11654_아스키 코드
⭕풀이:
print(ord(input()))📌필요지식
1) 아스키코드
- 아스키는 미국 정보 교환 표준 부호를 의미합니다. 문자열이나 기호와 같은 정보를 컴퓨터에서 사용하는 부호로 교환을 하는 코드를 말합니다.
7비트 인코딩이 가능한 코드이기 때문에 크기가 큰 한글을 교환하는 데는 적합하지 않습니다. 7비트 인코딩은 0부터 127까지로 표현이 가능하고 해당 범위 안에서 표현 가능한 문자는 숫자, 기호와 알파벳이 해당됩니다.
참고로 문자 인코딩은 문자열이나 기호를 컴퓨터에 사용할 수 있는 코드로 부호화, 코드화 하는 과정을 의미합니다.
1-1) ord()함수
ord( )함수의 괄호 안에 문자열을 입력하면 문자에 해당되는 아스키코드를 반환합니다. 괄호안에는 하나만 입력이 가능하니다.
2) chr( )함수
chr()함수는ord()함수의 반대 기능을 합니다. 아스키코드에 해당하는 숫자를 입력하면 그에 해당되는 문자열을 출력합니다.
11720_숫자의 합
⭕풀이:
N = int(input())
numbers = map(int, input())
print(sum(numbers))
10809_알파벳 찾기
⭕풀이:
word = input()
alphabet = list(range(97, 123)) #alphabet은 아스키코드 숫자범위를 이용해 [a, b, c, d,...y, z]이다.
for i in alphabet:
print(word.find(chr(i))) #find를 이용해 a,b,c,..들이 어디에 위치하고 있는지 a,b,c,..대신 위치값을 표현하게 된다.
2675_문자열 반복
⭕풀이:
test_case = int(input())
for _ in range(test_case):
R, S = input().split()
for i in S: #ex)S = hello, hello라는 문자열을 i에 넣어 반복해라.
print(i * int(R), end="") #for문을 통해 문자열을 반복하면 각 문자를 분리해 ('h', 'e', 'l', 'l', 'o') 반복한다. 그러므로, i를 처음 문자열로 받은 R을 int를 통해 정수로 바꿔 R만큼 반복해 출력한다.
print() #줄넘김📌필요지식
1) 문자열 반복
- 일반적으로, 문자열 반복은
*연산자를 사용하고 전체 문자열을 반복할 횟수를 지정해야 합니다.
2) for문의 문자열 반복
- for문 첫 줄의 기본구조는 [ for 변수 in iterable ]입니다. 이때, 반복 가능한
iterable자료형은 문자열도 포함됩니다. 문자열을iterable에 입력하면 문자열의 각 문자를 분리해서 변수에 선언합니다.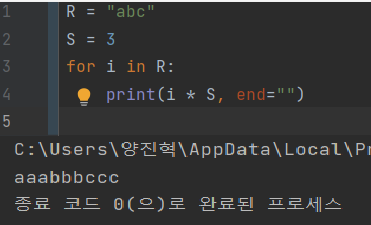
1157_단어 공부
⭕풀이:
words = input().upper() #입려된 값을 모두 대문자로 바꾼다.
alphabet = list(set(words)) #입력된 값 words에서 기존 단어의 순서는 지켜지지 않지만, set을 이용해 중복된 값을 제거한 후 문자열 하나씩 alphabet 리스트에 넣는다.
cnt_list = []
for i in alphabet: #ex)words = hello, alphabet = ['O', 'E', 'L', 'H']이면, 하나씩 i에 대입해 반복해라.
cnt = words.count(i) #처음에 주어진 값 HELLO에서 각 문자열이 몇개인지 센다. ['O', 'E', 'L', 'H'] -> 1,2,1,1가 cnt이다.
cnt_list.append(cnt) #cnt를 cnt_list에 넣어 list형태로 바꾼다.
