2750_수 정렬하기
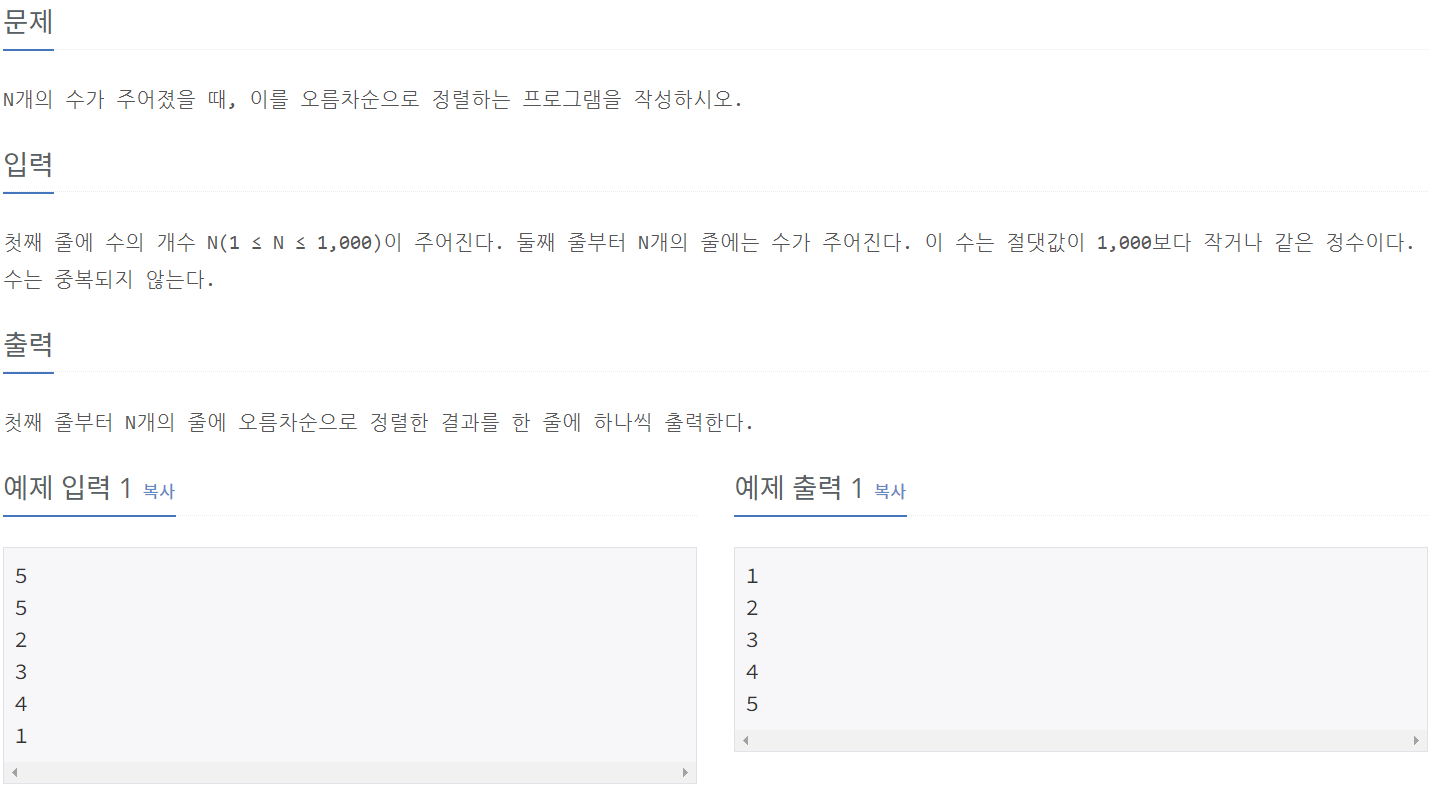
⭕풀이:
test_case = int(input())
num_list = [] #입력된 값들을 담을 비어있는 리스트
for _ in range(test_case):
num = int(input())
num_list.append(num) #입력된 값들을 미리 만들어둔 num_list에 넣는다.
num_list.sort() #num_list에 있는 값들을 리스트 내에서 오름차순으로 정렬한다.
for i in num_list: #하나씩 반복해 출력
print(i)
📌필요지식
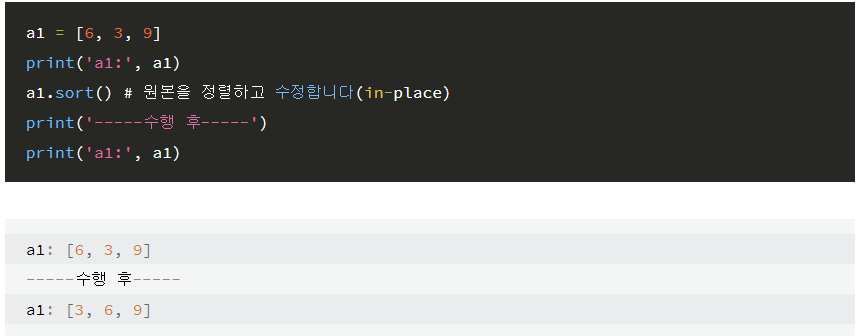
1) sort vs sorted 차이점
-
sort함수는
리스트명.sort()
형식으로 "리스트형의 메소드"이며 리스트 원본값을 직접 수정합니다.
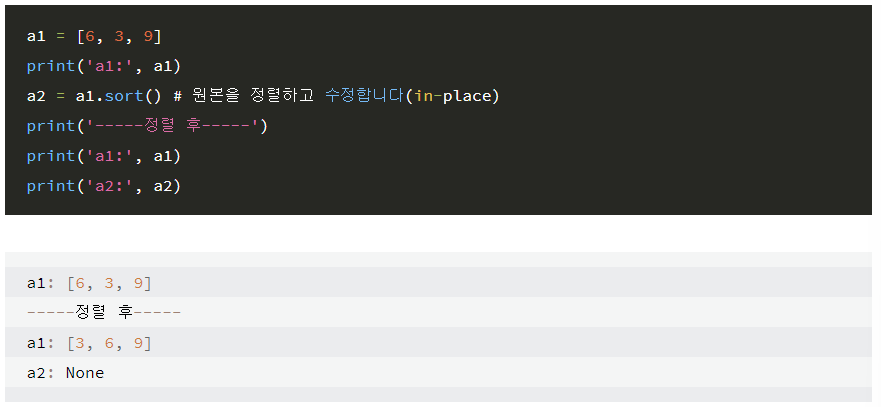
-
sorted함수는
sorted(리스트명)
형식으로 "내장 함수"이며 리스트 원본 값은 그대로이고 정렬 값만 반환합니다.

