C언어 메모리 구조
C언어의 동작 방식에 대해 더 잘 이해하고 이를 바탕으로 효율적인 C언어 코딩에 더불어 다른 언어의 동작 방식을 이해하는데 바탕이 되고자 C언어 메모리 구조에 대해 알아보려고 한다.
C언어를 컴파일하면 나오는 어셈블리어 코드는 기계어와 C언어의 중간 단계 언어로 어셈블리어 코드를 살펴보면 OS의 로더가 실제로 데이터를 메모리에 어떻게 로드하는지 직접 확인할 수 있다. 그러므로 C언어와 어셈블리어를 비교 분석하면서 C언어 메모리 구조를 알아보자.
#include <stdio.h>
#include <stdlib.h>
const int const_var = 10;
int global_var = 20;
int bss_var;
int main() {
char* str = "Hello World!";
const int const_local_var = 30;
int local_var = 40;
int* dynamic_var = malloc(4 * sizeof(int));
return 0;
}C언어
.arch armv8-a
.file "test.c"
.text
.global const_var
.section .rodata
.align 2
.type const_var, %object
.size const_var, 4
const_var:
.word 10
.global global_var
.data
.align 2
.type global_var, %object
.size global_var, 4
global_var:
.word 20
.global bss_var
.bss
.align 2
.type bss_var, %object
.size bss_var, 4
bss_var:
.zero 4
.section .rodata
.align 3
.LC0:
.string "Hello World!"
.text
.align 2
.global main
.type main, %function
main:
.LFB6:
.cfi_startproc
stp x29, x30, [sp, -48]!
