문제 1
프로그래머스(정렬) : K번째 수
참조 링크 : https://programmers.co.kr/learn/courses/30/lessons/42748

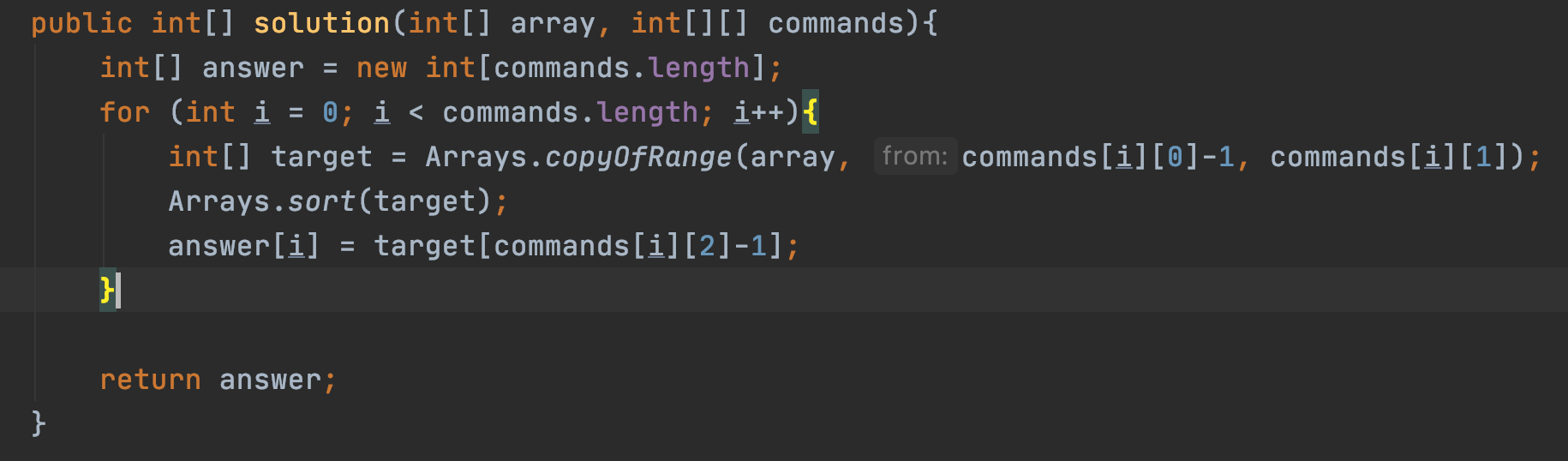
내 코드
프로그래머스 - K번째 수
배열의 일부분만 핸들링하는 것이 핵심인 것 같다.
CopyOfRange
- 전달받은 배열의 지정된 범위에 해당하는 요소만을 새로운 배열로 복사하여 반환

배열과 시작 인덱스, 끝 인덱스를 인자로 받아서 배열을 리턴한다.