if cnt_list.count(max(cnt_list)) > 1: #cnt_list에서 최댓값의 갯수가 1보다 크면(=최댓값이 둘 이상이면)
print('?')
else:
max_index = cnt_list.index(max(cnt_list)) #cnt_list의 최댓값의 위치를 cnt_list에서 어디에 위치하고 있는지 그 위치값이 max_index이다.
print(alphabet[max_index]) #alphabet리스트(['O', 'E', 'L', 'H'])에서 cnt_list의 최댓값의 위치값만큼의 위치에 있는 문자열을 출력해라.1152_단어의 개수
⭕풀이:
sentence = input().split()
print(len(sentence))
❗알게 된 점:
1) .split()와 리스트
index.split()을 하게 되면index에 있는 요소들을 띄워쓰게 하면서 추가로 기존에 문자열이었지만,index를 리스트형태로 바꿔준다는 사실을 알게 되었습니다. 모양만 같은가해서 리스트에 쓸 수 있는 함수인 .append()(리스트에 내용추가)를 해보았습니다.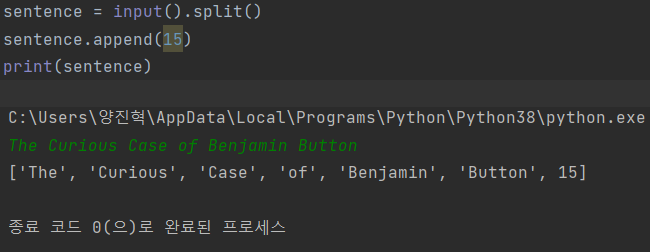
2908_상수

⭕풀이:
A, B = map(int, input().split())
fake_A = int(str(A)[::-1])
fake_B = int(str(B)[::-1])
fake_list = [fake_A, fake_B]
print(max(fake_list))📌필요지식
1) [::-1]
- 역순으로 변환할 때는 범위 선택 연산자를 [::-1]로 지정해서 문자 배열을 뒤집어서 반환되도록 할 수 있습니다.
5622_다이얼
