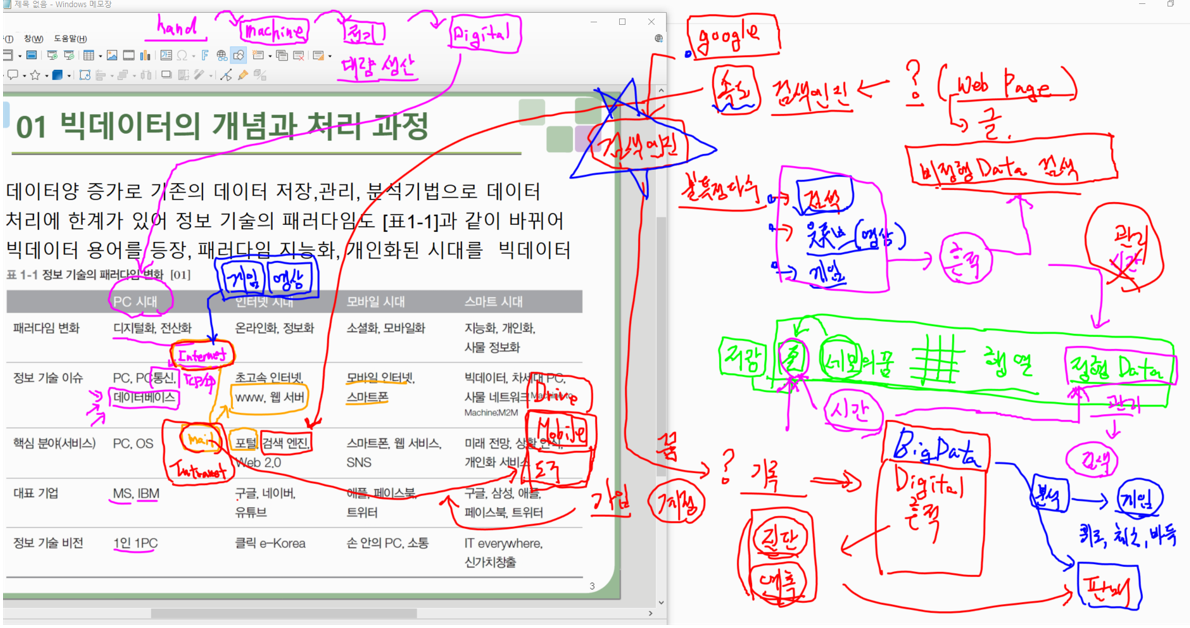
검색엔진
Hadoop 탄생, 기술
- PC -> Internet -> 검색[Indexing] -> Web -> [검색엔진] -> Mobile -> Cloud
- 하둡은 비정형 검색에서 시작했다.
더그 커팅
-
Lucene : 오픈소스 검색(Indexing) 라이브러리
- 검색엔진의 주 데이터 : 원하는 데이터
- 정형 데이터가 없음 -> 비정형 데이터를 가져오기 위한 인덱스를 만드는게 주 목적 = Lucene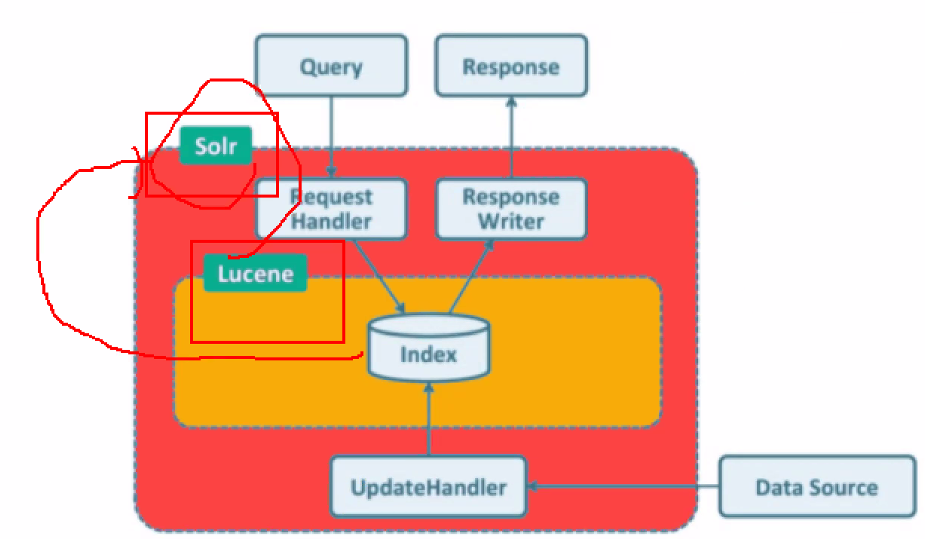
-
Apache Solr
- 오픈소스 검색(Indexing) 프로젝트
- Request/Response + Lucene -
Apache Nutch :
- Web 검색(Indexing) 엔진 프로젝트
- 웹 사이트 크롤링(Crawling)<== GFS 기술문서에서 분산 (Distributed File System) 개념
<== GFS 기술문서에서 분산처리 (MapReduce) 개념
-
NDFS(Nutch Distributed File System)을 시작
-
Apache Hadoop 시작
- 오픈소스형 Web 검색(Indexing) 엔진 & 분산 파일 시스템
- YaHoo 에서 전격 지원
Apache Hadoop :
오픈소스 검색 엔진 , 웹에서의 분산 파일 시스템
- 특징
- 분산 저장
- 처리 (MapReduce)
- 구성요소
- Named Node
- Data Node
