LCS(Longest Common Substring), 최장 문자열 알고리즘
Longest Common Substring이다.
문자열 FERRARI와 FERRNANDO가 있다면 두 문자열의 LCS는 FERR가 된다.
두 개의 문자열a,b를 한 글자씩 비교해가며 값이 같을 경우 2차원배열의 LCS[i][j]값에 LCS[i-1][j-1]+1을 더해준다.
점화식
if i == 0 or j == 0: # 마진 설정
LCS[i][j] = 0
elif string_A[i] == string_B[j]:
LCS[i][j] = LCS[i - 1][j - 1] + 1
else:
LCS[i][j] = 0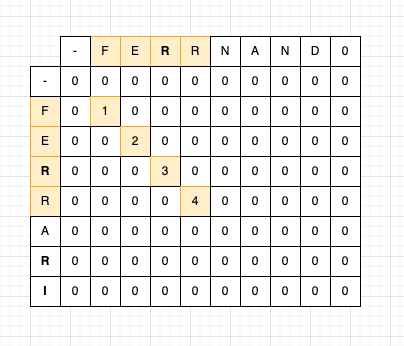
LCS(Longest Common Subsequence), 최장 공통 부분수열 알고리즘
최장 공통 부분 문자열과의 차이점은 부분집합이라는 점이다. 연속된 문자열이 아니고, 겹치는 알파벳의 순서가 같기만 하면 된다.
점화식
if i == 0 or j == 0: # 마진 설정
LCS[i][j] = 0
elif string_A[i] == string_B[j]:
LCS[i][j] = LCS[i - 1][j - 1] + 1
else:
LCS[i][j] = max(LCS[i - 1][j], LCS[i][j - 1])
- LCS 배열의 가장 마지막 값에서 시작합니다. 결과값을 저장할
result배열을 준비한다.LCS[i - 1][j]와LCS[i][j - 1]중 현재 값과 같은 값을 찾습니다.- 만약 같은 값이 있다면 해당 값으로 이동한다.
- 만약 같은 값이 없다면
result배열에 해당 문자를 넣고LCS[i -1][j - 1]로 이동한다.- 2번 과정을 반복하다가 0으로 이동하게 되면 종료합니다.
result배열의 역순이 LCS 이다.
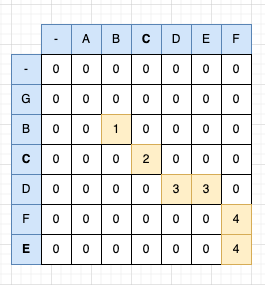
위의 그림에서는 LCS탐색 완료한 결과는 BCDF이다.
백준 예제 - LCS
코드
#9251번
import sys
read = sys.stdin.readline
s1, s2 = read().strip(), read().strip()
h,w = len(s1), len(s2)
lcs = [[0]*(w+1) for _ in range(h+1)]
for i in range(1,h+1):
for j in range(1,w+1):
if s1[i-1] == s2[j-1]:
lcs[i][j] = lcs[i-1][j-1] + 1
else:
lcs[i][j] = max(lcs[i][j-1], lcs[i-1][j])
print(lcs[-1][-1])참고자료

⚡실력으로 말하는 개발자가 되자⚡p.s.기록쟁이