이번 look-alike 프로젝트를 위해 얼굴 인식 분야에서 높은 성능을 보이는 Arcface 모델을 사용하기로 결정했다.
Arcface 모델은 얼굴 임베딩(얼굴 특징 벡터)을 생성하는 데에 사용된다. 이 모델은 인간 얼굴 인식의 특성을 모방하여, 다양한 각도와 조명 조건에서 얼굴 특징 벡터의 유사성을 최대화하는 방식으로 학습된다.
ArcFace 모델은 기본적으로 softmax 분류기를 사용하며, 라벨에 해당하는 클래스의 점수를 최대화한다. 그러나 일반적인 softmax 분류기와는 달리, ArcFace 모델은 추가적인 margin 값을 이용하여 클래스 간의 거리를 보다 잘 유지하면서, 클래스 내부의 유사도를 더욱 강화한다.
해당 모델을 코드로 구현하고 학습까지 시켜보았다. 다음은 그와 관련된 코드이다.
1. 전처리 과정
1-1. 초기 세팅
import torch
print(torch.__version__)
#라이브러리 세팅
import random
import pandas as pd
import numpy as np
import os
import cv2
from PIL import Image
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import albumentations as A #증강
from albumentations.pytorch.transforms import ToTensorV2
import torchvision.models as models
from tqdm.auto import tqdm
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings(action='ignore')
from sklearn.model_selection import train_test_split
# GPU 확인
print(torch.cuda.is_available())
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# EfficientNet 오류 안나게..
torch.backends.cudnn.enabled = False
CFG = {
'IMG_SIZE':456,
'EPOCHS':20,
'LEARNING_RATE':0.000003,
'BATCH_SIZE':16,
'SEED':42
}
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
seed_everything(CFG['SEED'])
from google.colab import drive
drive.mount('/content/drive')
df = pd.read_csv('/content/drive/MyDrive/look-alike/glory_train_df.csv')
image_root_dir = '/content/drive/MyDrive/glory_match/look-alike/pre-processed-image'1-2. 준비한 test dataset을 train과 valid로 분리.
class_name_list = []
tmp=df.copy()
tmp['class'].shape
for initial in tmp['class']:
if initial not in class_name_list:
class_name_list.append(initial)
class_name_to_lower_case_list = [class_name.lower() for class_name in class_name_list]
for initial in class_name_to_lower_case_list:
image_root_path = os.path.join(image_root_dir, initial)
for i in range(len(tmp)):
if (initial.upper() == tmp['class'][i]):
tmp['file_name'][i] = os.path.join(image_root_path, tmp['file_name'][i])
tmp['file_name'].head()
train = pd.DataFrame(columns=tmp.columns)
valid = pd.DataFrame(columns=tmp.columns)
for class_name in class_name_list:
tmp_with_class = tmp.loc[tmp['class'] == class_name]
train_tmp, valid_tmp = train_test_split(tmp_with_class, test_size = 0.3, random_state = 42)
train_tmp['class'] = class_name
valid_tmp['class'] = class_name
train = pd.concat([train, train_tmp])
valid = pd.concat([valid, valid_tmp])
# label을 tensor로 반환하기 위해 one-hot-encoding 적용
one_hot_encoded = pd.get_dummies(tmp['class'])
train_one_hot_encoded = pd.get_dummies(train['class'])
valid_one_hot_encoded = pd.get_dummies(valid['class'])
data = pd.concat([tmp, one_hot_encoded], axis=1)
data = data.drop(['class'], axis=1)
train = pd.concat([train, train_one_hot_encoded], axis=1)
train = train.drop(['class'], axis=1)
