시간복잡도
자료구조와 알고리즘를 이해하기 위해서는 시간복잡도 라는 개념이 필요하다. 시간복잡도는 알고리즘의 작동시간을 취해 시간을 정량화한 함수이다. 또한, 계수와 낮은 차수의 항을 제외시키는 빅오 표기법을 통해 표현한다.
예로 들면 크기 n의 트리를 탐색하는 경우 트리의 높이만큼 탐색하기 때문에 logn+1의 시간이 걸리고, 이를 시간복잡도로 표현하면 O(logn+1) 시간이 소요된다
시간복잡도의 문제 해결 단계
O(1): 입력에 관계없이 상수 시간이 걸린다. 문제를 해결하는데 오직 한 단계만 처리 가능하다O(logn): 문제를 해결하는데 필요한 단계들이 연산마다 특정 요인에 의해 줄어듦.O(n): 입력값과 문제를 해결하는 단계가 1:1 관계를 가짐. 입력이 증가하면 메모리 사용이 선형적으로 증가함.O(nlogn): 문제를 해결하기 위한 단계가 n*logn 번 만큼의 수행시간을 가진다.O(n^2): 이중 반복문을 사용하는 경우 O(n^2) 시간복잡도가 소요된다.O(C^n): 상수값의 제곱이기 때문에 값이 늘어날 수록 시간복잡도는 매우 큰 값으로 증가한다.
배열(Array)
- 특정 크기 만큼 연속된 메모리 공간에 데이터를 저장하는 구조
- 초기화 시 크기가 고정되기 때문에 데이터를 빈번하게 추가, 삭제 하는 경우 효율적이지 못하다
- 원시타입(int, byte등)으로 데이터 타입을 선언할 수 있고, 제네릭을 지원하지 않아 원시타입이 아닌 다른 타입을 선언하는 경우 exception이 발생한다.
- 데이터가 물리적으로 연속되어 있어 처음 배열의 주소만 알면 다른 데이터의 위치도 쉽게 알 수 있어 검색에 용이하다.
- 컴파일 과정에서 메모리가 할당되는 정적 메모리 이며, stack 영역에 할당된다
- 탐색 시 시간복잡도는 O(1) / 추가, 삭제 시 시간복잡도는 O(n) 소요된다
배열리스트(ArrayList)
- 초기화 하는 경우 크기를 선언하지 않기 때문에 새로운 배열을 할당받아 동적으로 크기를 할당 할 수 있는 배열 리스트 구조
- 데이터가 추가되어 리스트의 크기를 초과하면 내부적으로 부족한 만큼 새로운 배열을 할당받고 기존배열을 복사하는 작업을 진행하기 때문에 속도 측면에서 배열보다 느린편이다
- 중간에 특정 index에 데이터를 추가, 삭제하는 경우 해당 index 이후에 위치한 데이터를 이동해야 하기 때문에 비효율적이다
- 객체 타입만 데이터 타입 선언 가능하고, 제너릭을 통해 type-safety를 보장한다.
- 탐색 시 시간복잡도는 O(1) / 추가, 삭제 시 시간복잡도는 O(N) 소요된다.
연결리스트(Linked List)
- 데이터가 메모리 공간에 고유의 노드로 저장되어 있고, 노드 내부는 데이터 값을 저장하는 데이터 필드와 다른 노드의 주소값을 저장하는 링크 필드로 구성된다.
- 각각의 노드가 포인터를 갖고 다음 노드의 주소값을 저장하고, 마지막 노드의 링크는 null로 표현한다
- 특정 데이터를 탐색하는 경우 노드가 모두 떨어져 있기 때문에 처음부터 순차적으로 탐색해야 한다
- 데이터를 추가, 삭제하는 경우 노드가 가르키는 주소값만 변경하면 되므로 상수 시간이 거리며 효율적으로 추가, 삭제를 할 수 있다
- 런타임 환경에서 메모리가 할당되는 동적 메모리이며, heap 영역에 할당된다.
