1935_후위 표기식2
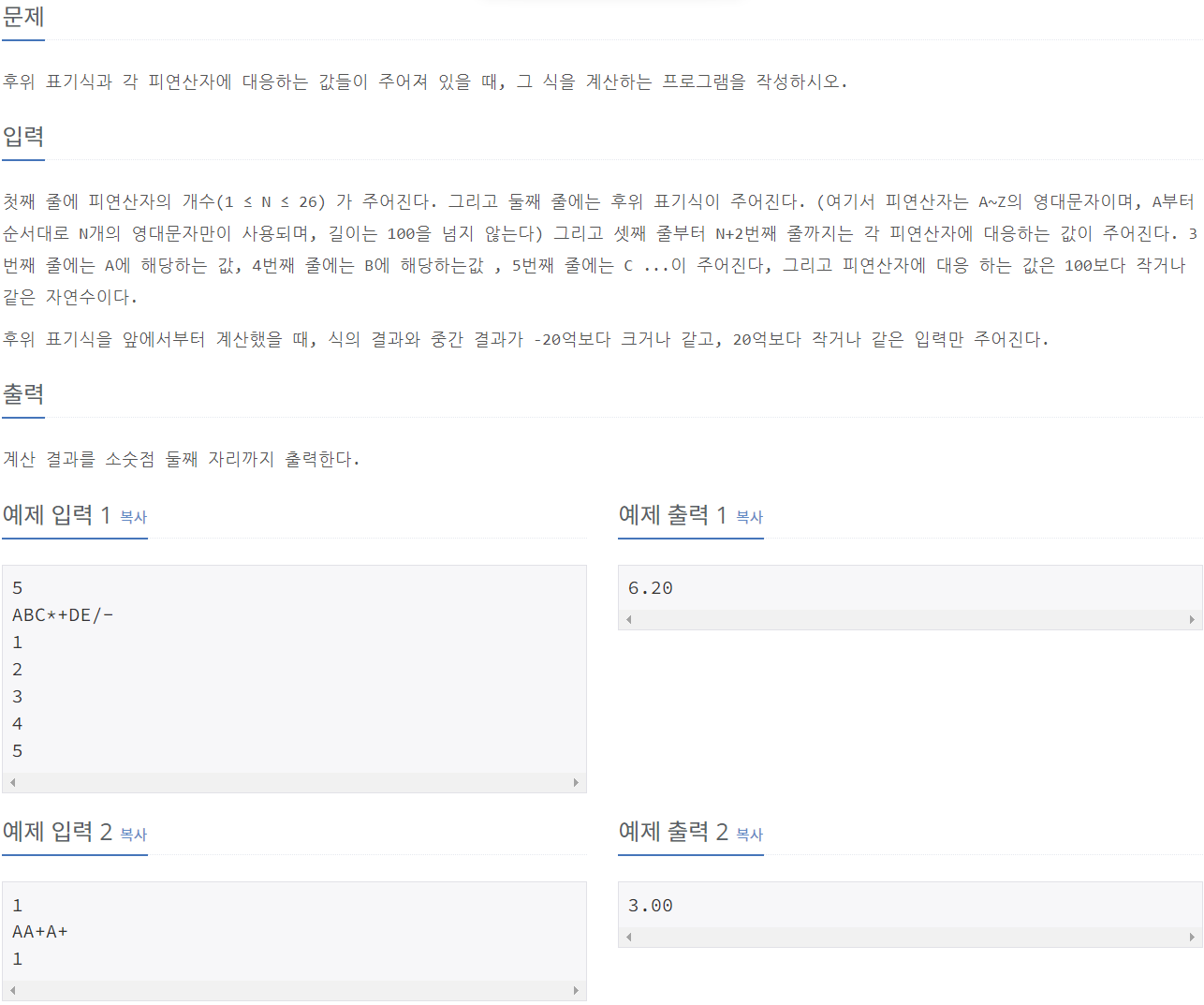
⭕풀이:
test_case = int(input()) #문자열의 갯수 = 문자열에 주어질 입력값 반복 횟수
expression = input() #수식 입력
num_list = [0] * test_case #입력된 A,B,C,..값을 num_list에 순서대로 넣어두기 위해 0으로 공백을 채워 [0, 0, 0,..]의 형태로 만들어 둔다.
for i in range(test_case):
num_list[i] = int(input()) #num_list는 세번째열부터 입력되는 A,B,C,..의 입력값들을 넣어둔다.
stack = [] #
for i in expression: #수식을 하나하나씩 i에 대입해 피연산자인지 연산자인지(알파벳(숫자)인지 연산기호인지) 검사한다.
