띄어쓰기가 되어 있지 않은 문자열을 비교하여 중복인지 여부를 판단하는 프로세스를 만들었다.
주로 행정안전부 - 인허가 데이터에서 '중식 음식점' 카테고리에 있는 상호명을 가져와 비교하였다.
- 데이터 분석 툴: postgreSQL(SQL), Jupyter Notebook (Python)
- 데이터 출처: 인허가 데이터 등을 참고로 만들어진 장소 데이터 테이블 일부
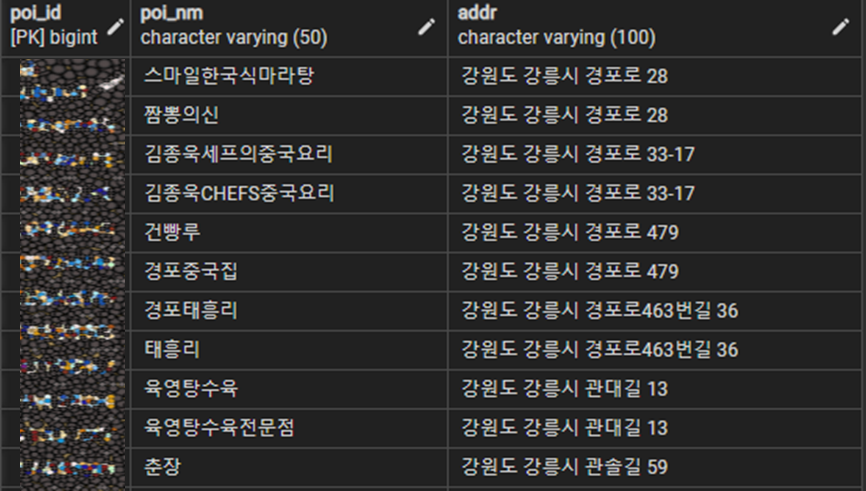
- 데이터 예시
Column – poi_id(고유id), poi_nm(상호명), addr(새주소)로 구성
1. 전처리 단계
(1) 특수문자 제거
상호명에 있던 특수문자를 제거한다.

ex) MR.탕수육 → MR탕수육
중국집-실크로드 → 중국집실크로드
맛있는짜장&짬뽕 → 맛있는짜장짬뽕
(2) 맞춤법 교정
네이버 맞춤법 검사기로 교정해주는 spell_checker 라이브러리 설치 후 교정

ex) 마라싸롱 → 마라살롱
헬로우마라 → 헬로마라
쭝국집 → 중국집
2. 데이터 분석
(1) 상호명 토크나이징 후 결과 비교
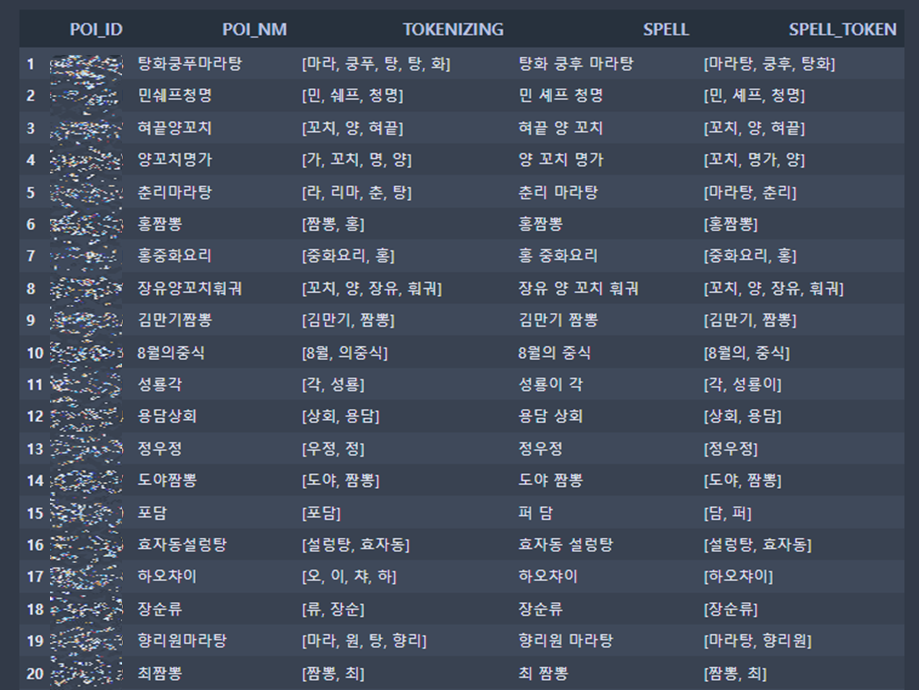
컬럼 정보
- POI_ID : 고유 ID
- POI_NM: DB에 등록된 상호명
- TOKENIZING: POI_NM을 Okt 라이브러리로 토크나이징
- SPELL : POI_NM을 네이버 맞춤법 교정기로 단어 교정
- SPELL_TOKEN : SPELL을 Okt 라이브러리로 토크나이징
데이터 탐색
-
POI_NM을 바로 TOKENIZING하는 것 보다 맞춤법 교정 및 띄어쓰기 후 TOKENIZING을 했을 때 품질이 더 높았다.
ex. 춘리마라탕: ‘춘‘, ‘리‘, ‘마라’, ‘탕’ vs. ‘춘리’, ‘마라탕’ 8월의중식: ‘8월‘, ‘의중식‘ vs. ‘8월의’, ‘중식‘ -
자주 등장하는 키워드가 어떤건 지 확인하기 위해 SPELL_TOKEN을 하나의 말뭉치로 저장한 후 최빈어를 확인하였다.
(2) 최빈어 분석을 통한 주요 키워드 추출