문제 2
프로그래머스(정렬) : 가장 큰 수
참조 링크 : https://programmers.co.kr/learn/courses/30/lessons/42746
내 코드
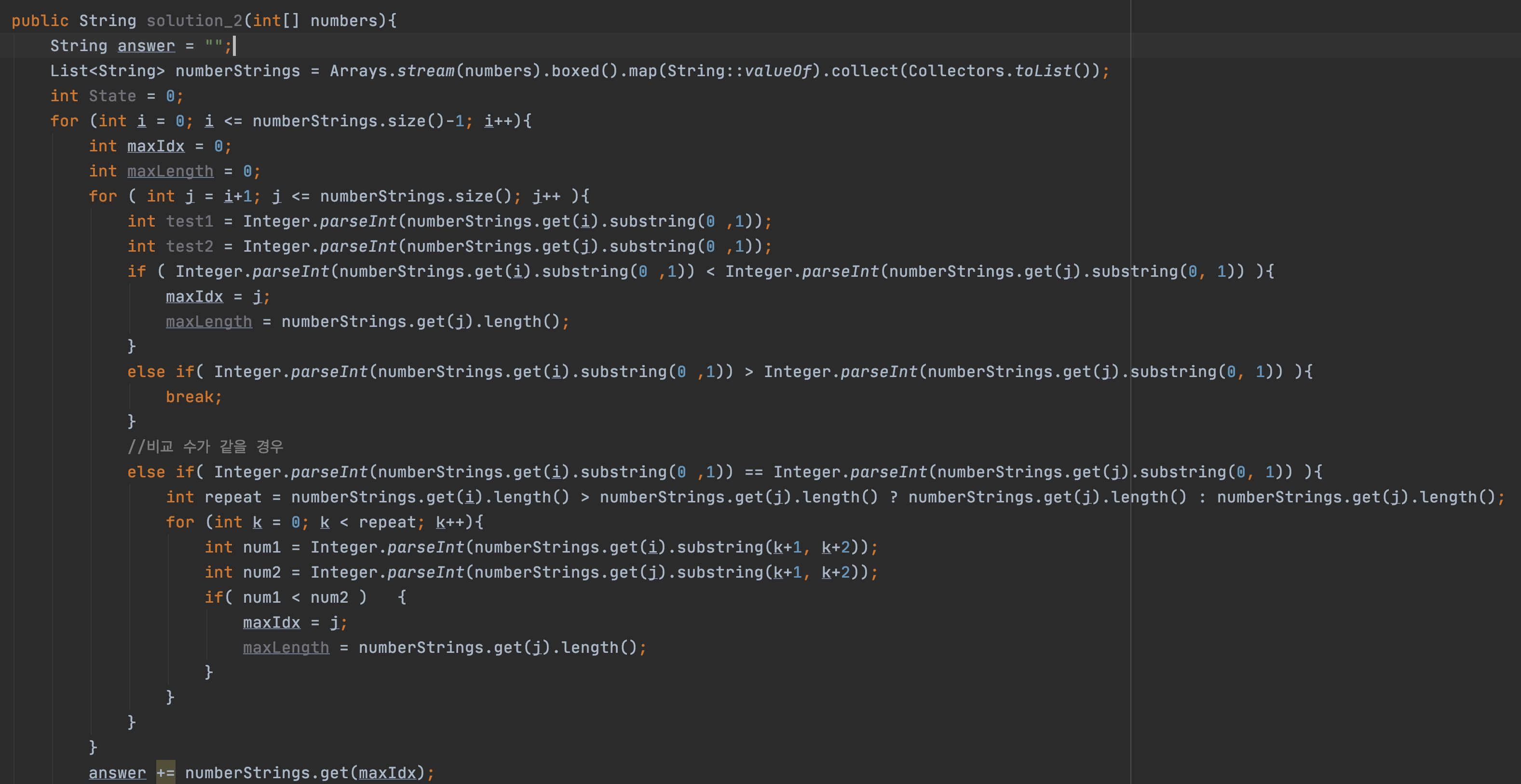
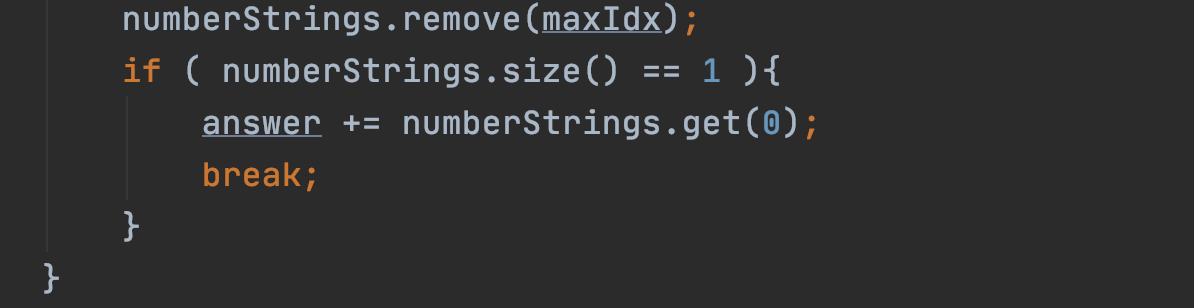
보다시피 안되는 걸 억지로 계속 끼워 맞추려 했던 흔적들이 보인다.
무슨 생각으로 코드를 이렇게 짰느냐 한다면
반복문을 돌면서 최대 값 찾는다.