2587_대표값2
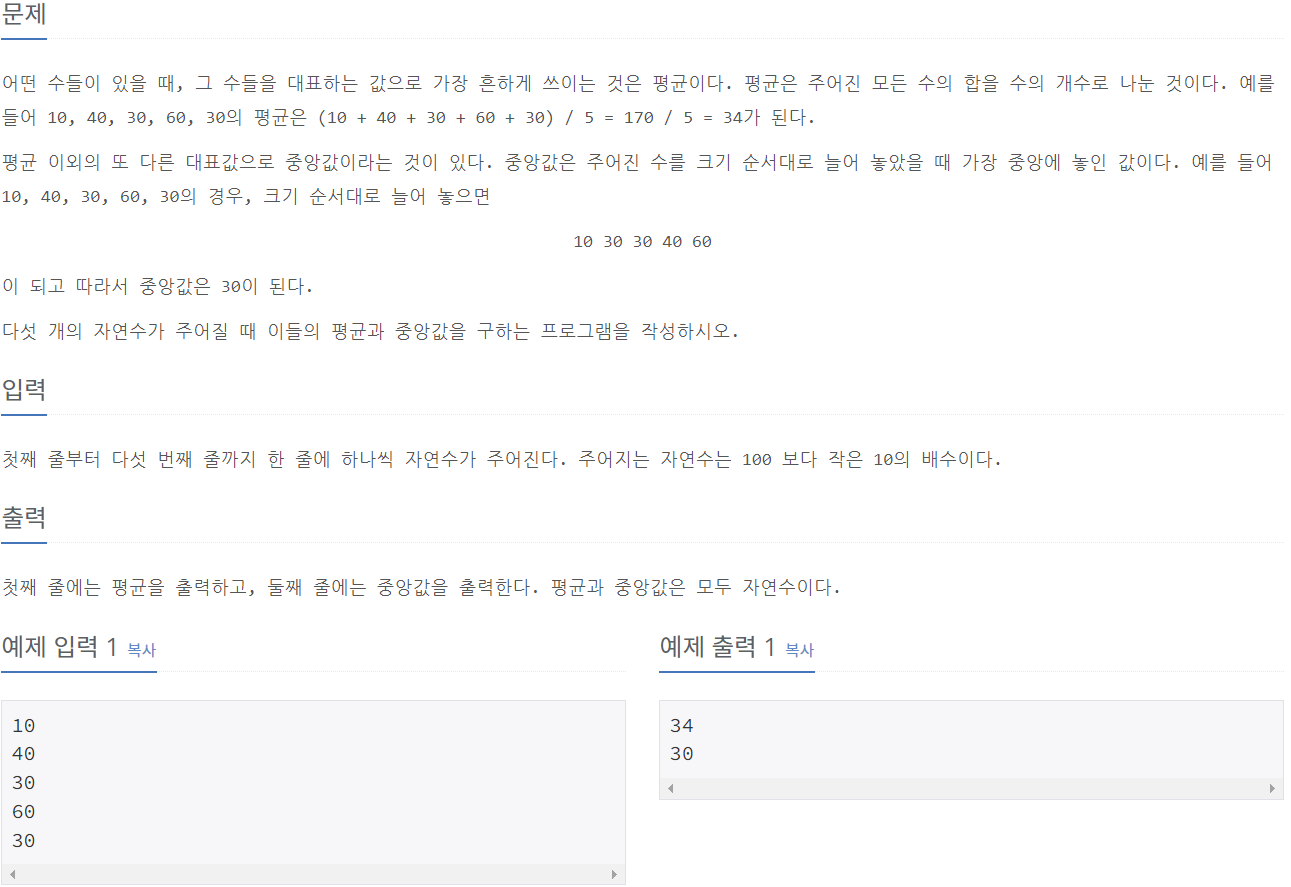
⭕풀이:
num_list = []
for _ in range(5):
num = int(input())
num_list.append(num)
num_list.sort()
average = sum(num_list) // len(num_list)
print(average, num_list[2])
25305_커트라인
⭕풀이:
N, k = map(int, input().split())
score = list(map(int, input().split()))
score.sort(reverse=True) #score리스트를 원본 값에서 역정렬해라.
print(score[k-1])
📌필요지식
1)리스트 정렬, 역정렬, 역순
-
리스트 정렬
리스트.sort()

-
리스트 역정렬
리스트.sort(reverse=True)

-
리스트 역순
리스트.reverse()
2751_수 정렬하기 2
⭕풀이:
test_case = int(input())
num_list = [] #입력된 값들을 담을 비어있는 리스트
for _ in range(test_case):
num = int(input())
num_list.append(num) #입력된 값들을 미리 만들어둔 num_list에 넣는다.
num_list.sort() #num_list에 있는 값들을 리스트 내에서 오름차순으로 정렬한다.
for i in num_list: #하나씩 반복해 출력
print(i)
📌풀이설명
- 위 문제를 풀었을 때, 아래 코드로 python으로 실행했을 시, 시간초과로인해 실패했습니다.
pypy는python으로 만든 언어여서 파이썬에서 돌아가면pypy에서도 돌아가 코드 전환상에는 문제가 없으며 또한, 속도가 더 빠르다는 장점이있습니다.
10989_수 정렬하기 3
⭕풀이:
import sys
N = int(sys.stdin.readline()) #주어진 입력값을 N에 부여한다.
nums = []
result = [0 for _ in range(10001)] #0, 0, 0, 0... 0 의 리스트를 result에 부여한다.
for i in range(N):
num = int(sys.stdin.readline())
result[num] += 1 #만약 N이 4이고, 입력된 값이 3,2,1,5면, result는 [0, 0, 0, 0, 0, 0, 0, 0...]에서 -> [0, 1, 1, 1, 0, 1, 0, 0...]이 된다. 이 과정을 통해 result 리스트가 010101100과 같은 형식을 통해 1부터 10000까지 어떤 숫자를 몇번 가지고 있는지 알 수가 있고, 순서는 저절로 오름차순이 된다.
for i in range(len(result)): #0 ~ result의 길이만큼 i에 넣어 반복해라.
if result[i] != 0: #result의 i번째에 있는 값이 0이 아니라면,
for _ in range(result[i]): #result의 i값만큼 i를 반복 출력해라.(= i자리에 i의 값이 존재하기 때문에 처음에 순서와는 상관이 없다.)