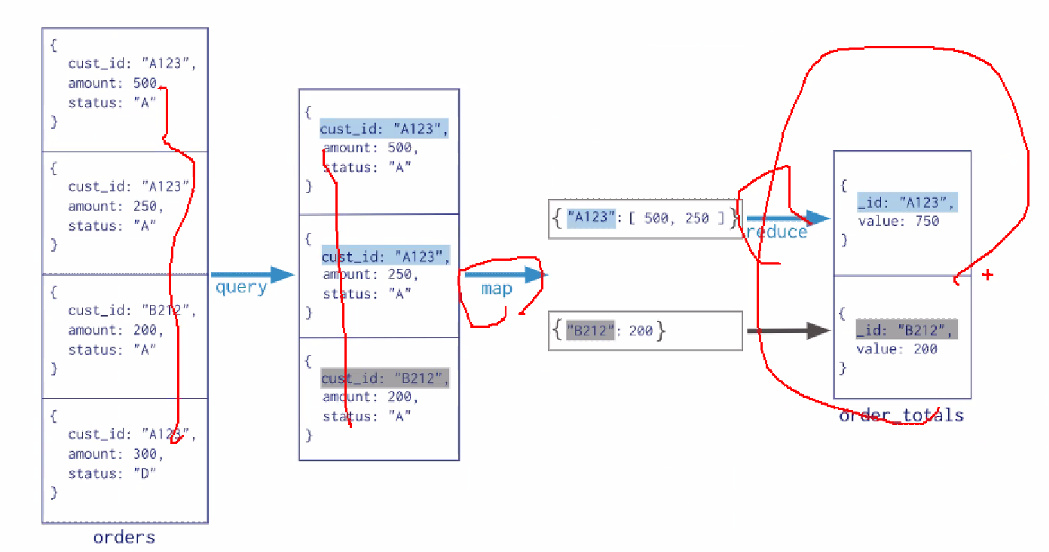
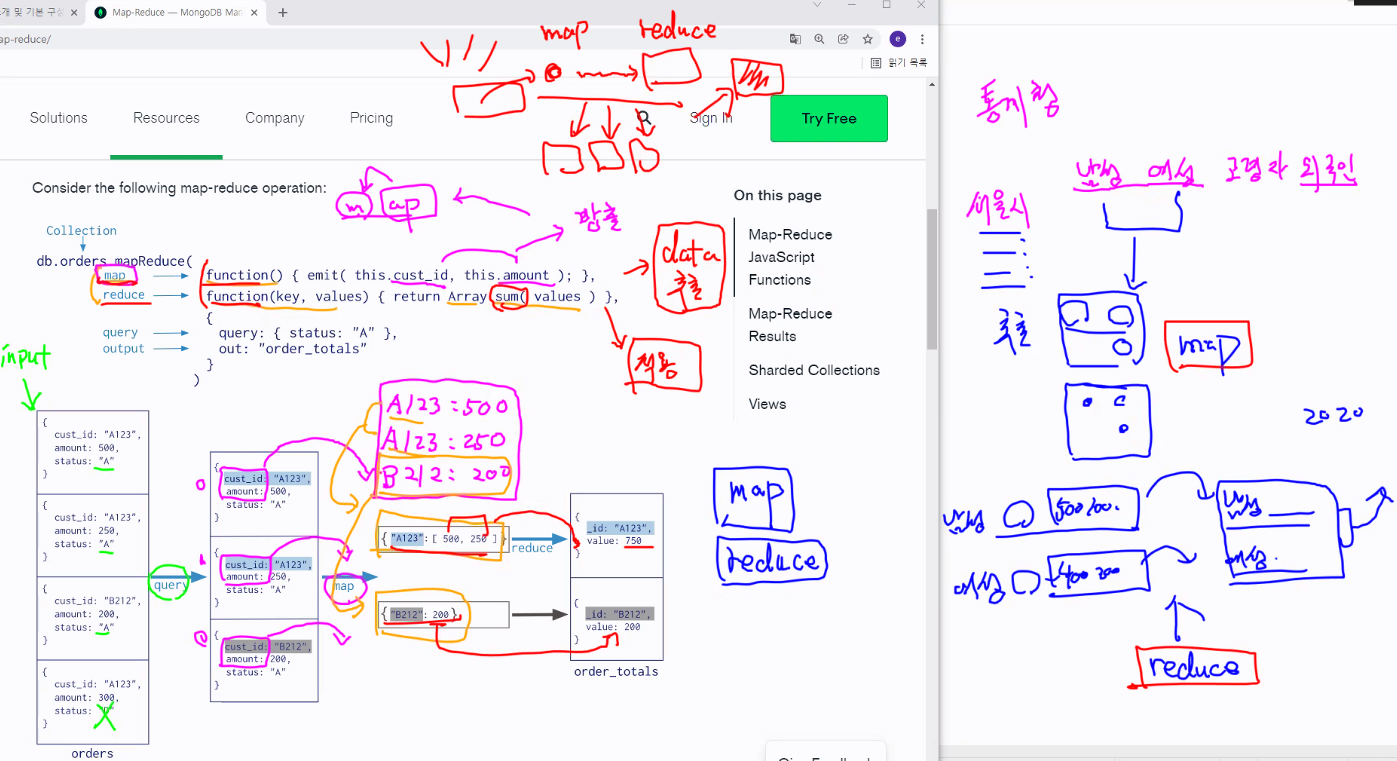
- Clustering - Map : 흩어져있는 데이터를 Key, Value 형태로 연관성 있는 데이터들로 분류 (Like. 번호별 분류 )
- Reduce : Map화 한 작업 중 중복 데이터를 제거 하고 원하는 데이터를 추출 하는 작업
 이미지 출처
이미지 출처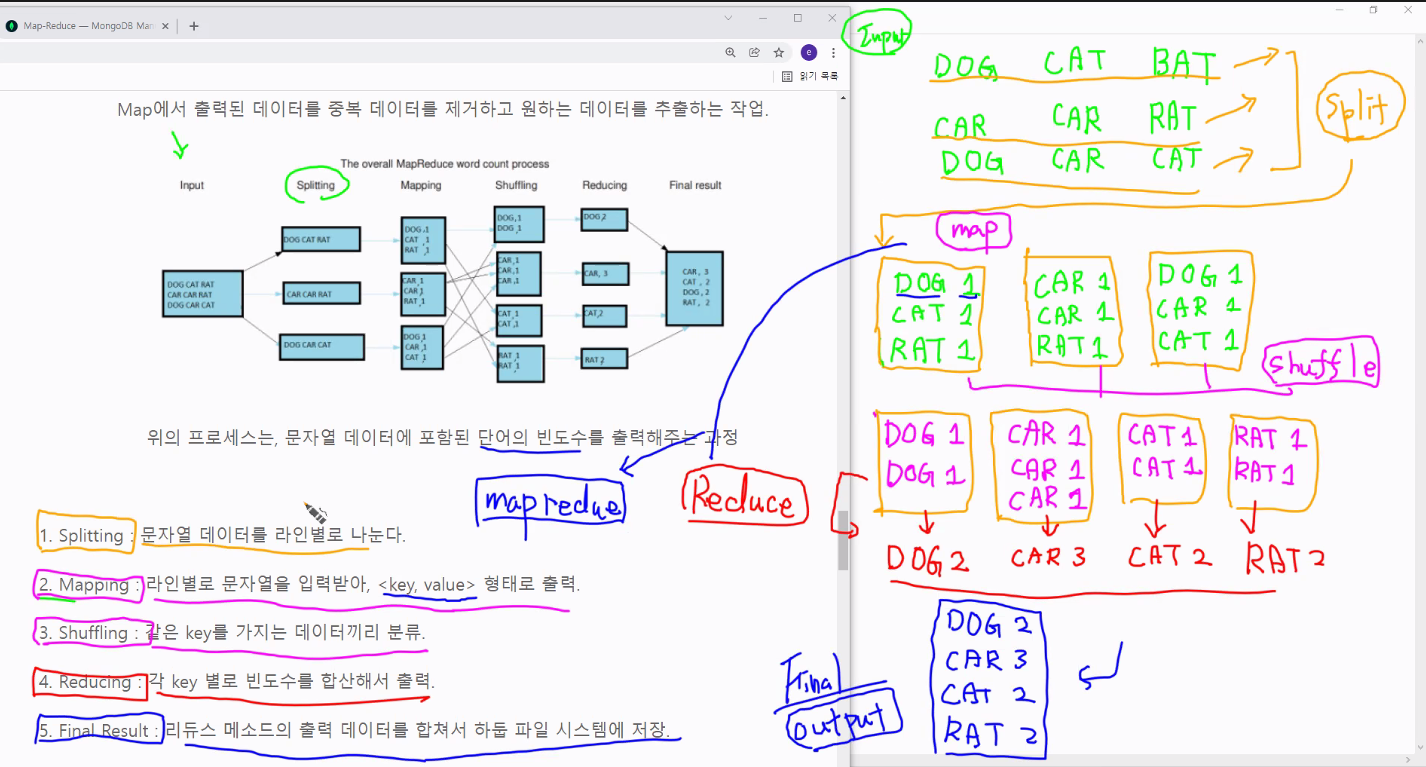 이미지 출처
이미지 출처
 이미지 출처
이미지 출처
Big Data 프로젝트와 기술 영역
목적
- + Money, - Money - Data 수집 위치분석 : ~~~을 알아가는 것
1) 분석종류 - 전통적인 방식 : 샘플에서 전부(모수)를 알아가는 것 - BigData 통계 방식 : 가져다 놓은 Data 전부에서 속성(패턴)이 무엇인지 알아가는 것 2) 프로젝트성 분석종류 - 현황분석 : Data 파악 - 진단분석 : 시계열 Data - 예측분석 : - 최적화분석 :구축 :
1) 구축하기 위한 구성요소 - BigData 제어할 수 지식, 기술, 표현할 수 있는 사람, - Data를 생성, 수집,저장,처리,분석,표현 기술 - 3V + Value[ + Money, - Money ] 가 있는 Data 2) BigData 프로젝트 유형 - Platform 구축 프로젝트 : 설치 - BigData 분석 프로젝트 : 분석 - BigData 운영 프로젝트 : 유지구성방식 : 회사내부 System 구축, S/W Platform, IT Servcie
