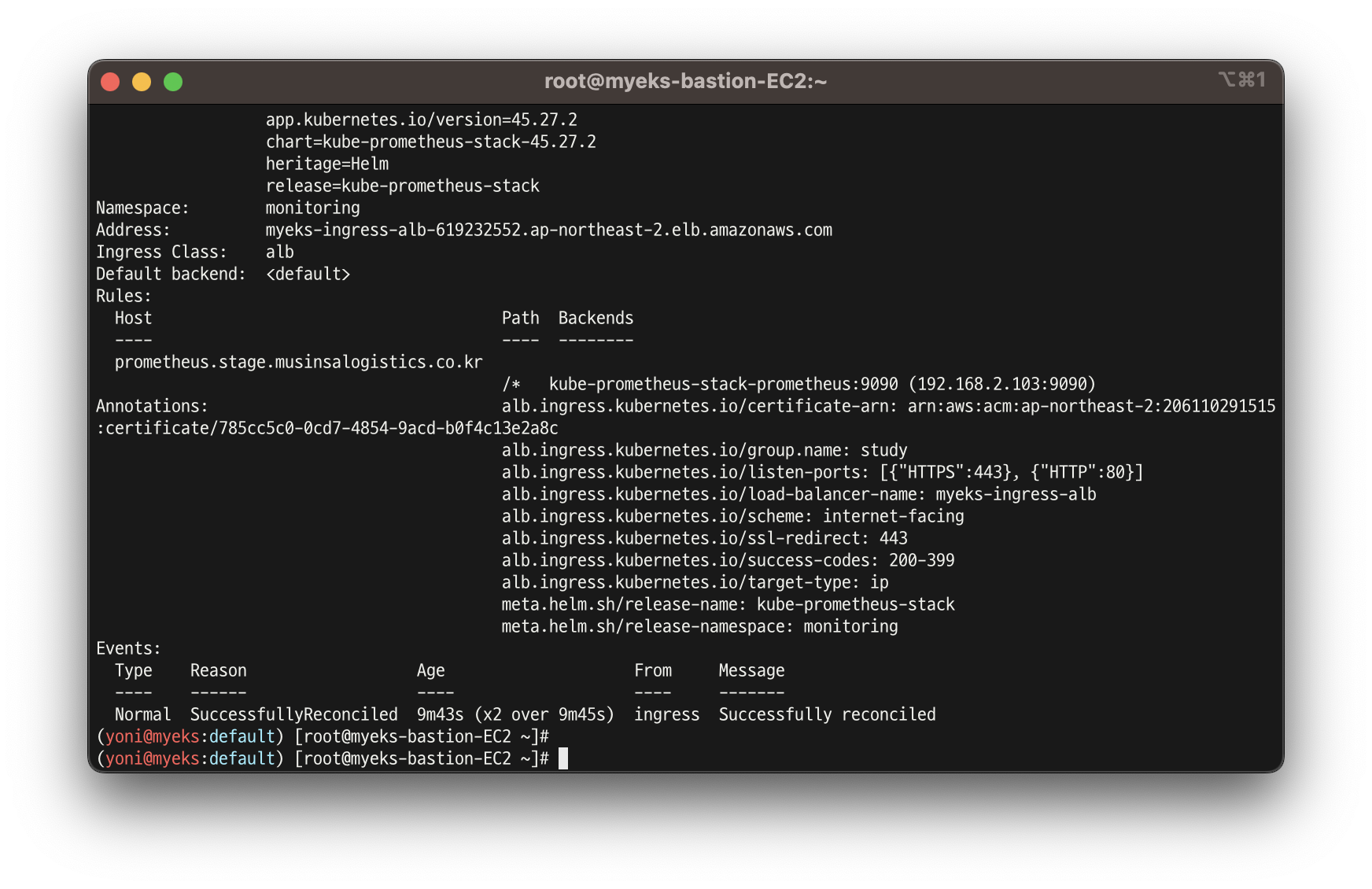
- 프로메테우스 인그레스 도메인으로 웹 접속
echo -e "Prometheus Web URL = https://prometheus.$MyDomain"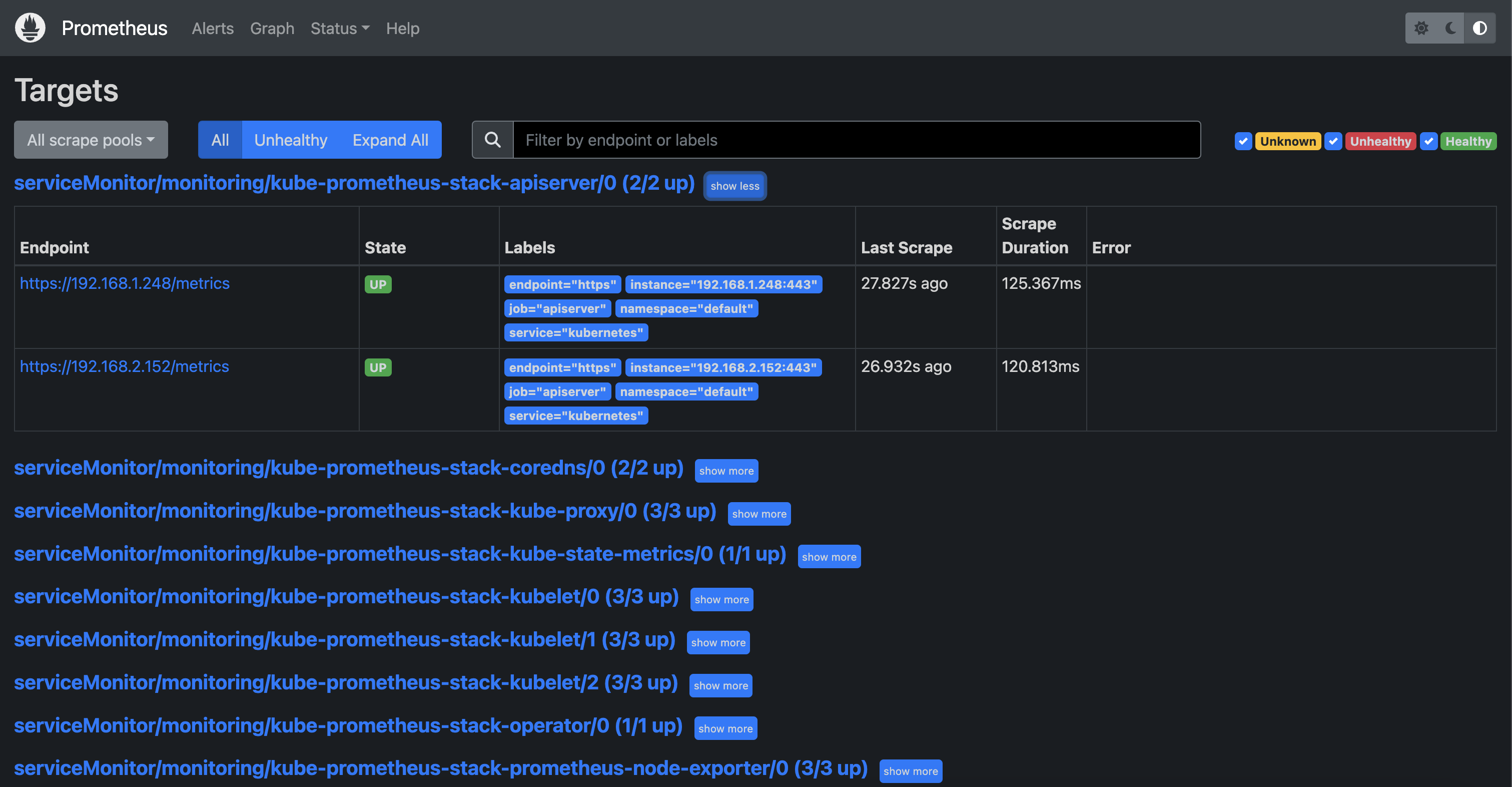
-
쿼리 입력 옵션
- Use local time : 출력 시간을 로컬 타임으로 변경
- Enable query history : PromQL 쿼리 히스토리 활성화
- Enable autocomplete : 자동 완성 기능 활성화
- Enable highlighting : 하이라이팅 기능 활성화
-
프로메테우스 설정(Configuration) 확인 : Status → Runtime & Build Information 클릭
