HDFS 설치 1 - Windows
Java 버전 => jdk 1.8 +
- Hadoop v2 : jdk 1.7+
- Hadoop v3 : jdk 1.8+ Hadoop 버전
- Hadoop v2.7
- Hadoop v3.2.2
압축해제 -> bandizip, 7zip
- "~~.tar.gz"
폴더 구성 / 확인
C:\HadoopPrj\Hadoop v2.7\
\etc\~~~~~~.xml core-site.xml ==> 이름, port
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9870</value> </property> </configuration>
hdfs-site.xml ==> namenode, datanode
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///C:/HadoopPrj/hadoop-3.2.2/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///C:/HadoopPrj/hadoop-3.2.2/data/datanode</value> </property> <property> <name>dfs.namenode.checkpoint.dir</name> <value>file:///C:/HadoopPrj/hadoop-3.2.2/data/namesecondary</value> </property> <property> <name>dfs.namenode.http-address</name> <value>localhost:9860</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>localhost:9850</value> </property> </configuration>
yarn-site.xml # yarn
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <description>Yarn Node Manager Aux Service</description> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>file:///C:/HadoopPrj/hadoop-3.2.2/data/tmp</value> </property> </configuration>
mapred-site.xml # 맵리듀스
<property> <name>mapreduce.framework.name</name> <value>yarn</value> <description>MapReduce framework name</description> </property> </configuration>
\sbin
- hadoop-env.cmd 확인 
- start-dfs.cmd 수정
