해당 블로그는 고려대학교 DSBA 연구실에서 공개한 유튜브를 토대로 만들었습니다. (https://youtu.be/x_8cp4Vdnak)
Background
Seq2Seq 모델
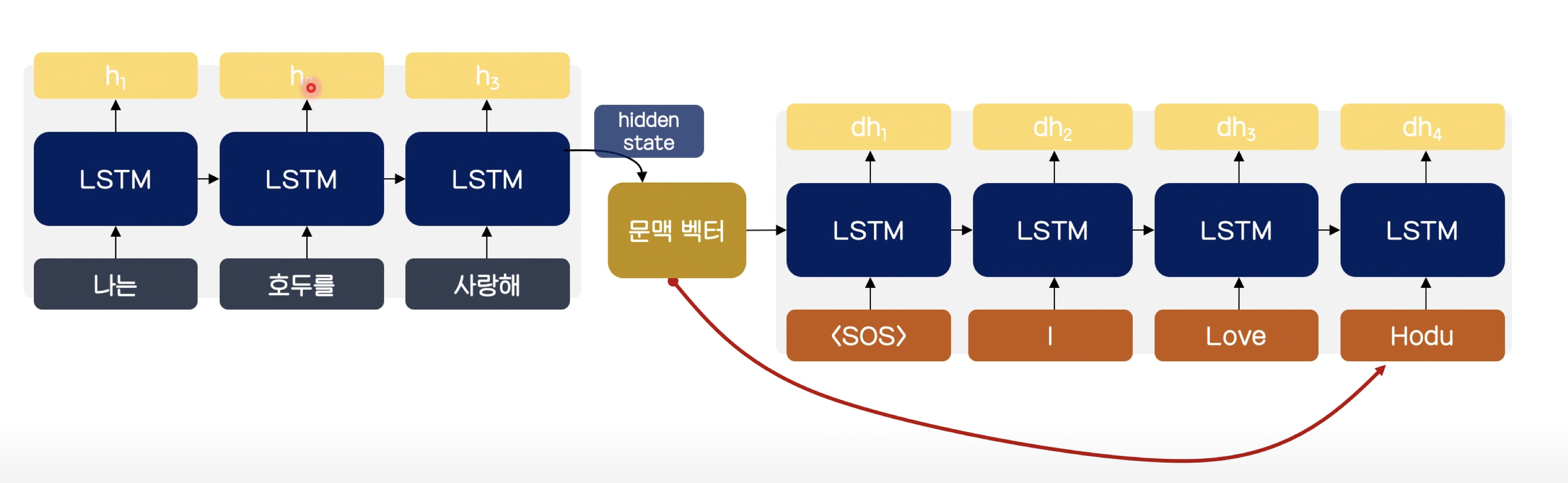
- Encoder와 Decoder를 각각 RNN으로 구성하는 방식입니다.
- 동작원리
- ‘나는’, ‘호두를’, ‘사랑해’ 라는 3개의 토큰들을 순차적으로 LSTM 셀에 넣으면 , hidden state를 하나씩 출력합니다.
- 이렇게 토큰들의 hidden state들이 출력되면, 마지막 hidden state는 정보를 압축한 vector가 되고, 이를 Context Vector 라고 칭합니다.
- Context Vector를 통해 이후 token들을 넣었을 때 다음 token 예측을 위한 hidden state가 출력됩니다.
- 문제점
- Sequence가 길어지는 경우에는 Gradient Vanishing 문제가 발생하여 Context Vector에 앞 순서 token들의 정보가 소실되는 문제가 발생했습니다.
- Context vector로는 encoder의 정보를 모두 담기 힘들었고, 그에 따라 decoder의 번역 품질이 저하되는 Bottleneck Effect가 발생했습니다.
