

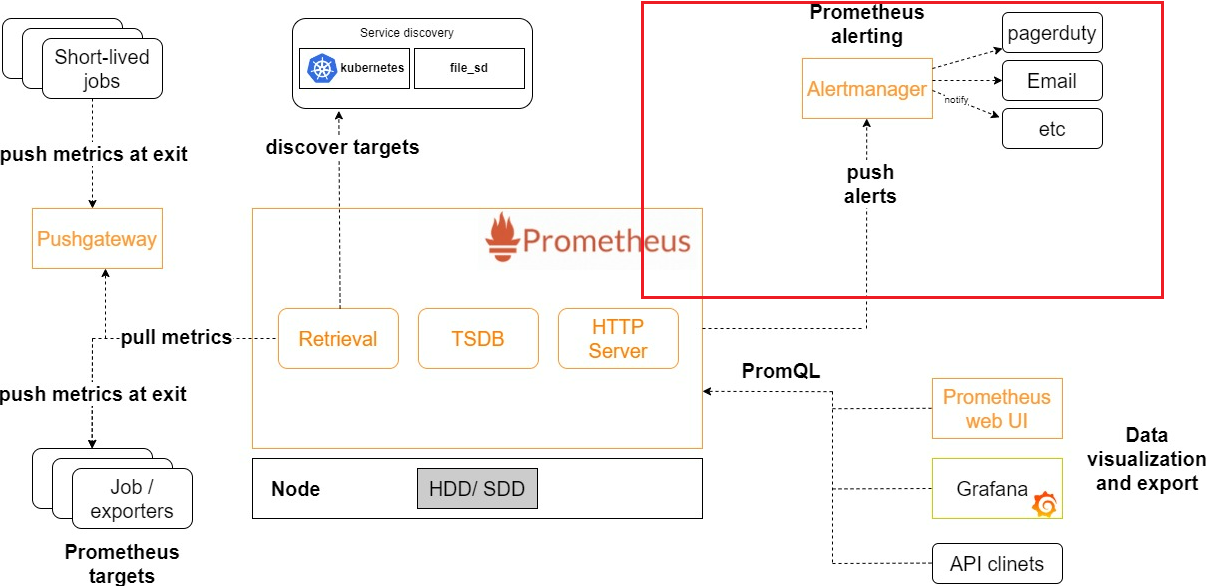
얼럿매니저(Alertmanager)
프로메테우스 스택은 프로메태우스(모니터링), 그라파나(시각화), 얼럿매니저(이벤트 알람)등이 구성되어 배포된다.
수집한 metric을 통한 모니터링 및 시각화도 중요하지만, 이에 해당하는 Metric과 지정된 Rule 통하여 발생되는 이벤트 내용을 알림 통보하는 Alert 기능도 중요하다.
얼럿매니저는 프로메테우스에서 발생한 Alert을 얼럿매니저에서 확인하고, 이러한 내용을 사용자한테 알림 메시지를 보낼 수 있게 하는 서비스 이다.
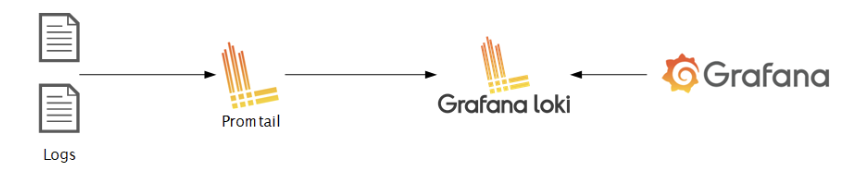
로깅시스템
여러 Pod에서 발생하는 로그를 통합 서버에서 수집하고 이를 그라파나를 통해 확인 할 수 있는 시스템이다.
일반적으로 파드에서 발생하는 로그를 kubectl log 명령어로 확인 할 수 있지만
로그 파일의 최대 크기 제한 및 종료된 Pod의 로그는 확인 할 수 제한이 있다.
따라서 이러한 로깅 시스템을 구성하여 쿠버네티스 클러스터에서 발생하는 로그를 통합 수집하고 이를 확인하여 이를 통하여 효과적이고 안정적인 서비스를 운영 할 수 있다.
목표
이번 6주차 스터디에서는 프로메테우스 스택의 얼럿매니저를 사용하여 이벤트 메시지 전달, PLG Stack(Promtail + Loki + Grafana)을 사용하여 클러스터의 로그를 조회 및 확인하는 방법을 학습할 예정이다.
얼럿매니저 슬랙 연동
얼럿매니저의 경우 프로메태우스 스택에 포함되어 있어 스택 배포 후 바로 확인 할 수 있다.
기본으로 제공하는 UI가 다소 직관적이지 못하여 karma 컨테이너를 설치하면 조금 더 직관적이고 보기 좋은 얼럿매니저 UI를 사용할 수 있다.
