지난번에 포스팅한 정렬들은 통상적으로 Θ(n**2)의 복잡도를 가지는 정렬이였다면
이번에 포스팅할 정렬들은 쉽게말해 더 고급(?)정렬이라 볼 수 있다.
여기서부터는 재귀 개념이 사용된다.
1. 합병 정렬(Merge Sort,병합 정렬)
책에서는 합병이 아닌 병합이라 표현하지만 통상적으로 합병이라 많이 쓰기 때문에 표현을 정정해서 올렸다.
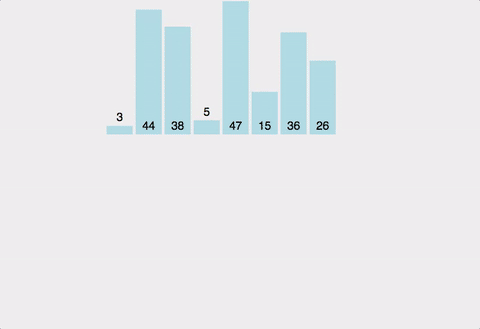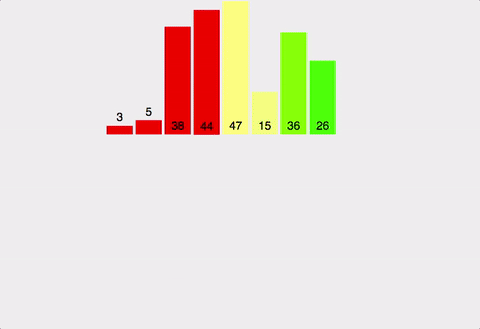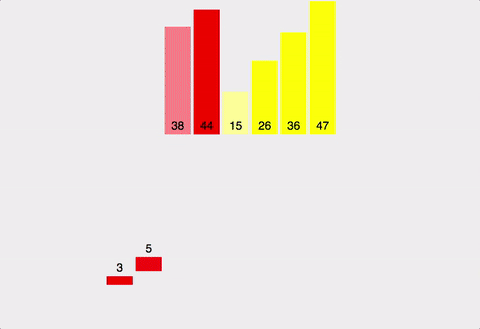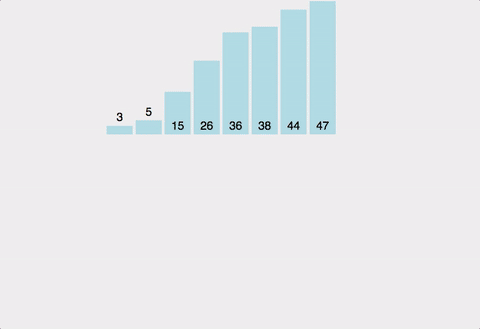
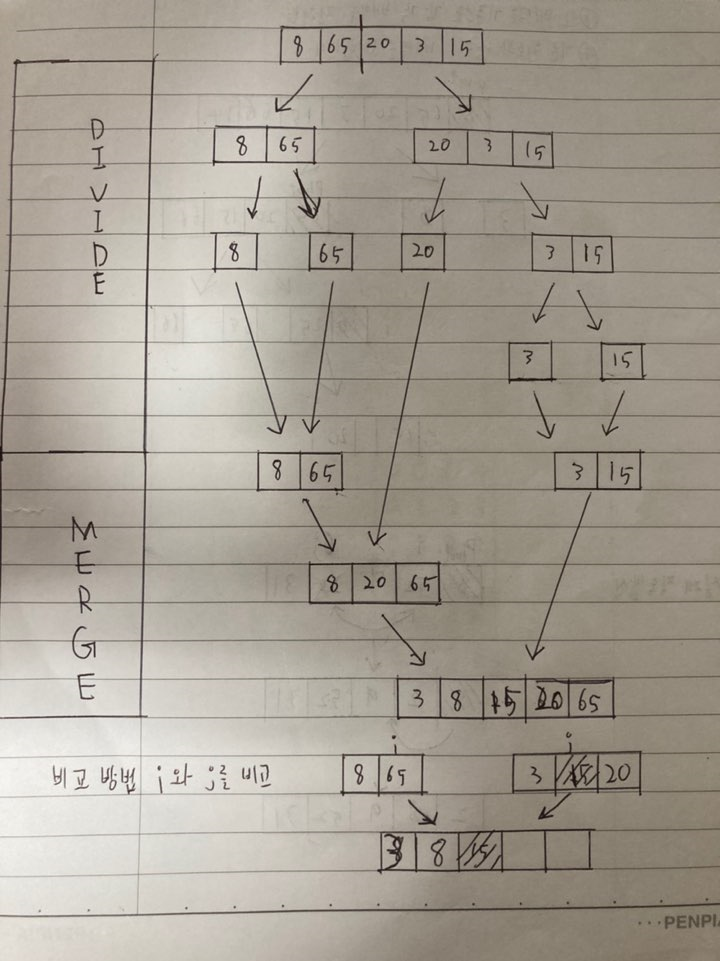
합병 정렬은 배열을 반으로 나눈 후 전반부와 후반부를 각각 독립적으로 정렬하고 이걸 다시 합병하는 합병정렬이다.
-
배열을 반으로 나눈다.
-
나눠진 배열을 다시한번 반으로 나눈다.