최대 값의 문자열 길이도 같이 비교해서 자리 수까지 잘라서 최대 값을 찾으려고 했다.
그리고 찾은 값은 배열에서 지운다.
곳곳에서 IndexBoundException이 났고 결국 포기했다.
정답
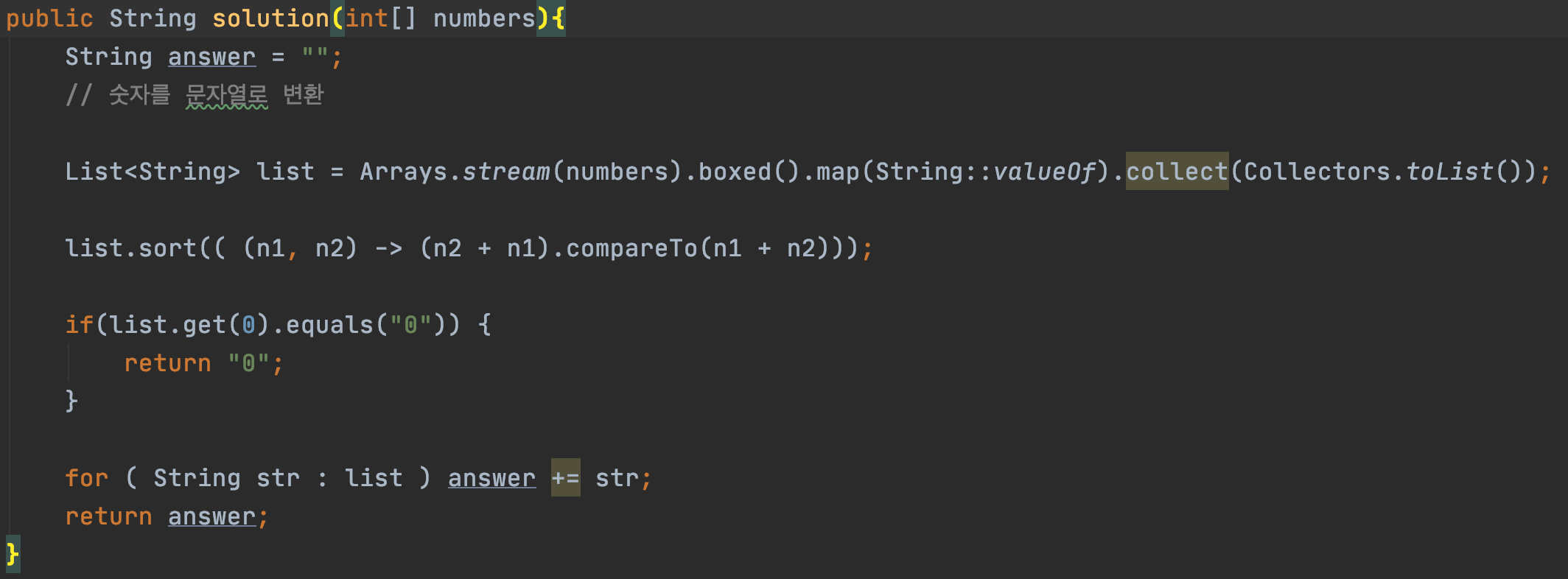
정답을 찾아보고 참 많이 놀라웠다.
왜 이런 생각을 못했을까 생각도 들었고 문제를 풀기 전에 생각을 좀 더 많이 해봐야겠다는 생각을 했다.
위 코드에서 핵심은 문자열 1, 2 를 붙인 것과 문자열 2, 1을 붙여서 비교하는 것이 핵심이다.
compareTo는 문자열도 정렬하고, 앞자리부터 차례차례 한 자리씩 비교한다.
즉, A : 6, B : 10 일 때,
(B+A).compareTo(A+B) 를 하면
(10+6).compareTo(6+10)이고 정렬 하면
B는 뒤로 밀린다.