print(i)
2108_통계학
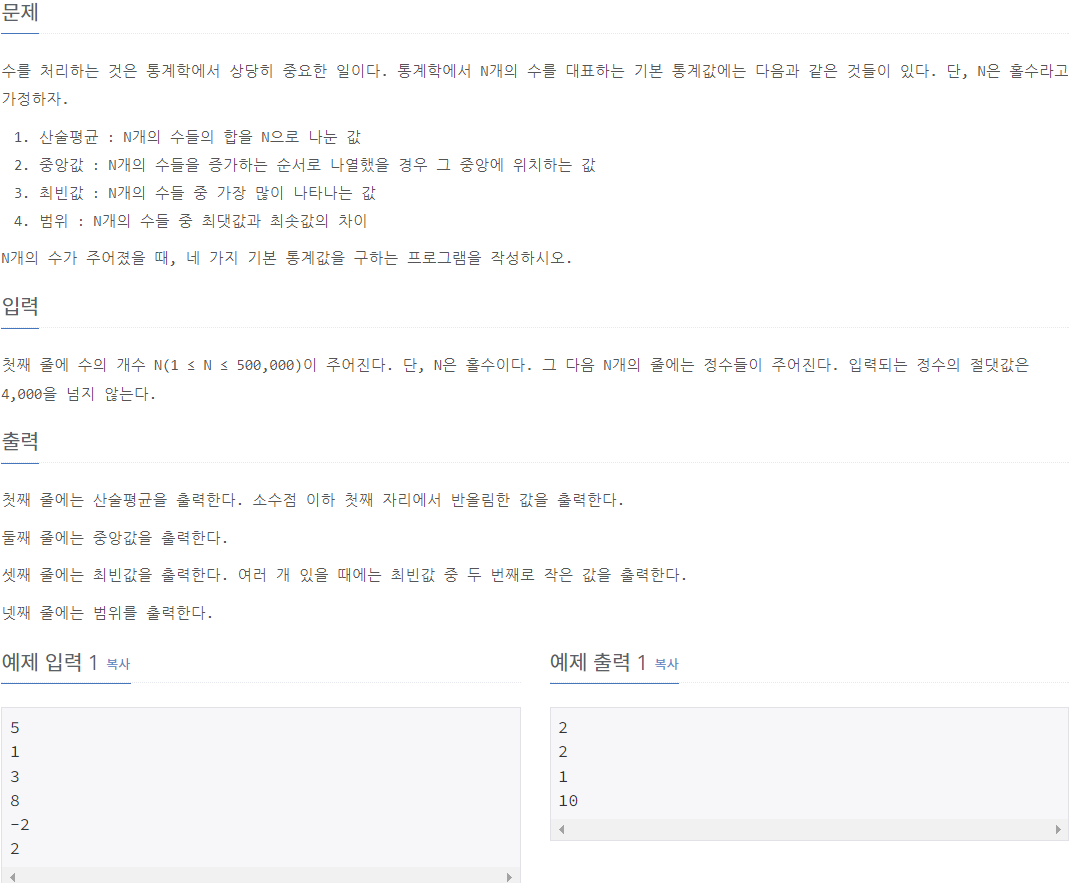
⭕풀이:
import sys
from collections import Counter #sys와 collections의 Counter모듈을 임포트해준다.
test_case = int(sys.stdin.readline()) #몇 개의 입력값들을 줄 것인지 입력할 변수를 선언한다.(홀수 값으로)
num_list = [] #test_case값을 제외한 입력값들을 담을 비어있는 리스트를 만들어 둔다.
for _ in range(test_case):
num_list.append(int(sys.stdin.readline())) #test_case의 값만큼 입력되고, 입력된 값들을 num_list에 넣는다.
print(round(sum(num_list)/test_case)) #산술평균 구하기, sum(num_list)로 입력값들의 총합을 구하고, test_case의 값인 숫자들의 갯수만큼 나눈 뒤, round()를 통해 소수 첫번째자리까지 반올림한다.산술평균 구하기
print(sorted(num_list)[len(num_list)//2]) #중앙값 구하기, 오름차순으로 정렬된 num_list에서 num_list의 길이(=숫자들의 갯수)를 2로 나눈 몫의 정수번째에 있는 값을 구한다.
count = Counter(num_list) #collection 모듈을 사용해 빈도 수를 구해주는 함수 Counter()를 이용해 num_list의 숫자들의 빈도수를 구해 count를 Counter({숫자: 빈도수, 숫자: 빈도수..})의 형태로 변수선언한다.
order = count.most_common() #딕셔너리 형태[(숫자: 빈도수), (숫자: 빈도수),..}로 빈도수가 많은 순서대로 숫자와 빈도수가 배열되게 한다.
max_frequency = order[0][1] #그러므로 order딕셔너리에서 제일 앞에 있는 최대 빈도수를 가진 숫자의 최대 빈도수를 max_frequeny로 변수선언한다.
frequency_list = [] #최대 빈도수를 가진 수들을 저장하는 리스트
for i in order:
if i[1] == max_frequency: #i[1] => 각 수의 빈도수이므로, 다음 값이 최대 빈도수라면,
frequency_list.append(i[0]) #frequency_list의 해당 숫자를 추가한다.
if len(frequency_list) == 1: #만약 최대빈도수를 가진 수가 1개라면
print(frequency_list[0]) #그 숫자만 출력한다.
else: #만약 그렇지 않다면,
print(sorted(frequency_list)[1]) #frequency_list를 오름차순으로 한 뒤 2번째 있는 숫자(=2번째로 작은 숫자)를 출력한다.
print(max(num_list) - min(num_list)) #범위 구하기, num_list의 최댓값과 최솟값을 빼면 범위의 크기를 알 수 있다.📌필요지식
1) Counter 기본 사용법
collecrions모듈의Counter클래스는 별도 패키지 설치 없이 파이썬에 내장되어 있기에 다음과 같이 임포트해서 바로 사용할 수 있습니다.

Counter생성자는 여러 형태의 데이터를 인자로 받는데요. 먼저 중복된 데이터가 저장된 배열을 인자로 넘기면 원소가 몇 번씩 나오는지가 저장된 객체를 얻게 됩니다.


1-1) most_common()most_common()은Counter를 통해 딕셔너리 형태가 된 변수를 배열형태로 변환 시켜줍니다.