-
이렇게 모든 배열이 하나가 될 때 까지 나눈 후
-
다시 나눠진 양 배열의 값을 하나씩 비교하면서 합병시킨다.
-
합병 시키는것을 반복하여 다시 정렬된 완전한 배열로 만든다.
이 개념이 햇갈리수도 있지만 원리를 보면 생각보다 쉽다.
전반적인 과정을 그림으로 표현한것이다.
합병 방법은
양 배열은 이미 완전히 정렬이 되면서 합병을 진행하기 때문에 완전히 정렬이 되어있는 상태이다.
양 배열의 A배열과 B배열이 있을 때 i = 0, j = 0으로 두고
A[i]와 B[j]를 비교하여 A[i]가 크면 A[i]를 넣고 i++을 한다.
이 과정을 반복하여 두 배열을 합병한다.
합병 과정의 시간 복잡도는
T(n) if(n == 1)이면 상수만큼의 복잡도를 가지지만
그 이상부터는 2T(n / 2) + cn의 복잡도를 가진다.
2 * T(n / 2)를 하는 이유는 n을 반으로 나눠서 다시 합병 정렬을 실행하는데(재귀) 이 때 당연히 다시 정렬해야할 배열이 2개가 되기 때문에 2를 곱해주는 것이다.
그리고 c는 합병에 쓰이는 시간을 충분히 잡아주기 위해 곱해준다. 비교의 횟수만으로 수행 시간을 분석할려면 c=1로도 충분하다.
T(n) = 2T(n / 2) + cn이다. 시간 복잡도를 계산하면
T(n) <= 2 * T(n / 2) + cn
T(n/2) = 2 * T(n / 4) + c(n / 2)일때,
<= 2 * T(n / 2) + cn
<= 2(2 * T(n / 4) + c(n / 2)) + cn = 2**2 * T(n / 2**2) + 2cn
<= 2**2(2T(n / 2**3_ + c(n / 2**2) + 2cn = 2**3 * T(n / 2**3) + 3cn
...
<= 2**k * T(n / 2**k) + kcnn = 2**k로 가정했을 때
= nT(1) + kcn = an + cnlog2(n) = Θ(nlog(n))이 된다.
T(1)은 위에서 설명했듯이 상수의 복잡도를 가지기 때문에 상수 a로 바꿔줬다.
그리고 n = 2**k 이기 때문에 log2(n) = k이다.
n = 2**k로 가정하는 이유는 일반적인 방법으로는 수행 시간을 따질 때 일반성을 잃지 않기 때문이다.
어떤 정수 n에대해 n과 2n 사이에 2k 있다면 즉 n < 2k < 2n이라면 n과 2n은 크기가 두 배 차이가 나는데 두 배 차이가 나는 입력에 대해서는 다항식 시간이 걸리는 모든 알고리즘은 같은 복잡도를 가지기 때문이다.
T(n) = Θ(n**p) (p는 상수) -> T(2n) = Θ((2n)**p) = 2**pΘ(n**p) = Θ(n**p) 이와같은 예시를 보면
시간 복잡도 계산은 사소한 값을 버리기 때문에 이와같이 같은 복잡도를 가질 수 있고,
n = 2**k같은 전제에도 일반성을 잃지 않을 수 있는 것이다.def mergeSort(alist):
if len(alist) == 1:
return alist
m = len(alist) // 2 #가운데 값을 계산
LeftList = m[:m]
RightList = m[m:]
LeftList = mergeSort(LeftList)
RightList = mergeSort(RightList)
alist = merge(LeftList, RightList)
return alistdef merge(leftList, rightList):
alist = []
i = 0
j = 0
while(i < len(leftList) and j < len(rightList)):#좌측 or 우측이 끝에 다다르면 반복문 종료
if(leftList[i] < rightList[j]):
alist.append(leftList)
i++
else:
alist.append(rightList)
j++
alist += leftList[i:]#좌측 배열이 남은 경우
alist += rightList[j:]#우측 배열이 남은 경우
return alist2. 퀵 정렬
퀵 정렬은 평균적으로 가장 좋은 성능을 가져 현장에서 가장 많이 쓰는 정렬 알고리즘이다.
- 배열의 끝 즉 가장 우측또는 좌측의 값을 선택
- 선택값보다 작은 값은 좌측 큰 값은 우측에 위치
- 위 과정을 재귀방식으로 반복하여 정렬 되면 병합
위와 다르게 코드부터 보자면
def paquickSort(alist):
if len(alist) <= 1: return alist
m = len(alist) // 2
alist = partition(alist)
leftList = quickSort(alist[:m])
rightList = quickSort(alist[m + 1:])
alist = leftList + [pivot] + rightList
return alistdef partition(alist):
m = len(alist) - 1
i = 0
j = m - 1
pivot = alist[m]
while(i != j):
if(alist[i] < pivot):
if(alist[j] > pivot):
alist[i], alist[j] = alist[j], alist[i]
i++
j--
else: j--
else: i++
alist[i], alist[m] = alist[m], alist[i]
return alist수행시간을 분석해보자면 최악의 경우 Θ(n ** 2)의 시간 복잡도를 가지지만 이런 경우는 pivot값을 기준으로 분활할 때 둘중 한곳이 지속적으로 하나도 없는 경우가 발생해야 한다.
이런 경우는 흔한 경우가 아니기 때문에 평균적인 경우에는 Θ(nlog(n))의 복잡도를 가진다.