문제 3
프로그래머스(정렬) : H-Index
참조 링크 : https://programmers.co.kr/learn/courses/30/lessons/42747

정답
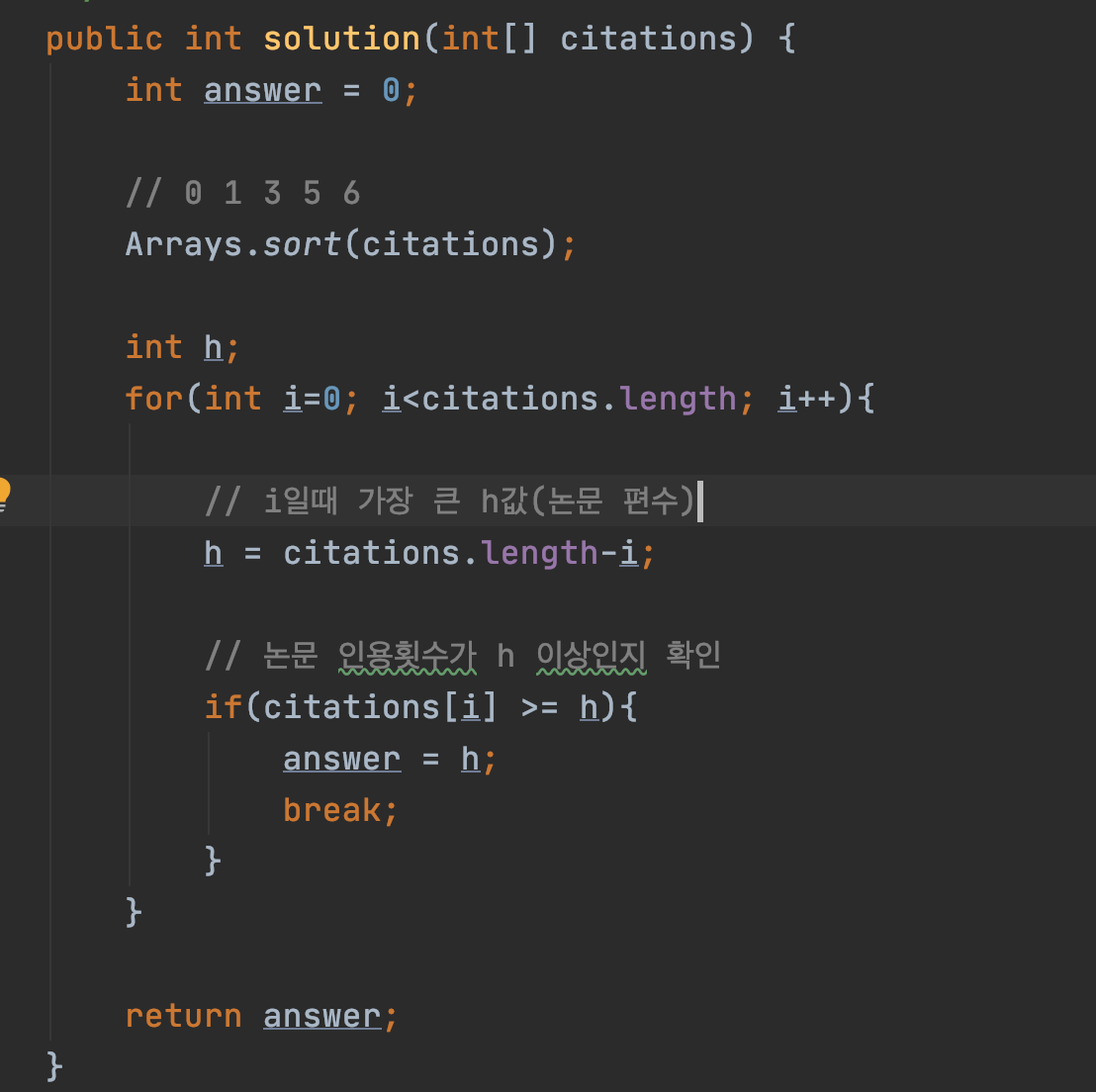
논문이 H-Index보다 커질 때까지 반복한다.
H-Index의 최대 점수는 배열의 길이와 비례한다.(배열의 길이가 6이면 H-Index는 0~6이다.)
원소 하나가 검사 범위에서 제외될 때마다 H-Index의 점수는 줄어든다.
즉, 논문의 인용 값으로 오름차순 후 H-Index보다 논문의 인용 값이 커질 때까지 반복한다.
반복 시 마다
H-Index : 총 논문 갯수 - 1
논문 인용 값 : 논문[i]
