1. Apache Spark란?
- 오픈 소스 클러스터 컴퓨팅 프레임워크
중요 개념
https://spark.apache.org/
1) multi language : Scala, Python, R, Java, SQL
2) cluster : 데이터 처리에 대한 cluster
3) 데이터 처리에 대한 얘기
= > Apache Spark는 Apache Hadoop 내에 있는 spark임
= > 즉, Hadoop Eco System에 spark를 올림
= > 하둡 에코시스템에 여러개 꽂아 사용할 수 있음
[Hadoop eco system]
scala, python, sql, java, R
hive, sqoop, flume , spark
=> spark를 hadoop eco system에 올림 -> 하둡이 더 빨라짐 Spark 성능
- hadoop :
disk i/o 하며 처리
메모리에서 끝나는게 아님
하둡은 분산 컴퓨팅 플랫폼 - spark :
스파크는 인메모리 기반 대용량 데이터 고속 처리 엔진
=> 맵리듀스 처리 엔진을 메모리에 올려서 처리- 작업이 메모리에서 끝남
- In Memory Type => 작업을 다 메모리에서 끝냄
- 분산처리시 하둡보다 100배가 빠름
- 작업에 메모리를 구성해줘야함 (작업 하나 당) => 워커노드
- worker node 하나에 메모리를 얼마씩 구성할 건지 설정 해줘야 함
- MASTER-SLAVE 방식
주관자가 있고 WORKER NODE가 실행할 수 있게 되어있음
Spark sbin, bin 구성 내용
spark 도구가 설치되어있는지 확인( bin, sbin )
cd bin 언어적인 도구는 bin에 들어있음 pyspark, sparkR , spark-shell, spark-class ..
ls
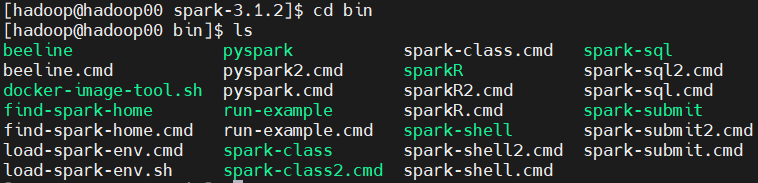
ls ../sbin : 구성을 하며 일을 시키는 작업은 shell을 씀 start-master.sh, start-slaves.sh ...

- 분산 병렬 처리에 대한 일을 시킬 때, job을 구성하는 언어를 pyspark를 이용해 pthon, spark r을 이용해 r, hive를 통해 spark sql로도 사용할 수 있다.
- sbin은 architecture를 그리는 것의 집합
2. 설치 환경
main host :
os windows 10
mem : 16GB
4cpu
vm <- spark
os : centos8
mem : 8GB
3cpu3. Apache Spark 설치
-
Spark 3.2.1 버전 Download
https://spark.apache.org/downloads.html
하둡버전도 맞춰주는것이 중요!

free -g=>메모리 사용량 확인
grep -c process /proc/cpuinfo=> cpu 코어 개수 확인 -
설치
설치 경로 : /home/hadoop/downdata

https://www.apache.org/dyn/closer.lua/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz
cp -r spark-3.1.2-bin-hadoop3.2 /home/hadoop/spark-3.1.2