1427_소트인사이드
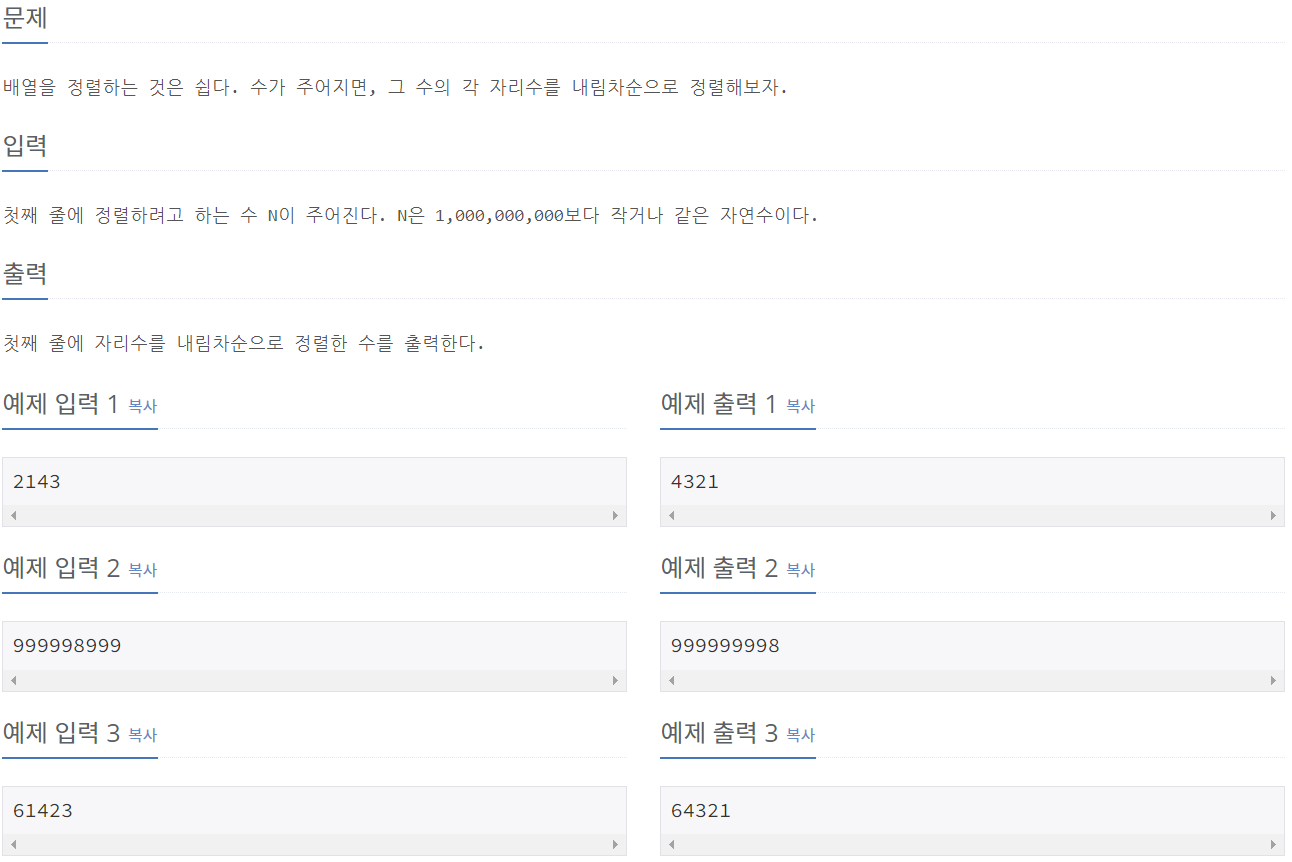
⭕풀이:
N = int(input())
N_list = []
for i in str(N): #숫자가 이어져 입력되는 경우 하나씩 따로 놓고 이를 배열해야 하기 때문에 정수(int)N을 문자열(str)N으로 바꿔 이를 하나씩 반복해
N_list.append(int(i)) #N_list에 넣는다.
N_list.sort(reverse=True) #reverse = True를 통해 내림차순으로 바꾼다.
for x in N_list: #N_list에 하나씩 입력되어 있는 요소(값)들을 하나씩 반복해
print(x, end='') #end = ''를 통해 간격없이 붙여 출력한다.
11650_좌표 정렬하기
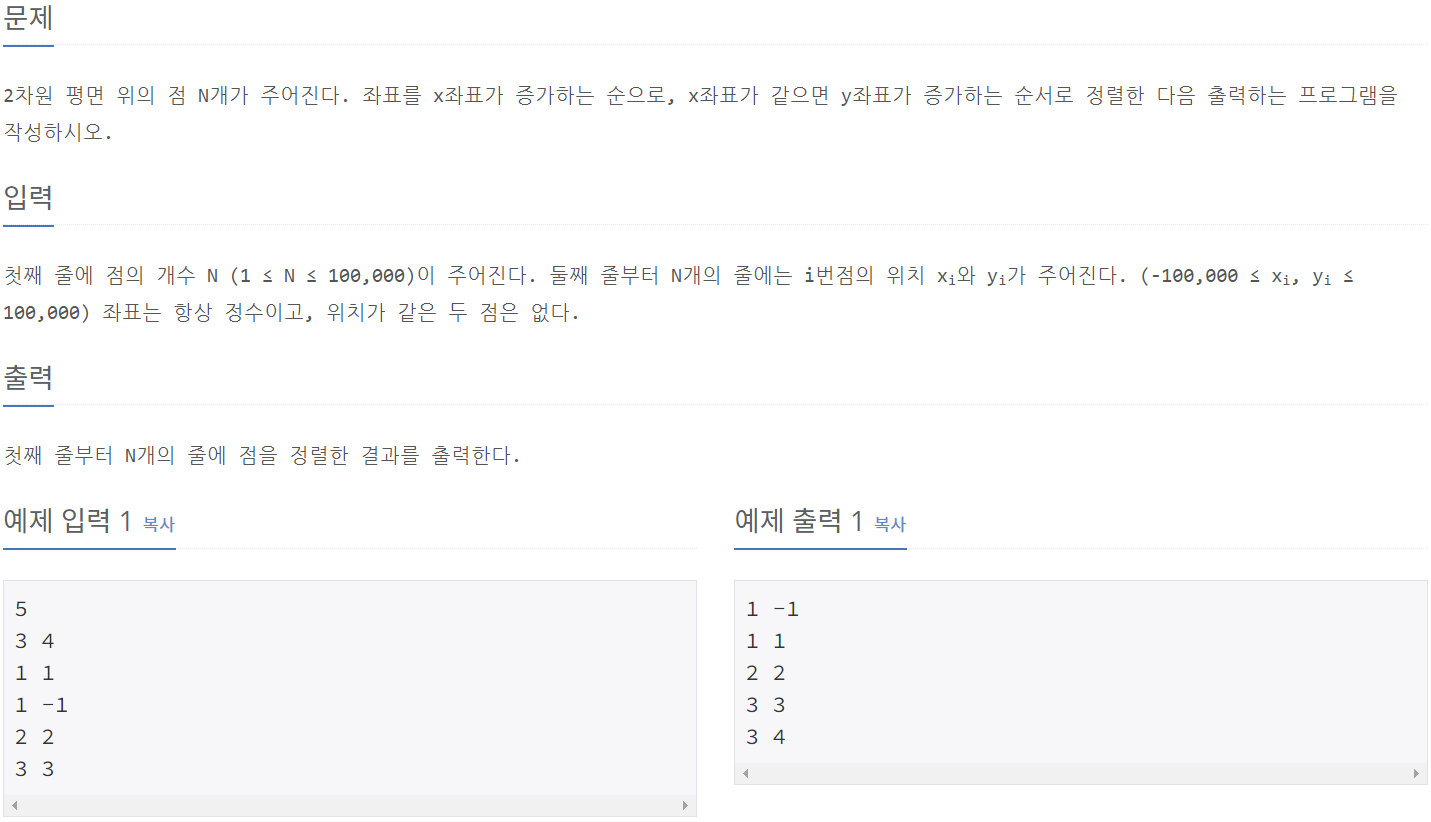
⭕풀이:
test_case = int(input())
arr_list = []
for i in range(test_case):
a, b = map(int, input().split())
arr_list.append([a, b]) #리스트 안에 리스트형식([[], [],..])으로 좌표 a와 b를 한 쌍씩 묶어준다(?).