# 실행
docker run -d -p 80:8080 -e ALERTMANAGER_URI=https://alertmanager.$KOPS_CLUSTER_NAME ghcr.io/prymitive/karma:latest
#[자신의 PC] 얼럿매니저 대시보드 karma 웹 접속 주소 확인
echo -e "karma Web URL = http://$(aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text)"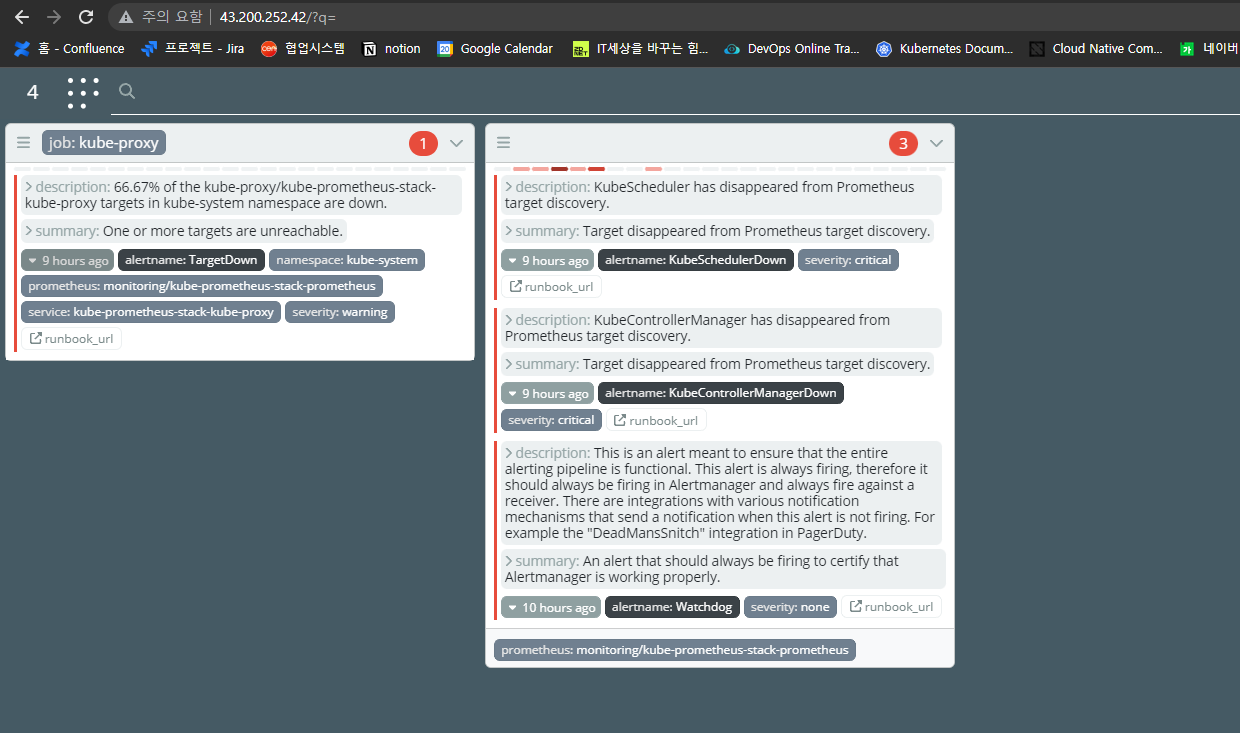
PLG Stack 설치 및 사용
Loki 설치
#Loki 설치
kubectl create ns loki
# Repo 추가
helm repo add grafana https://grafana.github.io/helm-charts
# 파라미터 설정 파일 생성
cat <<EOT > ~/loki-values.yaml