Attention 예시 (Long-term Attention)
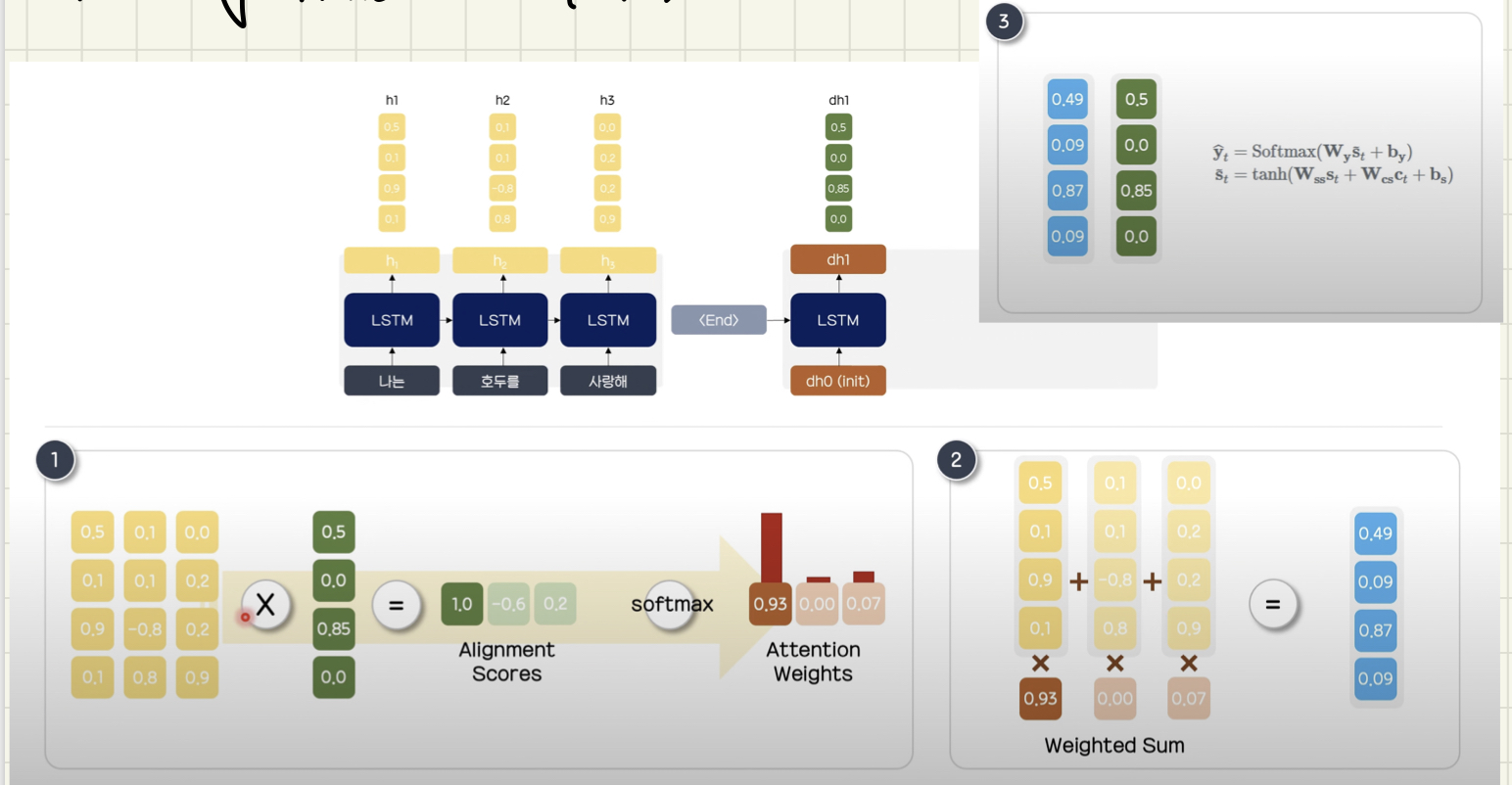
- hidden state들을 하나의 행렬로 보존한 후, decoder의 시작 토큰을 LSTM 셀에 넣은 hidden state 와 내적하여 Alignment Scores와 Alignment Weights를 구합니다.
- Attention Weights를 hidden state 행렬에 곱하여 가중합을 구합니다.
- 위의 과정들을 수행하여 구한 Attention Value들을 concat하고, tanh, softmax 함수를 이용해 예측 확률을 구하여 다음 token을 예측합니다.
Training Architecture
Token들이 encoder에 sequential하게 들어가서 순서가 보존되는 Seq2Seq 모델과는 다르게, Transformer는 한번에 모든 토큰을 encoder에 넣는 방식으로 설계되어 순서와 관련된 정보가 보존되지 않습니다.
이러한 문제점을 Position Encoding으로 해결했습니다.
Positional Encoding
positional encoding은 다음과 같은 특징을 가집니다:
- 각 토큰의 위치마다 유일한 값을 지녀야 합니다.