.cfi_def_cfa_offset 48
.cfi_offset 29, -48
.cfi_offset 30, -40
mov x29, sp
adrp x0, .LC0
add x0, x0, :lo12:.LC0
str x0, [sp, 32]
mov w0, 30
str w0, [sp, 24]
mov w0, 40
str w0, [sp, 28]
mov x0, 16
bl malloc
str x0, [sp, 40]
mov w0, 0
ldp x29, x30, [sp], 48
.cfi_restore 30
.cfi_restore 29
.cfi_def_cfa_offset 0
ret
.cfi_endproc
.LFE6:
.size main, .-main
.ident "GCC: (Ubuntu 13.2.0-23ubuntu4) 13.2.0"
.section .note.GNU-stack,"",@progbits
어셈블리어 (arm아키텍쳐, Ubuntu 24.04.1, gcc 컴파일러 사용)
메모리 영역 종류
C언어에는 다음과 같은 메모리 영역이 존재한다.
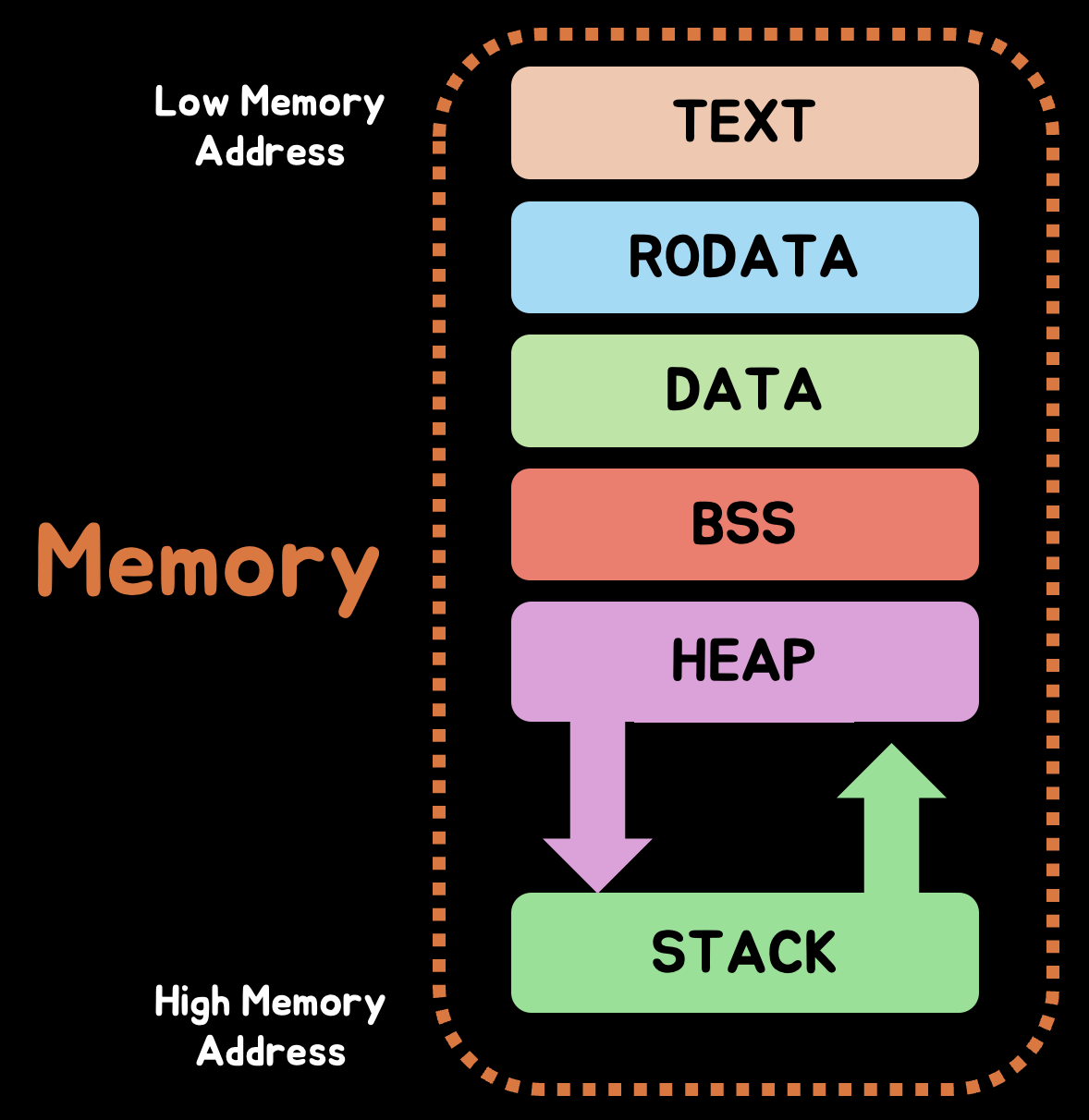
(주의!) 변수이름은 개발자와 컴파일러를 위한 것
뒤의 포스트에서 "변수 XXX는 메모리 영역 XXX에 로드된다"는 표현을 사용할 것이다. 여기에서 오해하면 안되는게 실제 메모리에 로드되는 것은 데이터이지 변수 이름이 아니라는 점이다. int var = 10; 에서 실제로 메모리에 로드되는 데이터는 10이지 var이 아니라는 것이다.
var과 같은 변수이름은 개발자와 컴파일러가 메모리에 할당된 데이터를 가리키기 위해 데이터를 담고 있는 메모리 공간에 이름을 붙인 것이다. 실제로 컴파일러가 컴파일한 어셈블리어를 확인해보면 변수이름이 사용되지 않고 메모리 주소 혹은 데이터 값을 그대로 사용하는 것을 확인할 수 있다.
TEXT 영역
TEXT 영역은 실행코드가 들어가는 읽기 전용 메모리 영역이다. 그렇다면 실행코드가 무엇일까? 어셈블리어를 통해 확인해보자.