BigData 처리 과정
1) 수집 : RDB, File, WebCrawling
- [Log Collector]
- Chukwa
- 2008년도 Yahoo에서 분산시스템 로그 수집 및 모니터링
- Hadoop에 의존적 - Flume:
- 2010년도 클라우데라에서 대량의 로그 데이터를 여러 소스에서 수집하여 저장하기 위한 목적으로 개발
- Data 주입이 간단하고, 아키텍처가 유연
- Chukwa
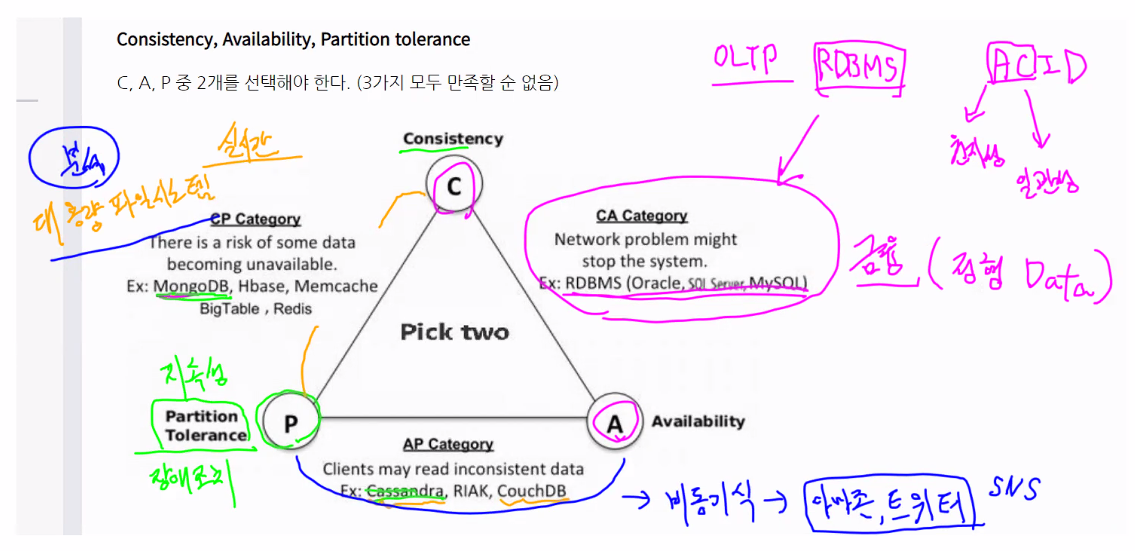
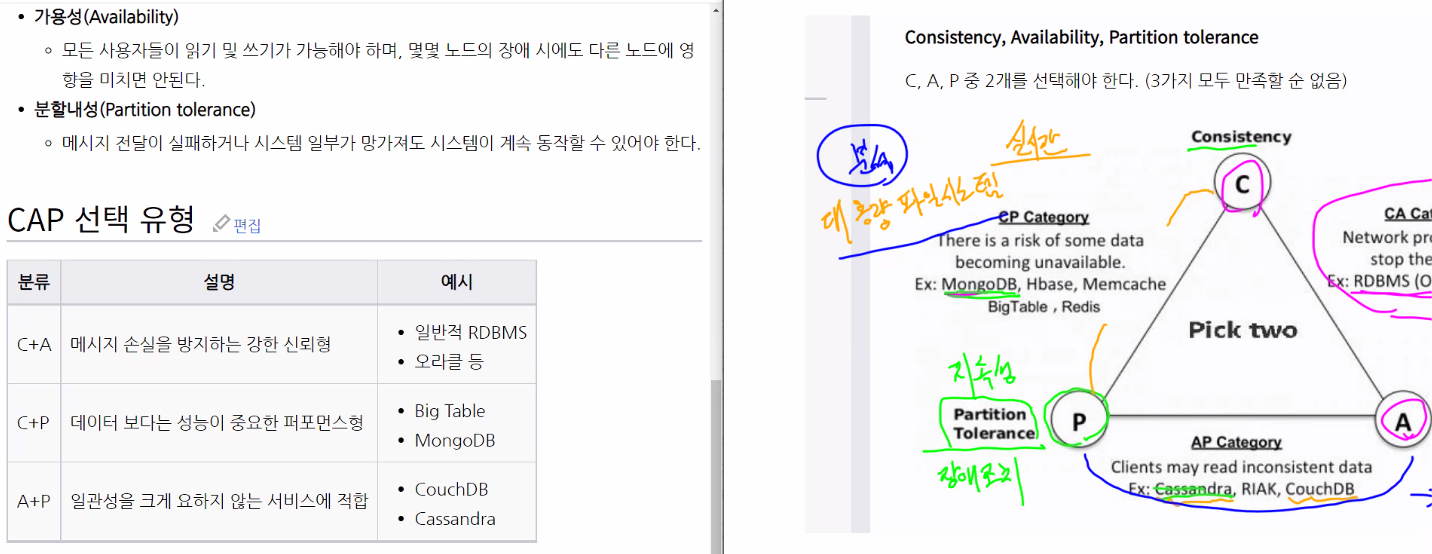
2) 저장(분산): CAP 이론
-
1> 대용량 파일 전체 : HDFS
2> 대규모 메시지 : NoSQL(HBase, MongoDB, Casandra
3> In-Memory Cache (다른 공간에 담는거) : Redis
4> 대규모메시지 데이터 버퍼링 (필요한 순간에 머물러있다 중간에 빼는거) : Kafka -
CAP 이론
 출처
출처
데이터 분석 프로젝트 : 대용량으로 데이터가 들어올걸 고민해서 분산파일 시스템과 실시간 데이터를 담을 수 있는 하둡, MongoDB를 사용
3) 처리 :
[Data 처리]
- Pig : 2006년도, Yahoo에서 데이터 처리 언어 프레임워크
- Hive : 2006년도, Yahoo에서 Hadoop기반 SQL언어로 개발(정형데이터에서 가져올 수 있는 언어)