- Storage retention : 5d or 10GiB → 메트릭 저장 기간이 5일 경과 혹은 10GiB 이상 시 오래된 것부터 삭제 ⇒ helm 파라미터에서 수정 가능
-
프로메테우스 설정(Configuration) 확인 : Status → Command-Line Flags 클릭
- -log.level : info
- -storage.tsdb.retention.size : 10GiB
- -storage.tsdb.retention.time : 5d
-
프로메테우스 설정(Configuration) 확인 : Status → Configuration ⇒ “node-exporter” 검색
- job name 을 기준으로 scraping
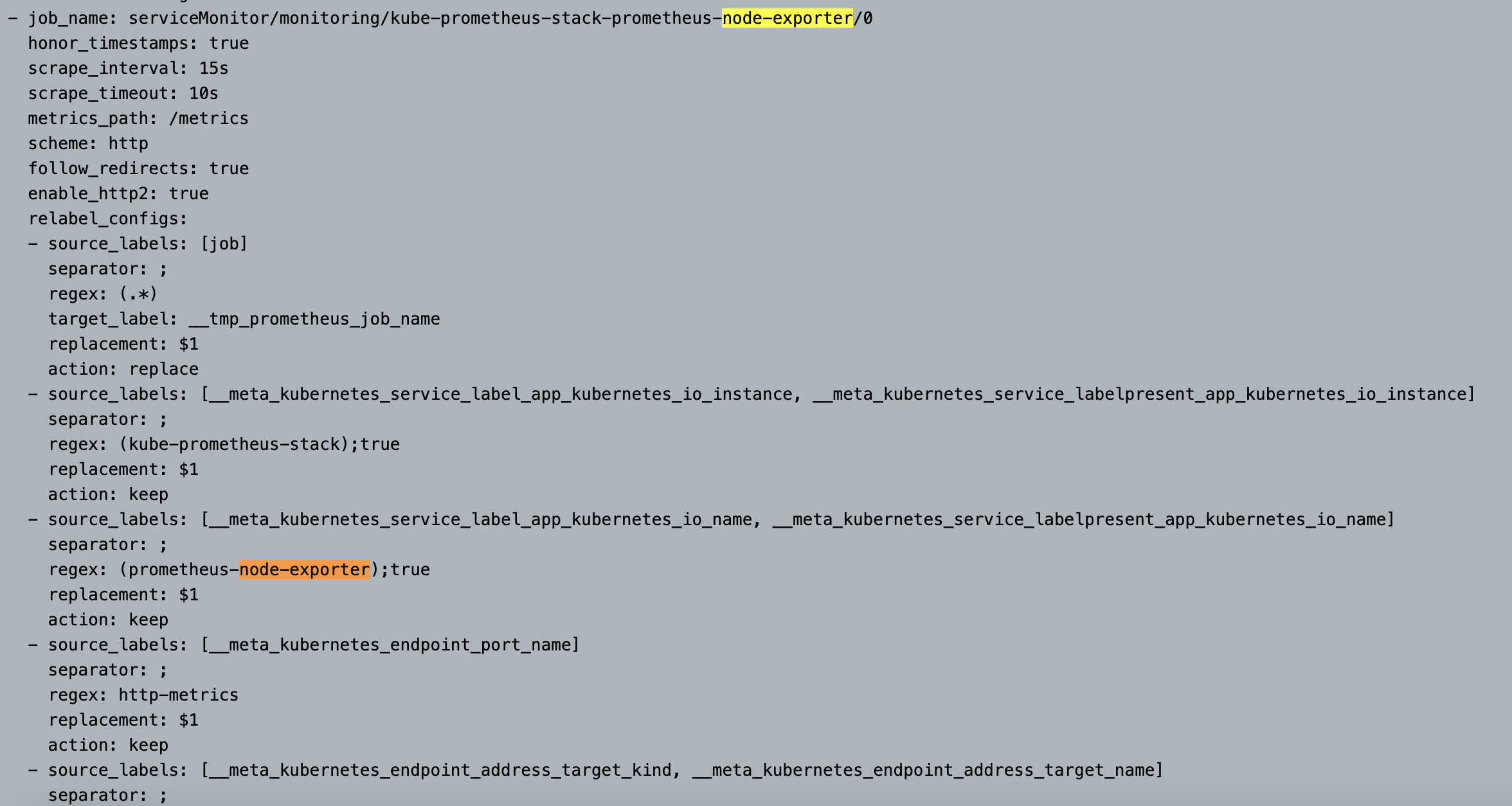
-
전체 메트릭 대상(Targets) 확인 : Status -> Targets
- 해당 스택은 ‘노드-익스포터’, cAdvisor, 쿠버네티스 전반적인 현황 이외에 다양한 메트릭을 포함
