😎 Spark SQL이 편리한 이유!
- 사용하는 데이터 포맷이 parquet이고, SQL만으로 처리할 수 있는 경우 schema에 매핑되는 클래스를 정의할 필요가 없다.
- Spark SQL에서는 Catalyst Optimizer가 최적화를 대신해준다.
- DataFrame은 Untyped Data인 Row를 사용하기 때문에 연산에 제한이 있었지만, Dataset은 Typed Data로 변환하여 처리하기 때문에 DataFrame보다 좀 더 복잡한 연산이 가능하다.
😮 Catalyst Optimizer
Spark SQL을 구현하기 위해 확장 가능한 옵티마이저인 카탈리스트가 구현되었다.
🧚♀️ 카탈리스트의 확장 가능한 설계의 목적
- Spark SQL에 새로운 최적화 요소나 기술 추가를 쉽게 할 수 있게 하기
- 외부 개발자들이 Optimizer를 확장시키는 것을 가능하게 하기
🌳 Trees
- 카탈리스트를 구성하는 주요 데이터 타입은 node object로 구성된 tree이다.
- Node 타입의 속성
- TreeNode 클래스를 상속 받는다.
- 0개 이상의 자식을 가질 수 있다.
- immutable
- tansformation 함수를 통해 만들어진다.
- 트리 형태로 표현한 expression (예시)
-
Add(Attribute(x), Add(Literal(1), Literal(2)))
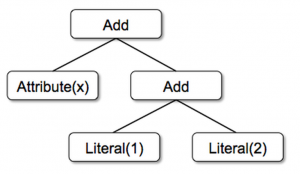
-
SELECT sum(v)
FROM (
SELECT
t1.id,
1 + 2 + t1.value AS v
FROM t1 JOIN t2
WHERE
t1.id = t2.id AND
t2.id > 50000) tmp- Expression
- 입력 값에 의해 계산되는 새로운 값
1 + 2 + t1.value,t1.id = t2.id(boolean)
- Attribute
- Dataset의 컬럼 혹은 데이터 연산에 의해 새롭게 생성된 컬럼
t1.id,v
- Query Plan
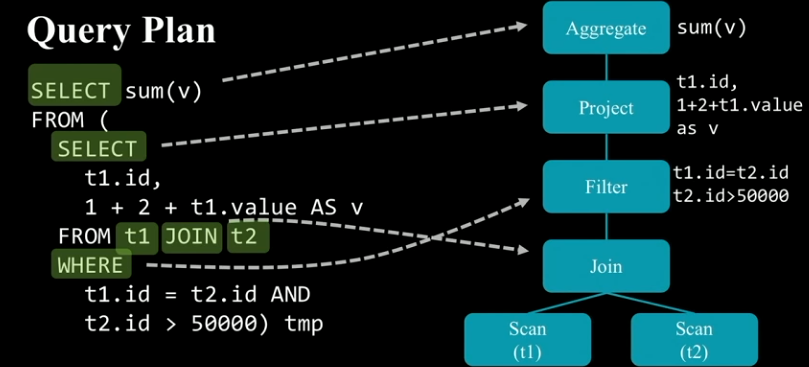
- Input Dataset에 적용하여 새로운 Dataset을 생성해내는 연산을 의미한다.
- Aggregate, Join, Filter 등
- Logical Planning 단계에서 Tree는 Logical Plan과 Expression으로 구성된다.
- Physical Planning 단계에서는 TreeNode를 사용하지 않는다.
📏 Rules
- 새로운 Tree는 Tree를 다른 Tree로 변경(transformation)하는 Rule을 생성할 수 있다.
- Rule을 통해 입력으로 들어온 Tree 전체를 변환할 수도 있지만, 특정 구조를 가진 Sub Tree를 찾아 변경하는 Pattern Matching Set을 적용하는 방식이 일반적이다.
- Catalyst에서 Tree는 하위 모든 노드에 재귀적으로 Pattern Matching 함수를 수행하는 transform 함수를 제공한다.
- 아래와 같이 두 개의 상수를 더하는 Add Operation을 하나의 Literal로 Fold하는 Rule을 구현할 수 있다.
tree.transform { case Add(Literal(c1), Literal(c2)) => Literal(c1+c2) }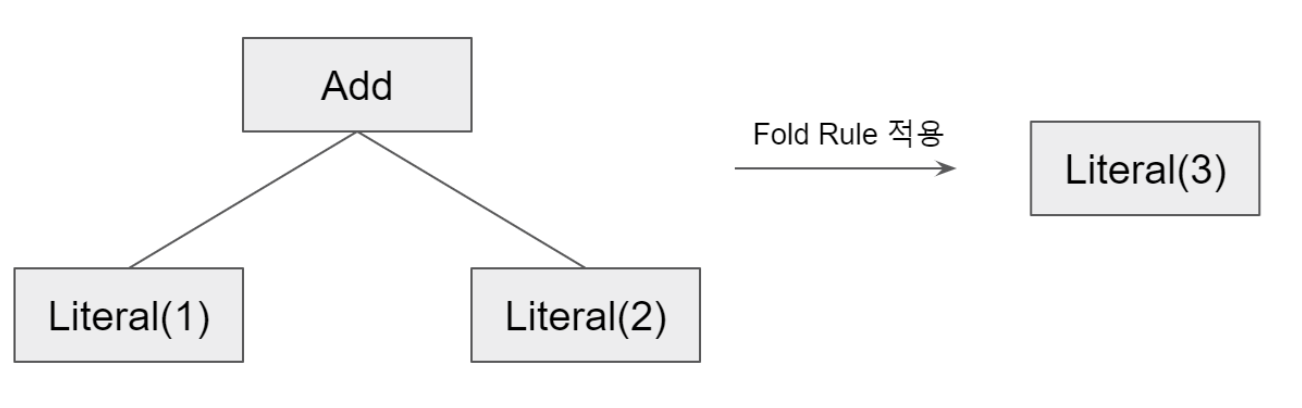
- Catalyst의 Rule은 Optimization이 필요한 Tree에 대해서만 적용되고 그렇지 않는 Tree에 대해서는 적용되지 않는다.