- Sqoop : 대량의 데이터 전송, 대상은 정형데이터(RDB), 비정형 데이터(NoSQL)에서 대용량 벌크 전송
- Spark SQL
[Workflow 제어]
- Oozie : 2009년도 Apache에서 Hadoop기반 Workflow 제어 시스템
4) Yarn, Spark, Zookeeper
-
Yarn :
수백, 수천개의 노드로 구성된 클러스터에서 작업이 제출되면 수 많은 작업들을 관리하고,
특정 작업에 사용할 자원(CPU, RAM)ㅇ르 관리해주는 분산자원관리 기능을 담당함 -
SPARK : 분산 In-Memory Data 처리 Framework
<- with Python
- SQL (select, filter, join, group by, ,,,)
- Streaming
- MLib(Machine Learning) -
Zookeeper :
- 분산 시스템 간의 정보 공유 및 상태 체크, 동기화를 처리하는 프레임워크
<요약>
하둡이 어떻게 만들어졌고, 부족한 부분을 어떻게 보완했는지 확인하면 됨

Hadoop 개념과 구성
분산 파일 시스템
-
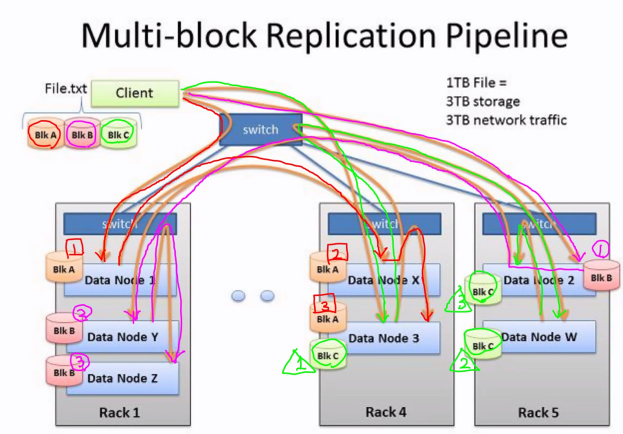
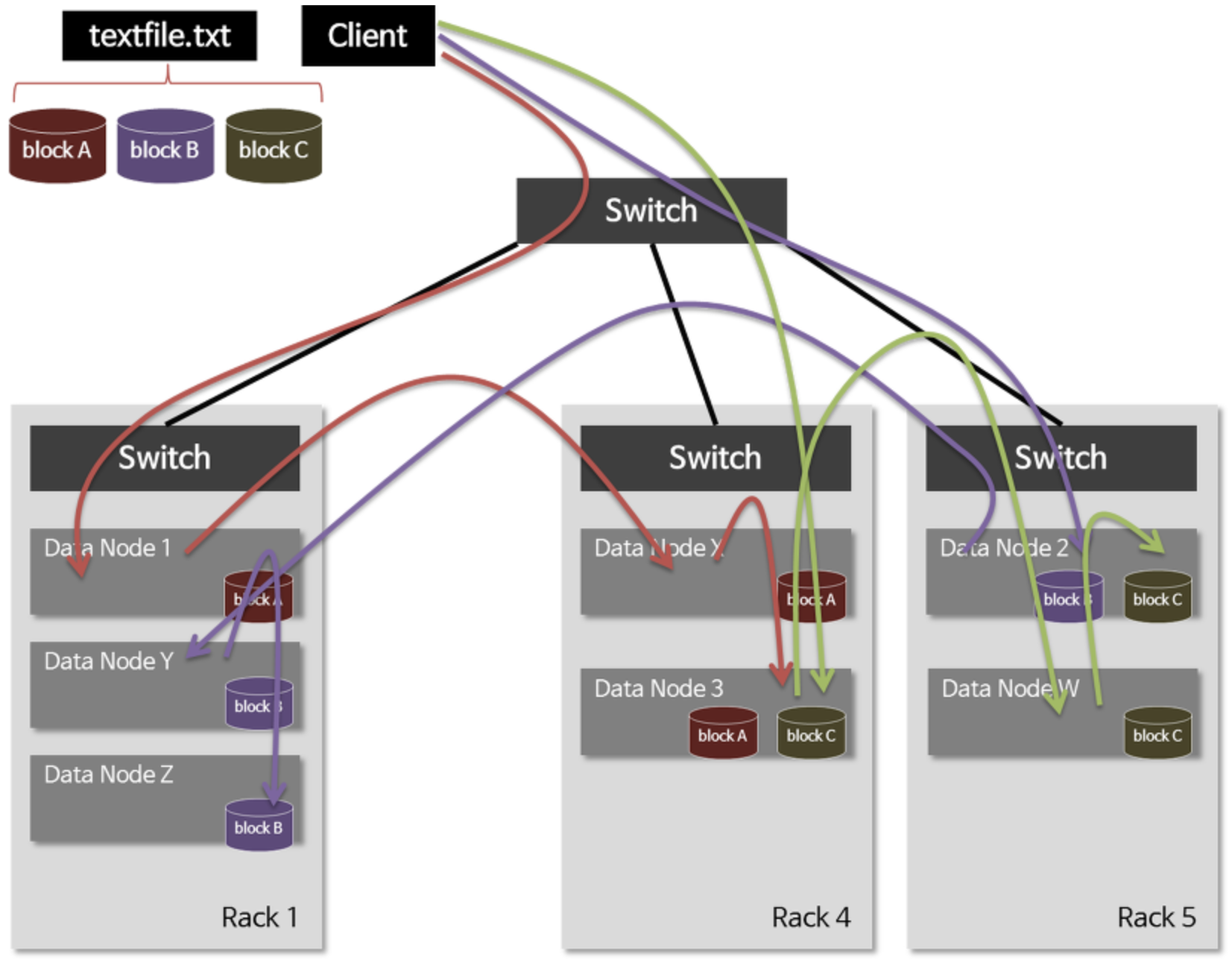
@. Data 저장 : 2개의 Node
Name Node[Master Node] : Data Block 단위
- Data Node 관리
- Directory/File 정보를 포함한 메타 데이터 관리
Data Node - Data 저장 관리