.text
.global const_var // const_var 변수 선언 코드
.section .rodata // const_var 변수가 들어갈 영역 정의
.align 2
.type const_var, %object .text
.align 2
.global main
.type main, %function
main:
.LFB6:
.cfi_startproc
stp x29, x30, [sp, -48]!어셈블리어 코드에서 두 번 등장하는 .text 코드는 TEXT 영역에 뒤의 코드를 집어넣겠다는 코드이다. 결과만 말하자면 첫 번째 .text 코드는 TEXT 영역에 어떤 실행코드도 집어넣지 못하지만, 두 번째 .text 코드만 TEXT 영역에 실행코드를 집어넣는다.
첫 번째 .text 코드 다음에는 const_var 변수가 선언된다. 그런데 const_var는 TEXT 영역이 아닌 RODATA 영역으로 로드될 변수이다. 이렇게 되면 첫 번째 .text 코드는 아무런 역할을 하지 못하고 무시된다. 실제로 첫 번째 .text 코드는 없어도 무방한 코드이다.
두 번째 .text 코드 다음에는 main 함수가 선언된다. main 함수는 다른 메모리 영역에 로드되지 않는다. 그러므로 main 함수의 동작을 구성하는 코드가 모두 TEXT 영역에 들어간다.
위의 두 .text 코드의 역할을 통해 TEXT 영역에 로드되는 실행코드에 대해 확인할 수 있다. 실행코드는 다른 메모리 영역에 로드되는 변수를 선언하는 코드를 제외하고 프로그램의 동작을 수행하는 코드이다. 그리고 TEXT 영역은 이 실행코드를 담고 있는 메모리 영역이다.
// TEXT 영역에 로드된 실행코드
int main() {
char* str = "Hello World!";
const int const_local_var = 30;
int local_var = 40;
int* dynamic_var = malloc(4 * sizeof(int));
return 0;
}참고로 STACK과 HEAP에 로드될 변수와 관련된 코드는 실행코드에 포함되는데 왜냐하면 뒤에 설명할테지만 STACK과 HEAP에 데이터를 넣는 방식은 어셈블리어 입장에서 변수를 선언하고 그 변수를 STACK이나 HEAP에 넣는 방식이 아니다. 어셈블리어 명령어를 통해 stack pointer을 조작하거나 malloc 함수를 호출하는 방식을 사용한다. 그리고 stack pointer을 조작하거나 malloc 함수를 호출하는 명령어는 실행코드로 본다.
즉, TEXT 영역에는 소스코드가 그대로 로드되는게 아니라는 것이다. 생각해보면 만약 TEXT 영역에 단순히 모든 소스코드가 로드된다고 하면 다른 메모리 영역에 로드될 변수 데이터가 소스코드에도 존재하고 다른 메모리 영역에도 로드되어 있다면 서로 중복되는 데이터가 로드되어 있으므로 메모리 낭비일 것이다.
TEXT 영역은 읽기 전용 메모리 영역이다. 이는 TEXT 영역에 있는 실행코드를 수정해서 CPU로 하여금 의도하지 않는 작업을 하도록 하는 보안취약점을 예방하기 위해서이다.
RODATA 영역
RODATA 영역은 Read-Only DATA의 줄임말로 말 그대로 읽기 전용 변수를 담는 메모리 영역이다. 그렇다면 어떤 변수가 읽기전용 변수로서 RODATA 영역에 로드될까? 어셈블리어를 통해 확인해보자.
상수
.global const_var
.section .rodata
.align 2
.type const_var, %object
.size const_var, 4
const_var:
.word 10 .section .rodata
.align 3
.LC0:
.string "Hello World!"먼저, const int const_var = 10에서 10이 RODATA 영역에 로드된 것을 알 수 있다. const_var은 값 재할당이 안되는 상수를 담는 변수로 RODATA 영역에 들어가는 것이 자연스럽게 납득이 가는 읽기 전용 변수이다.