#해당 PV에 수집한 log 파일 저장.
persistence:
enabled: true
size: 20Gi
serviceMonitor:
enabled: true
EOT
# 배포
helm install loki grafana/loki --version 2.16.0 -f loki-values.yaml --namespace loki
Promtail 설치
# 파라미터 설정 파일 생성
cat <<EOT > ~/promtail-values.yaml
serviceMonitor:
enabled: true
config:
serverPort: 3101
clients:
- url: http://loki-headless:3100/loki/api/v1/push
#defaultVolumes:
# - name: pods
# hostPath:
# path: /var/log/pods
EOT
# 배포
helm install promtail grafana/promtail --version 6.0.0 -f promtail-values.yaml --namespace loki
노드에서 작동하는 컨테이너의 로그는 /var/log/pods 경로에 저장된다.
promtail는 Pod의 로그를 해당 경로에서 수집.
- Master Node에서 수집되는 Pod의 로그(/varlog/pods)
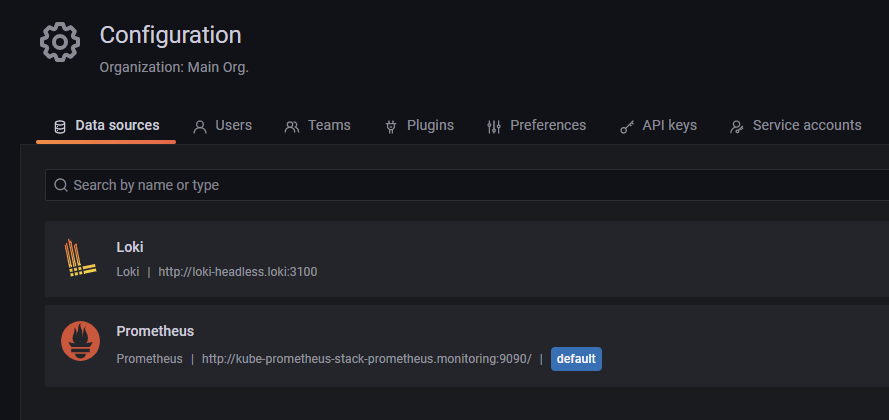
그라파나 데이터 소스 추가
기존에는 프로메테우스만 적용되어 있었지만, Loki를 추가하여 현재 Loki, 프로메테우스 두개의 데이터 소스로 구성
Nginx 로그 확인
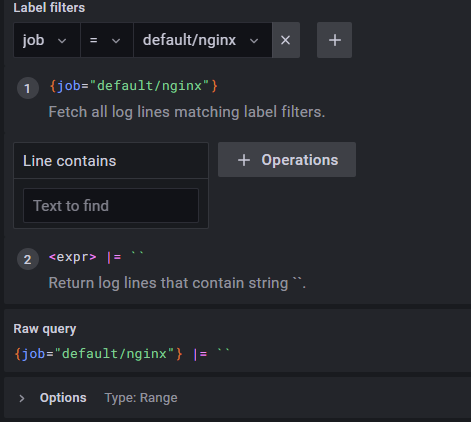
Explore > Label filters > Job : default/nginx > Run query