- 탐색 시 시간복잡도는 O(n) / 삽입 삭제 시 연결된 값만 변경하면 되므로 O(1) 가 소요된다
이중 연결 리스트(Doubly Linked List)
- 노드가 이전 노드와 다음 노드로 구성되어 있어 이전 노드의 주소값과 다음노드의 주소값을 가지고 있음
- 양방향으로 연결하기 때문에 검색 시 속도가 빠름
- 운영체제 동적 메모리 관리에 적합하다
원형 단순 연결 리스트 (Circular Singly Linked List)
- 노드가 다음 주소값을 가지고 있고, 마지막 노드의 링크 필드는 head의 주소값을 가지고 있기 때문에 원형 구조를 띄는 자료구조
- head 노드는 마지막 노드를 가르키는데, 길이에 상관 없이 첫번째 노드 앞이나 마지막 노드 뒤에 일정한 시간으로 노드를 삽입할 수 있다
스택(Stack)
- 먼저 입력된 데이터가 나중에 출력되는 후입선출의 데이터 구조
- 정해진 방향(top)으로만 입력과 출력이 가능하다
- 연산은 top을 통해 데이터를 삽입하는 연산인 push와 top을 통해 데이터를 삭제하는 연산인 pop으로 구성되어 있다
- 후위 표기법이나 역순 문자열을 구현할 때 사용 된다
큐(Queue)
- 먼저 입력된 데이터가 먼저 출력되는 선입선출의 데이터 구조
- 한쪽 끝에서는 삽입, 또 다른쪽에서는 삭제가 이뤄진다
- 연산은 삽입을 지원하는 enqueue, 삭제를 지원하는 dequeue 연산으로 구성되어 있다
- front, rear 변수로 데이터 추가,삭제 시 현재 큐의 위치를 파악
- 프로세스 관리나 운영체제에서 캐시를 관리하는 경우 사용된다
덱(Deque)
- 양방향에서 삽입, 삭제가 가능한 구조이며 스택과 큐의 특성을 갖기 때문에 스택과 큐의 연산을 모두 지원한다
- 원형 큐와 동일하게 사용 가능하다
- 중간으로 요소를 삽입, 삭제하는 경우에는 성능은 좋지 않다
- 스레드간 동기화(Thread-safe)를 지원한다
- 양방향 삽입,삭제라는 특성이 있기 때문에 양쪽에 링크 필드를 가지는 노드를 사용하는 이중연결리스트를 이용하여 구현해야함
우선순위 큐(Priority Queue)
- 입력된 순서에 상관 없이 우선순위가 높은 데이터가 먼저 출력되는 자료 구조
- 모든 데이터에 우선순위를 두며 우선순위가 같은 경우 queue의 순서에 따라 제공된다
- 연산은 큐에 새로운 데이터를 추가하는 enqueue , 큐에서 최대 우선순위 요소를 삭제하고 값을 반환하는 연산인 dequeue , 최대 우선순위를 반환하는 연산인 peek 을 지원한다
- peek 연산은 우선순위 값을 항상 front에 있기 때문에 시간복잡도 O(1)이 소요된다
- enqueue 연산은 부모의 값과 비교해서 값을 바꾸는 작업을 진행하기 때문에 노드의 높이만큼 소요되 시간복잡도 O(logN)만큼 소요된다.
- dequeue 연산도 동일하게 시간복잡도 O(logN)만큼 소요된다
- 구현은 주로 힙을 통해 구현되며 배열이나 연결리스트로 구현하는 경우 시간복잡도 O(N)을 보장하며, 힙으로 구현하는 경우 시간복잡도 O(logN)를 보장한다
- CPU 스케쥴링, Dijkstra 최단거리 알고리즘, Prim 최소신장트리에 사용된다
힙(Heap)
- 마지막을 제외한 모든 노드에서 자식들이 꽉 채워진 이진트리를 기초로 하는 자료구조
- 중복값을 허용한다
- 완전이진트리의 형태를 갖기 때문에 배열을 이용해서 구현할 수 있다.
- 힙의 종류에는 최대 힙, 최소 힙이 있다.
- 최대 힙 : 부모노드의 키 값이 자식 노드의 키 값보다 항상 큰 완전 이진 트리
- 최소 힙 : 부모노드의 키 값이 자식 노드의 키 값보다 항상 작은 완전 이진트리
- 최대 힙의 경우 루트에는 항상 큰 값이 존재하므로 최대값을 구할 경우에 상수 시간인 시간복잡도 O(1) 이 소요된다
힙의 삽입연산 시간복잡도(최대 힙 기준)
- 루트노드가 아닌 말단노드에 새로운 데이터 삽입
- 말단노드의 부모노드와 비교하여 부모노드 보다 자식노드가 큰 경우 자식노드를 부모노드의 위치와 교환한다
- 또 부모노드와 비교하고, 위의 과정을 부모노드가 자식노드보다 값이 클 경우 까지 반복합니다.
- 힙의 마지막 노드에 삽입하는 경우 시간복잡도는 O(1)이 소요되고, 최악의 경우 삽입한 데이터를 루트까지 비교해야 하므로 힙의 높이만큼 데이터 탐색, 삽입 단계를 반복해야 하므로 최대 logn의 시간이 소요된다.