if i.isalpha(): #i가 알파벳인 피연산자일 경우,
stack.append(num_list[ord(i) - ord('A')]) #num_list에 있는 요소값들은 [A, B, C,..]로, expression에 나올 알파벳 또한 순서대로 나올 것이기 때문에 알파벳의 순서처럼 배열되어 있는 아스키코드를 이용해 해당 알파벳, i번째 알파벳을 정수로 변환하고, 이를 아스키코드(A)로 값을 뺀 경우 0, 1, 2 가 되므로 num_list의 요소값들(A, B, C,..)을 stack 리스트에 차례대로 넣을 수 있다.
else: #i가 연산기호인 연산자일 경우,
str2 = stack.pop() #str2는 차례대로 입력된 알파벳의 값에서 마지막에 있을 값이고,
str1 = stack.pop() #str1은 차례대로 입려된 알파벳의 값에서 (마지막을 뺐으니) 2번째로 마지막에 있을 값이 된다.
if i == "+":
stack.append(str1 + str2)
elif i == "-":
stack.append(str1 - str2)
elif i == "*":
stack.append(str1 * str2)
elif i == "/":
stack.append(str1 / str2)
print('%.2f' %stack[0]) #소수 2째 자리에서 반올림해라.
📌필요지식
1) format(%f)
- 실수를 출력하는 방법은 아래와 같습니다.

1918_후위 표기식
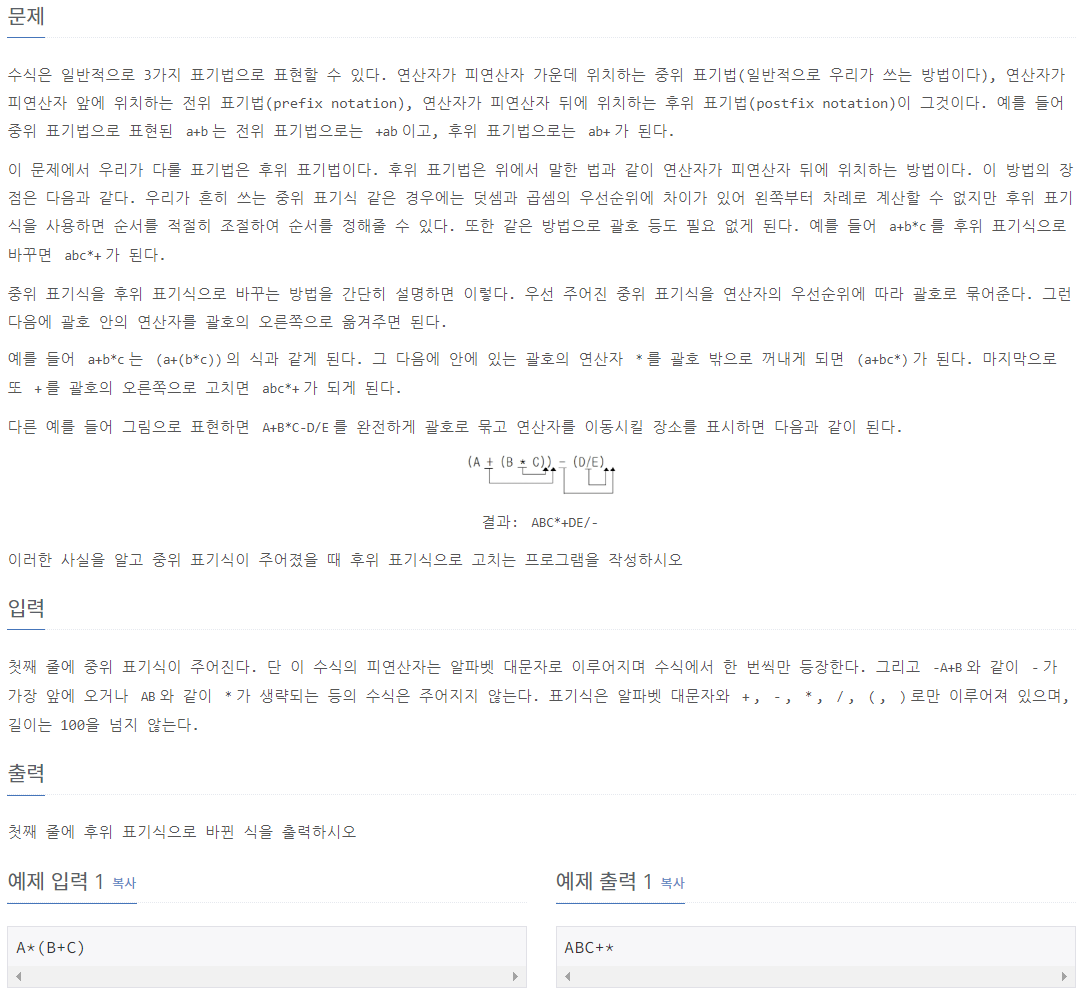
⭕풀이:
expression = list(input()) #수식 입력
stack = [] #
ans = ""
for i in expression:
if i.isalpha(): #수식에서 문자열이 알파벳이 나올 경우,
ans += i #비어있는 변수 i에 문자열을 더해 수식에 있는 문자열들을 띄어쓰기 없이 붙여 쓸 수 있다.