- Rule은 동일한 Transform 호출 내에서 여러 개의 패턴과 일치할 수 있기 때문에, 여러 Transform을 호출하지 않고 한번에 처리할 수 있도록 패턴을 정확히 구현하는 것이 중요하다.
👉 Tree를 완전히 Transform 하기 위해서는 Rule이 여러 번 적용되어야 할 수 있다. Catalyst는 Rule을 Batch라는 단계로 묶고, 각 Batch를 Tree가 Rule을 적용해도 변경되지 않은 지점인 Fixed Point까지 반복해서 실행한다.
🎨 Spark SQL에서 카탈리스트 사용하기!
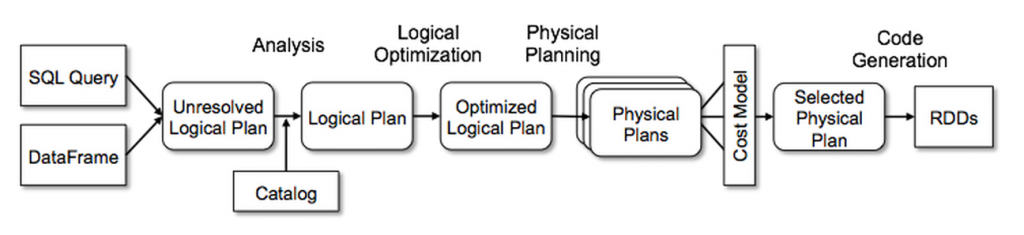
- Catalyst에서는 4개 부분으로 나누어 Tree에 Transformation을 수행한다.
- Analysis
- Logical Plan Optimization
- Physical Planning
- Code Generation
1️⃣ Analysis
- Spark SQL은 SQL Parser에서 반환한 Abstract Syntax Tree(AST) 혹은 Dataframe 객체의 Relation을 계산(연산)하는 것으로부터 시작된다.
- Spark SQL은 Catalyst Rule과 Catalog object(Data source의 모든 Table을 Tracking하는 객체)을 이용하여 Attribute를 분석한다. (컬럼의 타입, 컬럼 이름이 valid한지 등)
2️⃣ Logical Plan Optimization
- Logical Plan에 Rule 기반 Optimization을 적용한다.
- Rule Based Optimization
Constant Folding: 상수 표현식을 Runtime Time에 계산하지 않고 Compile Time에 미리 계산해버리는 방법. 처리 속도를 높일 수 있다.Predicate Pushdown: 쿼리 밖에 있는 조건절을 쿼리 안쪽으로 넣는 방법. 불필요한 연산을 줄일 수 있다.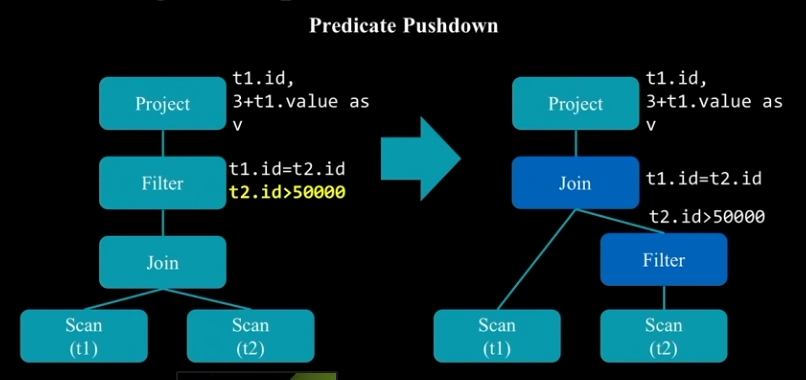
Projection Pruning: 연산에 필요한 컬럼만을 가져오는 기법. 필요한 컬럼만을 project하므로 성능이 개선된다.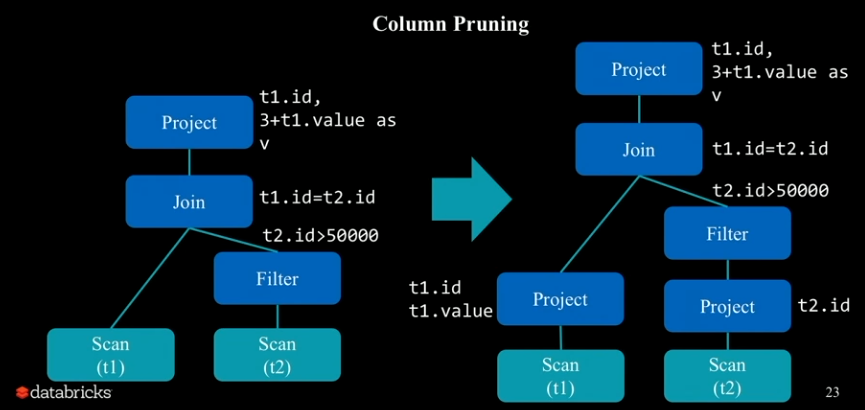
Null PropagationBoolean Expression Simplification
3️⃣ Physical Planning
- Logical Plan을 이용하여 1개 이상의 Physical Plan을 만들어낸다.
- Cost Based Optimization이나 Spark Operation 관련 Optimization을 진행한다.
4️⃣ Code Generation
- 만들어진 Plan을 각 장비에서 실행시킬 수 있도록 Java Byte Code로 변환한다.

DCDI