하지만 모든 상수가 RODATA 영역에 로드되는 것이 아니다. 전역영역에서 선언된 상수만 RODATA 영역에 로드되고 로컬영역에서 선언된 상수는 STACK 영역에 로드된다. 왜냐하면 로컬영역에 선언되는 변수의 경우 해당 로컬영역의 실행이 끝날 경우 로컬영역에 할당된 메모리가 모두 해제되어야 하기 때문이다. 만약 로컬영역에서 선언된 상수를 RODATA 영역에 로드하면 해당 로컬영역의 실행이 끝나도 그 상수는 계속 메모리 공간을 차지할 것이고 이는 메모리 낭비이다. 아래 어셈블리어 코드를 살펴보면 로컬영역에서 선언된 상수가 일반적인 로컬변수와 다르지 않다는 것을 확인할 수 있다.
mov w0, 30
str w0, [sp, 24]그렇다면 로컬영역에서 const 키워드를 이용해서 상수 선언해도 일반적인 로컬변수와 똑같이 선언이 되던데 로컬영역에서의 const 키워드는 의미가 없는걸까? 로컬영역에서 선언된 상수는 컴파일러가 컴파일을 하는 도중 상수에 재할당이 발생하면 컴파일 에러를 발생시킨다. 즉, 컴파일 단위에서 상수의 재할당을 막는다.
로컬영역에 선언된 상수가 STACK 영역에 로드되기 때문에 상수에 새로운 값을 재할당할 수 있는 재미있는 상황도 발생한다.
#include <stdio.h>
int main() {
const int const_local_var = 10;
int* ptr = (int*) &const_local_var;
*ptr = 20;
printf("%d\n", *ptr);
return 0;
}
=> 20앞서 설명했듯 전역영역에서 할당된 상수는 읽기전용 메모리인 RODATA에 로드되기 때문에 구조적으로 재할당이 불가능하다. 로컬영역에서 할당된 상수도 기본적으로는 재할당이 불가능하다. 하지만 이는 컴파일러 단위의 조치일 뿐이다. 로컬영역에서 할당된 상수는 쓰기가 가능한 STACK영역에 로드되기 때문에 포인터를 이용하면 재할당이 가능하다.
문자열 리터럴
다음으로, char* str = "Hello World"에서 "Hello World"가 RODATA 영역에 들어간 것을 알 수 있다. 심지어 str이 로컬영역인 main 함수의 로컬영역에 선언되었음에도 RODATA 영역에 로드되었다. C언어에서 "Hello World"와 같은 문자열 리터럴은 값을 변경할 수 없는 상수 취급을 받는다. 실제로 아래와 같이 "Hello World"의 값을 바꾸려고 하면 오류가 발생한다. 문자열 리터럴은 RODATA 영역에 들어간다.
char* str = "Hello World!";
str[0] = 'h';
// => segmentation fault (core dumped)문자열 리터럴 선언은 단순히 RODATA 영역에 문자열 리터럴을 로드하는 것에서 끝나는 것이 아니다. RODATA 영역에 로드된 문자열 리터럴을 가리키는 포인터 변수를 STACK 영역에 로드해야 한다. int* ptr = &var;과 같은 일반적인 포인터는 이미 존재하는 데이터의 메모리 값을 포인터 변수에 저장하는 것으로 끝이 난다. 하지만 char* str = "Hello World!";와 같은 문자열 리터럴 선언은 "Hello World!"라는 문자열 리터럴을 RODATA 영역에 로드하는 것 + RODATA 영역에 로드된 문자열 리터럴을 가리키는 포인터 변수 선언까지 해야하는 것이다. 문자열 리터럴 선언이 복잡하기는 한데 어렵게 생각할 것 없다. 포인터를 선언해서 데이터의 주소값을 DATA 영역에 넣는 것까지는 똑같고 이후 문자열 리터럴을 RODATA 영역에 로드하는 것 뿐이다.
만약 똑같은 문자열 리터럴이 중복해서 선언될 경우 중복된 문자열 리터럴이 각각 모두 RODATA 영역에 들어가는 것이 아니라 하나의 문자열 리터럴만 RODATA 영역에 들어간다.