- 토큰 간 차이가 일정한 의미를 지녀야 합니다.
- 더 긴 길이의 문장이 입력되어도 일반화가 가능해야 합니다.
Encoder의 구조
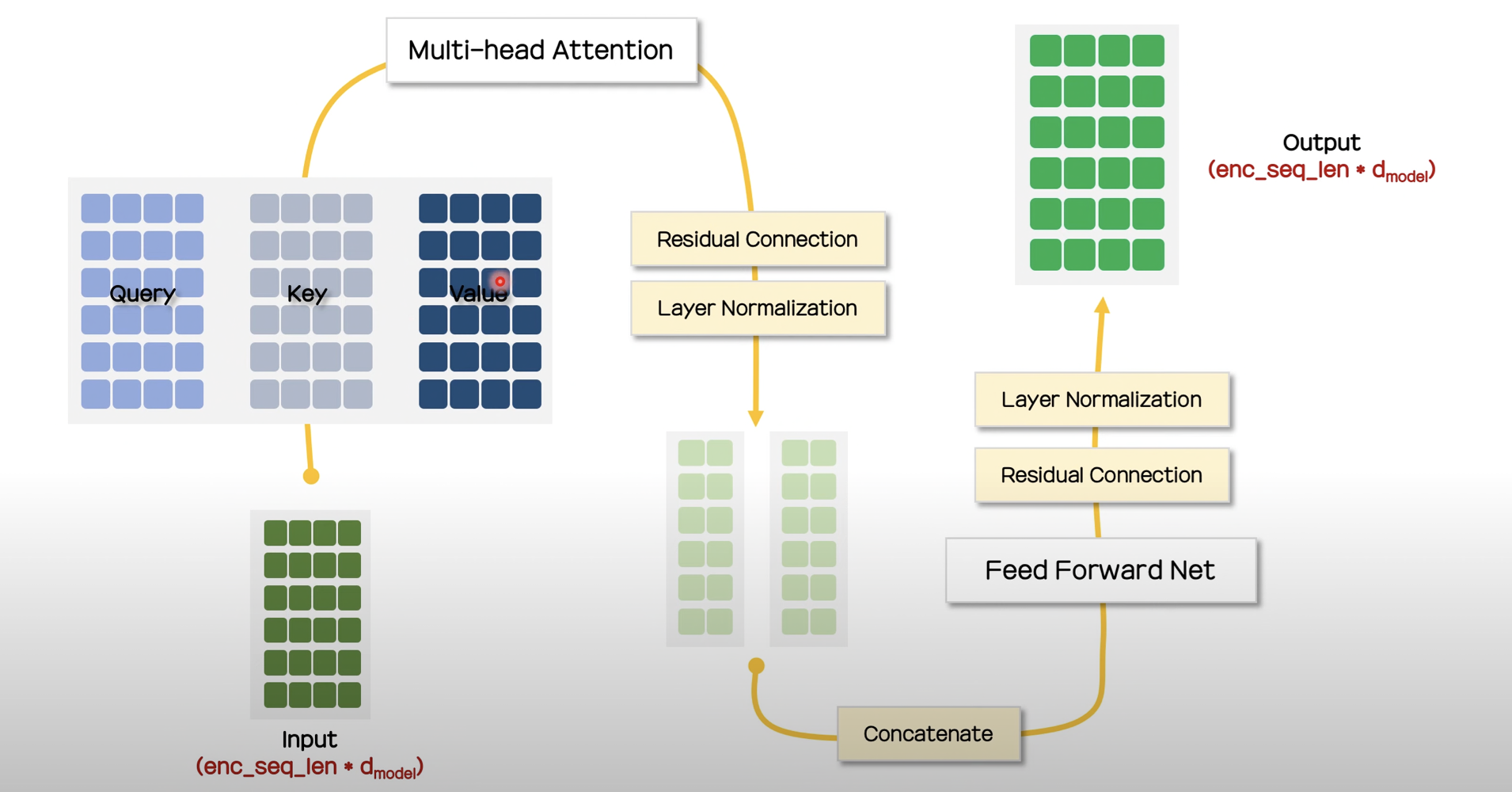
-
Input을 3개 복사하여, Qurey, Key, Value 각각의 가중치를 곱해 Q, K, V 행렬을 생성합니다.