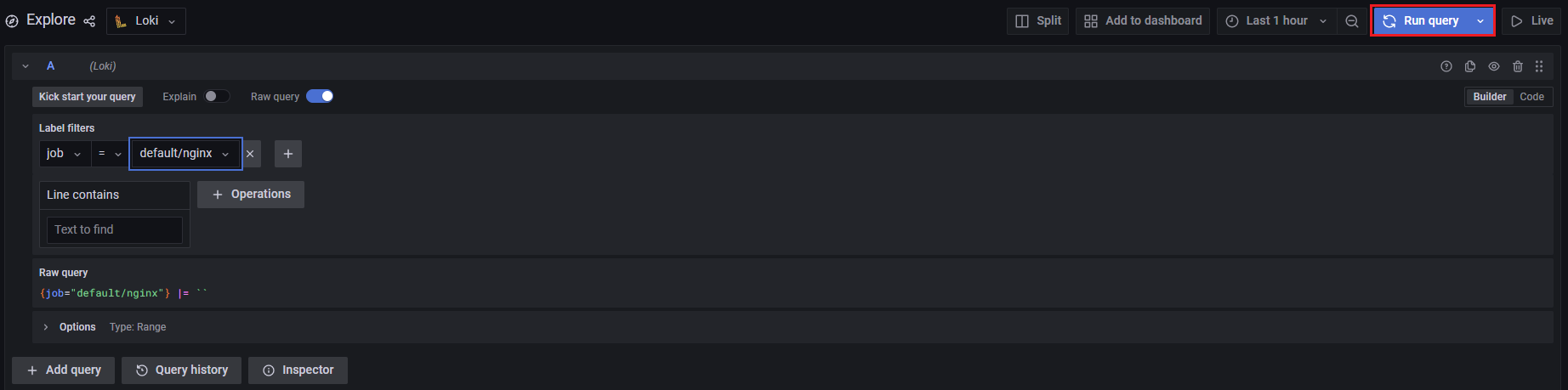
- Nginx의 access.log 확인
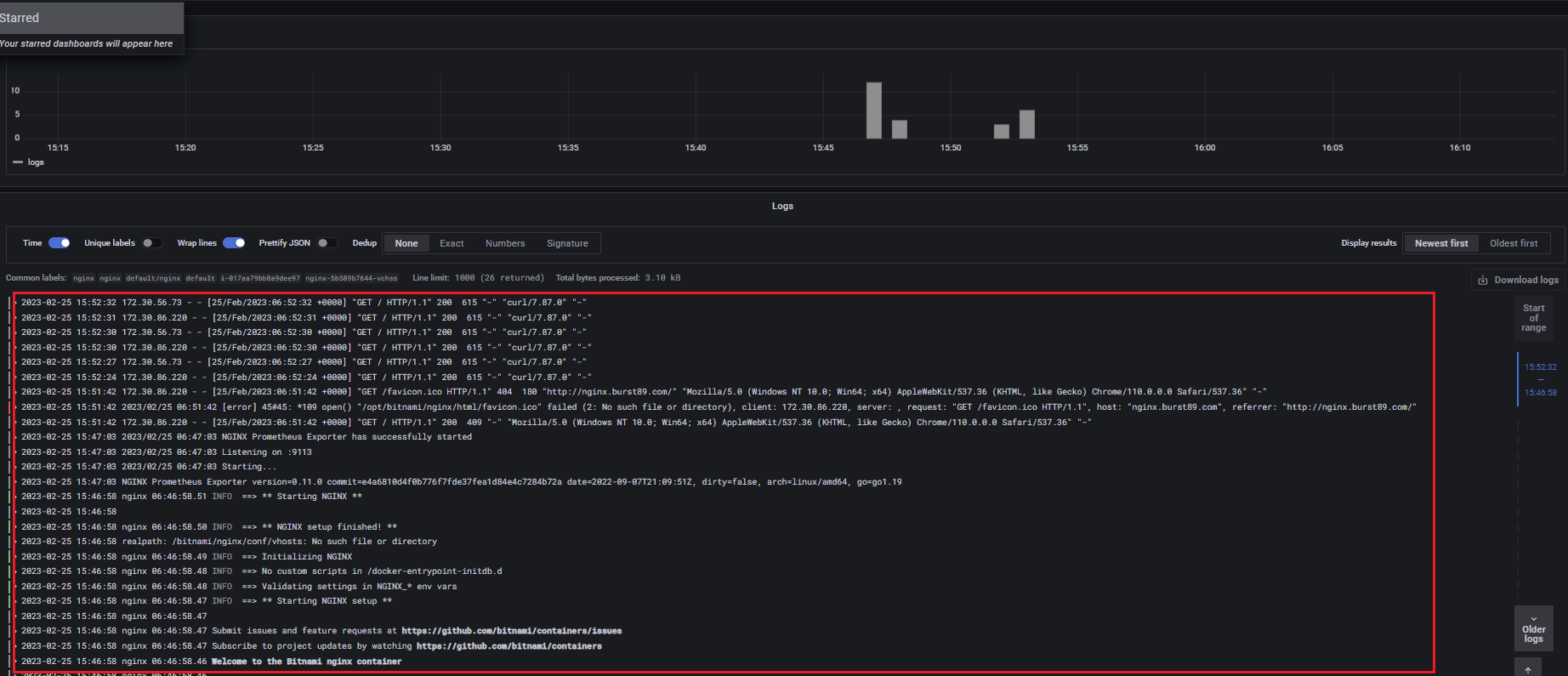
과제
[과제1]책 367~372페이지 - 사용자 정의 prometheusrules 정책 설정 : 파일 시스템 사용률 80% 초과 시 시스템 경고 발생시키기 ⇒ 직접 실습 후 관련 스샷을 올려주세요
- 현재 구성되어 있는 rule의 정보 중 filesystemoutofspace 부분 확인
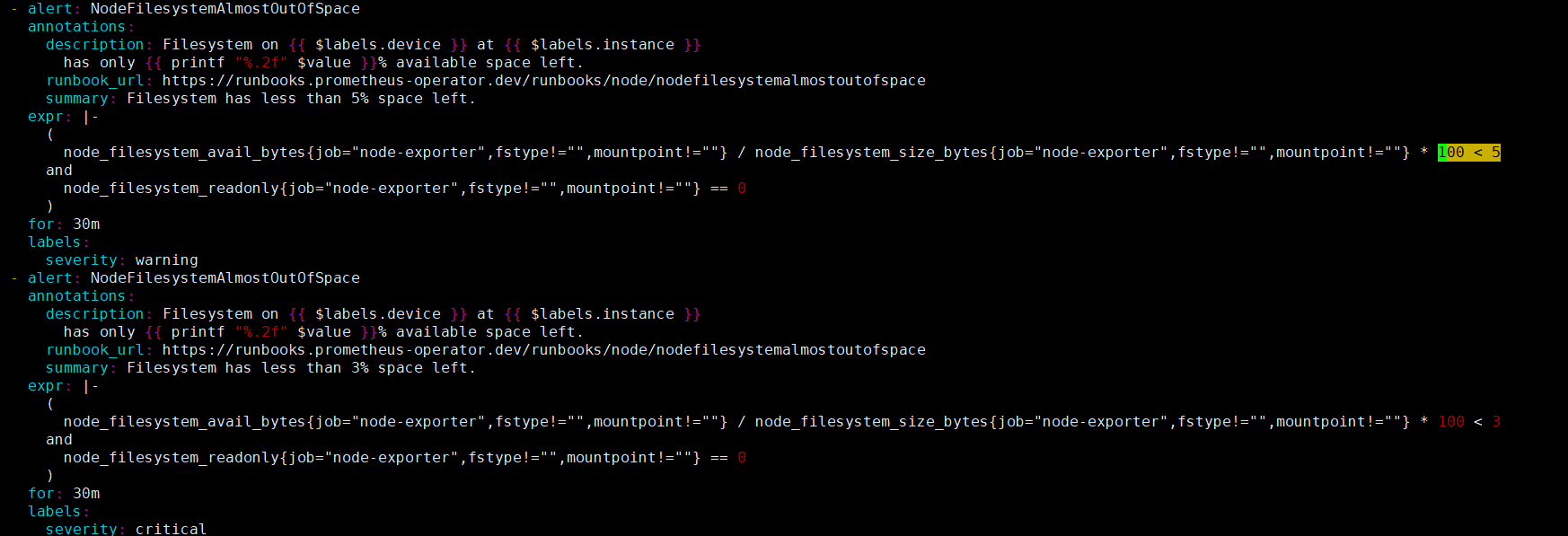
- 기존 룰을 복사사여 시간 1분 , 20%미만이면 경고 발생 룰 수정

- 추가 된 룰 적용

- 프로메테우스 alert에서 확인

- 더미파일을 사용하여 노드의 파일 사용량 80%초과
- Master Node의 filesystem