SPELL_TOKEN에 있는 단어들을 하나의 리스트로 묶은 후(말뭉치) 키워드 빈도순으로 나열한 결과
'반점': 6255, '짬뽕': 5792, '양': 2592, '꼬치': 2534, '짜장': 2399, '마라탕': 1646,
'중화요리': 1029, '손': 979, '차이나': 965, '각': 703, '마라': 702…

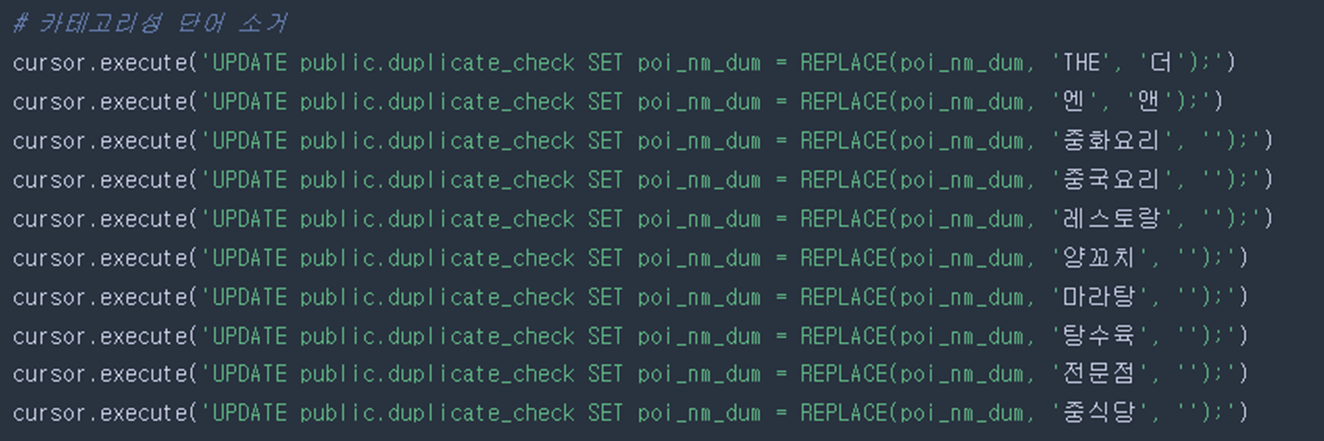
(3) 카테고리성 단어 소거
키워드 중 ‘중식’과 연관된 카테고리성 키워드(반점, 짬뽕, 중화요리 등)를 소거 후 브랜드성 단어만 남김