else: #수식에서 문자열이 연산자 혹은 괄호일 경우,
if i == '(': #여는 괄호라면,
stack.append(i) #stack에 넣는다.
elif i == "*" or i == "/": #"*"나 "/"연산자이면,
while stack and (stack[-1] == "*" or stack[-1] == "/"): #stack에 요소값이 있고, stack의 마지막 값도 "*"나 "/"연산자라면, 계속해서
ans += stack.pop() #ans변수에 stack의 마지막 요소값인 "*" or "/" 연산자를 빼고, ans에 붙여쓴다.
stack.append(i) #해당 연산자 "*" or "/"를 stack에 넣는다.
elif i == "+" or i == "-": #"+"나 "-"연산자이면,
while stack and (stack[-1]) != "(": #stack에 요소값이 있고, stack의 마지막 값도 "+"나 "-"연산자가 아니라면, 계속해서
ans += stack.pop() #ans변수에 stack의 마지막 요소값인 "*" or "/" 연산자를 빼고, ans에 붙여쓴다.
stack.append(i) #해당 연산자 "*" or "/"를 stack에 넣는다.
elif i == ")": #")"닫는 괄호라면,
while stack and stack[-1] != "(": #stack에 요소값이 있고, stack의 마지막 요소값도 "("여는 괄호가 아니라면, 계속해서
ans += stack.pop() #ans변수에 stack의 마지막 요소값인 ")"닫는 괄호를 빼고, ans에 붙여쓴다.
stack.pop() #stack의 마지막 값을 제거한다.
while stack:
ans += stack.pop()
print(ans)10808_알파벳 개수
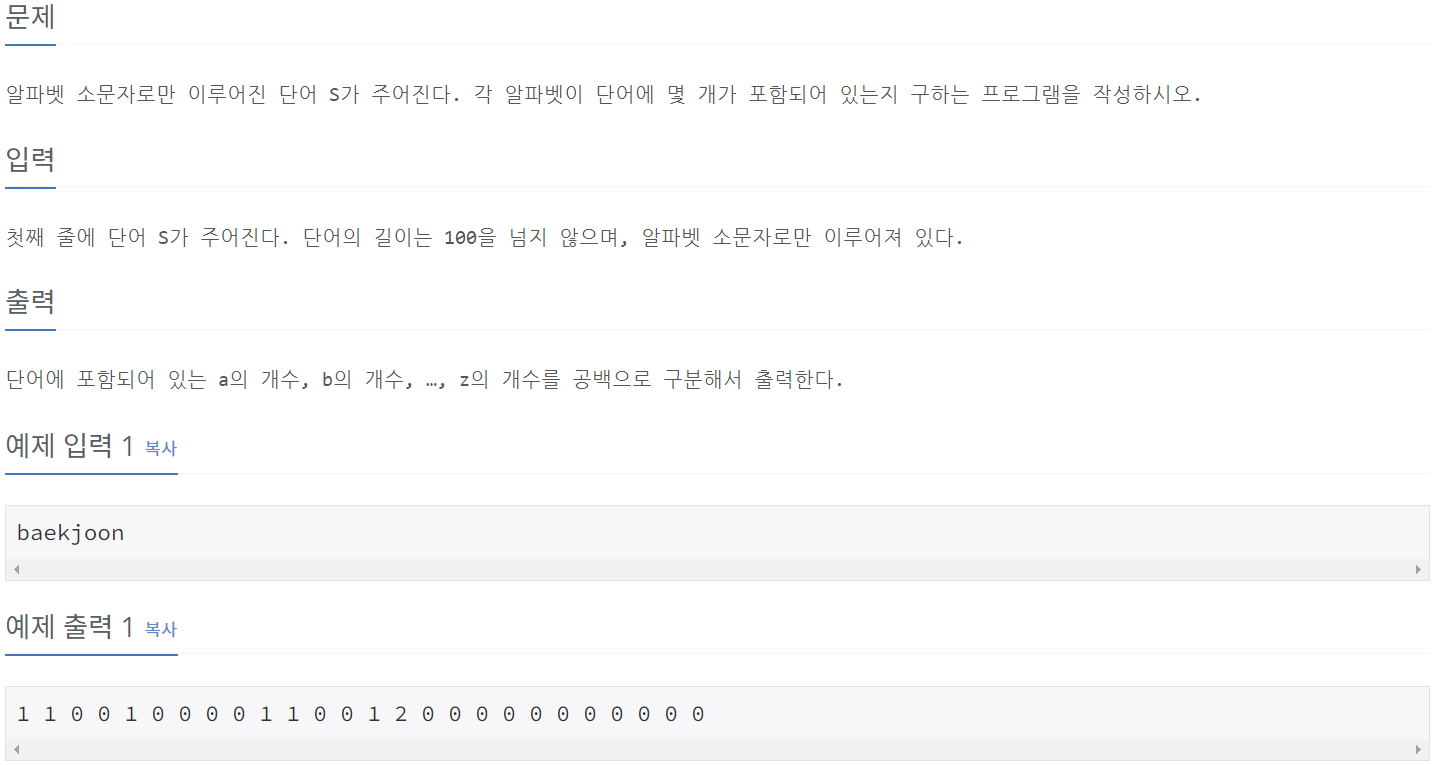
⭕풀이:
S = input()
alphabet_list = [0] * 26
for i in S:
alphabet_list[ord(i) - ord('a')] += 1
print(*alphabet_list)10809_알파벳 찾기
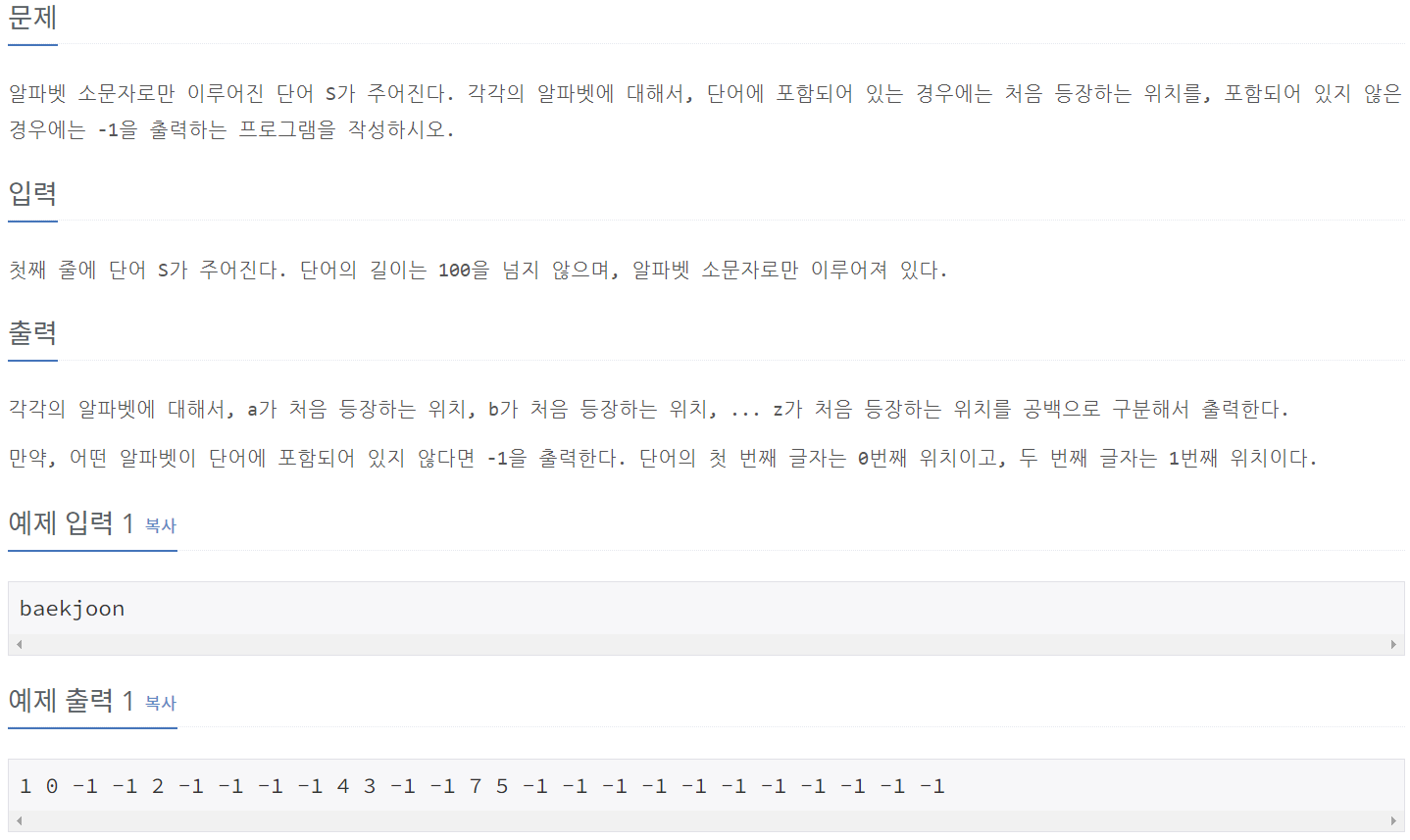
⭕풀이:
S = input()
alphabet_list = list(range(97, 123))
for i in alphabet_list:
print(S.find(chr(i)), end=" ")📌필요지식
1) find
- find함수는 "찾을 문자" 혹은 "찾을 문자열"이 존재하는지 확인하고,
찾는 문자가 존재한다면 해당 위치의 index값을 반환해주고,
찾는 문자가 존재하지 않는다면 -1을 반환합니다.