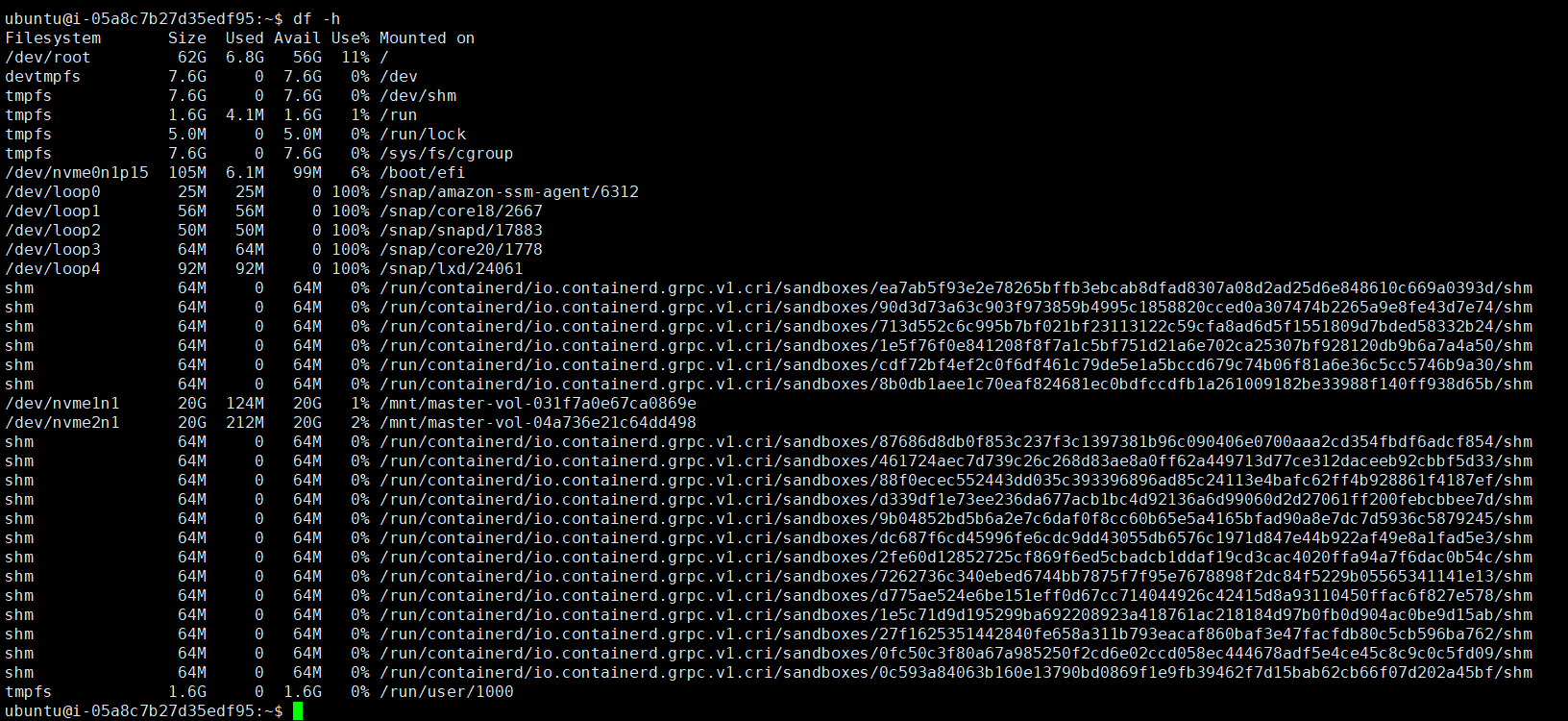
- 더미파일 생성 및 filesystem 확인
- 50GB 더미파일 생성으로 현재 90%이상 사용
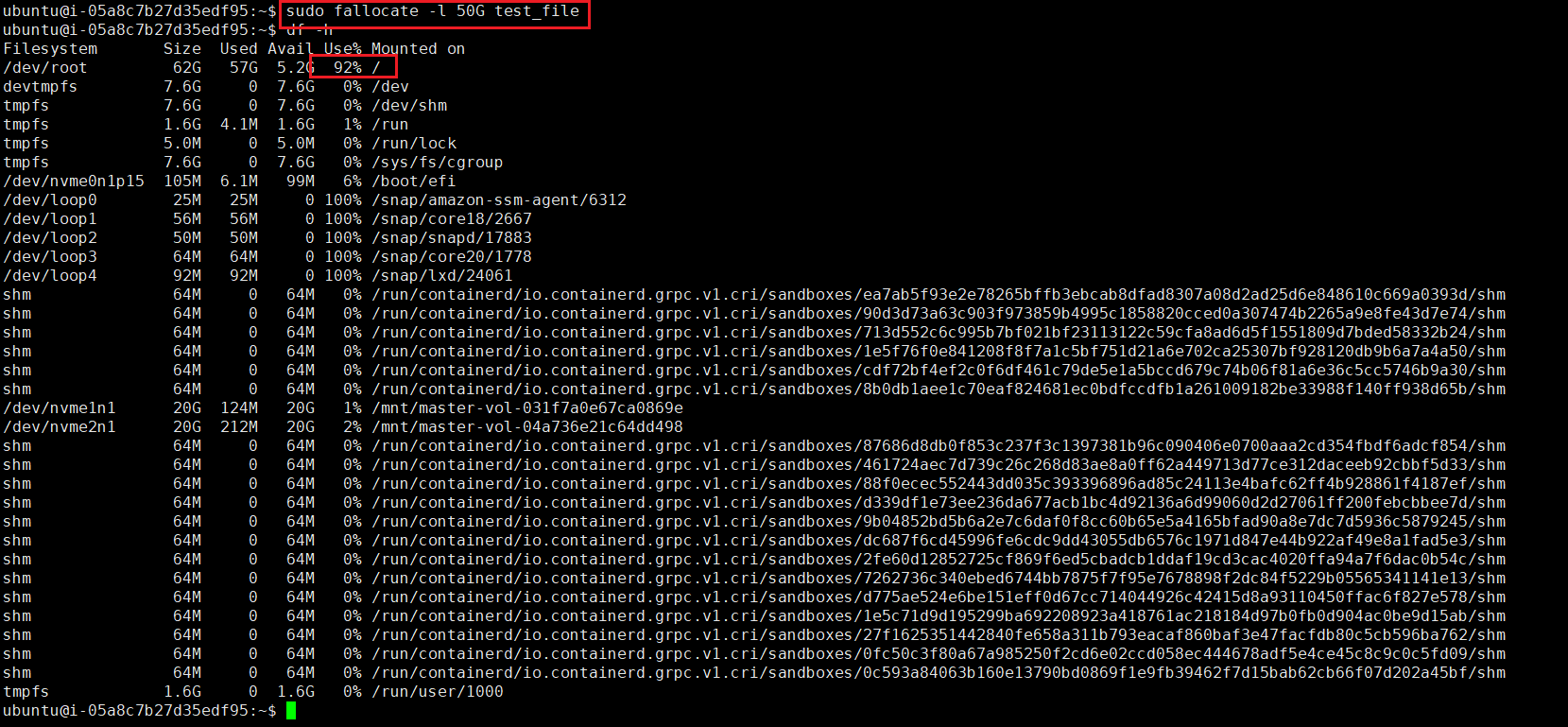
- Pending 발생
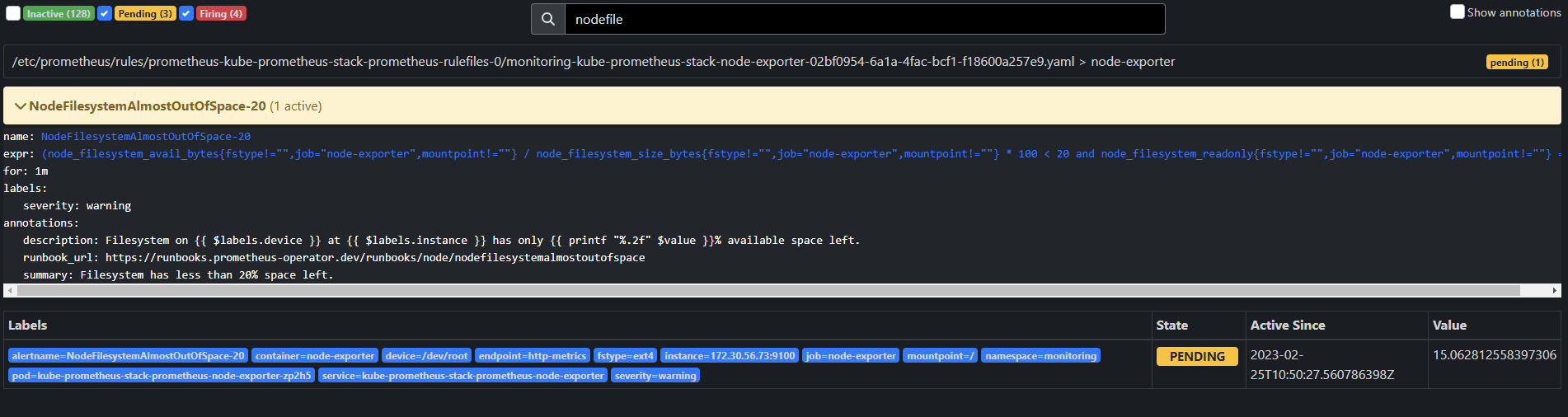
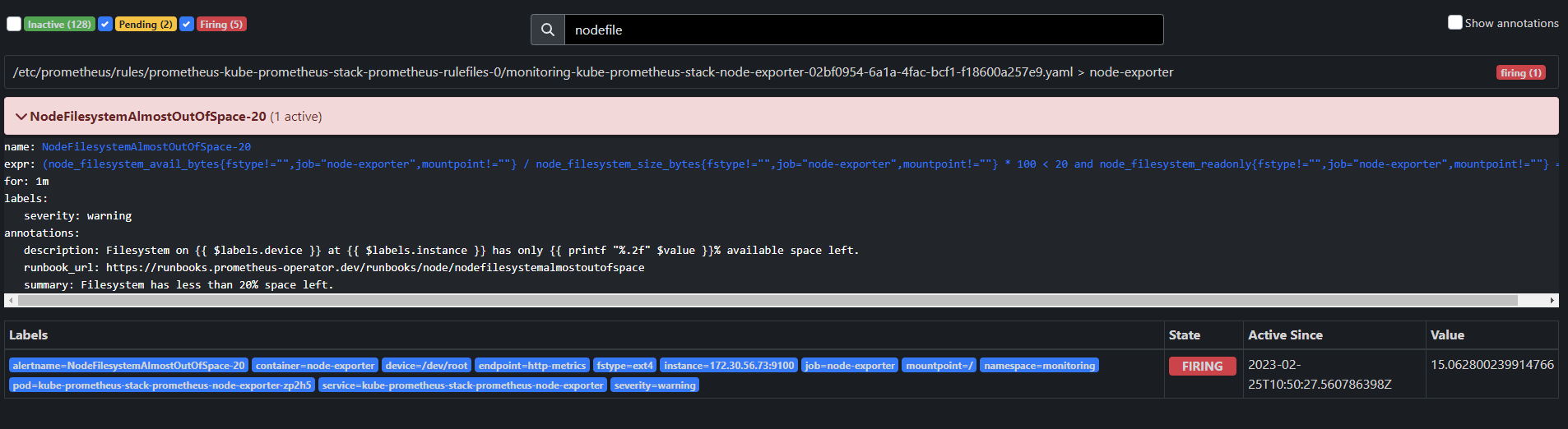
- Fireing
- karma 확인
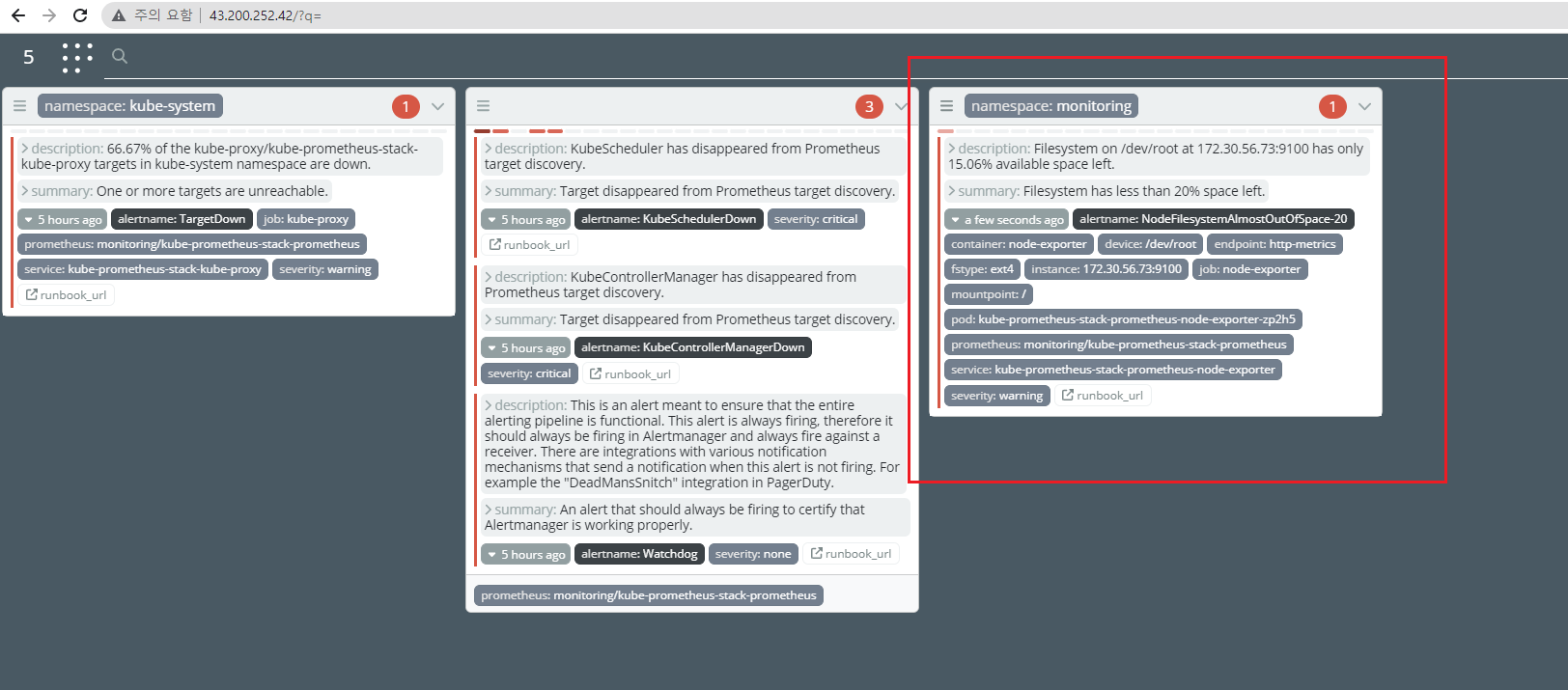
[과제2]책 386~389페이지 - LogQL 사용법 익히기 ⇒ 직접 실습 후 관련 스샷을 올려주세요.
LogQL
- LogQL은 기본적으로 레이블을 선택하는 부분과 로그 메시지를 필터링 하는 부분으로 나뉨
- 레이블의 경우 그라파나 로그 조회 화면에서 전체 레이블 목록을 확인 및 선택할 수 있음.