- 복제 관리
-
@. Data 처리 : 2 개의 Tracker
-
Job Tracker
- ex. 라면
- 처리해야 할 Job 항목 -
Task Tracker
- ex. 물을 끓여, 스프와 면을 넣고 3분간 끓인다.
- 하나의 Job에서 처리해야 할 세부 Task
-
-
@. 작업(slot) :
- Map
- Reduce
-
@. 병목현상 처리 :
yarn : <--- hadooop v2.0
- container 단위 처리
- Application Master -> 자원 요청 -> Resource Manager
- yarn이 들어가면서 Hadoop ech system에들어갈 수 있는 모듈들이 많아졌다.
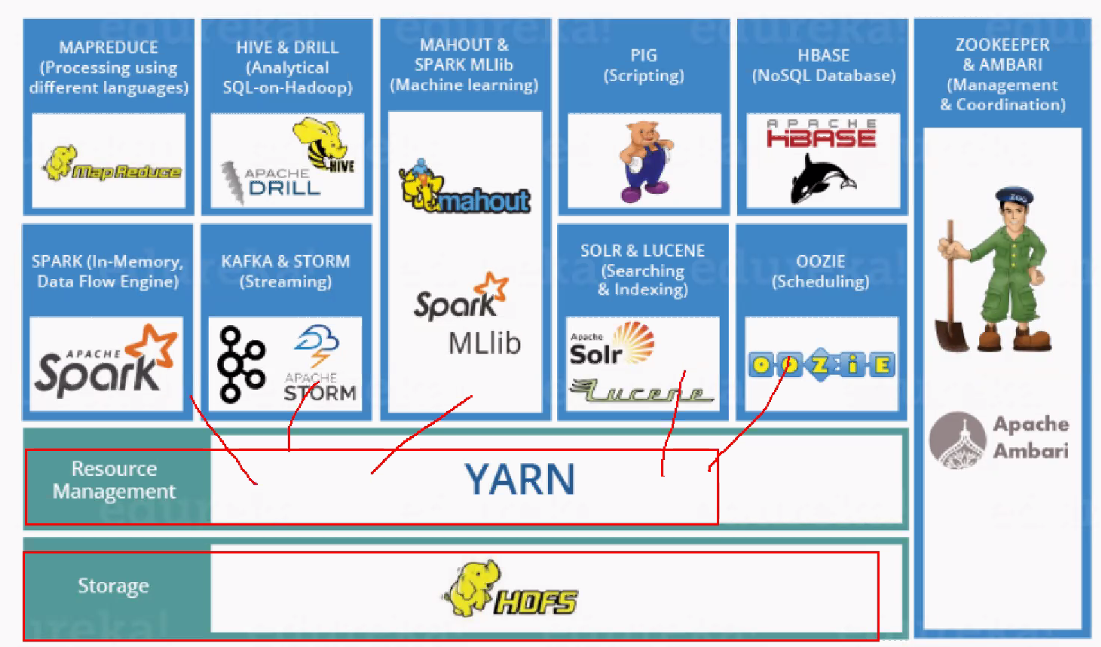
- 결론 : 하둡 echo system에 4가지 구성이 이루어져야함
- 하둡 자체의 구성
- 분산 시스템 구성
- yarn 구성
- map reduce 구성
-
@. Eraser Coding <-- hadoop v3.0
- File 복제(1+2) => Blcok 복제(XOR Parity)
HDFS
- 블록 단위 저장
- 블록 복제를 이용한 장애 복구
- 읽기 중심
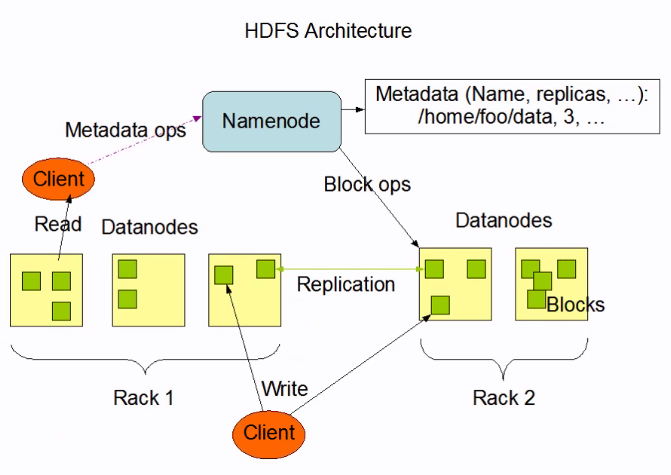
1) Data 장애가 발생한다는 것을 가정하여 설계됨
- 장애 Block을 빼고, 복사본 개수를 다시 채워 유지 --> 고비용의 스토리지는 필요 x
2) hdfs-site.xml / dfs.replication 설정 값을 정의 (default -> 3)