-
프로메테우스 웹에서 메트릭 정보 확인

-
프로메테우스 설정(Configuration) 확인 : Status → Service Discovery : 모든 endpoint 로 도달 가능 시 자동 발견!, 도달 규칙은 설정Configuration 파일에 정의
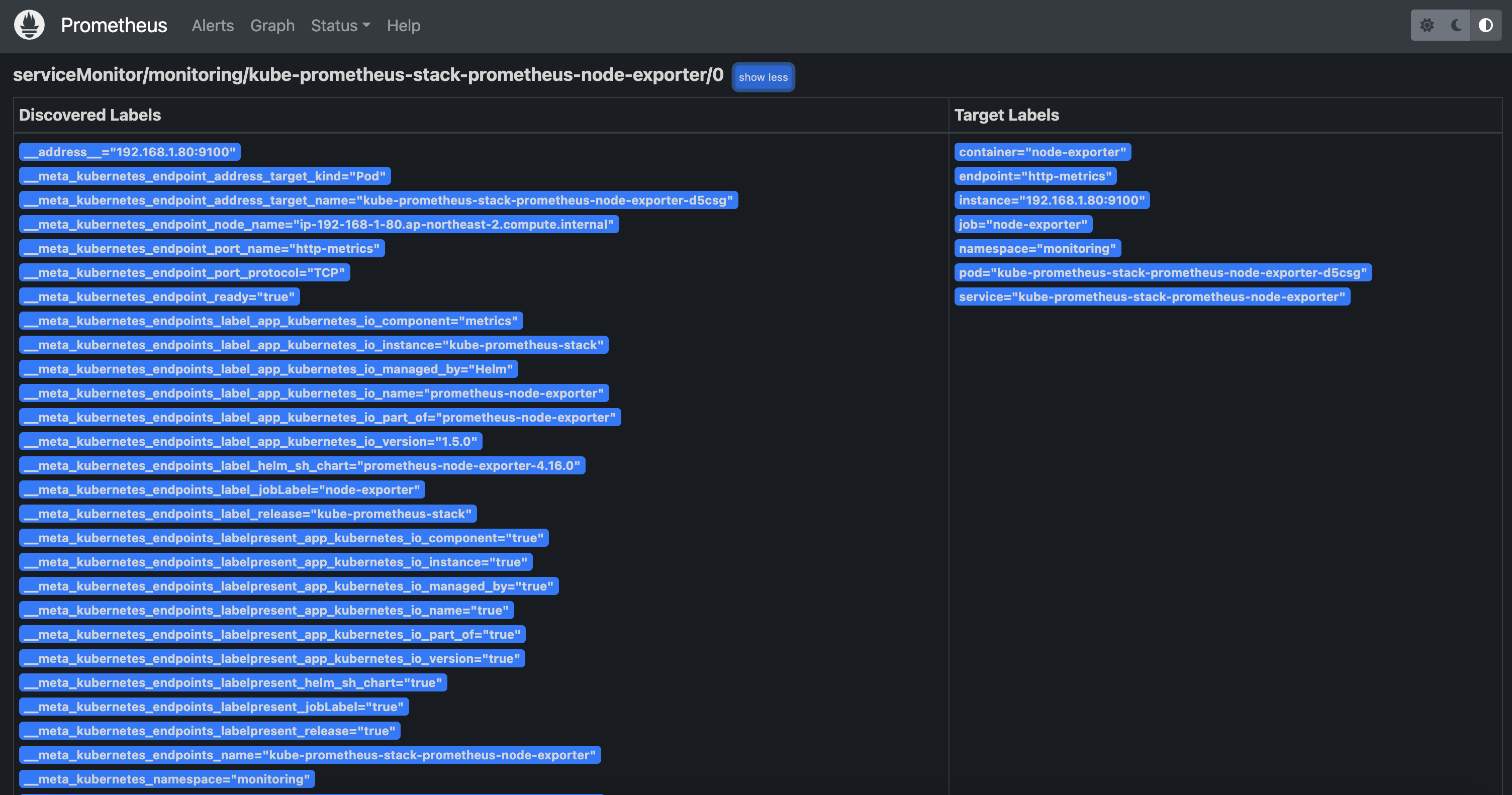
-
메트릭을 그래프(Graph)로 조회 : Graph - 아래 PromQL 쿼리(전체 클러스터 노드의 CPU 사용량 합계)입력 후 조회 → Graph 확인
- 혹은 지구 아이콘(Metrics Explorer) 클릭 시 전체 메트릭 출력되며, 해당 메트릭 클릭해서 확인
1- avg(rate(node_cpu_seconds_total{mode="idle"}[1m]))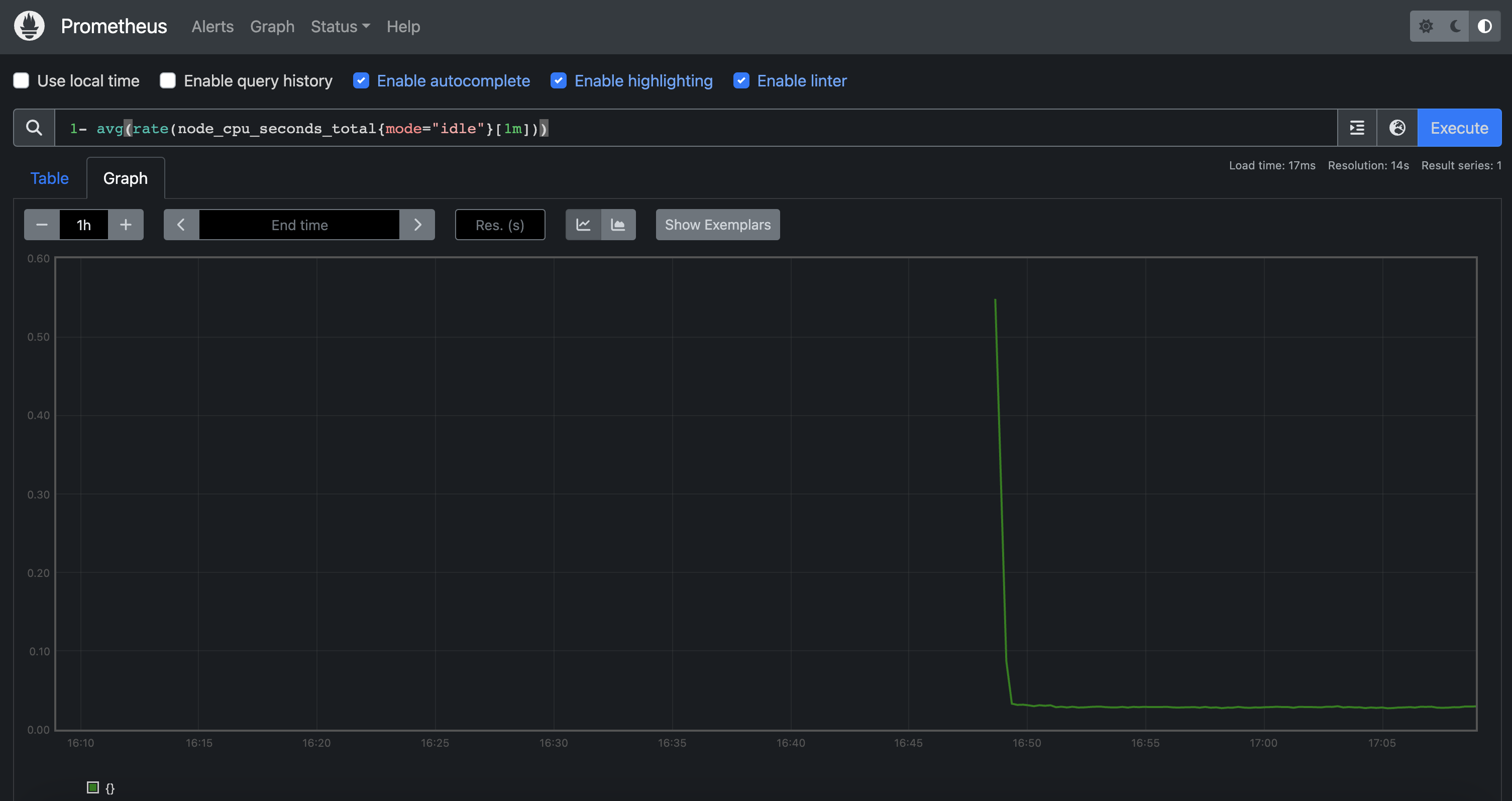
7. 그라파나
-
그라파나란?