- 메시지 필터링은 리눅스의 grep과 유하게 파이프(|)를 입력하고 원하는 문자열을 포함한 로그파일 및 포함하지 않는 로그를 선택해서 조회
- |= : 문장 포함
- != : 문자 포함하지 않음
- |~ : 정규식 표현 포함
- !~ : 정규식 표현 포함하지 않음
[책에서 실습한 namespace 및 pods가 없어 설치한 nginx 로그를 통해 실습 진행]
-
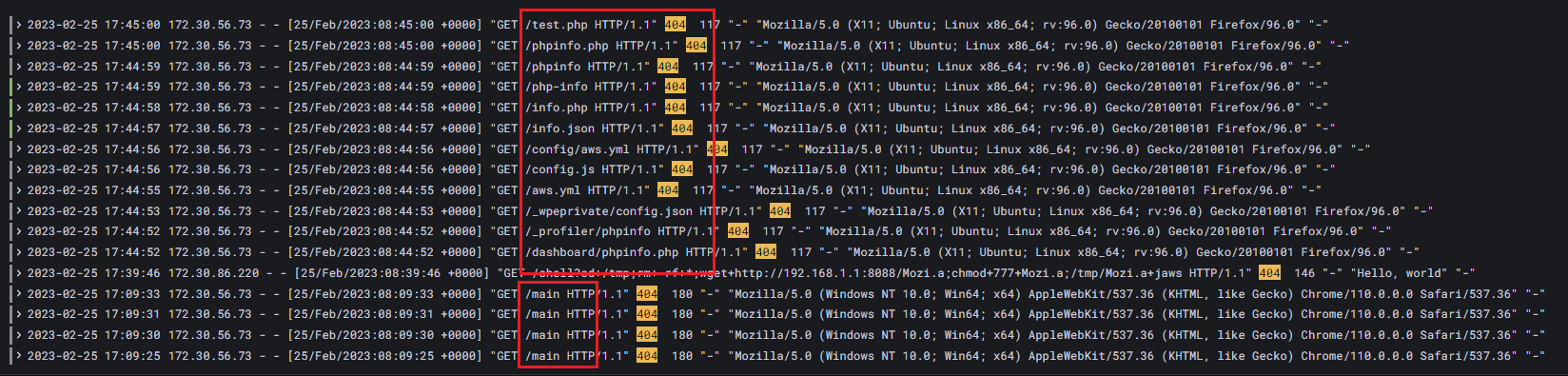
400에러 로그 발생 (존재하지 않는 경로를 url에 추가하여 접속)
-
nginx.burst89.com/main
-
nginx.burst89.com/main/img
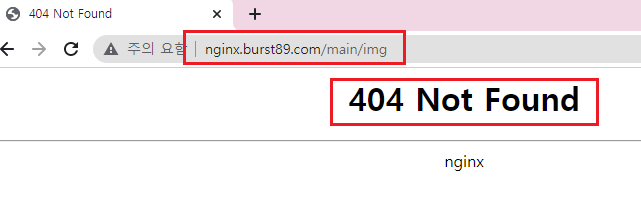
-
그라파나에서 해당 에러 확인

-
기존에 적용한 쿼리에서는 응답메시지 200, 404를 모두 포함하여 로그를 확인

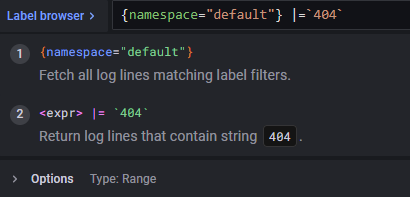
- 전체 로그 중 default 네임스페이스의 로그만 검색

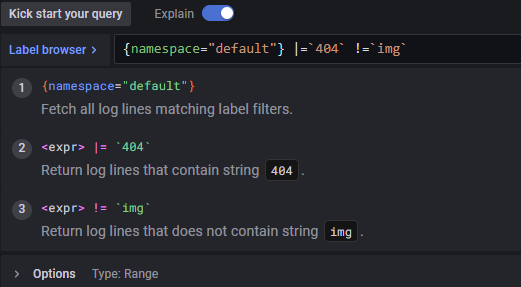
default 네임스페이스의 nginx를 제외한 별도의 pod가 없기 떄문에 기존가 동일하게 nginx 로그 전체가 조회 - 그중 대소문자를 구분하지 않고 '404'문자열을 포함한 로그 검색
- 레이블 선택 시 {}안에 내용 작성 / 해당 값들은 " "를 사용
- |=을 사용하여 404문자열을 포함한 로그만 조회
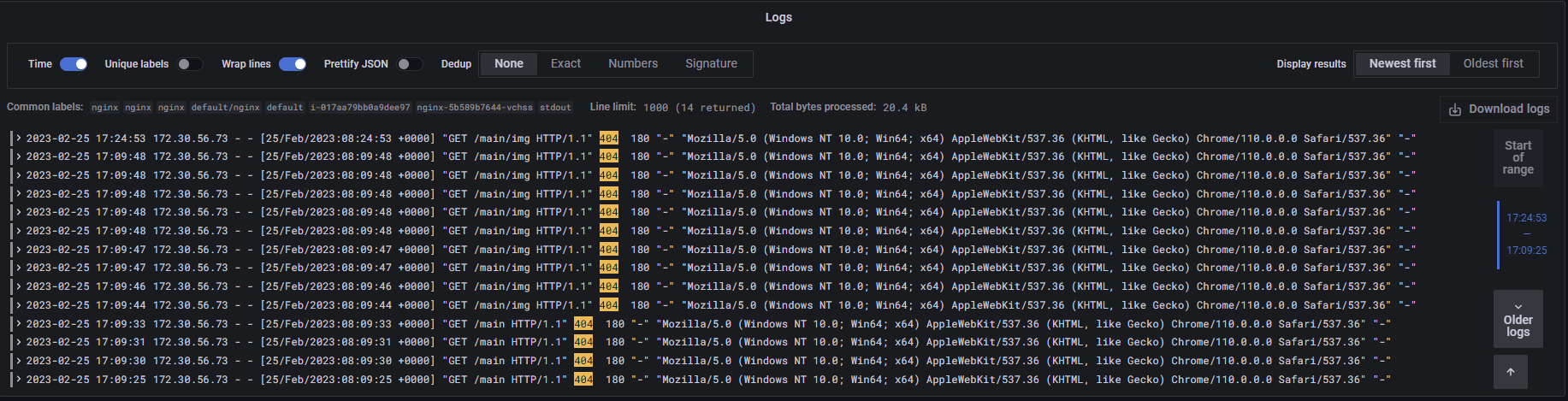
- 그중 'img'문자열이 포함된 로그를 제외하고 검색
- !=을 사용하여 img 문자열 제외
- 책에 설명된 표현식
- ?는 0번 또는 1번 이상 문자를 포함하는 경우 나타내는 정규 표현식
- i는 대소문자를 구분하지 않을때 사용하는 옵션
- (?!)을 같이 사용하면, 대소문자 구분하지 않고 0번 또는 1번 이상 나타나는 문자열 조회
- {namespace="metallb" |~ "(?!)err"}의 경우 metallb 네임스페이스에 있는 0번 또는 1번 이상의 대소문자를 구분하지 않고 err이 포함된 문자열이 포함된 로그 조회
[과제3]Awesome Prometheus alerts 를 참고해서 스터디에서 배우지 않은 Alert Rule 생성 및 적용 후 관련 스샷을 올려주세요