arr_list.sort() #sort()를 이용해 오름차순으로 정렬한다. 여기서 sort를 오름차순할 때, 리스트의 정렬성질을 알 수 있다. 리스트의 요소값이 작은 순대로 배열되면서, 위치가 같은 요소값이 같을 경우, 다음 요소 값의 크기를 비교해 배열된다.
for i in range(test_case):
print(arr_list[i][0], arr_list[i][1]) #arr_list에 있는 [[a[0], b[0]], [a[1], b[1]],..]값에서 숫자를 반복한 test_case만큼 반복해 모두 출력한다.11651_좌표 정렬하기 2
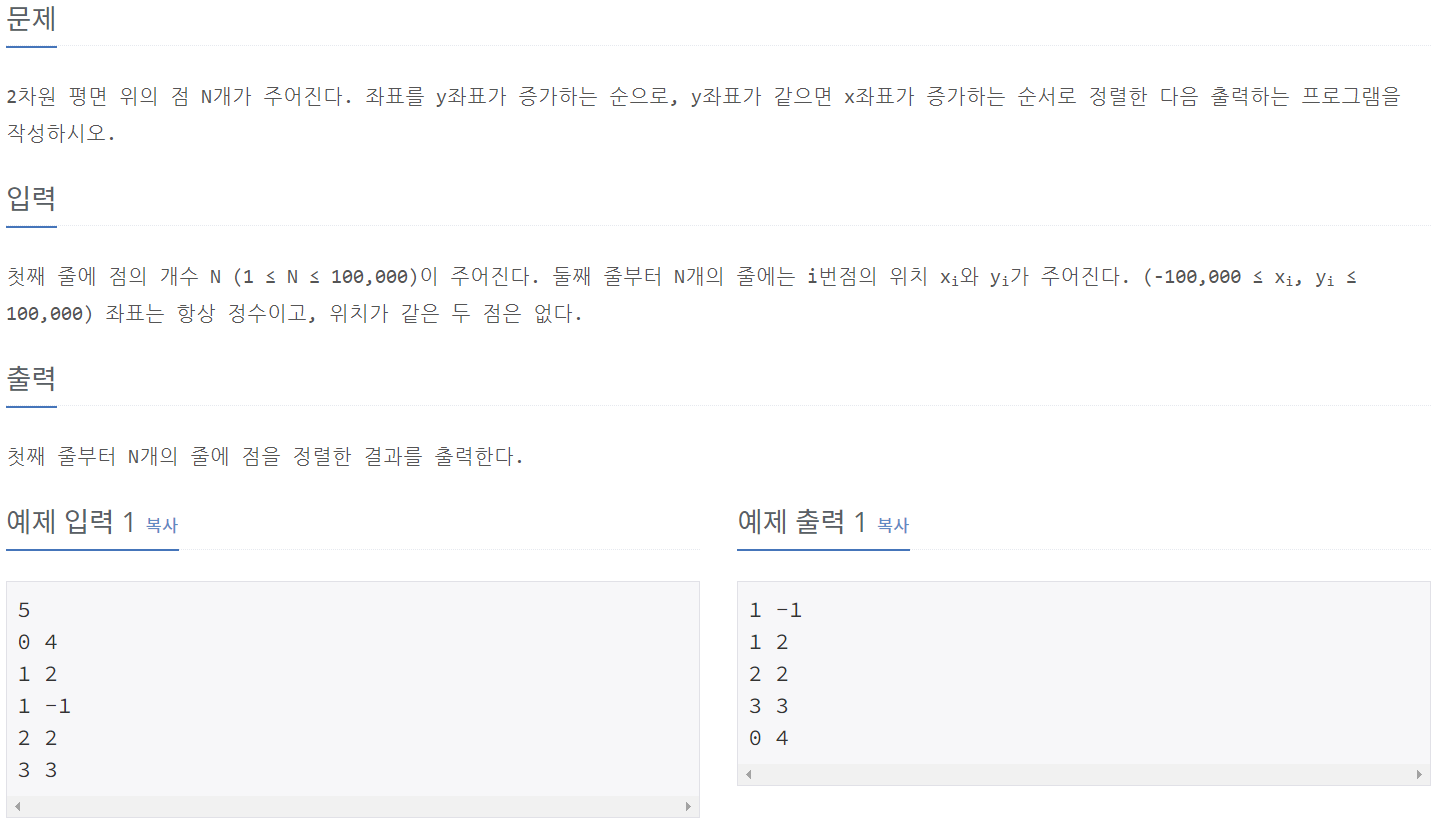
⭕풀이:
import sys #sys모듈을 이용해 시간단축
test_case = int(sys.stdin.readline())
arr_list = []
for i in range(test_case):
a, b = map(int, sys.stdin.readline().split())
arr_list.append([b, a]) #x값이 아닌 y값을 기준으로 오름차순해야하기 때문에 y값에 위치한 b의 값을 앞에, x값에 위치한 a의 값을 뒤에 위치하게 한다. [[a[0], b[0]], [a[1], b[1]],..] -> [[b[0], a[0]], [b[1], a[1]],..]