3) 파일 생성, 삭제, append 만 가능 (즉, 수정 불가)
4) Data Node 관리
- 데이터 저장
- 데이터 복제
- 블록 단위 관리
- 활성상태 확인
- heartbeat 설정 (중요)
- main 노드는 살아있을 때 던지면 보관 안함- 데이터 노드가 살아있다는 표시가 주기적으로 왔다갔다 안하면, 중앙에서는 이미 있다 생각해서 보관 안함
- 블록 단위 복제 => 복구할 틈이 없음 블록 단위 복제 하며 고 성능의 스토리지 장비는 필요 없음
- 아예 장애가 났을 때 빠른 대처 안하면 복구 못함
비용을 낮추는걸 선택
블록단위 복제 하면서 -> 비용을 낮추면서 -> 장애가 나면 복구할 틈이 없을 수 있다. - 데이터 노드가 활성화 되어있는지 확인하는게 중요하다.
- 운영 상태
- 서비스를 잠시 멈춰야 할 경우 블록을 안전하게 보관하기 위해 설정- 운영중 여러가지 상태가 있음 - 1. 나 살아있어 / 2. 나 죽어있어
- 안정적으로 데이터 이전시켜둘래 말래?
- 데이터가 안전하게 보관
- 장애가 되지 않도록, 삭제되거나 append되는걸 방지 => 읽기 전용으로 만들음
- 운영상태에 대해서 어떻게 둘지
- 서비스를 잠시 멈춰야 할 때 하는 얘기
5) Secondary Name Node
- Fsimage 와 Edits 파일을 주기적으로 Merge
- 최신 Block의 상태로 파일을 생성함
- Edits 파일을 삭제함으로써, Disk 부족 문제를 해결함