만약, 찾는 문자나 문자열이 여러 개 있다면 맨 처음 문자의 index를 반환하게 됩니다.

2) find와 index의 차이점
2-1) find()
- 찾는 문자가 없는 경우에 -1을 출력합니다.
문자열을 찾을 수 있는 변수는 문자열만 사용이 가능합니다. 리스트, 튜플, 딕셔너리 자료형에서는 find함수를 사용할 수 없습니다. 만일 사용하게 되면 AttributeError 에러가 발생합니다.
2-2) index()
- 찾는 문자가 없는 경우에 ValueError 에러가 발생합니다.
문자열, 리스트, 튜플 자료형에서 사용 가능하고 딕셔너리 자료형에는 사용할 수 없어 AttributeError 에러가 발생합니다.

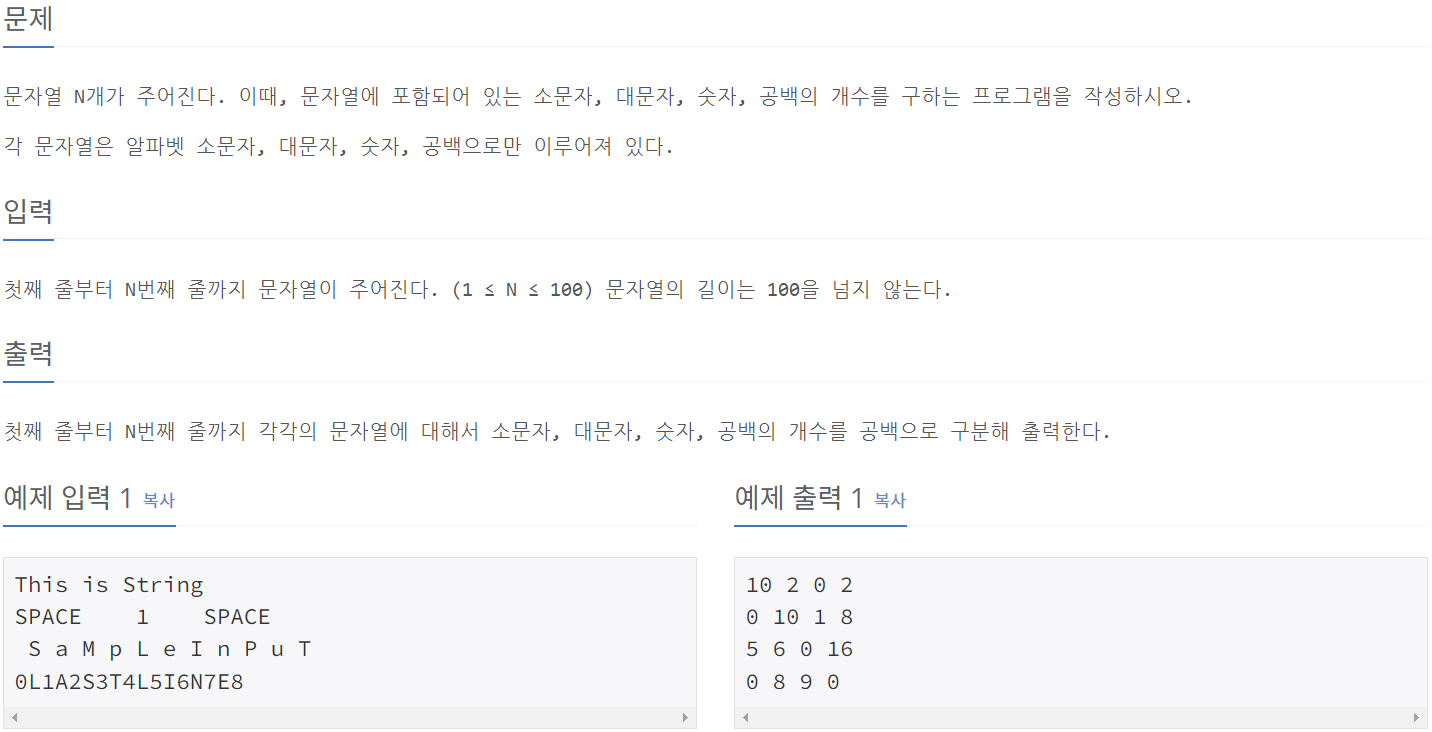
10820_문자열 분석
⭕풀이:
import sys
while True:
s = sys.stdin.readline().rstrip('\n')
if not s:
break
lower, upper, digit, blank = 0, 0, 0, 0
for i in range(len(s)):
if s[i].islower():
lower += 1
elif s[i].isupper():
upper += 1
elif s[i].isdigit():
digit += 1
else:
blank += 1
print(lower, upper, digit, blank)
📌필요지식
1) islower(), isupper(), isdigit()
1-1) islower()
문자열.islower()는 해당 문자열이 모두 소문자이면True를 리턴하고, 그렇지 않으면False를 리턴합니다.