: TSDB 데이터를 시각화, 다양한 데이터 형식 지원(메트릭, 로그, 트레이스 등) -
그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않음 → 현재 실습 환경에서는 데이터 소스는 프로메테우스를 사용
-
접속 정보 확인 및 로그인 : 기본 계정 - admin / prom-operator
-
❗️ 회사에 대한 정보가 담겨 있어서 실습 화면은 생략
# 그라파나 버전 확인
kubectl exec -it -n monitoring deploy/kube-prometheus-stack-grafana -- grafana-cli --version
grafana cli version 9.5.1
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속 : 기본 계정 - admin / prom-operator
echo -e "Grafana Web URL = https://grafana.$MyDomain"Connections → Your connections
: 스택의 경우 자동으로 프로메테우스를 데이터 소스로 추가해둠
- 서비스 주소 확인
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus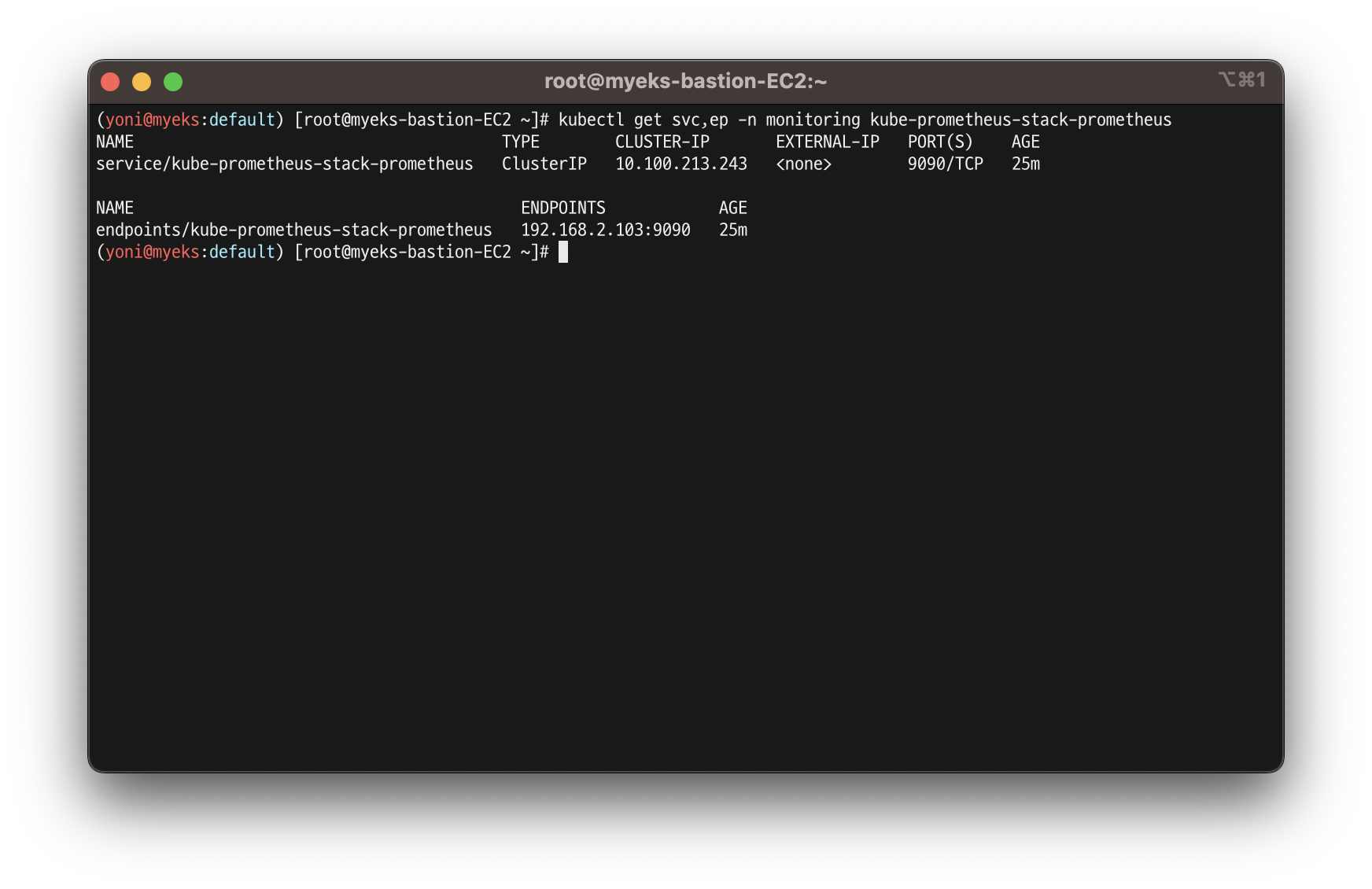
- 해당 데이터 소스 접속 확인
# 테스트용 파드 배포
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: netshoot-pod
spec:
containers:
- name: netshoot-pod