네임노드가 구동되고 나면 Edits 파일이 주기적으로 생성됩니다. 네임노드의 트랜잭션이 빈번하면 빠른 속도로 Edits 파일이 생성됩니다. 이는 네임노드의 디스크 부족 문제를 생성할 수도 있고, 네임노드가 재구동 되는 시간을 느려지게 할 수도 있습니다.
세컨더리 네임노드는 Fsimage와 Edits 파일을 주기적으로 머지하여 최신 블록의 상태로 파일을 생성합니다. 파일을 머지하면서 Edits 파일을 삭제하기 때문에 디스크 부족 문제도 해결 할 수 있습니다.
6) HDFS Federation
- hdfs 의 목적 !
한 군데에서 다수의 NamenNode가 생성 가능하다.
메모리 영역을 분리해서 , 서로 다른 NameNode에 영향을 주지 않게 한다.
7) HDFS HA - QJM(Quorum Journal Manager)
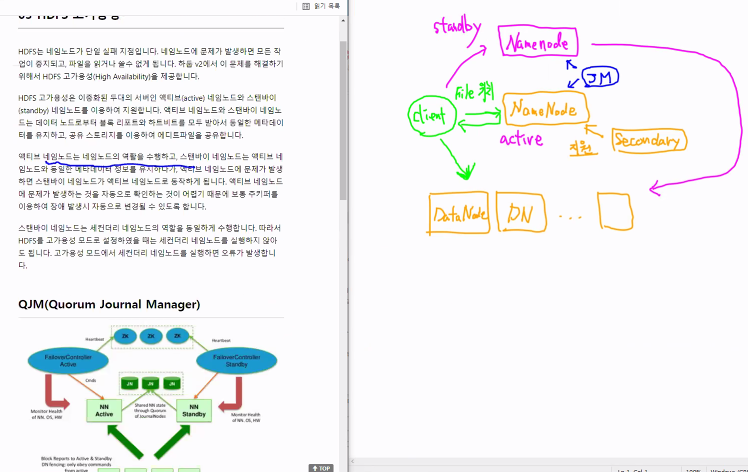
-
Active NameNode, Standby NameNode 구성
-
Block Report , Heartbit 를 이용해서 동일한 메타데이터 유지
- 공유 Storage 를 이용하여 Edit 파일 공유
- Standby NameNode 는
+ Secondary Name Node 기능도 함
+ 그래서, HA 구성시, Secondary Name Node 구성 안 함
NameNode를 하나 더 만들어 둠
client가 복제된 NameNode는 대기 상태 (stnadby)
client NameNode (active)
NameNode간 정보가 공유되어야 함.