cd=>ll
4. 환경 설정
1) bashrc 파일에 환경변수 추가
- SPARK_HOME 환경변수와 Spark bin, sbin 디렉토리 경로를 PATH에 추가
vi .bashrc
export SPARK_HOME=/home/hadoop/spark-3.1.2
export PATH=$PATH:$HADOOP_HOME/sbin:~~~~:$FLUME_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
source .bashrc
echo $SPARK_HOME
spark-submit --version
spark-submit --help==> welcome to spark 나오면 성공! 
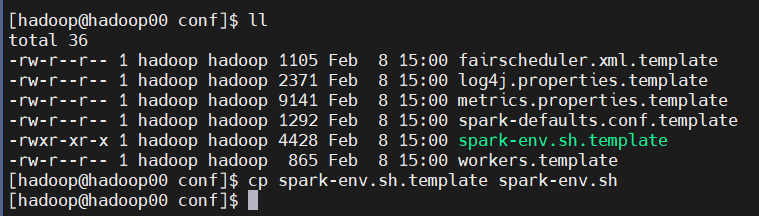
2) spark env 파일 수정
- /home/hadoop/spark-3.1.2/conf 경로에서 spark-env.sh.template 복사 후 아래 내용 추가
cp spark-env.sh.template spark-env.sh
- SPARK_WORKER_INSTANCES : worker의 수 지정
vi spark-env.sh
# - MESOS_NATIVE_JAVA_LIBRARY, to point to your libmesos.so if you use Mesos
export SPARK_WORKER_INSTANCES=2
# Options read in YARN client/cluster mode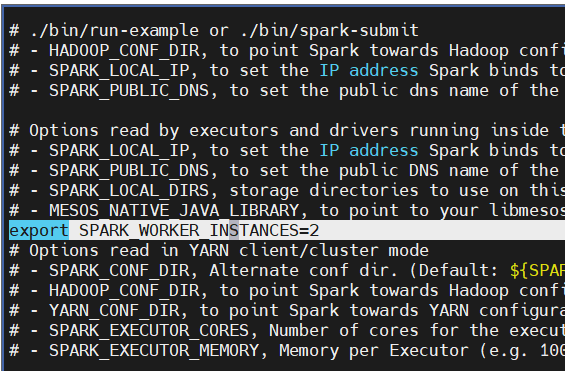
5. Spark 실행
-
hadoop 실행 (선행되어 있어야 함)
start-dfs.sh
start-yarn.sh
jps=> 5개 올라와있는지 확인 -
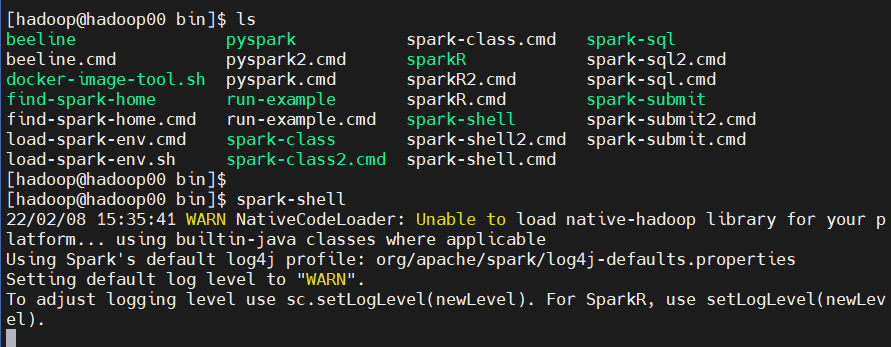
Spark 실행
spark-shell
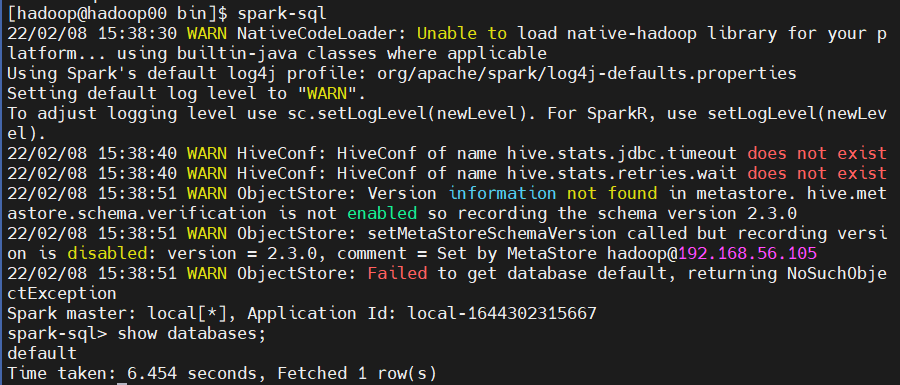
spark-sql
pyspark
오류 발생 => /usr/bin/python3 : No such file or directory
python 설치하면 해결! 아래 글 참고
https://velog.io/@yje876/Error-%ED%95%B4%EA%B2%B0-pyspark-%EC%98%A4%EB%A5%98
- master job 실행
sh start-master.sh