arr_list.sort() #arr_list를 오름차순으로 하고,
for i in range(test_case):
print(arr_list[i][1], arr_list[i][0]) #출력할 때에도 x좌표에 y좌표값이 들어가 있기 때문에 반대로 출력하면 제 값이 출력하게 된다.1181_단어 정렬
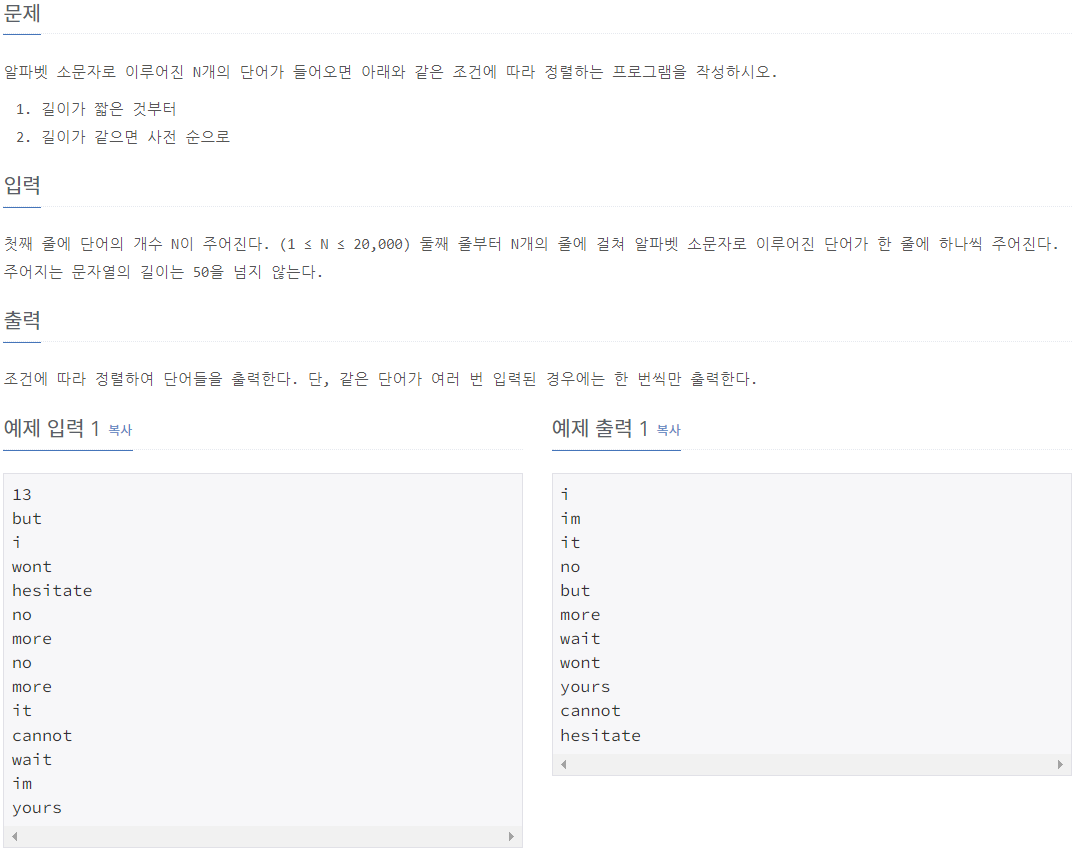
⭕풀이:
test_case = int(input())
words_list = []
for _ in range(test_case): #주어진 입력값(test_case)만큼 단어 입력을 반복해라.
word = input() #단어들을 word라는 변수로 선언하고,
words_list.append(word) #word값들은 모두 words_list에 담는다.
word_list = list(set(words_list)) #words_list의 중복을 제거하기 위해 set()함수(집합함수)를 이용해 중복제거하고, 중복제거된 words_list의 값들을 word_list에 담는다.
word_Len_list = [] #word_list의 요소값들의 길이를 같이 넣기 위해 비어있는 word_Len_list 리스트를 만든다.
for i in word_list: #word_list의 값들을 i에 하나씩 대입해
word_Len_list.append((len(i), i)) #(요소값의 길이, 요소값)형태로 word_Len_list에 담는다.
result = sorted(word_Len_list) #word_Len_list를 sort()를 통해 오름차순으로 하면 요소값의 길이순서대로 정렬되고 값이 같을 경우, 문자열의 순서대로 정렬되는 sorted의 성질을 알 수 있다. -> [(1, 'i'), (2, 'im'), (2, 'it'), (2, 'no'), (3, 'but'), (4, 'more'),
for len_words, words in result:
print(words)⭕쉬운 풀이:
test_case = int(input())
words_list = []
for i in range(test_case):
word_list.append(input()) #입력과 동시에 append 해준다.
word_list = set(words_list) #중복 문자를 제거해주고,
words_list = list(word_list) #다시 list형으로 바꿔준다.
words_list.sort() # 알파벳 순서로 정렬해줌
words_list.sort(key = len) #리스트 요소를 길이 순으로 정렬할 때는 sort 메소드에서 key=len
for i in ans:
print(i)🙋♂️comment.
길이순 정렬 -> 알파벳순 정렬 ( x )
알파벳순 정렬 -> 길이순 정렬 ( o )
처음에 길이를 순서로대로 정렬하고, 알파벳순으로 해서 원점으로 돌아갔는데, 반대로, 알파벳순으로 words_list를 정렬하고, 길이순서대로 정렬하면 맞춰질 수 있었다.