-
Q와 K의 행렬곱을 수행하여 스케일링하고, masking과 softmax 함수를 거쳐 나온 결과물을 V와의 행렬곱을 계산합니다. 이때, 다양한 task 수행을 위해 multi-head attention기법을 사용합니다.
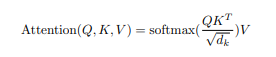
Q, K, V의 계산 방식
-
이후 만들어진 2개의 행렬을 concat하고, residual connection, layer normalization을 수행하여 feed-forward network에 넘깁니다.
-
다시 residual connection, layer normalization을 수행하여 output을 얻습니다.
이때, output과 input의 크기는 동일합니다 !!!
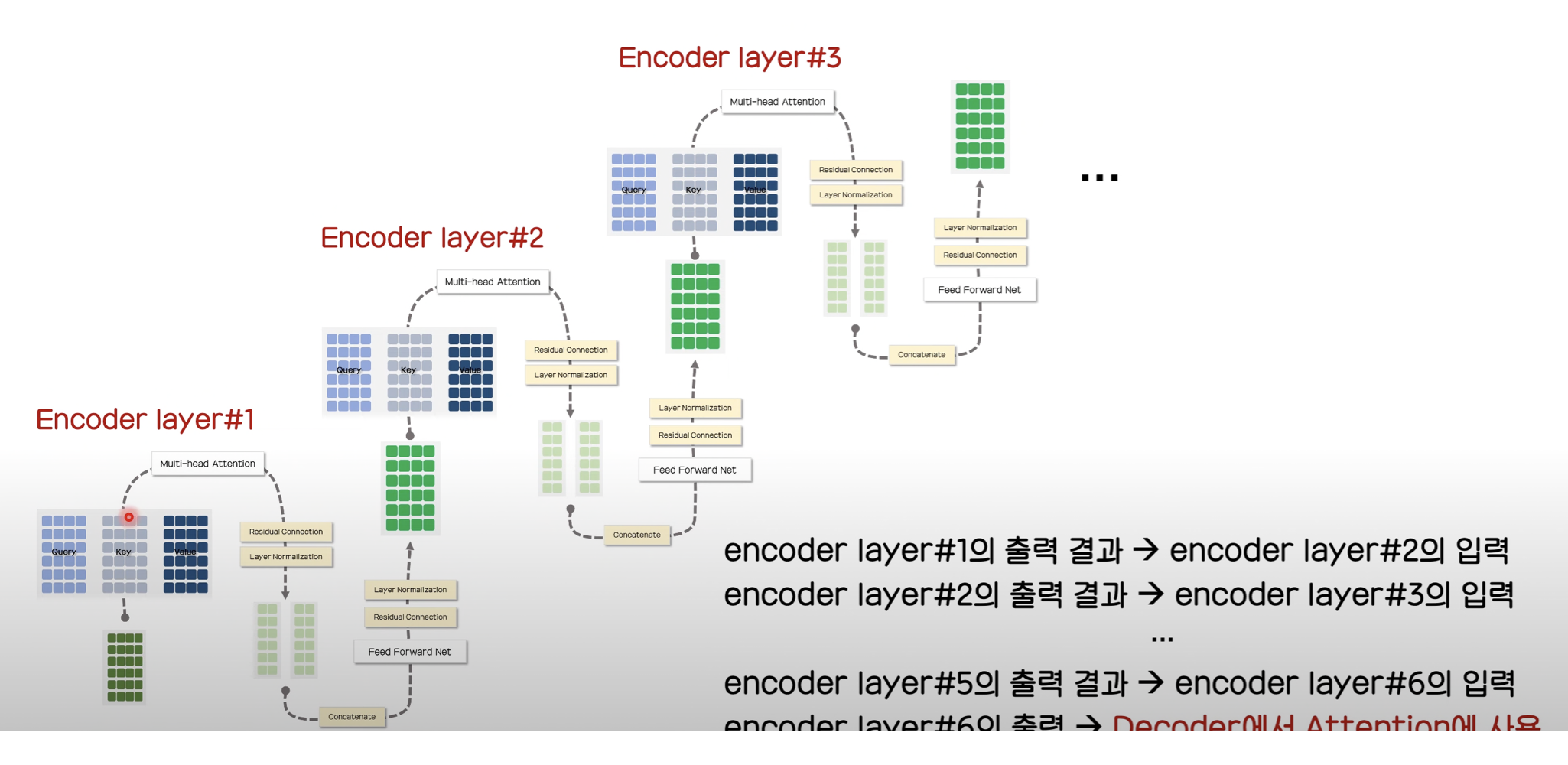
논문에서는 6개의 encoder layer를 사용합니다. output과 input의 크기가 동일하므로, 같은 구조의 encoder layer를 6번 사용할 수 있습니다.