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
EOF
kubectl get pod netshoot-pod
# 접속 확인
kubectl exec -it netshoot-pod -- nslookup kube-prometheus-stack-prometheus.monitoring
kubectl exec -it netshoot-pod -- curl -s kube-prometheus-stack-prometheus.monitoring:9090/graph -v ; echo
# 삭제
kubectl delete pod netshoot-pod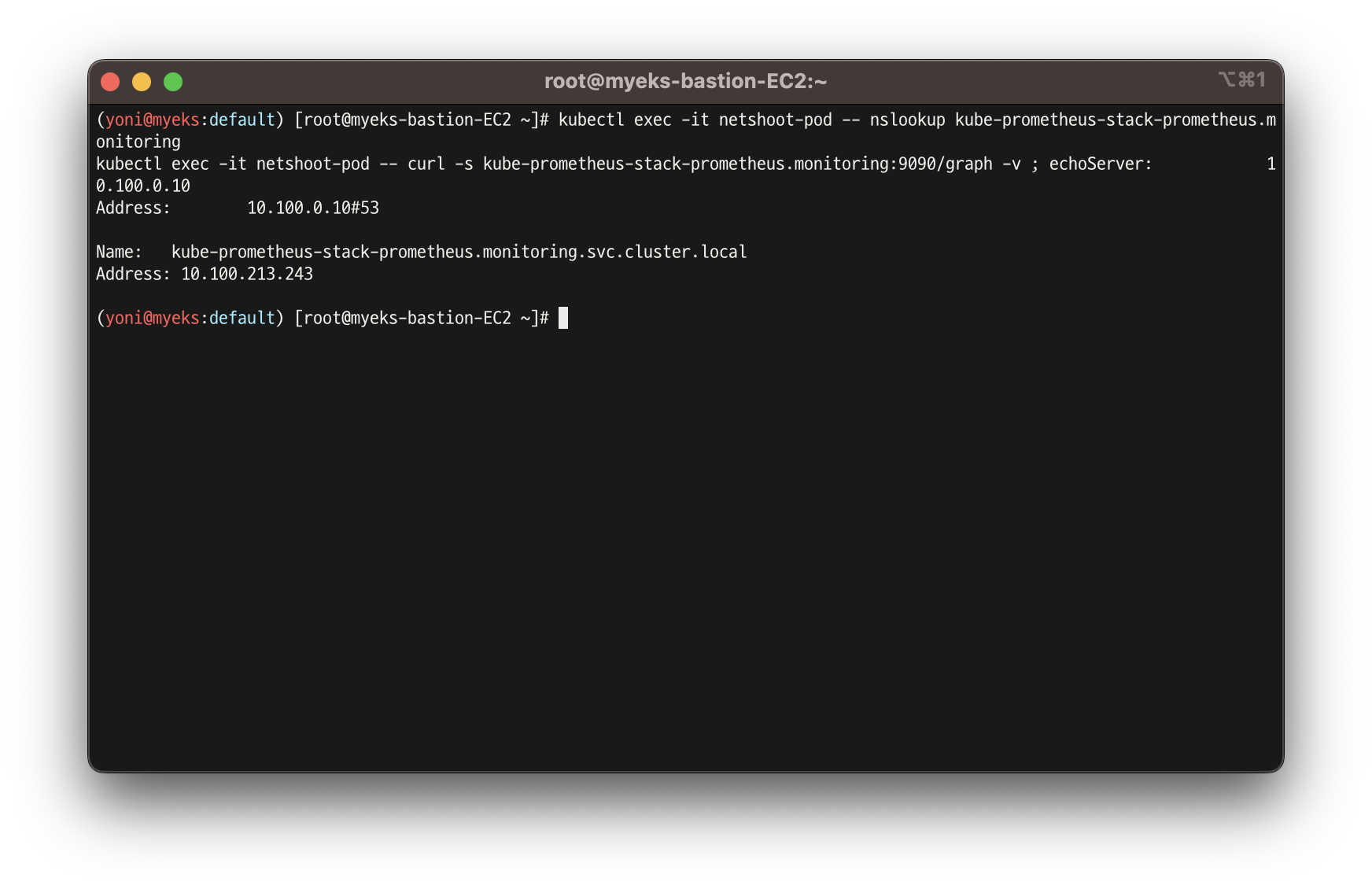
👉 대시보드 사용
기본 대시보드
- 스택을 통해서 설치된 기본 대시보드 확인 : Dashboards → Browse
- (대략) 분류 : 자원 사용량 - Cluster/POD Resources, 노드 자원 사용량 - Node Exporter, 주요 애플리케이션 - CoreDNS 등
공식 대시보드
- [**Kubernetes / Views / Global**] Dashboard → New → Import → 15757 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [**1 Kubernetes All-in-one Cluster Monitoring KR**] Dashboard → New → Import → 13770 or 17900 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [**Node