10814_나이순 정렬
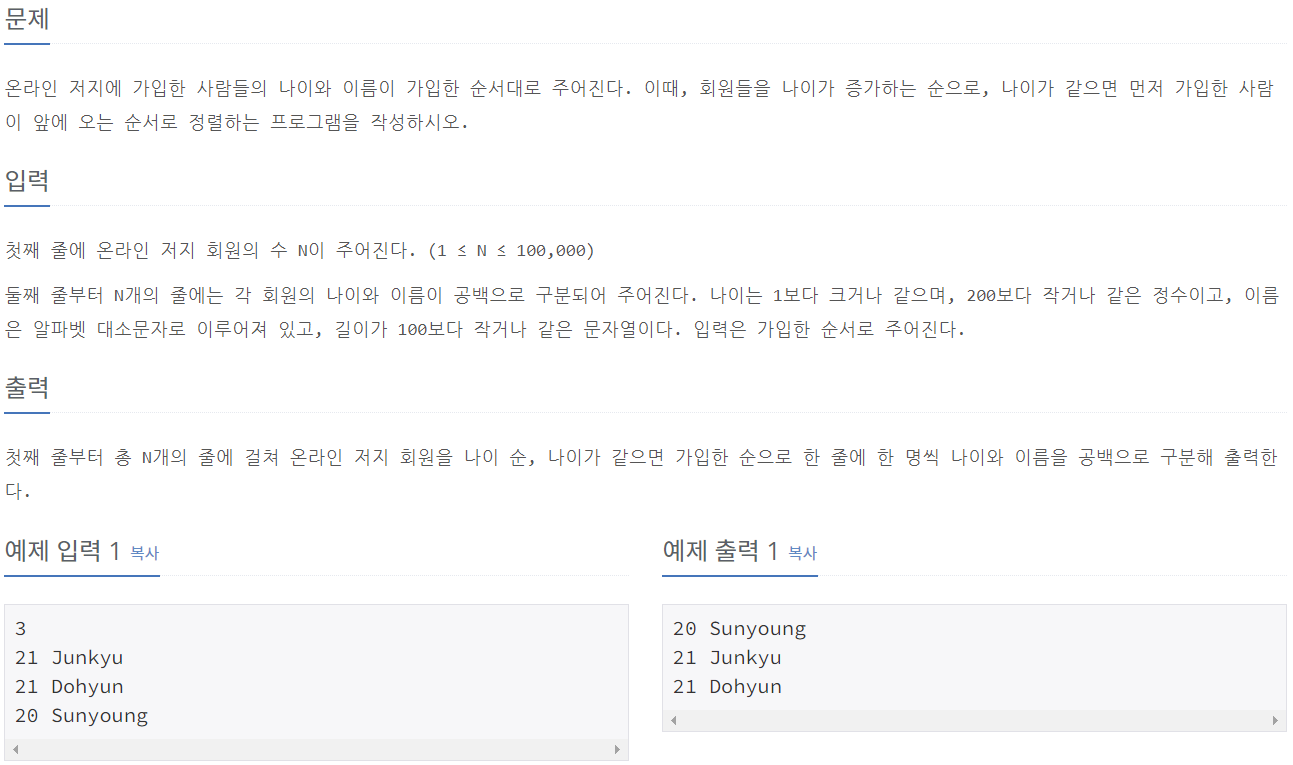
⭕풀이:
test_case = int(input())
member_list = []
for _ in range(test_case):
age, name = input().split() #나이와 이름을 age와 name이라는 변수로 선언하고, 이를 띄워서 입력해 구분했다.
member_list.append([int(age), name]) #기존에 정수와 문자열을 함께 받기 위해 age를 정수로 받지 않았기 때문에, age를 정수로 변환하고, name과 같이 비어 있는 member_list에 넣는다.
member_list.sort(key=lambda x: x[0]) #lambda를 통해 리스트의 첫번째 값(=0번째 값)인 name을 제외한 age를 기준으로 member_list를 오름차순으로 정렬할 수 있다.
for i in range(test_case):
print(member_list[i][0], member_list[i][1])📌필요지식
1) lambda
-
의미 익명함수를 지칭하는 용어 즉, 기존의 함수(명)를 선언하고, 사용하던 방식과는 달리 바로 정의해 사용할 수 있는 함수입니다.
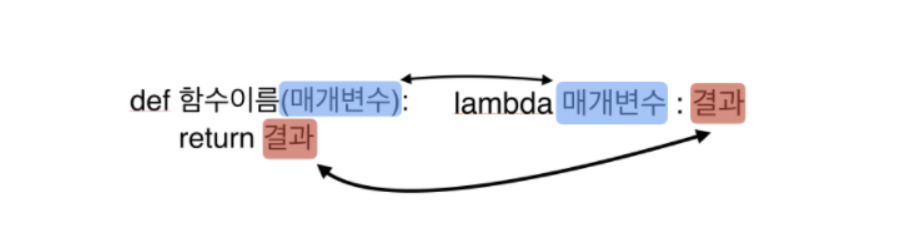
1-1) 사용방법f = lambda x: x+10
print(f(10))
20
-
이렇게 하면 코드가 간단해지고, 메모리를 줄일 수 있습니다.
원래 함수를 선언하게 되면 그 함수자체를 메모리에 할당되는데lambda함수를 사용하면 한 번만 사용하고 사라지기 때문에 효율적으로 쓸 수 있습니다.1-2) 사용 예시
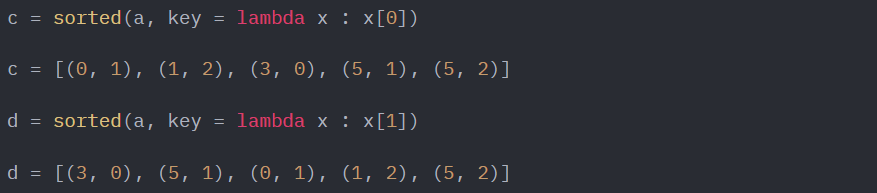

-
🙋♂️comment.
처음엔 sort()를 통해 오름차순으로 정렬하기만 하면 쉽게 해결할 수 있는 문제라고 생각했는데, sort()만 이용하니
[age, name]에서 name도 같이 알파벳 오름차순으로 정렬이 되어버렸습니다.
나이가 같을 경우엔, 가입한 순서(=입력한 순서)로 정렬해야하기 때문에 오름차순을 하되, name을 건드리지 않고, age의 값을 기준으로 정렬해야 했습니다.
그래서 구글로 검색을 해본 결과, lambda를 이용하면 리스트 안에 원하는 값을 기준으로 정렬할 수 있다는 걸 알게 됐고, 이를 이용해서 정답을 보지 않고, 풀 수 있었습니다.