Decoder의 구조
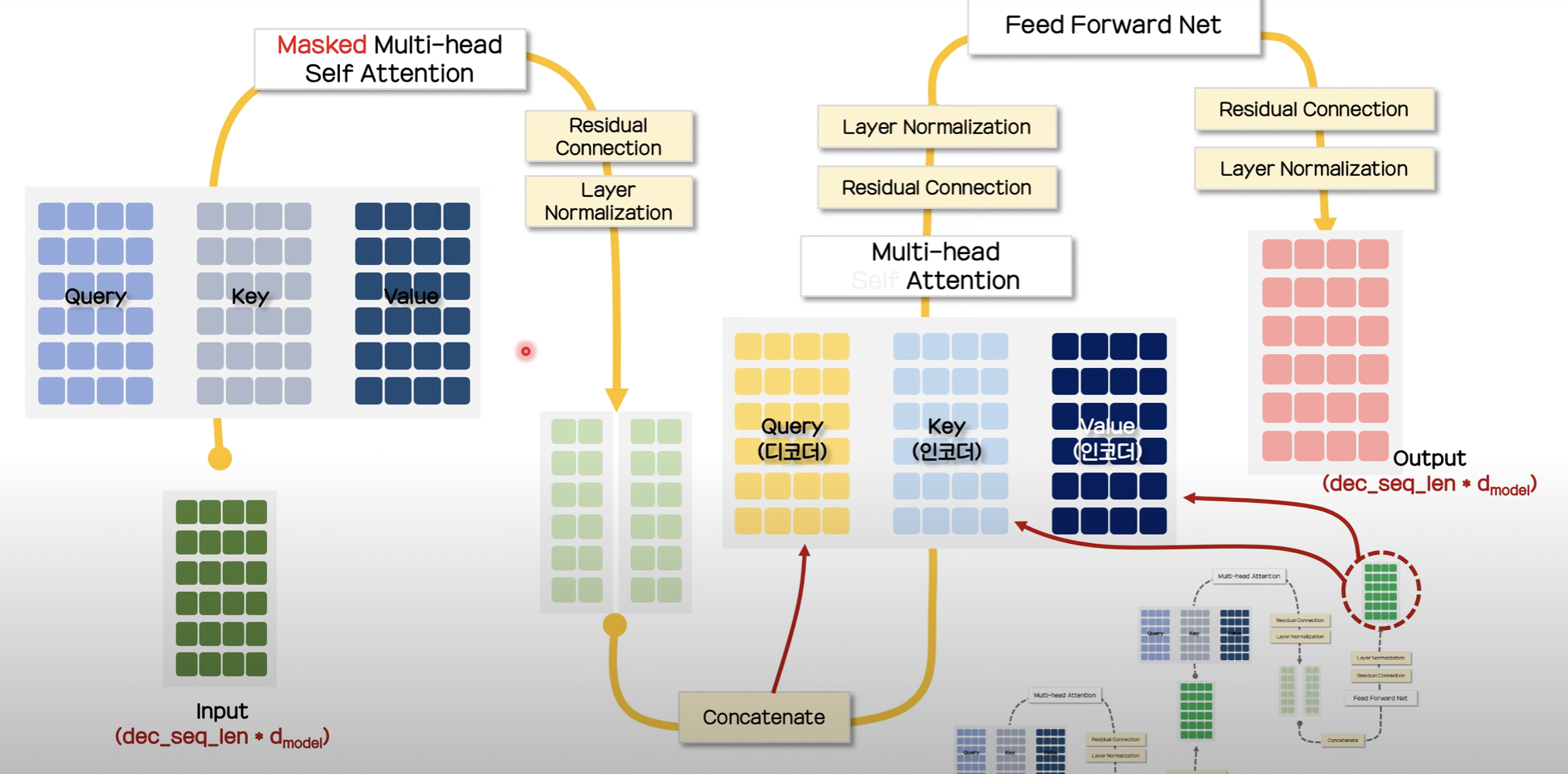
-
타겟 문장 학습 시 input token들을 one-hot-encoding으로 변환하여 embedding layer에 넣고, positional encoding을 수행합니다.