1-2) isupper()
문자열.isupper()는 해당 문자열이 모두 대문자이면True를 리턴하고, 그렇지 않으면False를 리턴합니다.
1-3) isdigit()
문자열.isdigit()는 해당 문자열이 모두 숫자이면True를 리턴하고, 그렇지 않으면False를 리턴합니다.
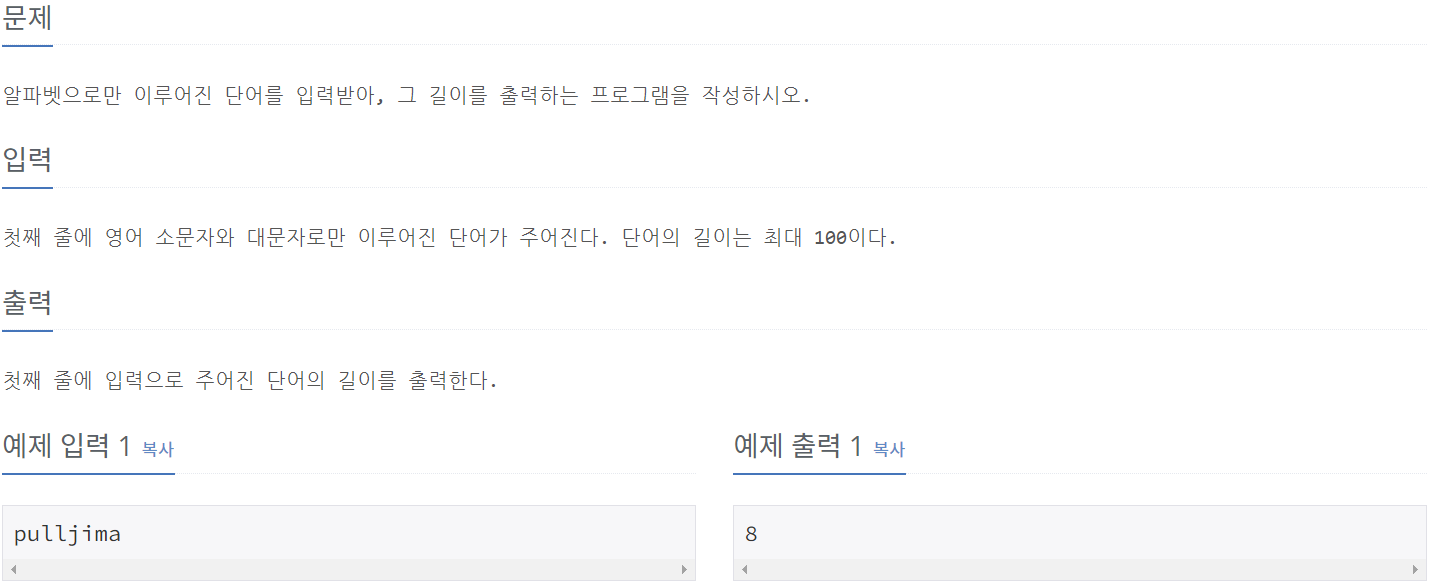
2743_단어 길이 재기
⭕풀이:
word = list(input())
print(len(word))
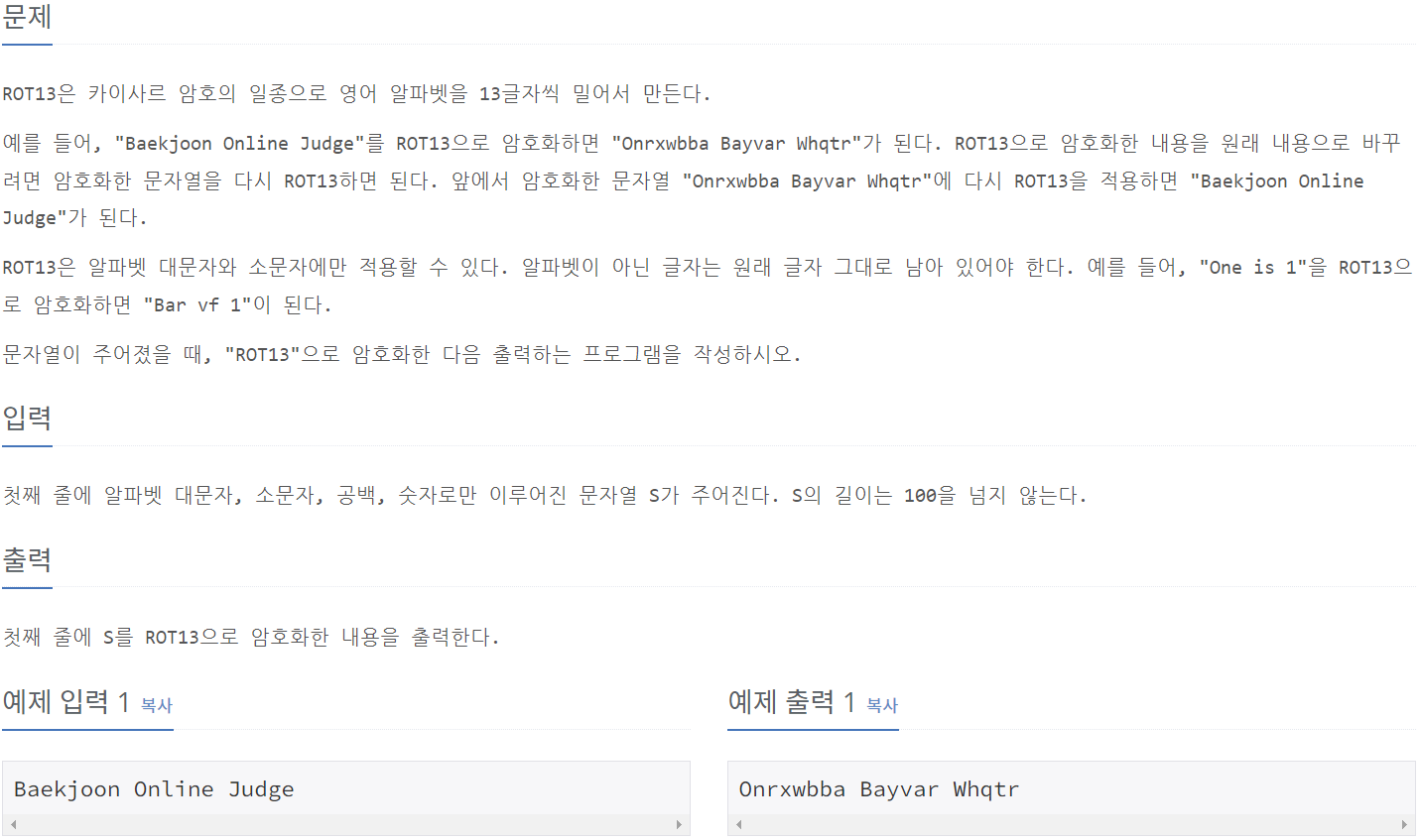