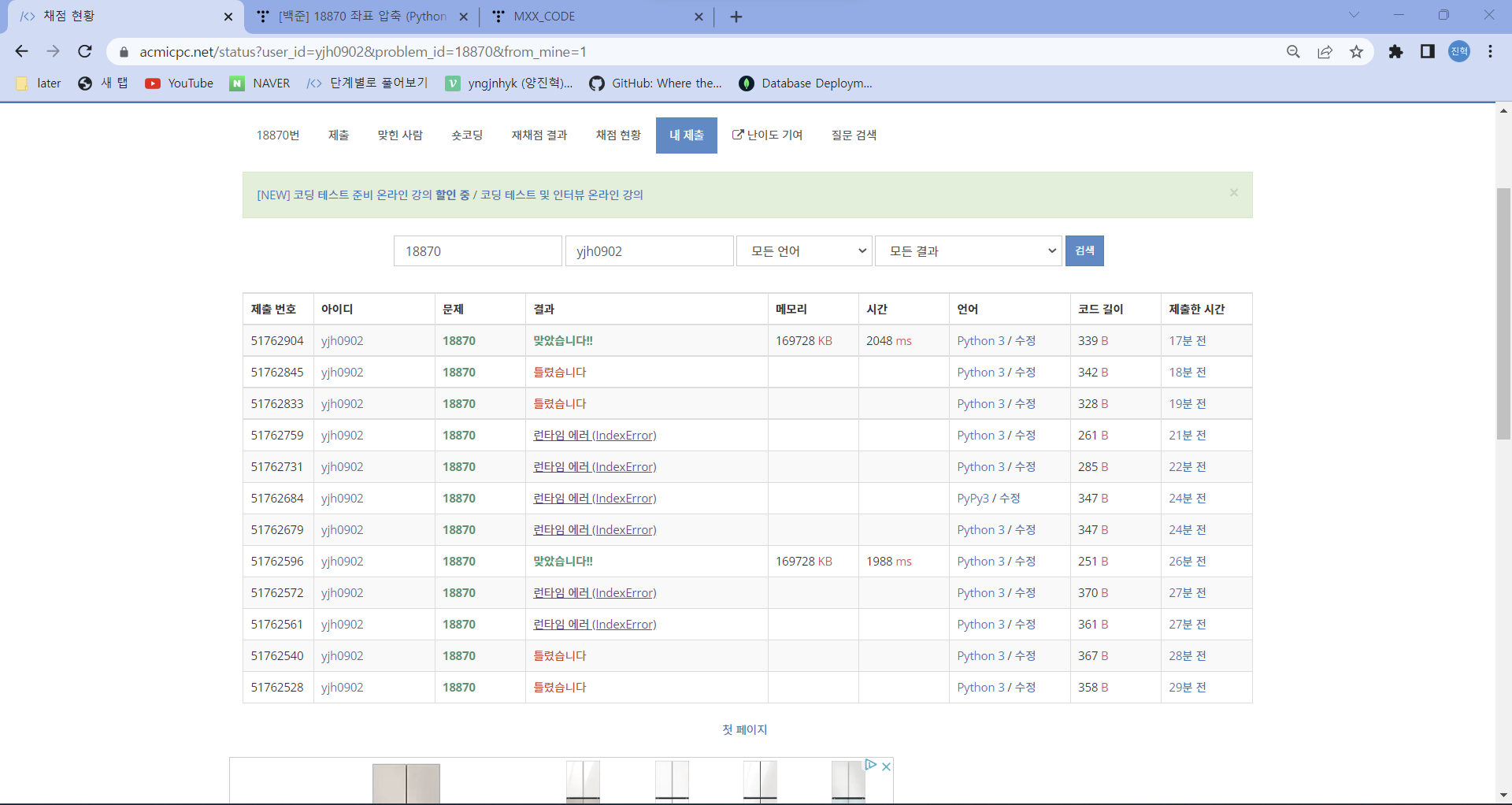
18870_좌표 정렬하기
⭕풀이:
import sys
test_case = int(input())
number_list = list(map(int, sys.stdin.readline().rstrip().split())) #가장 우측 공백을 제거하고, 한 칸씩 띄워 값을 입력하게 하고, 입력값들을 number_list에 리스트형태로 넣는다.
set_Number = set(number_list) #set함수를 이용해 number_list의 중복된 값을 제거해 값의 순서를 메길 수 있게 한다.
set_Number_list = list(set_Number) #집합의 형태인 set_Number를 리스트 형태로 바꿔 set_Number_list라는 리스트에 변수선언해준다.
set_Number_list.sort() #set_Number_list를 오름차순으로 정렬한다.
num_dict = {} #딕셔너리 형태로 num_dict를 변수선언한다.
for i in range(len(set_Number_list)): #set_Number_list의 길이만큼 i를 0부터 반복 대입해라.
num_dict[set_Number_list[i]] = i #test_case = 5, number_list = [2 4 -10 4 -9]일 때, {-10: 0, -9: 1, 2: 2, 4: 3}와 같은 딕셔너리를 만들 수 있다.
for i in number_list: #처음 입력받은 number_list를 i에 대입해 반복해라.
print(num_dict[i], end=' ') #num_dict의 i의 value값들을 한 줄에 반복해 출력해라.
📌필요지식
1) dicrionary, 딕셔너리
- dictionary(사전)은 파이썬에서 list(리스트)와 더불어 가장 많이 사용되는 내장 데이터 타입 중 하나입니다.
- 딕셔너리는 키(key)와 밸류값(value)으로 이루어진 여러 쌍의 데이터를 담아 둘 때 시용합니다.
1-1) 사용방법
- 딕셔너리를 생성하는 데는 여러가지 방법이 있지만, 가장 많이 사용되는 방법은 중괄호{}를 사용하는 것입니다. 중괄호 안에 키 : 밸류값 형태의 데이터 쌍을 쉼표,로 구분해서 나열해주면 됩니다.

1-1-1) 데이터 추가
- 사전에 데이터를 추가할 때는 대괄호 [키] = 밸류값 를 사용해 원하는 값을 할당해줄 수 있습니다.
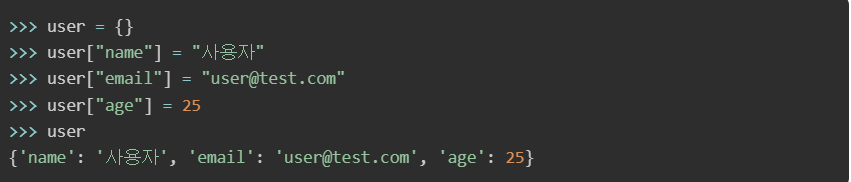
1-1-2) 데이터 접근
- 사전이 담고 있는 데이터에 접근할 때도 대괄호 [키]를 사용합니다.

1-1-3) 데이터 갱신
- 가변 데이터 타입인 사전은 자유롭게 담고 있는 데이터를 갱신할 수 있습니다. 기존 키에 새로운 값을 할당하기만 하면 기존 값이 새로운 값으로 대체됩니다.

11전12기.
마약같은 "맞았습니다!!"
이 맛에 백준 못 끊어