Exporter Full**] Dashboard → New → Import → 1860 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [****Node Exporter for Prometheus Dashboard based on 11074] 15172**
- kube-state-metrics-v2 가져와보자 : Dashboard ID copied! (13332) 클릭 - 링크
- [kube-state-metrics-v2] Dashboard → New → Import → 13332 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [Amazon EKS] **AWS CNI Metrics 16032 - 링크
# PodMonitor 배포
cat <<EOF | kubectl create -f -
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node
EOF
# PodMonitor 확인
kubectl get podmonitor -n kube-system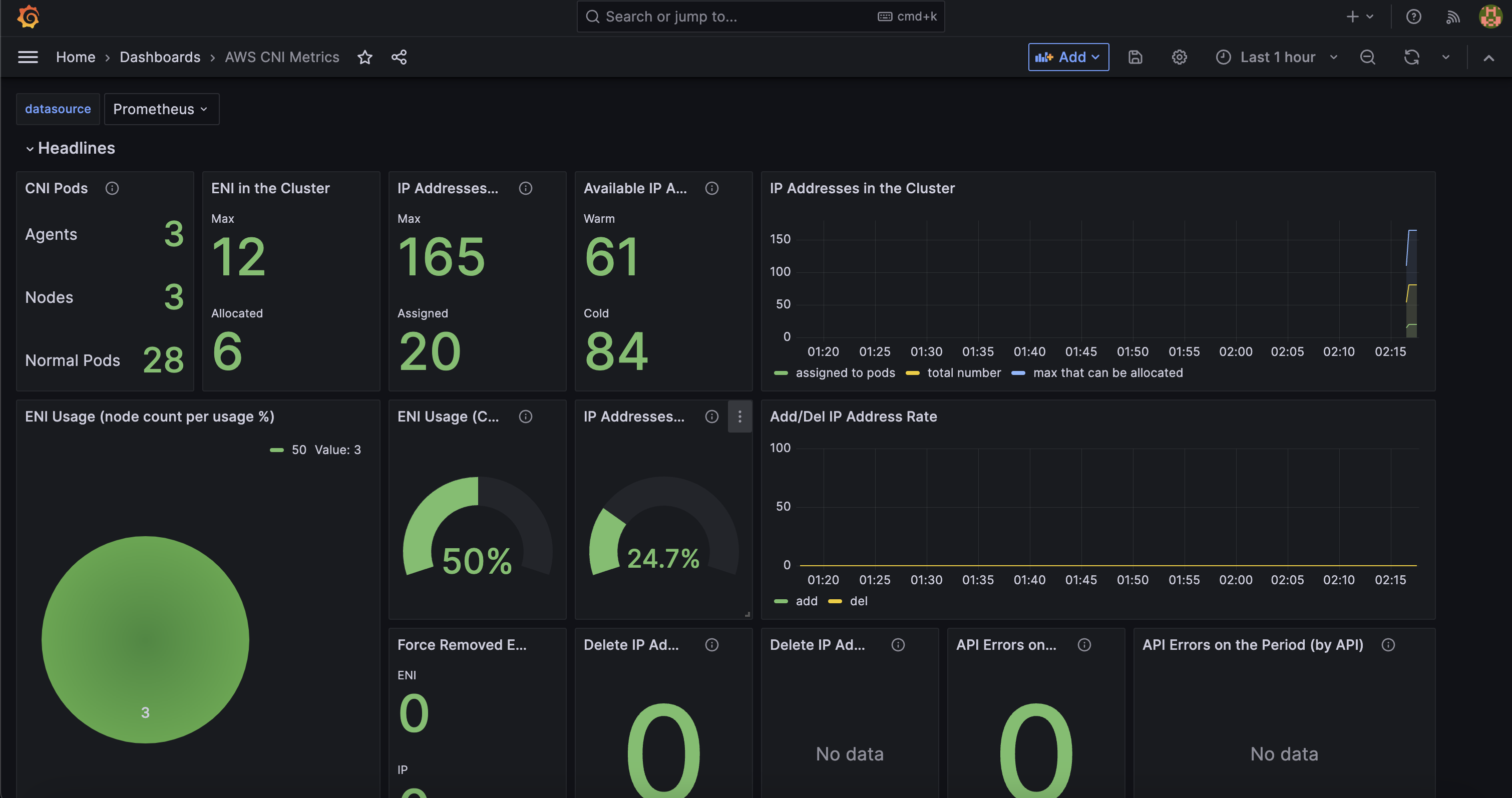
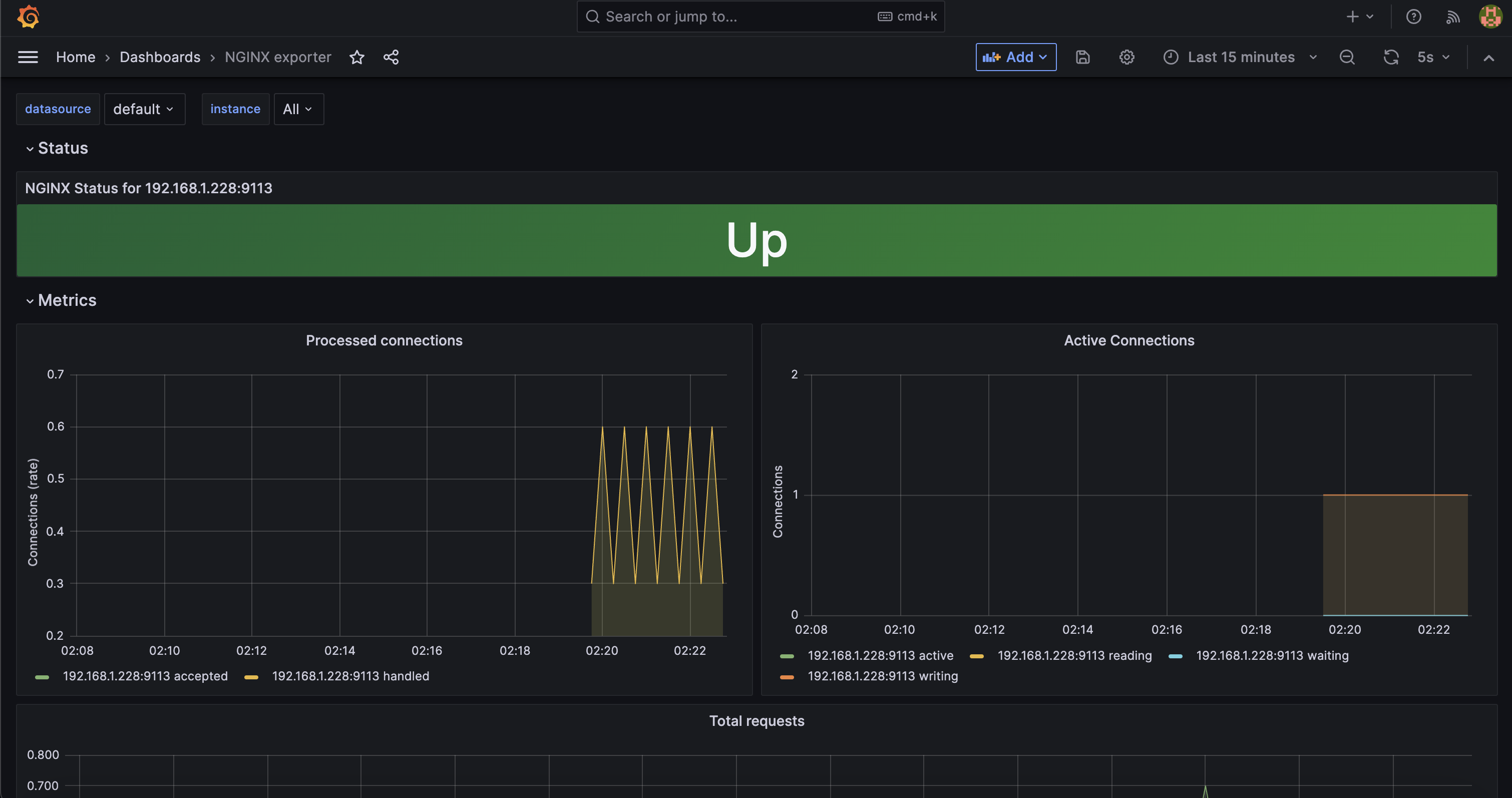
👉 NGINX 웹서버 배포 및 애플리케이션 모니터링 설정 및 접속
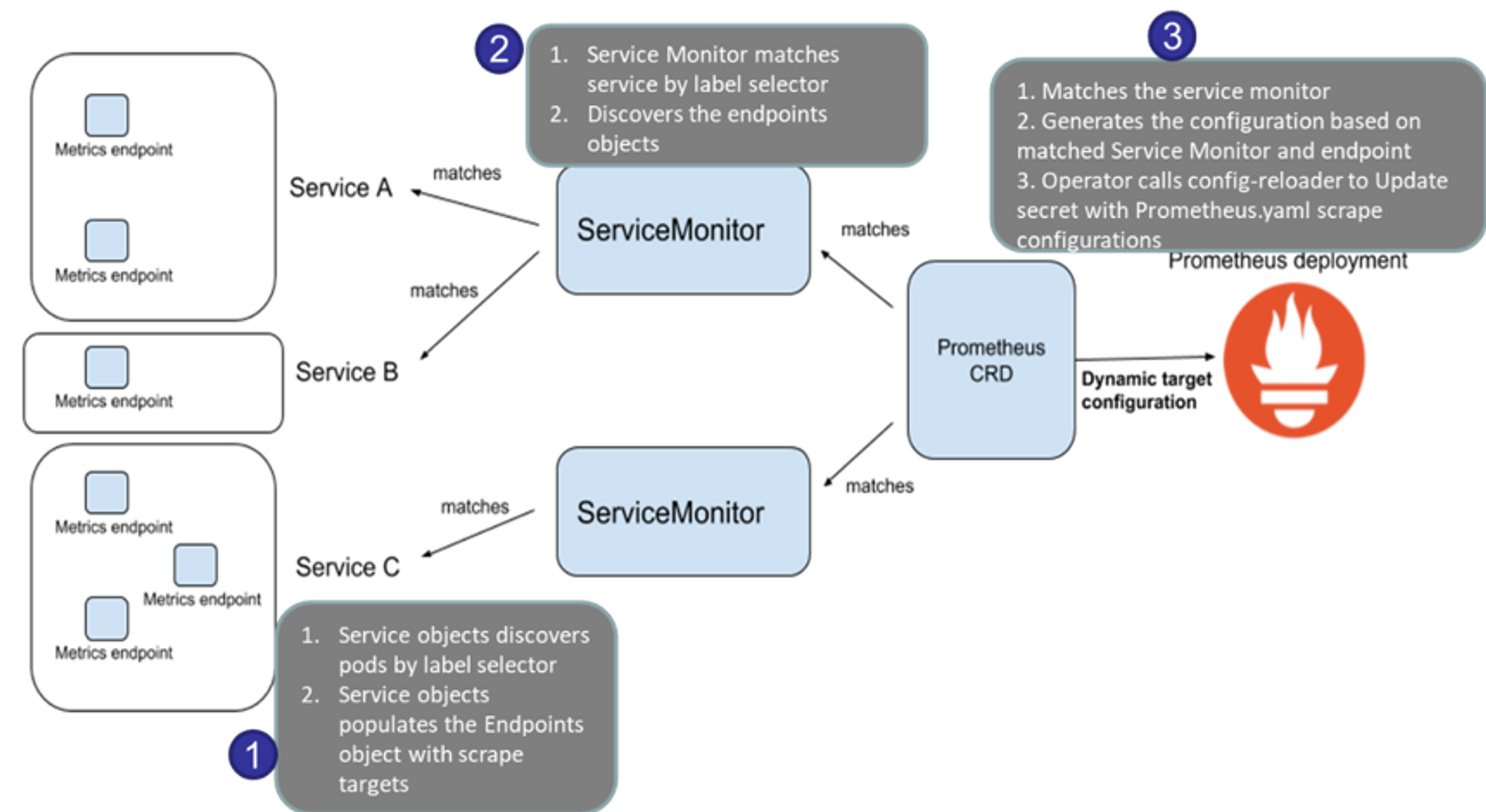
-
nginx 를 helm 설치 시 프로메테우스 익스포터 Exporter 옵션 설정 시 자동으로 nginx 를 프로메테우스 모니터링에 등록 가능!