이 단자가 QJM
Journal Manager가 양쪽에게 서로 알려줌
so, 변형되는 정보들을 DataNode에서도 알게되는 것임
secondary : 지원의 역할 (복제 아님)
실시간으로 모니터링하는애 : 주키퍼
고가용성이 된다면, NameNode가 Secondary 역할을 하다가 문제가 생겼을 때 NameNode가 올라감
NameNode는 Secondary 역할 + HA(고가용성)
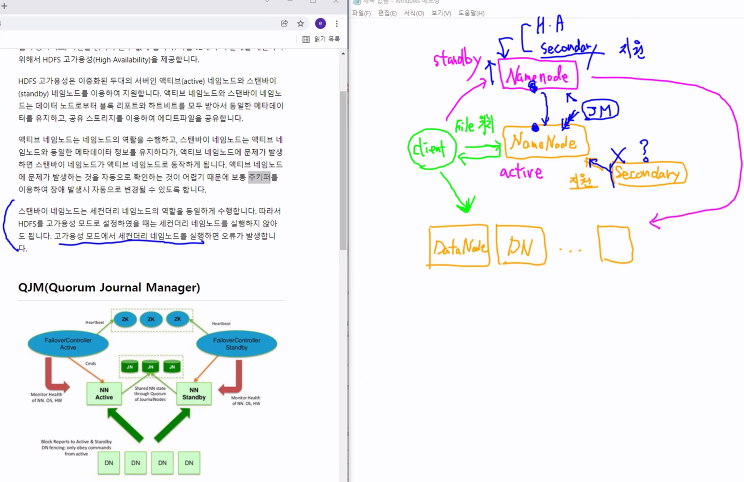
HA -> HDFS에서 -> QJM이 하고있다
zookeeper는 위의 기능 포함해서 더 많은 것을 해결할 수 있음
참고 https://wikidocs.net/22652
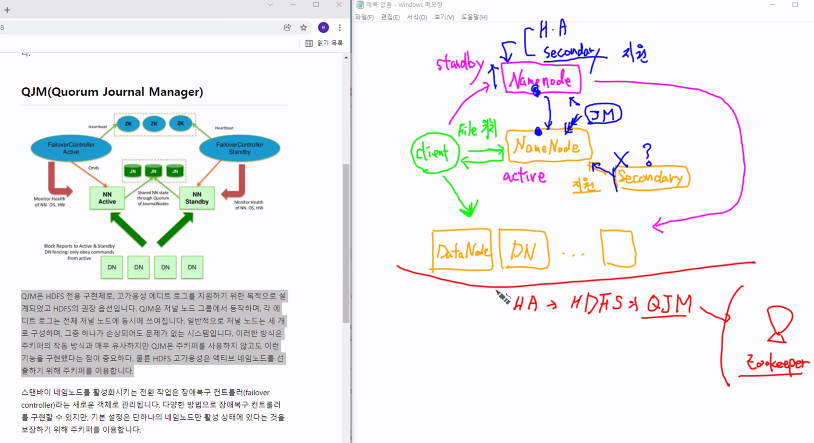
8) HDFS Tresh- 휴지통 기능
9) HDFS 명령어
10) HDFS API 설정
11) HDFS 암호화
12) HDFS Balancer
- 데이터 불균형이 발생하는 경우 -> 고쳐야함 -> so, 이전시킴
*** CMD -> echo

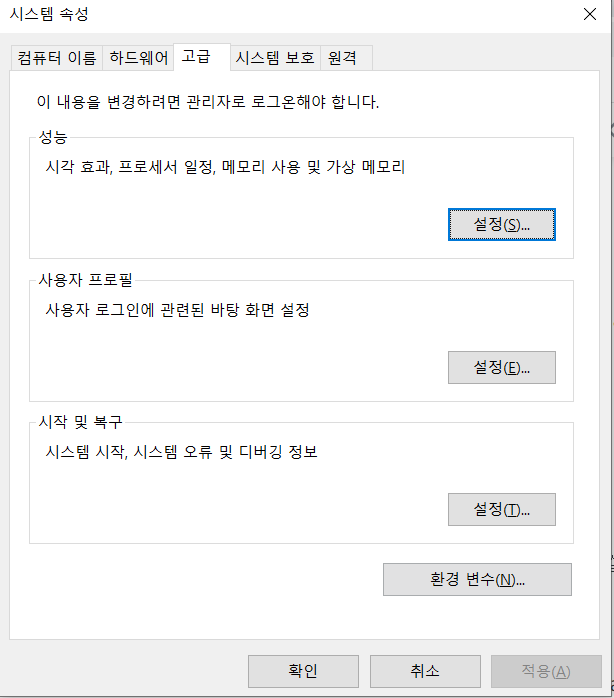
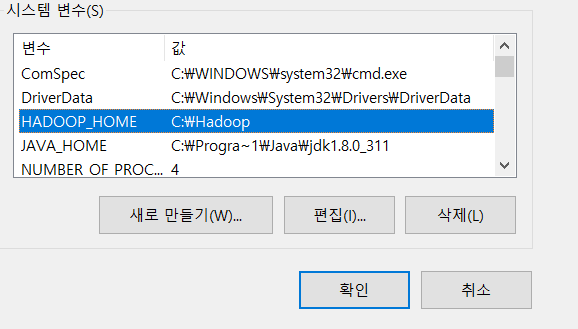
HADOOP 변경함 ㅠ