DATA 영역
DATA 영역은 초기화된 전역변수가 로드되는 메모리 영역이다.
.global global_var
.data
.align 2
.type global_var, %object
.size global_var, 4
global_var:
.word 20어셈블리어를 확인해보면 초기화된 전역변수 global_var가 DATA 영역에 할당되는 것을 확인할 수 있다.
DATA 영역의 크기는 컴파일 타임에 결정되어야 한다.
BSS 영역
BSS 영역은 초기화되지 않은 전역변수가 로드되는 메모리 영역이다.
.global bss_var
.bss
.align 2
.type bss_var, %object
.size bss_var, 4
bss_var:
.zero 4어셈블리어를 확인해보면 초기화되지 않은 전역변수 bss_var가 BSS 영역에 할당되는 것을 확인할 수 있다.
DATA 영역과 BSS 영역을 구분하는 이유
그렇다면 전역변수를 굳이 "초기화되지 않은 전역변수"와 "초기화된 전역변수"로 나누어서 다른 메모리 영역에 저장하는 이유는 무엇일까? 초기화되지 않은 전역변수는 용량을 많이 잡아먹지 않아 실행파일의 크기를 효율적으로 줄일 수 있기 때문이다.
먼저 실행파일이란 무엇인가? 실행파일은 어셈블리어 코드를 컴파일러의 링커가 기계어로 컴파일한 기계어 코드를 말한다. 컴파일러를 이용해 gcc test.c 명령어를 실행하면 나오는 a.out 파일이 실행파일이다.
초기화된 전역변수의 경우 초기값을 어셈블리어 코드와 실행코드에 명시해야 한다.(.word 20) 그래야 OS의 로더가 초기값을 읽고 메모리에 변수의 초기값을 로드시켜줄 것이다. 하지만 초기화되지 않은 전역변수의 경우 단순히 0으로 채울 메모리의 크기만 명시해주면 된다.(.zero 4) 컴파일러의 입장에서는 실행파일을 만들 때 초기값을 저장하는 것보다 0으로 채울 변수의 크기를 저장하는 것의 용량이 더 작은 모양이다.
초기화되지 않은 전역변수는 이와 같이 자동으로 BSS에 메모리 공간을 확보해서 0으로 채우기 때문에 전역변수는 지역변수와 달리 초기화하지 않아도 자동으로 0으로 초기화되는 것이다.
STACK 영역
STACK과 HEAP은 이전의 TEXT, RODATA, DATA, BSS 메모리 영역과는 성격이 완전히 다르다.
TEXT, RODATA, DATA, BSS 메모리 영역은 OS의 로더가 어셈블리어를 읽고 미리 데이터를 이 메모리 영역에 로드시켜놓는다. 그리고 이 메모리 영역에 로드된 데이터들은 프로그램이 끝날 때까지 계속해서 사용된다.
하지만 STACK, HEAP 메모리 영역은 프로그램의 런타임 도중에 데이터가 동적으로 로드되기도 하고 삭제되기도 한다.
STACK 메모리 영역은 이름 그대로 FIFO 방식의 stack 자료구조를 가지고 있다. 이는 caller 함수에서 callee 함수를 호출하고 callee 함수가 종료되면 다시 caller 함수로 돌아간다는 함수의 실행 과정과 stack 자료구조의 FIFO 설계구조가 서로 알맞기 때문에 STACK 메모리 영역에서 stack 자료구조를 사용하는 것이다.
STACK 프레임
STACK에는 프로그램의 런타임 중 호출된 함수를 실행하는데 필요한 정보를 담고 있는 STACK 프레임이 들어간다. 이 STACK 프레임에는 함수의 매개변수, 지역변수, 함수가 끝나면 돌아갈 명령어의 주소를 담고 있는 리턴 주소 등 함수의 실행 과정에서 필요한 데이터들이 들어있다.