-
앞선 encoder의 1~3번 과정 (self-attention 과정)을 반복하여 산출된 결과를 Query로, Encoder의 ouput을 2개 복사하여 Key와 Value 값으로 사용합니다.
Self-attention 수행 시 encoder와 decoder의 다른 masking 기법
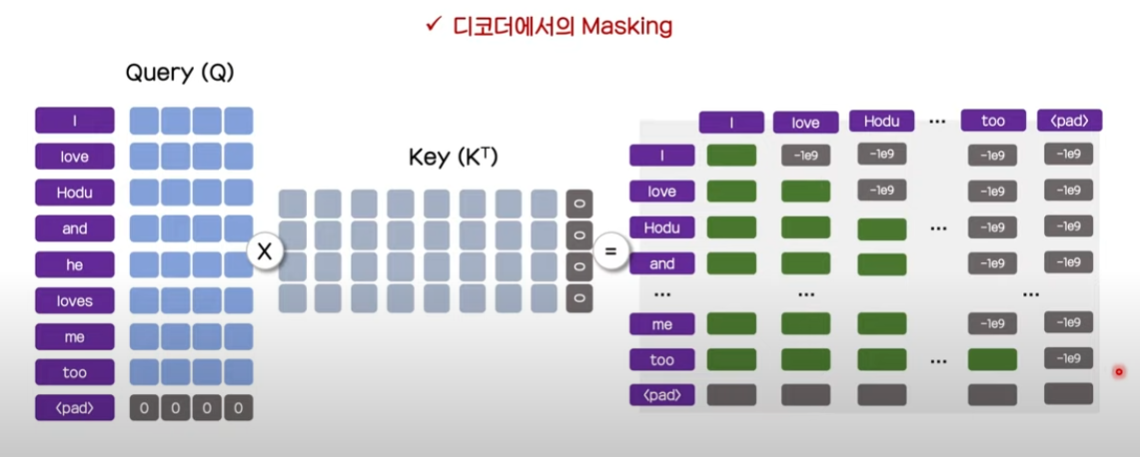
padding masking 기법만을 사용하는 encoder와는 다르게, decoder에서는 padding masking과 삼각행렬 윗부분까지 masking하는 기법을 사용합니다.
decoder에서 해당 masking 기법을 사용하는 이유는 attention의 가중치를 구할 때, 대상 token 이후의 token은 참조하지 못하도록 하기 위해서입니다.
만약 그림과 같이 삼각행렬의 윗부분을 masking하지 않는다면, 첫번째 행에서 I는 love, Hodu~too의 모든 정보들을 미리 받아오는 문제가 발생합니다.
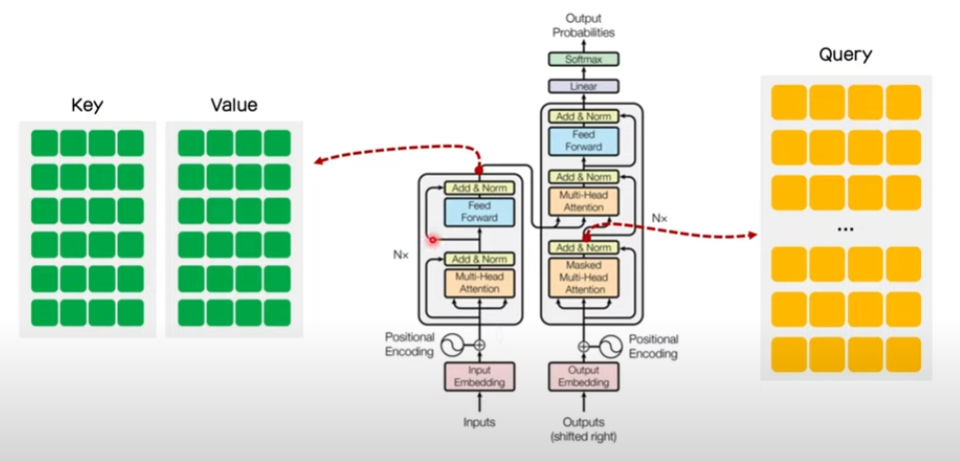
-
아래 수식을 활용하여 multi-head attention을 수행합니다. (encoder-decoder self attention이라고도 부릅니다.)