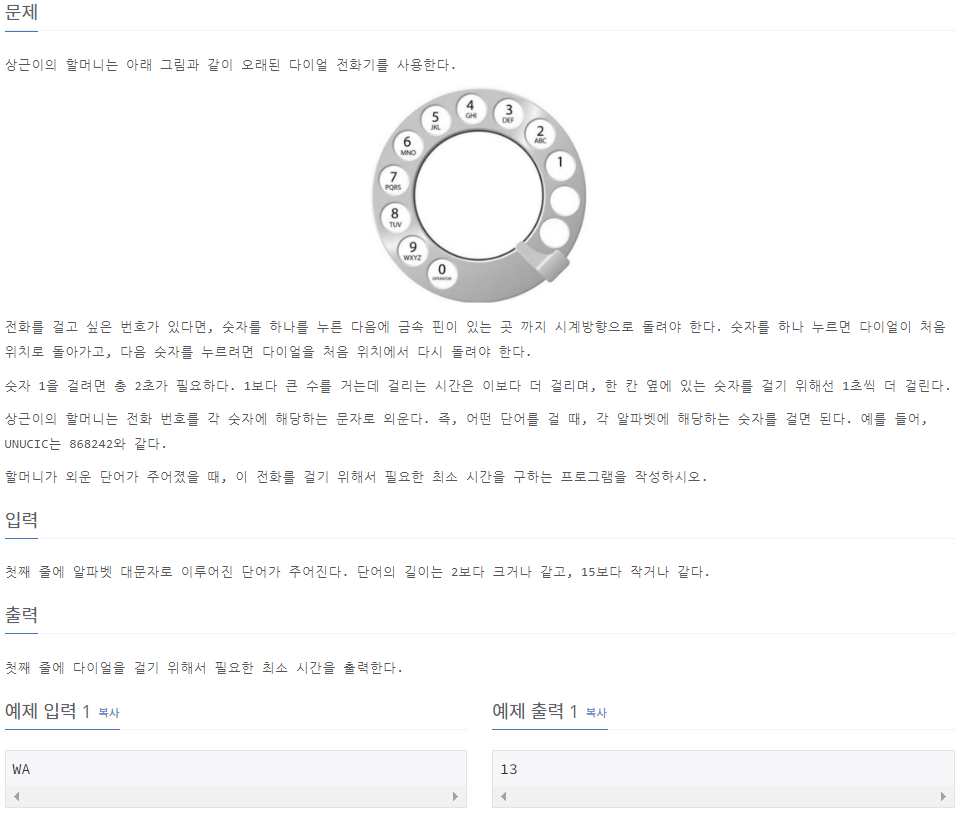
⭕풀이:
alphabet_list = ['ABC', 'DEF', 'GHI', 'JKL', 'MNO', 'PQRS', 'TUV', 'WXYZ'] #alphabet_lis를 같은 칸에 있는(=돌리는 시간이 같은) 알파벳끼리 하나의 문자열을 만들어 리스트를 작성해 이들의 위치값을 이용해 걸리는 시간을 구할 예정이다.
word = input()
time = 0
for unit in alphabet_list: #alphabet_list에 있는 문자열들을 unit에 대입해 반복해라.
for i in unit: #alphabet_list를 통해 받은 문자열 'ABC', 'DEF', 'GHI',..들을 'A', 'B', 'C'형태로 나눠 i에 대입해 반복해라.
for x in word: #word값을 x에 대입해 반복해라.
if i == x: #i와 x가 같다면
time += alphabet_list.index(unit) + 3 #alphabet_list에 있을 unit('ABC', 'DEF', 'GHI',..)의 위치값에 + 3한 값이 걸리는 시간이다.
print(time)2941_크로아티아 알파벳
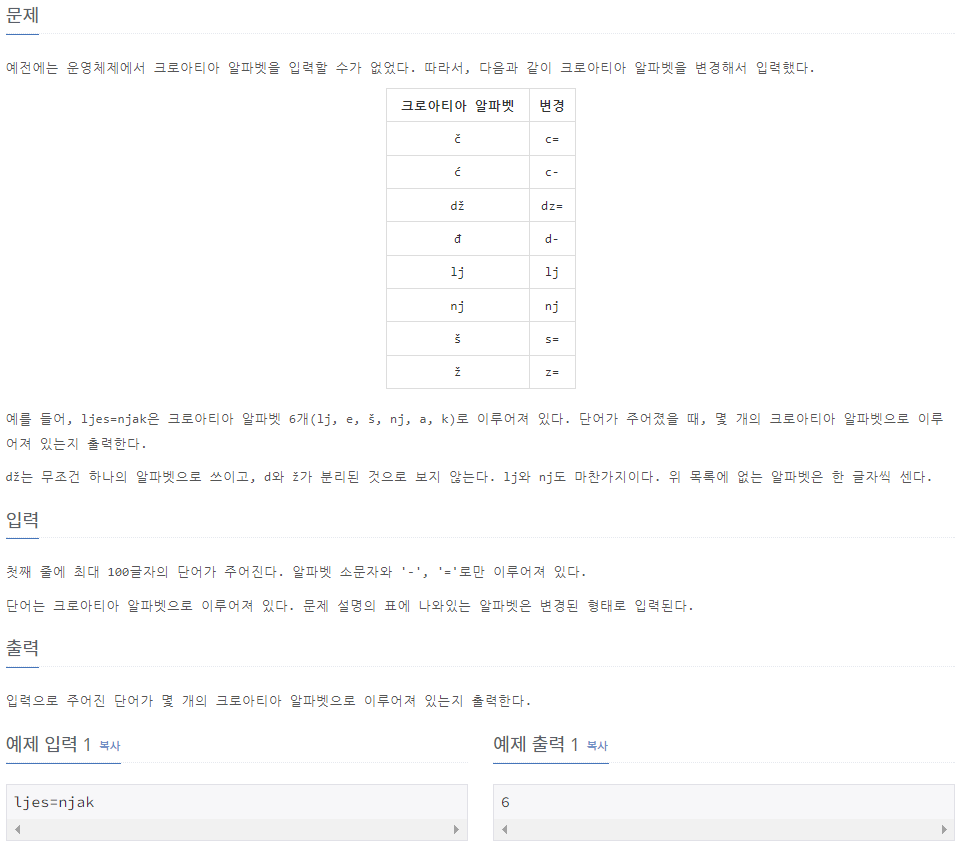
⭕풀이:
croatia = ['c=', 'c-', 'dz=', 'd-', 'lj', 'nj', 's=', 'z=']
word = input()
for i in croatia:
word = word.replace(i, '*') #replace를 통해 주어진 단어 word에서 크로아티아 알파벳인 i를 기호 '*'로 변환시키고, 그 값이 word라는 변수에 다시 적용된다.
