
1. Elastic Search
- Apache Lucene(아파치 루씬) 기반의 Java 오픈소스 분산 검색 엔진
- Elasticsearch를 통해 루씬 라이브러리를 단독으로 사용할 수 있게 됨
- 방대한 양의 데이터를 신속하게, 거의 실시간( NRT, Near Real Time )으로 저장, 검색, 분석할 수 있음
- 검색을 위해 단독으로 사용되기도 하며, ELK( Elasticsearch / Logstatsh / Kibana )스택으로 사용되기도 함
- 출처 https://victorydntmd.tistory.com/308
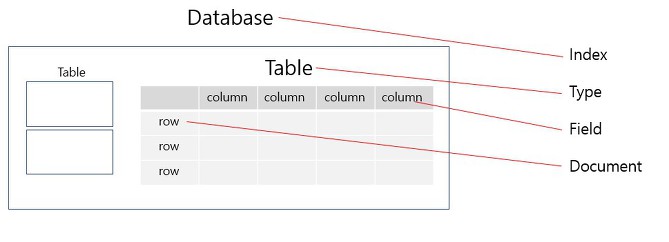
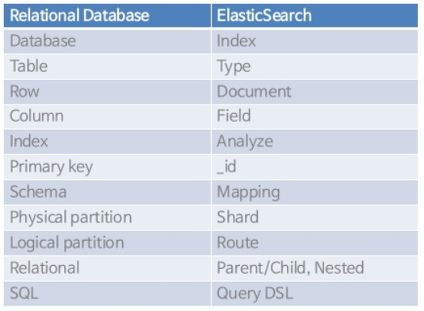
1-1. 관계형 DB 비교
- 관계형 DB는 Elasticsearch에서 각각 다음과 같이 대응시킬 수 있음
1-2. 아키텍처/용어 정리
- 클러스터(cluseter), 노드(node)
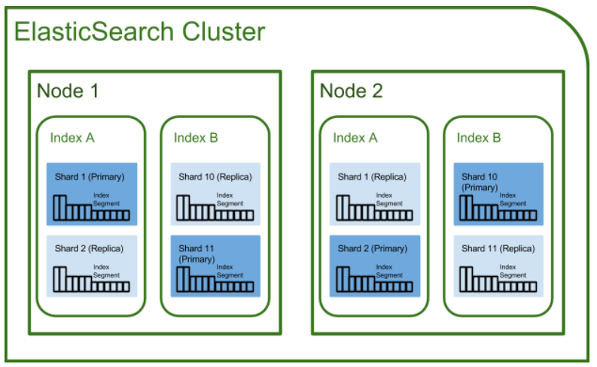
1-2-1. 클러스터(cluseter)
- 가장 큰 시스템 단위로, 최소 하나 이상의 노드로 이루어진 노드들의 집합
- 서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지됨
- 여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재할 수도 있음
1-2-2. 노드(node)
- Elasticsearch를 구성하는 하나의 단위 프로세스
- 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분
- master-eligible node(링크) : 클러스터를 제어하는 마스터로 선택할 수 있는 노드
- master-eligible node 역할 : 인덱스 생성, 삭제 / 클러스터 노드들의 추적, 관리 / 데이터 입력 시 어느 샤드에 할당할 것인지 결정
- Data node(링크) : 데이터와 관련된 CRUD 작업과 관련있는 노드 / CPU, 메모리 등 자원을 많이 소모하므로 모니터링이 필요 / master 노드와 분리되는 것이 좋음
- Ingest node(링크) : 데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할
- Coordination only node(링크) : data node와 master-eligible node의 일을 대신하는 노드 / 대규모 클러스터에서 큰 이점이 있음 / 로드밸런서와 비슷한 역할
1-2-3. 인덱스(Index)
- RDBMS에서 database와 대응하는 개념
- shard와 replica는 Elasticsearch에만 존재하는 개념이 아니라, 분산 데이터베이스 시스템에도 존재하는 개념
1-2-4. 샤드(Shard)
- 데이터를 분산해서 저장하는 방법
- Elasticsearch에서 스케일 아웃을 위해 index를 여러 shard로 쪼갠 것
- 기본적으로 1개가 존재하며, 검색 성능 향상을 위해 클러스터의 샤드 갯수를 조정하는 튜닝을 하기도 함
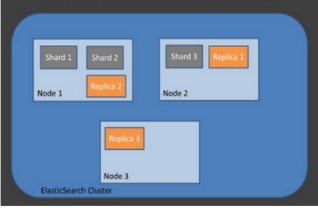
1-2-5. 복제(Replica)
- 또 다른 형태의 shard라고 할 수 있음
- 노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드들을 복제하는 것
- 따라서 replica는 서로 다른 노드에 존재할 것을 권장
- 아래 사진에서 보는 바와 같이 Replica1은 Node2에 존재하는 것을 확인할 수 있음
1-3. 사용 예제

개린이