ex) 청솔반점 → ‘반점’ 제거 → ‘청솔’만 남음
(4) Tri-gram으로 텍스트 유사도 측정
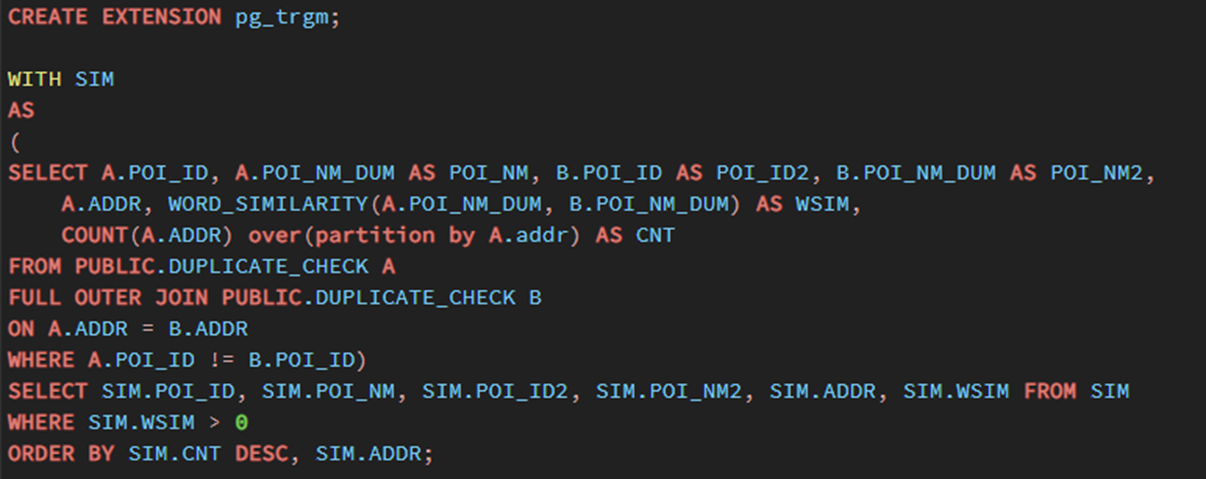
- 자연어 처리 기법 중 n-gram 언어 모델은 n개의 연속 문자를 토큰화한 후 비교대상인 문자열과 비교해 단어의 유사도를 측정하는 방식이다.
- 이번 유사도 측정에는 3개의 문자씩 토큰화하는 Tri-gram을 사용하였고 postgreSQL에 내장된 pg_trgm이라는 모듈을 추가 설치한 후 분석하였다.
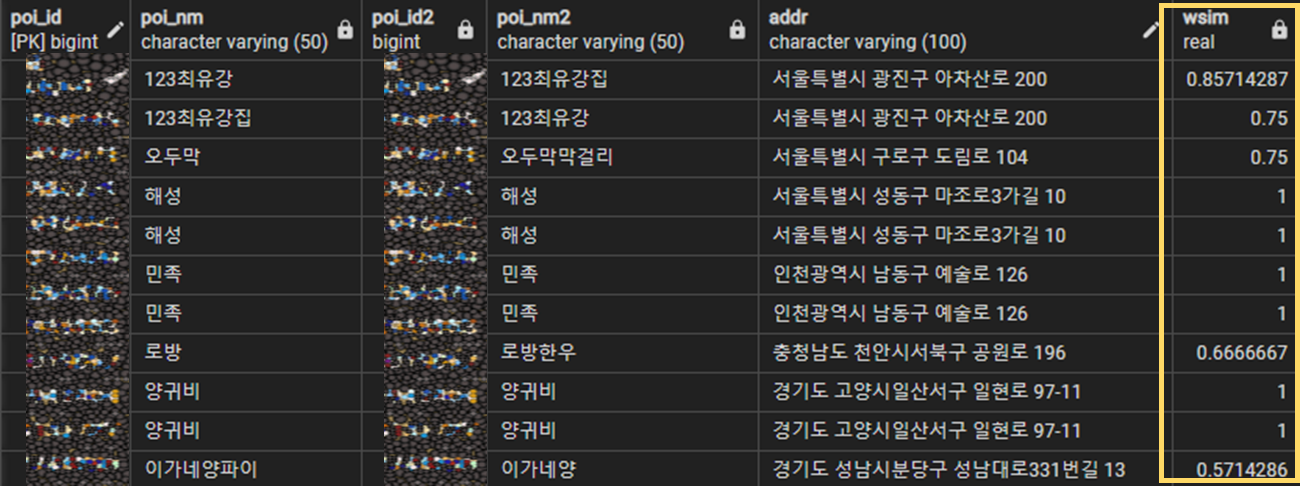
- 사용할 문자열(poi_nm, poi_nm2)은 카테고리성 키워드를 소거한 문자열을 사용하였다.
3. 데이터 분석 결과
-
동일 주소(addr)를 갖는 상호명의 텍스트 유사도 (wsim) 측정 결과 0이 아닌 값이 약 25% 검출되었다!
(wsim이 1에 가까울 수록 문자열 사이의 유사도가 높다는 의미. wsim = 1은 두 문자열이 완전 동일.) -
기존 키워드 소거법만으로 중복을 측정하던 방식보다 유사도로 비교하는 방식이 2배 이상의 중복 검출 결과를 내놓아 작업 퀄리티가 훨씬 상승했다.
-
다만 유사도 측정 방식의 경우 값이 0이상이라고 해도 반드시 중복이라고 판단할 수는 없기 때문에 검수 시간이 좀 더 소요되는 편이다.