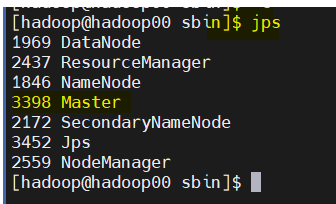
- 상태 확인 => master가 올라왔는지 확인
jps
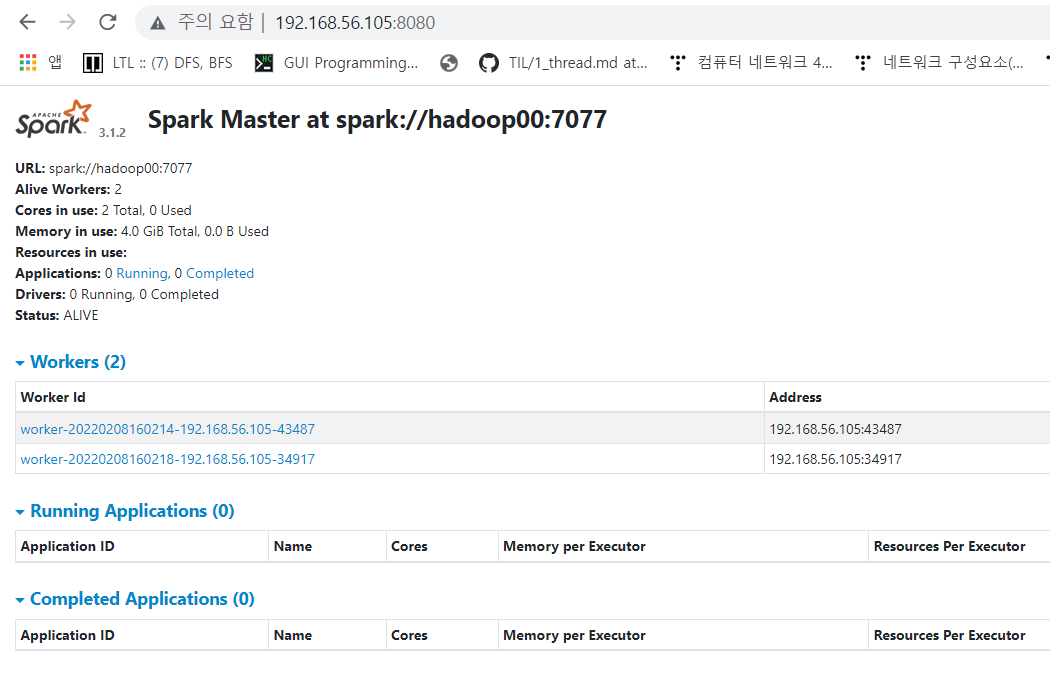
- Spark Web UI 확인
spark://hadoop00:7077 - 여유 공간 확인
free -g

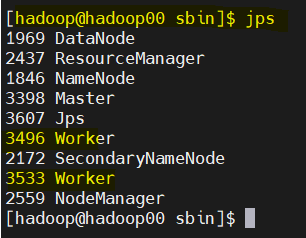
- master가 실행되는 위치에 worker node를 실행 (메모리, cpu 지정해 할당 )
sh start-slave.sh spark://hadoop00:7077 -m 2g -c 1 - 상태 확인
jps
worker가 2개 올라왔는지 확인
6. 예제 실습
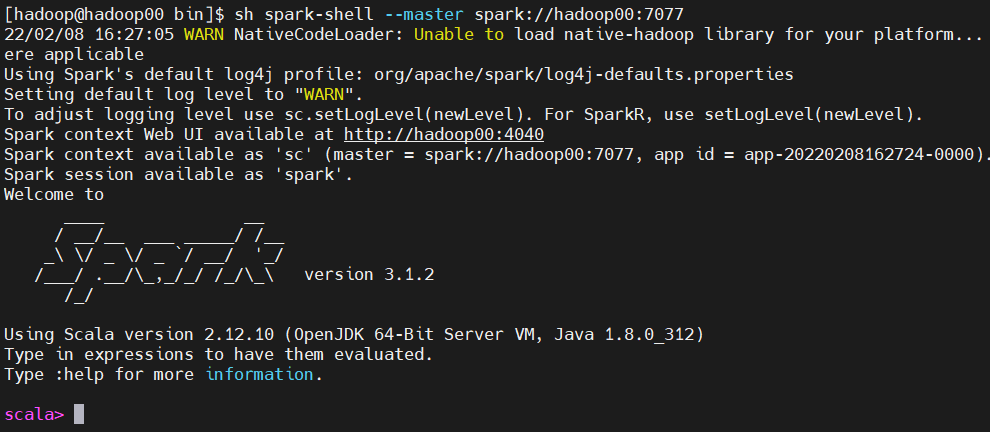
1) 작업을 spark master 위치에 올리기
pwd : /home/hadoop/spark-3.1.2/bin
sh spark-shell --master spark://hadoop00:7077
2) README.md 확인
3) Spark Shell에서 README.md count
val lines = sc.textFile("README.md")
lines.count()
4) ip:8080에서 running application 확인

5) Spark shell 확인
- 오류
참고하면 좋은 사이트
- 빅데이터 스칼라 스파크 시작하기
https://wikidocs.net/28377 - spark sample 예제
https://spark.apache.org/examples.html - Http Rest Client
https://jamong-icetea.tistory.com/250 - ReFS
https://studyforus.tistory.com/104 - Spark 설치
https://hoyy.github.io/posts/spark-start-install-standalone