valid = pd.concat([valid, valid_one_hot_encoded], axis=1)
valid = valid.drop(['class'], axis=1)1-3. CustomDataset
train_transform = A.Compose([
A.Resize(224, 224),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.5),
A.RandomBrightnessContrast(brightness_limit=(-0.3, 0.3), contrast_limit=(-0.3, 0.3), p=1),
A.ChannelShuffle(p=0.2),
ToTensorV2()
])
valid_transform = A.Compose([
A.Resize(224, 224),
ToTensorV2()
])class CustomDataset(Dataset):
def __init__(self, file_list, label_list, transform=None):
self.file_list = file_list
self.label_list = label_list
self.transform = transform
def __len__(self):
return len(self.file_list)
def __getitem__(self, index):
image = cv2.imread(self.file_list[index])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # BGR -> RGB
image = image.astype(np.float32) / 255.0
if self.transform:
transformed = self.transform(image=image)
image = transformed["image"]
label = self.label_list[index]
return image, labelfrom torch.utils.data import DataLoader
# 파일 이름 및 레이블 목록 추출
train_files = train["file_name"].tolist()
train_labels = train.drop(["file_name", "index"], axis=1).values
valid_files = valid["file_name"].tolist()
valid_labels = valid.drop(["file_name", "index"], axis=1).values
# CustomDataset 정의
train_dataset = CustomDataset(train_files, train_labels, transform=train_transform)
valid_dataset = CustomDataset(valid_files, valid_labels, transform=valid_transform)
# DataLoader 정의
batch_size = 16
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=True)2. Model 정의
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
import math
class ArcMarginProduct(nn.Module):
def __init__(self, in_features, out_features, scale=30.0, margin=0.50, easy_margin=False, device='cuda'):
super(ArcMarginProduct, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.scale = scale
self.margin = margin
self.device = device
self.weight = nn.Parameter(torch.FloatTensor(out_features, in_features))
nn.init.xavier_uniform_(self.weight)
self.easy_margin = easy_margin
self.cos_m = math.cos(margin)
self.sin_m = math.sin(margin)
self.th = math.cos(math.pi - margin)
self.mm = math.sin(math.pi - margin) * margin
def forward(self, input, label):
cosine = F.linear(F.normalize(input), F.normalize(self.weight))
sine = torch.sqrt(1.0 - torch.pow(cosine, 2))
phi = cosine * self.cos_m - sine * self.sin_m
if self.easy_margin:
phi = torch.where(cosine > 0, phi, cosine)
else:
phi = torch.where(cosine > self.th, phi, cosine - self.mm)
one_hot = torch.zeros(cosine.size(), device=input.device)
one_hot.scatter_(1, label.view(-1, 1).long(), 1)
output = (one_hot * phi) + ((1.0 - one_hot) * cosine)
output *= self.scale
return output
class CustomArcFaceModel(nn.Module):
def __init__(self, num_classes, device='cuda'):
super(CustomArcFaceModel, self).__init__()