- 결론적으로 logn+1 만큼의 시간이 소요되기 때문에 시간복잡도는 O(logn)이 소요된다
힙의 삭제연산 시간복잡도(최대 힙 기준)
- 루트노드를 삭제하고 가장 말단노드의 데이터를 루트노드로 이동한다
- 자식노드 중 큰 값을 가진 자식과 위치를 교환한다
- 교환한 노드에서 큰 값을 가진 자식과 위치를 교환하고, 위 과정을 반복하여 재구조화를 진행한다
- 삽입과 동일하게 힙의 높이만큼 시간복잡도 O(log n)이 소요된다
힙 재구조화 (heapify)
- 힙에서 데이터 삽입, 삭제 시 힙의 조건이 깨지는 경우가 있는데 이런 경우 힙의 특성을 만족시키기 위해 노드의 위치를 변경하는 것
해시 테이블(Hash Table)
- key 값에 value를 저장하는 데이터 구조
- key는 hash function을 통해 hash값으로 변경되며 hash는 value와 매칭되어 저장소에 저장된다
- hash 함수의 의존성이 높다
- key, value로 데이터를 관리하는 자료구조 이기 때문에 삽입, 삭제, 검색의 경우 시간복잡도 O(1)이 소요되며, 삽입의 경우 hash 값이 충돌되는 경우에 모든 버킷의 값을 찾아봐야 하므로 시간복잡도 O(n)이 소요된다
해시테이블 collision
- 데이터가 많아졌을 때 다른 데이터의 키가 같은 해시값으로 충돌 나는 현상
- 위와 같은 경우 특정 키의 버킷에 집중 되기 때문에 해시 테이블의 성능을 떨어트림
collision의 해결 방법
- 체이닝

- 버킷 내에 연결리스트 할당, 버킷에 데이터를 삽입하다가 해시충돌이 발생할 경우 삽입할 데이터를 기존 자료 다음의 연결리스트로 데이터를 연결하는 방법
- 상대적으로 적은 메모리를 사용하는 장점
- 개방 주소법
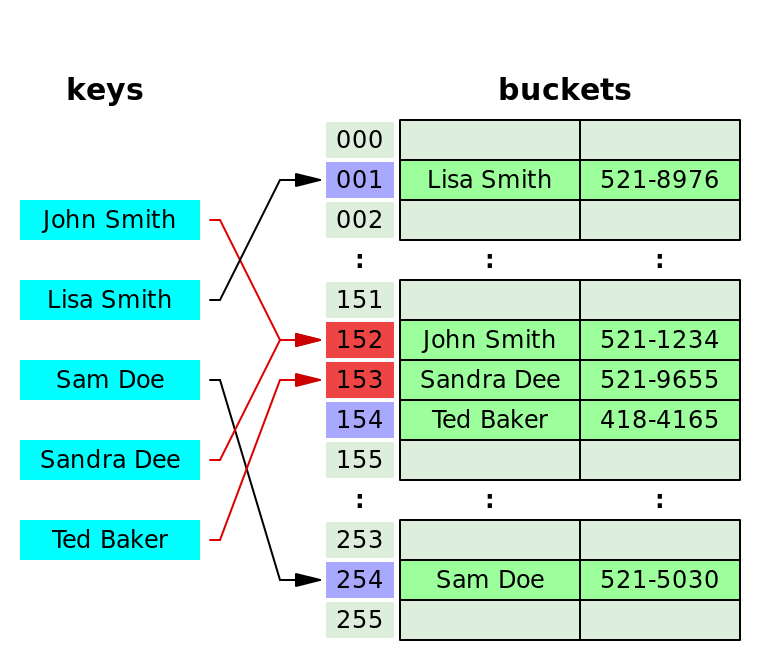
- 해시 충돌이 일어나는 경우 다른 버킷에 데이터를 삽입하는 방식이다 체이닝 처럼 포인터가 필요 없고, 추가적인 저장공간도 필요 없고, 삽입-삭제 시 오버헤드가 적다
- 선형탐사 : 개방주소법의 한 종류로 충돌이 발생하는 경우 다른 해시값에 해당하는 버킷에 엑세스 하는 경우 고정폭으로 이동한다
- 제곱탐사 : 개방주소법의 한 종류로 다른 해시값에 해당하는 버킷에 엑세스 하는 경우 제곱폭으로 이동한다
- 이중해싱 : 처음 해시 함수로는 해시 값을 찾기 위해 사용하고 두번째 해시함수는 충돌이 발생했을 때 탐사 폭을 계산하기 위해 사용되는 방식이다
해시 맵(Hash Map)
- 자바에서 내부적으로 배열을 통해 구현된 자료구조, key-value 형태로 구현되어 있고 해싱을 통해 인덱스를 구한다
- 내부적으로 Synchronized 키워드 없이 구현되었기 때문에 스레드 간 동기화를 보장하지 않는다. 멀티스레드 환경에서 사용하기 적합하지 않다
- 멀티스레드 환경에서 HashMap을 사용하기 위해 자바는 ConcurrentHashMap 를 통해 스레드간 동기화를 보장한다.
- ConcurrentHashMap은 entry를 조작하는 경우에 해당 entry에만 lock을 걸기 때문에 데이터를 다루느 속도가 빨라 멀티스레드 환경에서 사용하기 적합하고 성능을 향상시킬 수 있다.
Reference
https://www.geeksforgeeks.org/data-structures/
https://blog.chulgil.me/algorithm/
https://opentutorials.org/module/1335/8821
https://suyeon96.tistory.com/31
https://baeharam.netlify.app/posts/data structure/hash-table
https://en.wikipedia.org/wiki/Hash_table#Open_addressing
https://lordofkangs.tistory.com/78

:)