11655_ROR13
⭕풀이:
word = list(input())
answer = ""
for i in word:
if i.isupper():
i = ord(i) + 13
if i > 90:
i -= 26
answer += chr(i)
elif i.islower():
i = ord(i) + 13
if i > 122:
i -= 26
answer += chr(i)
else:
answer += i
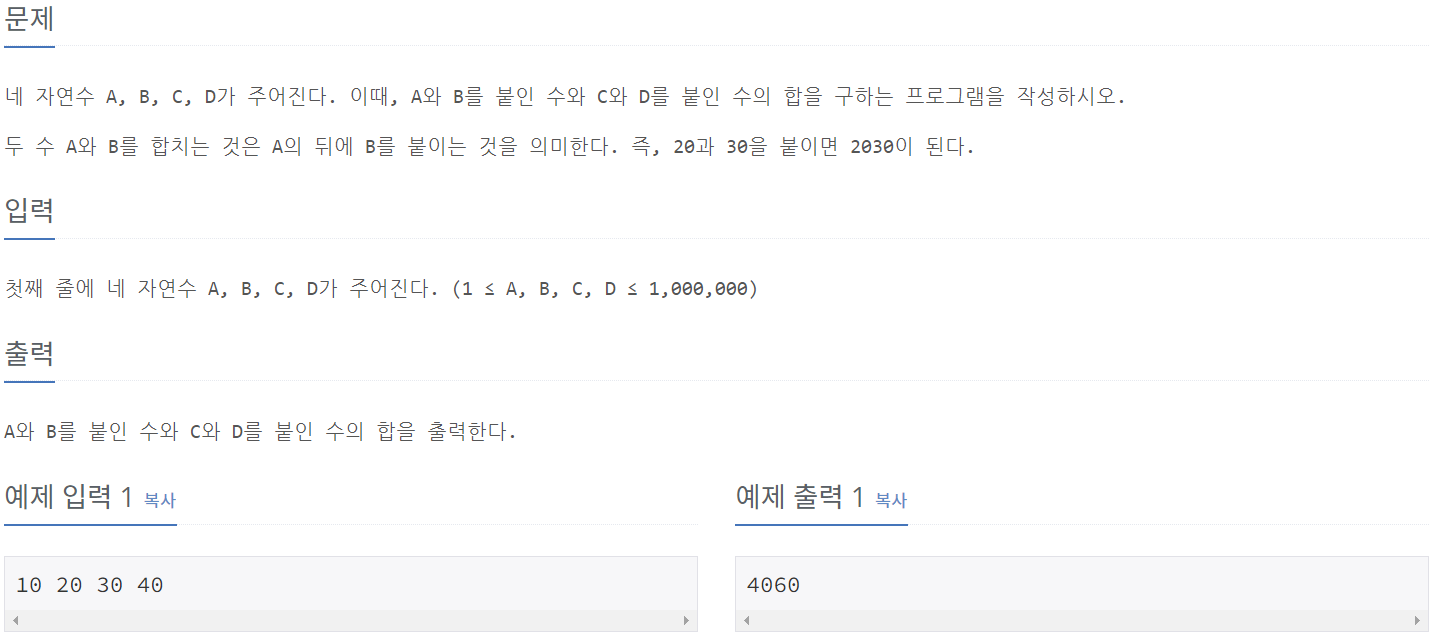
print(answer)10824_네 수
⭕풀이:
A, B, C, D = input().split()
sumAB = str(A) + str(B)
sumCD = str(C) + str(D)
print(int(sumAB) + int(sumCD))11656_접미사 배열
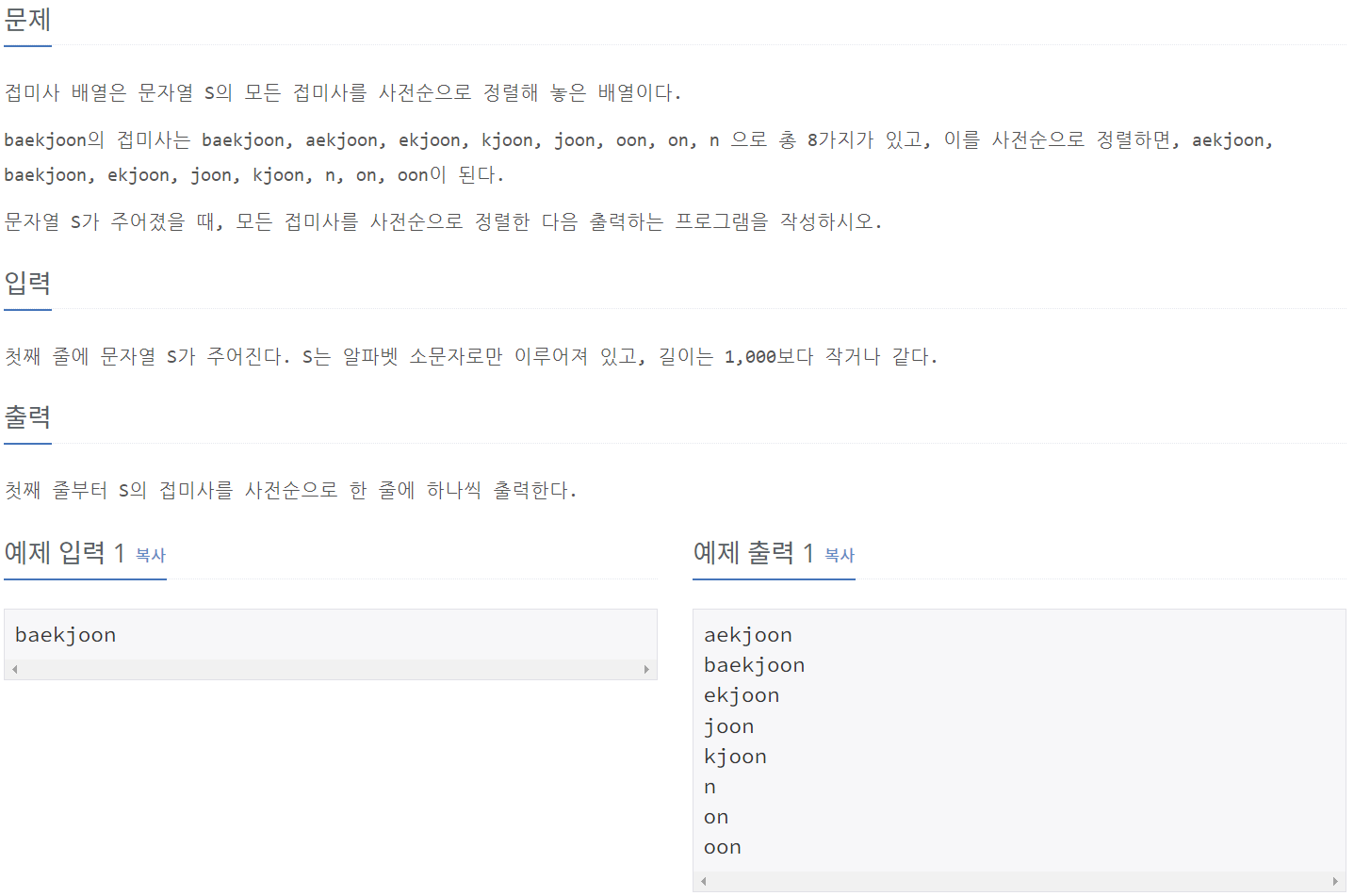
⭕풀이:
word = input()
word_list = []
for _ in word:
word_list.append(word)
word = word[1:]
for i in sorted(word_list):
print(i)
타이밀크티는 맛있습니다.