self.device = device
self.backbone = nn.Sequential(*list(models.resnet50(pretrained=True).children())[:-1])
self.arc_margin_product = ArcMarginProduct(2048, num_classes, device=self.device)
nn.init.kaiming_normal_(self.arc_margin_product.weight)
def forward(self, x, labels=None):
features = self.backbone(x)
features = F.normalize(features)
features = features.view(features.size(0), -1)
if labels is not None:
logits = self.arc_margin_product(features, labels)
return logits
return featuresfrom tqdm import tqdm
def train(model, optimizer, criterion, train_loader, valid_loader, device, epochs):
model.to(device)
best_accuracy = 0.0
for epoch in range(epochs):
model.train()
train_loss = 0.0
train_corrects = 0
for x, y in tqdm(train_loader, desc=f"Epoch {epoch + 1} - Training"):
x = x.to(device)
# y = y.to(device)
y = torch.argmax(y, dim=1).to(device)
optimizer.zero_grad()
output = model(x, y)
loss = criterion(output, y)
loss.backward()
optimizer.step()
_, preds = torch.max(output, 1)
train_loss += loss.item() * x.size(0)
train_corrects += torch.sum(torch.eq(torch.round(preds), y.data)).float()
train_loss = train_loss / len(train_loader.dataset)
train_accuracy = train_corrects.double() / len(train_loader.dataset)
model.eval()
valid_loss = 0.0
valid_corrects = 0
with torch.no_grad():
for x, y in tqdm(valid_loader, desc=f"Epoch {epoch + 1} - Validation"):
x = x.to(device)
# y = y.to(device)
y = torch.argmax(y, dim=1).to(device)
output = model(x, y)
loss = criterion(output, y)
_, preds = torch.max(output, 1)
valid_loss += loss.item() * x.size(0)
valid_corrects += torch.sum(torch.eq(torch.round(preds), y.data)).float()
valid_loss = valid_loss / len(valid_loader.dataset)
valid_accuracy = valid_corrects.double() / len(valid_loader.dataset)
print(f"Epoch {epoch + 1}/{epochs} - Train Loss: {train_loss:.4f}, Train Acc: {train_accuracy:.4f}, Valid Loss: {valid_loss:.4f}, Valid Acc: {valid_accuracy:.4f}")
if valid_accuracy > best_accuracy:
best_accuracy = valid_accuracy
torch.save(model.state_dict(), "arcface.pth")
return model3. 모델 학습
# 하이퍼파라미터 설정
num_classes = 11 # 분류할 클래스의 수 (CDE, CHJ, HAR, IDH, IJH, JJJ, JSI, OJY, SHE, SHG, SMO)
embedding_size = 2048
learning_rate = CFG['LEARNING_RATE']
epochs = 150
# 모델 생성
model = CustomArcFaceModel(num_classes, embedding_size)
# 옵티마이저 및 손실 함수 설정
optimizer = torch.optim.Adam(model.parameters(), lr = learning_rate)
criterion = nn.CrossEntropyLoss()
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.5, patience=2,threshold_mode='abs',min_lr=1e-8, verbose=True)
# 모델 학습
trained_model = train(model, optimizer, criterion, train_loader, valid_loader, device, epochs)4. 학습결과
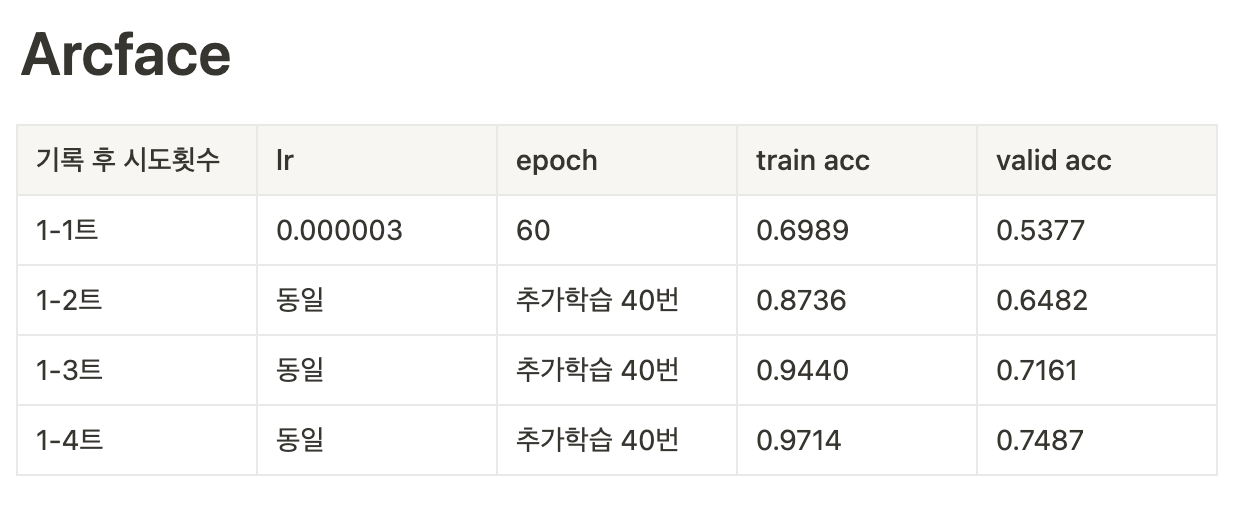
train accuracy에 비해 valid accuracy가 낮게 나왔다.
하이퍼파라미터를 좀 더 조정해보아야 (많이 조정해봤지만 ㅠㅠ) 할 것 같다.

배움의 개발자