참고로 함수의 실행 과정에서 필요한 데이터들이 들어있는 것이지 함수 실행 코드가 들어있는 것이 아니다. 실제로 CPU가 읽어서 실행하는 코드는 앞서 살펴본 것처럼 TEXT 영역에 들어있다.
컴파일 단계에서 STACK의 크기가 결정된다
STACK에 대해 공부를 하다보면 STACK의 크기는 컴파일 단계에서 결정된다는 이야기를 많이 접한다. 실제로 어셈블리어를 살펴보면 STACK을 사용하는 데이터의 경우 그 데이터가 저장되어 있을 STACK의 주소를 컴파일러가 미리 알아서 변수이름 대신 그 STACK 주소를 사용하는 것을 볼 수 있다.
mov w0, 30
str w0, [sp, 16]
(const_local_var이 저장될 STACK의 주소를 알고 있음)방금 위에서는 STACK, HEAP 메모리 영역은 프로그램의 런타임 도중에 데이터가 동적으로 로드, 삭제된다고 했는데 프로그램을 실행하지도 않는 컴파일 단계에서 컴파일러가 어떻게 STACK 영역의 크기를 알 수 있다는 걸까?
그 이유는 STACK 프레임의 크기는 프로그램을 실행해보지 않아도 컴파일러가 확인할 수 있기 때문이다. STACK 프레임은 지역변수, 매개변수, 리턴주소 등으로 구성되어 있다고 했다. 그리고 이 데이터들은 굳이 프로그램을 실행해보지 않아도 크기를 알 수 있는 데이터들이다. 그렇기 때문에 컴파일러는 STACK 프레임의 크기를 컴파일 단계에서 알 수 있고 이를 바탕으로 각 지역변수의 STACK에서의 위치, 전체 STACK 영역의 크기를 계산할 수 있는 것이다.
참고로 컴파일 단계에서 알 수 없는 데이터들은 뒤에 설명할 HEAP 영역에 저장된다.
VLA
void foo(int user_input) {
int arr[user_input]
}위와 같이 지역영역에서 배열을 선언하는 것은 컴파일 타임에 user_input 값을 알 수 없기 때문에 불가능해보인다. 하지만 실제로 코드를 실행시켜보면 실행이 되는 것을 확인할 수 있는데 이는 C99 버전의 컴파일러부터 적용된 VLA 덕분이라고 한다. VLA 덕분에 컴파일 타임에 크기가 결정되는 것이 아닌 런타임에 크기가 결정되는 배열을 선언할 수 있다.
HEAP 영역
HEAP 영역은 런타임에 동적으로 할당되는 데이터들이 로드되는 메모리 영역이다. malloc, new 등의 함수나 연산자를 통해 HEAP 영역에 메모리 공간을 할당 받고 그 메모리 공간에 원하는 변수를 넣을 수 있다.
HEAP 영역은 STACK 영역과 같이 런타임 중에 데이터가 로드되기도 하고 삭제되기도 하는 동적인 메모리 영역이지만, STACK 영역에 들어가는 스택 프레임의 크기는 컴파일 때 결정이 되기 때문에 STACK 영역의 크기는 컴파일 단계에서 결정되지만 HEAP 영역에 들어가는 데이터 자체가 런타임 단계에서 결정되기 때문에 HEAP 영역의 크기는 결정지을 수 없다.
동적 데이터를 가리키는 포인터
int main() {
scanf("%d", &userInputNum);
int* arr = (int*) malloc(sizeof(int) * userInputNum);
}오해하면 안되는게 malloc을 통해 할당한 메모리는 HEAP 메모리 영역에 들어가지만 그 메모리 영역을 가리키는 포인터 변수는 전역변수로 선언된 경우에는 DATA 영역, 지역변수로 선언된 경우에는 STACK 영역에 들어간다는 점이다. 실제 데이터와 포인터 변수를 따로따로 생각한다는 점은 문자열 리터럴과 같다.