- 프로메테우스 설정에서 nginx 모니터링 관련 내용을 서비스 모니터 CRD로 추가 가능!
-
기존 애플리케이션 파드에 프로메테우스 모니터링을 추가하려면 사이드카 방식을 사용하며 exporter 컨테이너를 추가!
-
nginx 웹 서버(with helm)에 metrics 수집 설정 추가 - Helm
-
배포 및 확인
# 모니터링
watch -d kubectl get pod
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용, nginx 웹서버 노출은 AWS CLB 기본 사용
cat <<EOT > ~/nginx_metric-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm upgrade nginx bitnami/nginx --reuse-values -f nginx_metric-values.yaml
# 확인
kubectl get pod,svc,ep
kubectl get servicemonitor -n monitoring nginx
kubectl get servicemonitor -n monitoring nginx -o json | jq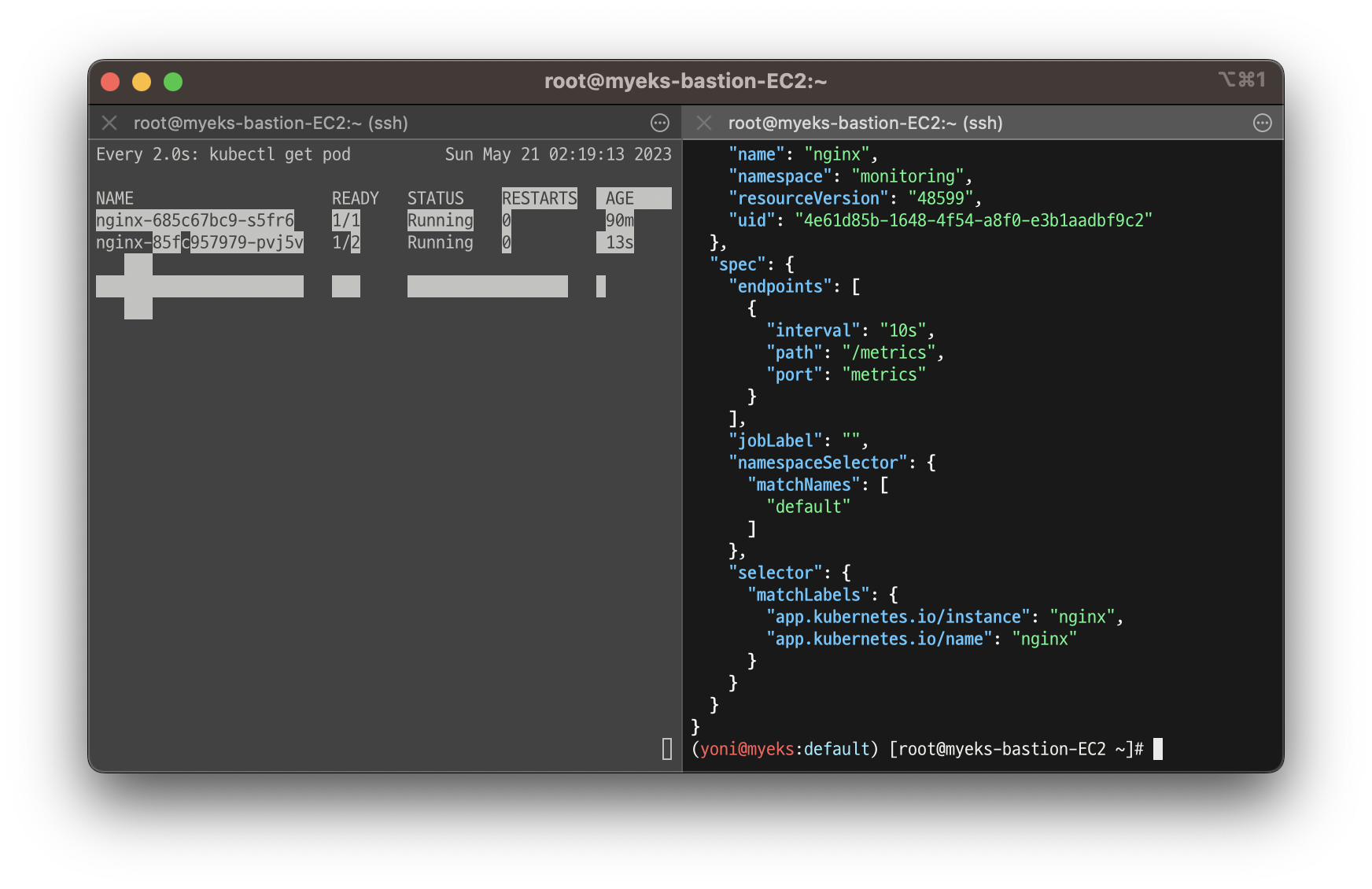
- 메트릭 확인
NGINXIP=$(kubectl get pod -l app.kubernetes.io/instance=nginx -o jsonpath={.items[0].status.podIP})
curl -s http://$NGINXIP:9113/metrics # nginx_connections_active Y 값 확인해보기
curl -s http://$NGINXIP:9113/metrics | grep ^nginx_connections_active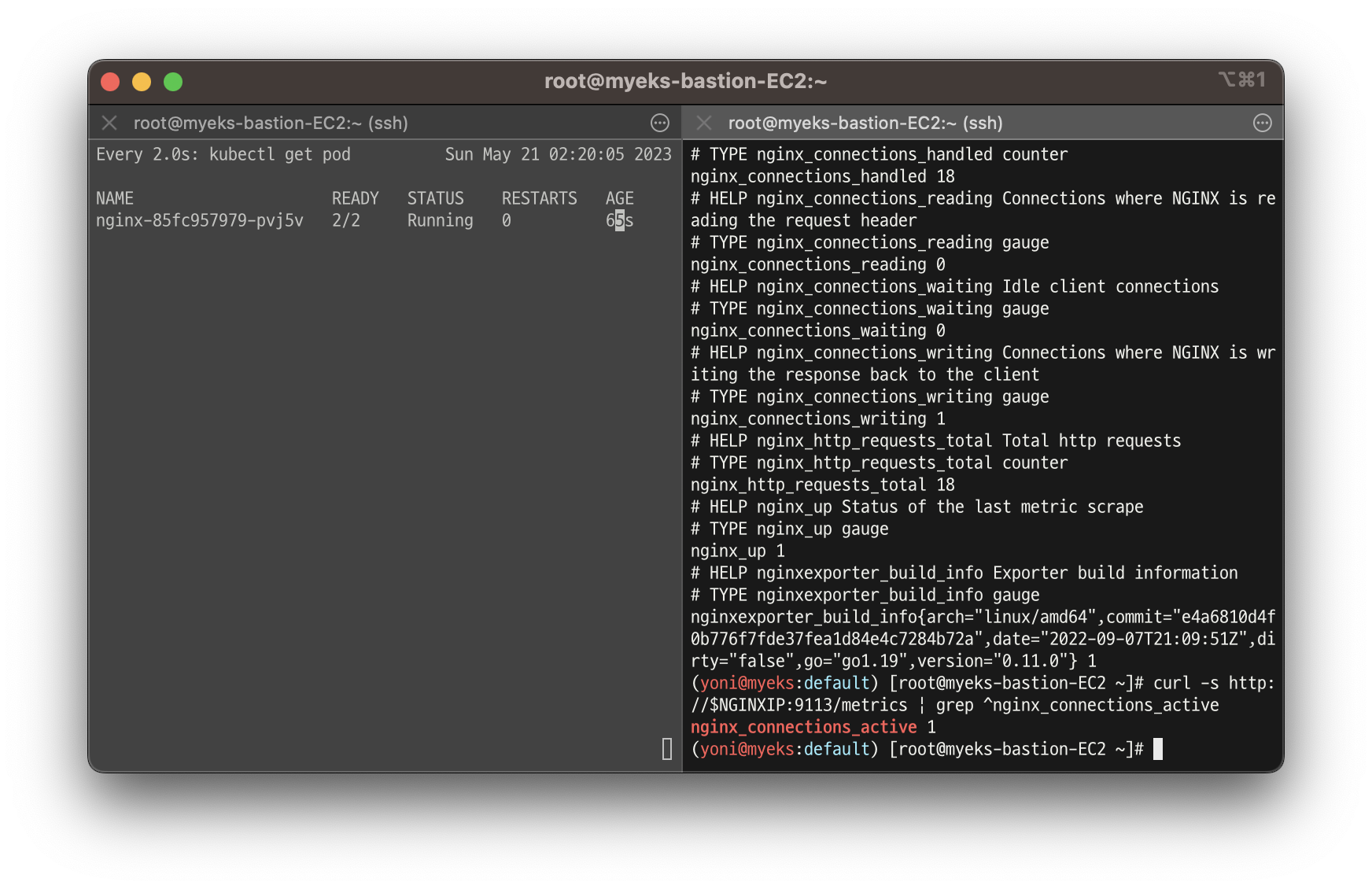
-
서비스 모니터링 생성 후 프로메테우스 웹서버 -> target에 nginx 서비스 모니터 추가 확인
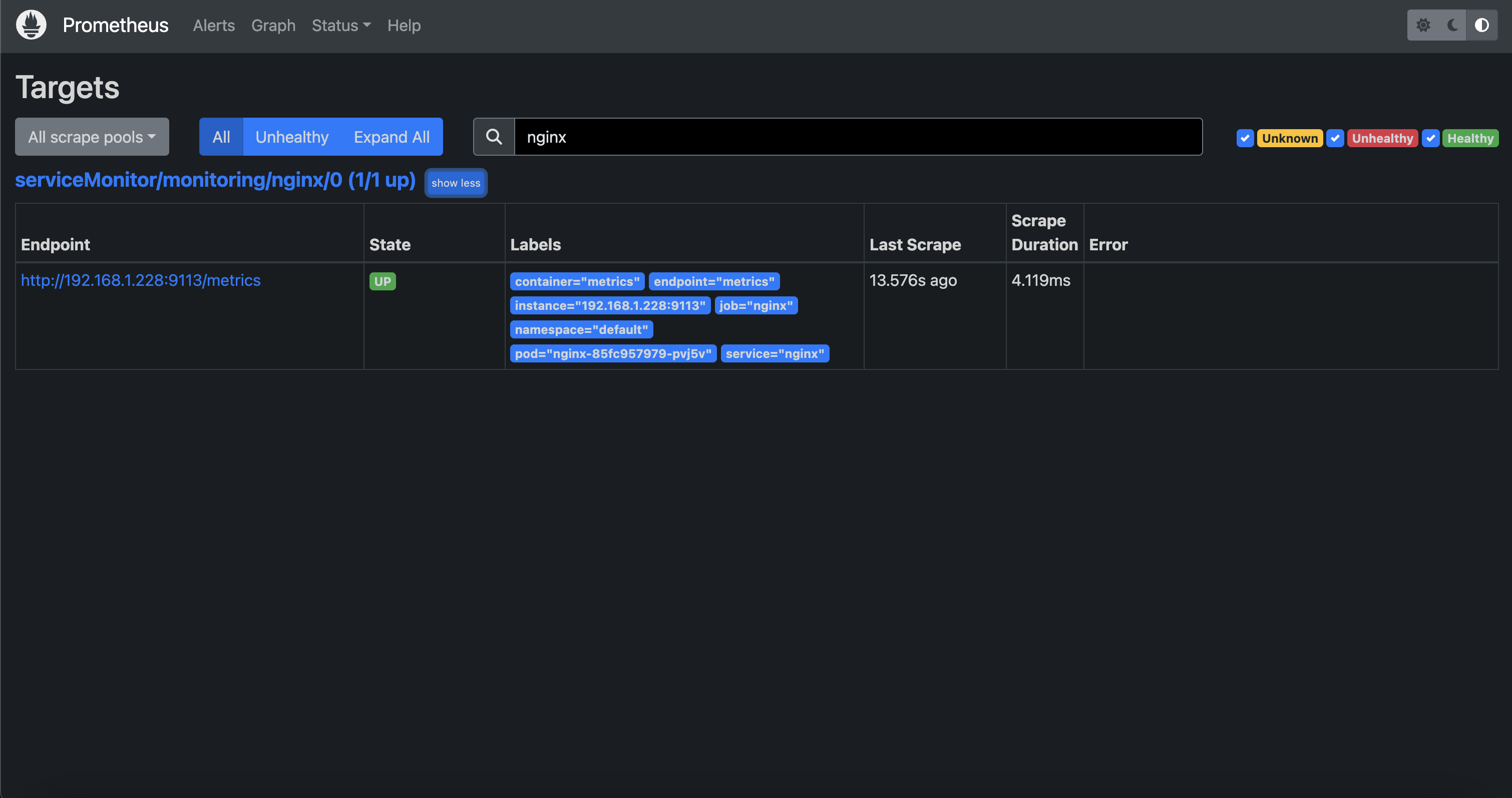
-
NGINX 애플리케이션 모니터링 대시보드 추가 : 그라파나에 12708 대시보드 추가