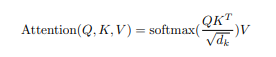
Q, K, V의 계산 방식
-
생성된 두 행렬은 concat하고, residual connection, layer normalization을 수행하여 feed forward network에 넘깁니다.
-
이후 다시 residual connection, layer normalization을 수행하여 output을 생성합니다.
이때도, output과 input의 크기는 동일합니다.
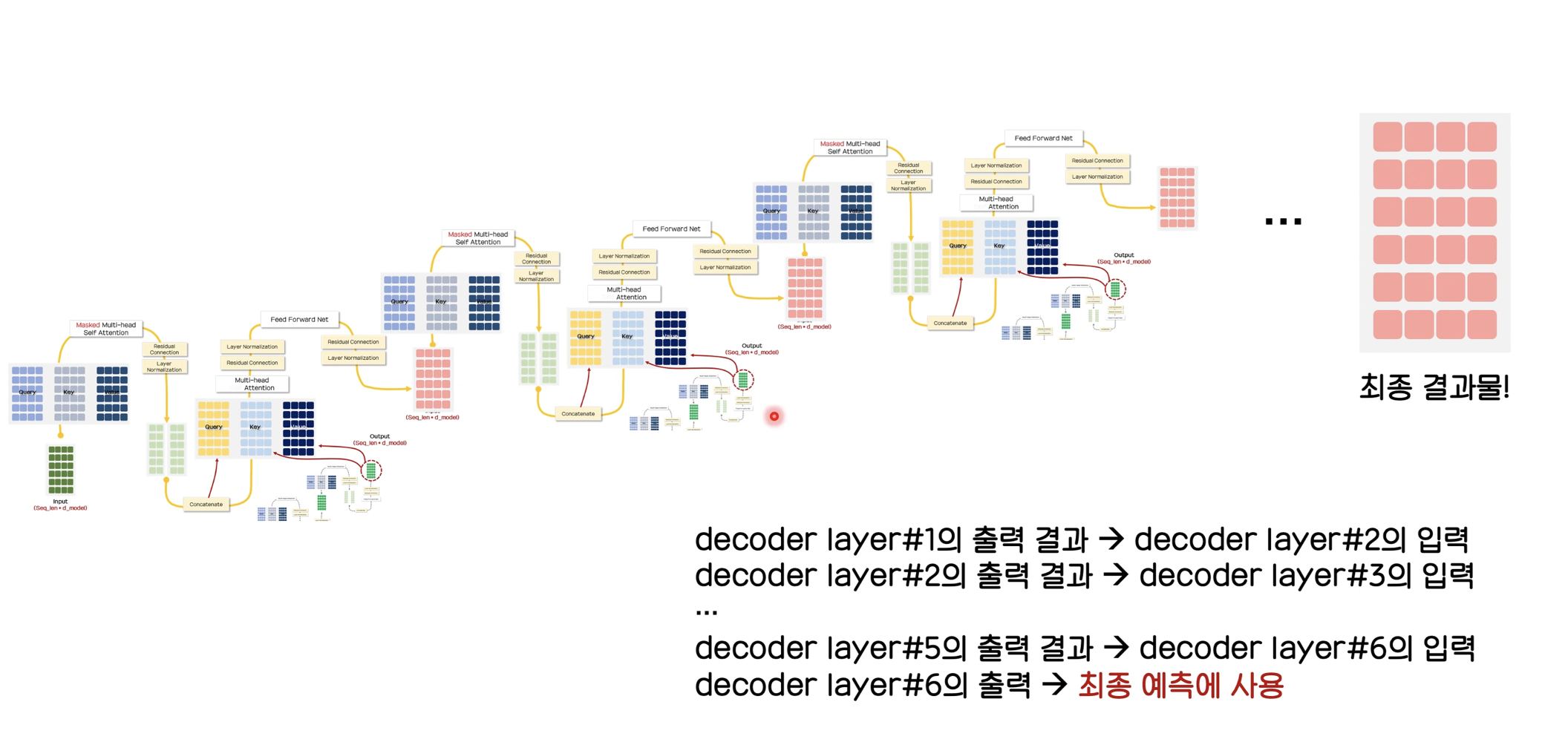
논문에서는 6개의 decoder layer를 사용하여 최종 결과물을 생성하여 예측에 사용합니다.
이렇게, Transformer의 전체적인 구조에 관해 리뷰해보았습니다.