print(len(word))
#이 문제는 단어가 주어졌을때, 실제로 해당 단어를 크로아티아 알파벳으로 변환시켜주지 않고, 출력해야 하는 건 크로아티아의 갯수라는 점입니다.
문제를 풀기 위해서 입력받는 문자에서 2글자~3글자로 이루어진 8개의 알파벳이 있는 경우, 한 글자로 변환을 하고서 이후에 변환된 문자열의 총 글자 수를 세는 방법으로 코드를 작성했습니다.📌필요지식
1) replace(old, new)
- replace는 문자열을 변경하는 함수이다. 문자열 안에서 특정 문자를 새로운 문자로 변경하는 기능을 가지고 있다.
사용방법은 index.replace(바꾸고자 하는 특정 문자, 특정 문자를 새로 바꿀 문자)
1316_그룹 단어 체커
⭕풀이:
N = int(input())
group_word = 0
for _ in range(N):
word = input()
error = 0 #그룹단어가 아니라면, error에 값이 들어가기 위해 변수 error = 0을 둔다.
for index in range(len(word)-1): #바로 다음 내용에 index를 통한 위치값을 이용해 지정글자와 지정글자 + 1과 같은지 아닌지 비교해야 하기 때문에 index범위를 0에서 입력받은 값인 word의 글자개수 - 1까지 둔다.
if word[index] != word[index+1]: #index=0,1,..word의 글자 개수 - 1까지 이기 때문에 word[0]와 word[1]가 다르면,
new_word = word[index+1:] #word[1]부터 word[0]이후에 글자들은 new_word이다. -> word[0,1..] = word[0] + new_word
if new_word.count(word[index]) > 0: #new_word에서 word[0]의 개수를 셋을 때, 0보다 크면, -> new_word에서 word[0]가 한 글자라도 있다면,
error += 1 #error는 error + 1이다.
if error == 0: #글자 하나씩 대입해 끝까지 해보았을 때, 지정글자와 지정글자가 같거나, 같지 않더라도 같지 않은 순간의 지정글자가 이후에도 없어서 error = 0이라면,
group_word += 1 #group_word는 group_word + 1이다.
print(group_word)📌필요없는 지식

느낀 점
이번 문자열 단계를 풀어보면서 느낀 점은
코딩테스트를 잘 한다는 건 단순히 문제를 보고 해당하는 코딩내용을
리팩토링하면서 짧게 구현해낸다기 보다는,
문제를 수학문제처럼 대하고, 쉽게 풀어갈 수 있는 키포인트(3초풀이와 비슷한)를 찾아내 나름의 공식을 만들어 그 공식의 내용을 코딩하면 자연스레 리팩토링된 답변을 작성할 수 있고, 그것이 코딩테스트를 잘 하는 것이라고 생각된다.

타이밀크티는 맛있습니다.