프로그램이 종료되는 많은 원인 중 하나는 Out of Memory(OOM) 에러이다.
→ Spark 튜닝으로 성능 최적화와 함께 OOM 에러를 해결할 수 있다.
✅ 스파크 배경지식
- 1개의 익스큐터는 하나의 JVM을 갖는다.
- 각각의 익스큐터는 같은 개수의 Core와 같은 크기의 Memory(Heap)을 갖는다.
- 분산 능력이 없다면 스파크 잡은 하나의 익스큐터에서 실행된다.
- 병렬성이 없다면 하나의 익스큐터와 하나의 Core에서 실행된다.
- Spark와 YARN은 아래와 같이 익스큐터 컨테이너 단위로 메모리 계층을 구성한다.
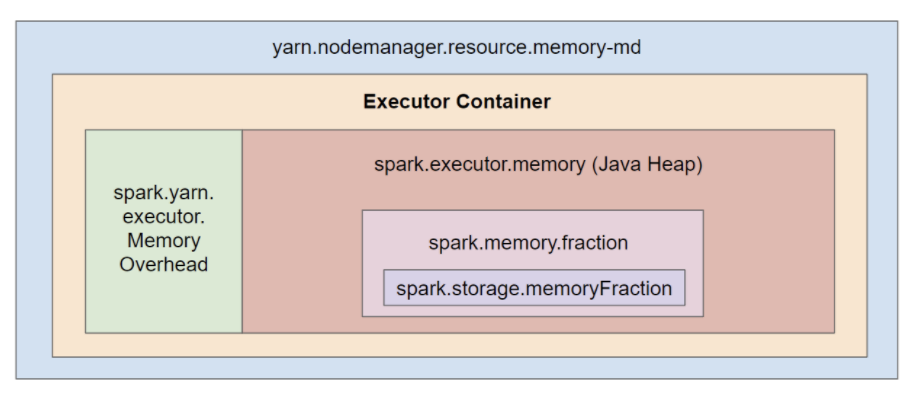
- yarn.nodemanager.resource.memory-md: 1개의 노드에 있는 모든 익스큐터 컨테이너들이 사용하는 메모리 총합
- spark.yarn.executor.MemoryOverhead: 오버헤드를 위한 여유분 메모리 크기
- spark.executor.memory: 1개의 익스큐터가 사용하는 메모리 크기로, 실제로 태스크를 실행할 때 사용된다.
- spark.memoryFraction: 태스크 실행, 셔플, 조인, 정렬, 집계를 위한 데이터 저장 비율
- spark.storage.memoryFraction: cache, broadcast, accumulator를 위한 데이터 저장 비율
- RDD
- 스파크 고유의 자료구조이며 분산이 용이하게 여러 개 파티션으로 구성된다.
- read-only, immutable, fault-tolerance
- 스파크 잡은 RDD를 가공해 새로운 RDD를 얻는다.
- 트랜스포메이션과 액션 두 가지의 operator가 있다.
- 지연 연산으로 operation 파이프라인을 최적화한다.
- 변환 함수는 Narrow와 Wide로 구분되며 Wide는 네트워크를 통해 데이터 셔플이 발생하는 아주 비싼 operator다.
✅ 파티셔닝
- Divide and Conquer
- 각 파티션이 일정 크기의 데이터를 가지는 것에 한해서 파티션 개수를 최대화하여 병렬성을 높이는 것이 좋다.
- 파티셔닝은 개수를 제어하는 것 뿐 아니라 파티션의 데이터 분포를 균등하게 조절하는 역할도 한다.
- 데이터가 한 쪽 파티션에 쏠리면 speculative execution이 증가해 성능 저하를 유발한다.
- 데이터를 로딩할 때 스파크는 데이터 크기에 맞게 자동으로 적절한 파티션 개수를 설정한다.
- 이후 narrow 변환 함수만 실행되면 파티션 개수에는 변함이 없으며, Join, GroupBy와 같이 데이터 셔플을 유발하는 wide 함수가 실행되면 200개로 재설정된다.
- 예) Filter 변환 함수 → 데이터 분포가 편향될 수 있음 → 파티셔닝 방법을 사용하여 고른 데이터 분포를 갖도록 한다.
repartition(): 파티션 개수를 줄이거나 늘릴 때 사용coalesce(): 파티션 개수를 줄일 때 사용 (데이터 셔플이 일어나지 않는다.)partitionBy(): 디스크 파티셔닝- repartition 계열의 함수는 해시를 기반으로 데이터를 분배한다.
- salting 기법 → 기준이 되는 새로운 컬럼을 인위적으로 생성해 데이터를 정확히 균등하게 분배한다.
✅ 캐싱
- RDD를 캐싱하면 이후에 실행되는 액션 함수는 재평가 없이 재사용할 수 있다.
- 같은 RDD 또는 DataFrame에 반복되는 액션 함수를 실행시킬 때 유용하다.
- RDD →
persist/ DataFrame →cache - persist는 스토리지 레벨에 따라 캐싱할 수 있다는 장점이 있다.
✅ 브로드캐스팅
- 브로드캐스트 변소는 모든 작업 노드들이 접근할 수 있는 공유 변수이다.
- 예) 작은 DataFrame과 큰 DataFrame을 조인하려고 할 때, 작은 DataFrame을 브로드캐스팅한다면 셔플 연산이 없이 조인을 할 수 있다.
✅ 그 외
- RDD.collect() 메서드를 호출하면 분산되어 있던 모든 데이터를 드라이버 프로세스로 보내게 되는데, 이는 메모리 에러가 발생할 확률이 높고 분산의 장점을 활용하지 못한다. 따라서
take또는takeSample메서드를 사용하거나필터링하여 데이터의 일부만 가져올 수 있다. - 데이터 처리 단위에 따라
디렉토리 구성을 세밀하게 해야 할 필요가 있다.
[출처]

DCDI