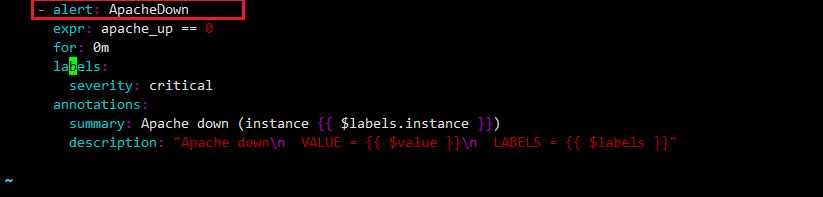
- apache 관련 Rule 추가
- kube-prometheus-stack-node-exporter.yaml 파일에 ApacheDown Rule 추가
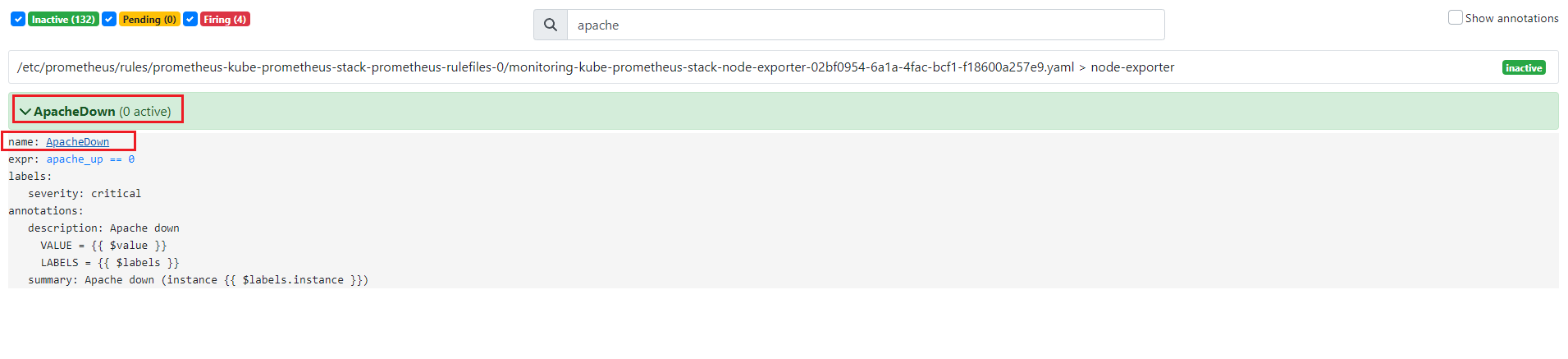
- Rule 적용 후 프로메테우스 Alert에서 확인
- 기존 실습에서 nginx 배포와 동일하게 apache 서비스 배포
- metric 활성화 및 서비스 모니터링 활성화
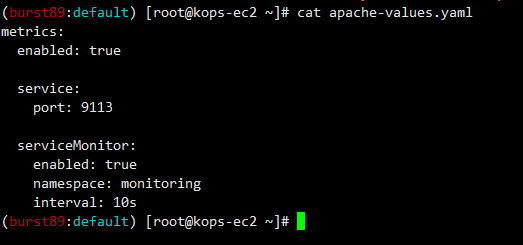
#헬름 repo 추가
helm repo add my-repo https://charts.bitnami.com/bitnami
# 파라미터 파일 생성 : 서비스 모니터 방식으로 apache 모니터링 대상을 등록하고, export 는 9113 포트 사용, apache 웹서버 노출은 AWS CLB 기본 사용
cat <<EOT > ~/nginx-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm install my-release my-repo/apache -f apache-values.yaml
# CLB에 ExternanDNS 로 도메인 연결
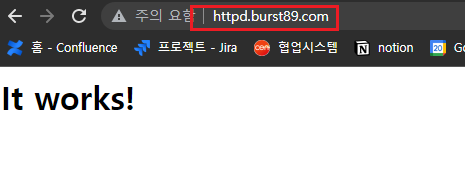
kubectl annotate service my-release-apache "external-dns.alpha.kubernetes.io/hostname=httpd.$KOPS_CLUSTER_NAME"
# 접속 주소 확인 및 접속
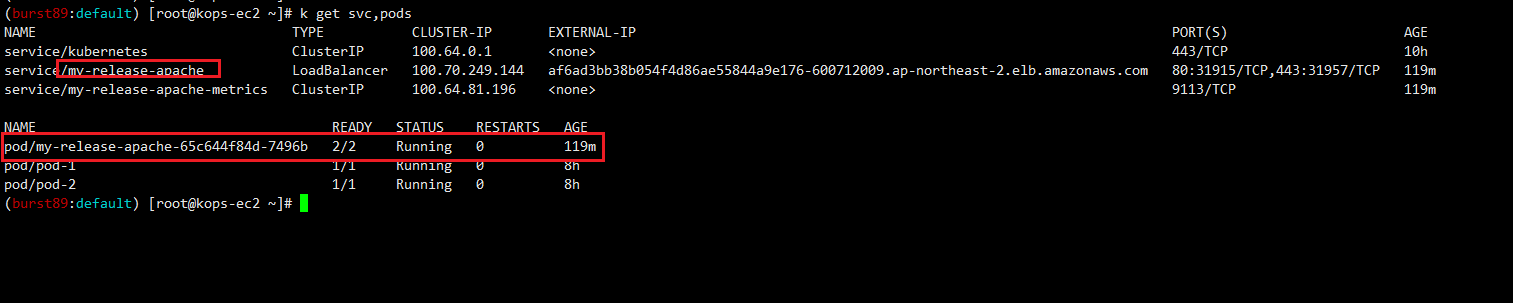
echo -e "HTTPD WebServer URL = http://httpd.$KOPS_CLUSTER_NAME"- apache 서비스 및 pod 확인
- 서비스 다운 후 알람 확인
- 프로세스 확인
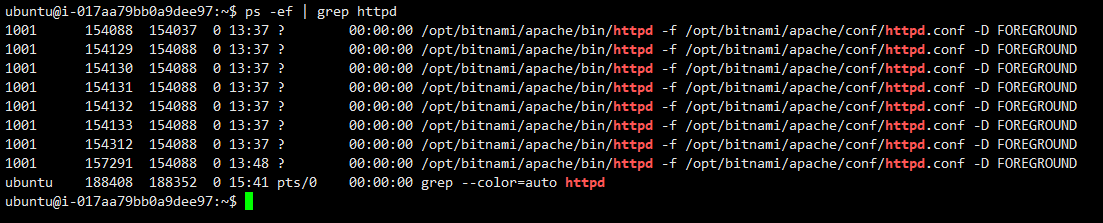
- 프로세스 다운
프로세스 다운 후 alert 발생 및 슬렉으로 weebhook 메시지를 보고 싶었지만.. 실패..
이런 application 관련 alert rule은 kube-prometheus-stack-node-exporter에 추가하는게 맞는건지, 아니면 다른 rule에 추가를 해야하는지 아님 별도의 rule로 생성되어야 하는지.. 어렵다............