start "Apache Hadoop Distribution" hadoop secondarynamenode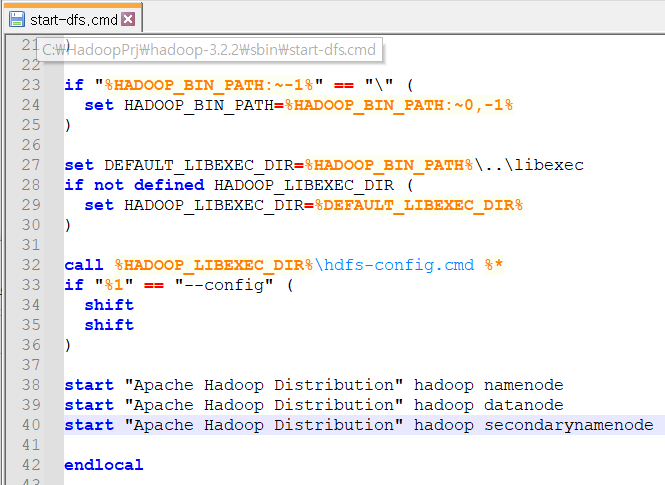
- stop-dfs.cmd
Taskkill /FI "WINDOWTITLE eq Apache Hadoop Distribution - hadoop secondarynamenode"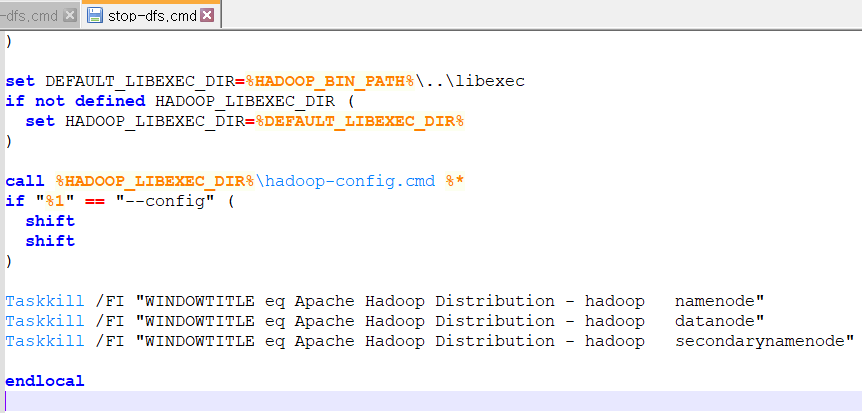 [참고]
[참고] 폴더 생성
~~/data
/datanode
/namenode
/namesecondary
/tmp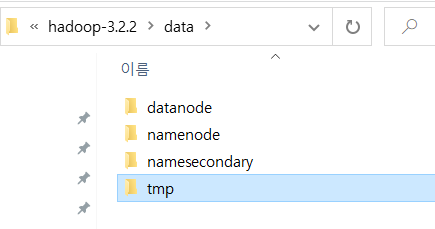
환경변수
-
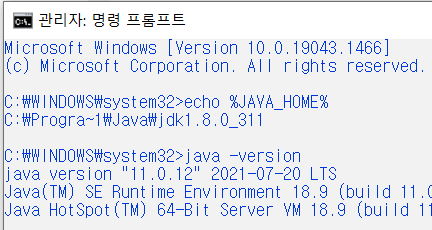
JAVA_HOME: echo $JAVA_HOME% (환경변수 설정 확인)
--> C:\Program"Files\Java\jdk1.8.0_301
--> C"\Progra~1\Java\jdk1.8.0_301 -
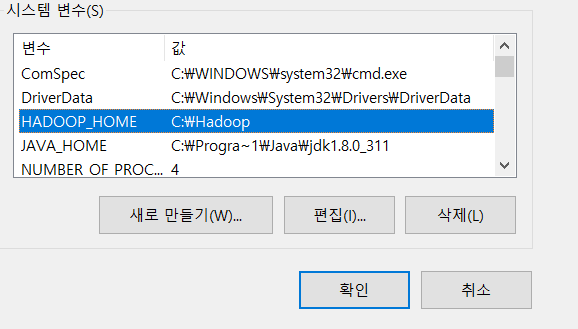
HADOOOP_HOME : echo %HADOOP_HOME% (환경변수 설정 확인)
--> C:\HadoopPrj\hadoop-3.2.2 -
path에서 추가
--> %JAVA_HOME%\bin
--> %HADOOP_HOME%\bin
--> %HADOOP_HOME%\sbin
-
확인
-> hadoop version
-> hadoop -version
hdfs namenode - format
- winutils.exe 다운로드(버전에 맞게)
- hadoop.dll 다운로드(버전에 맞게)
- Hadoop v0.0.zip --> Hadoop v0.0.bak
https://github.com/cdarlint/winutils --> hadoop/bin에 옮기기
- 확인
정상 실행 확인
- Powershell or CMD [관리자 권한 실행]
hadooop -version
hadooop version
hadoop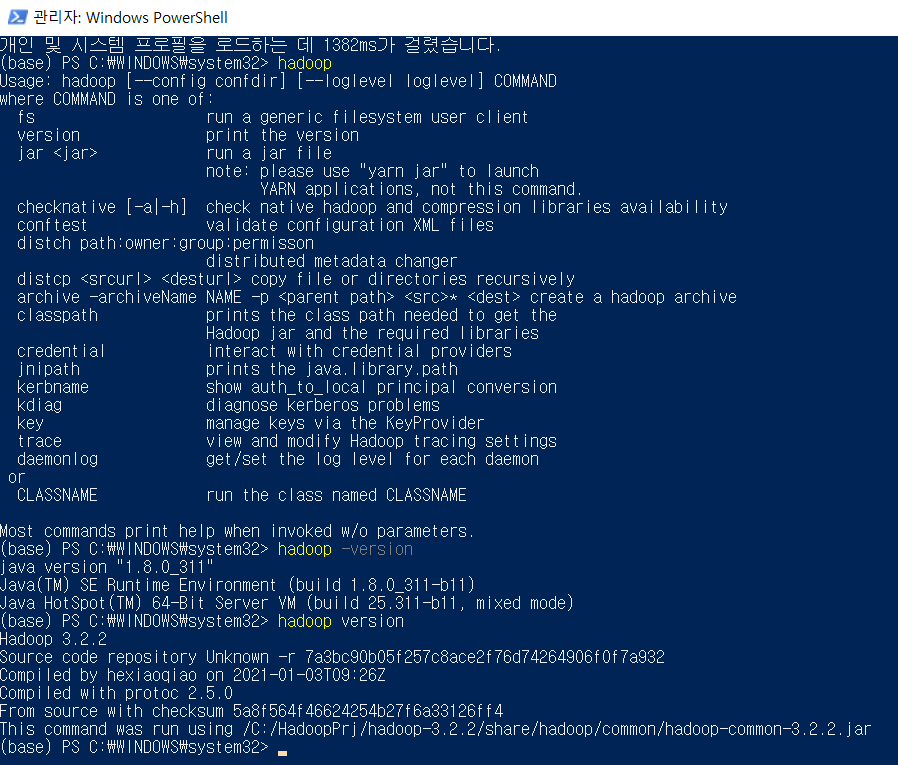
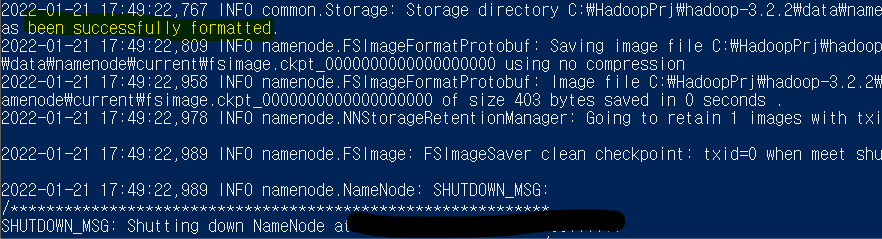
hdfs namenode -format
been successfully formatted 나왔으면 오류 없이 잘 실행된 것
namenode 파일에 아래 파일들이 들어가있는지 확인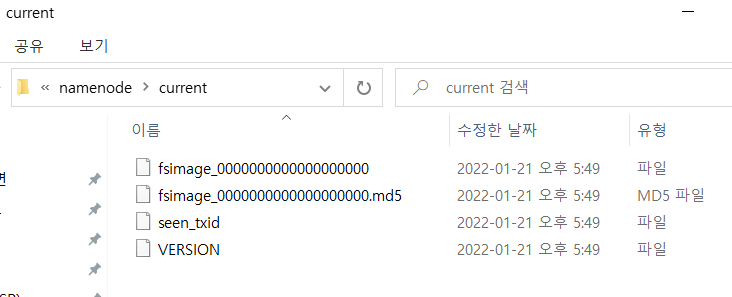
start-all.cmd
jps: 5개가 나오는지 확인 (ResourceManager, SecondaryNamenode, DataNode, Jps, NodeManager)

localhost:9860
9870: service
9860 : namenode
9850 : secondary node 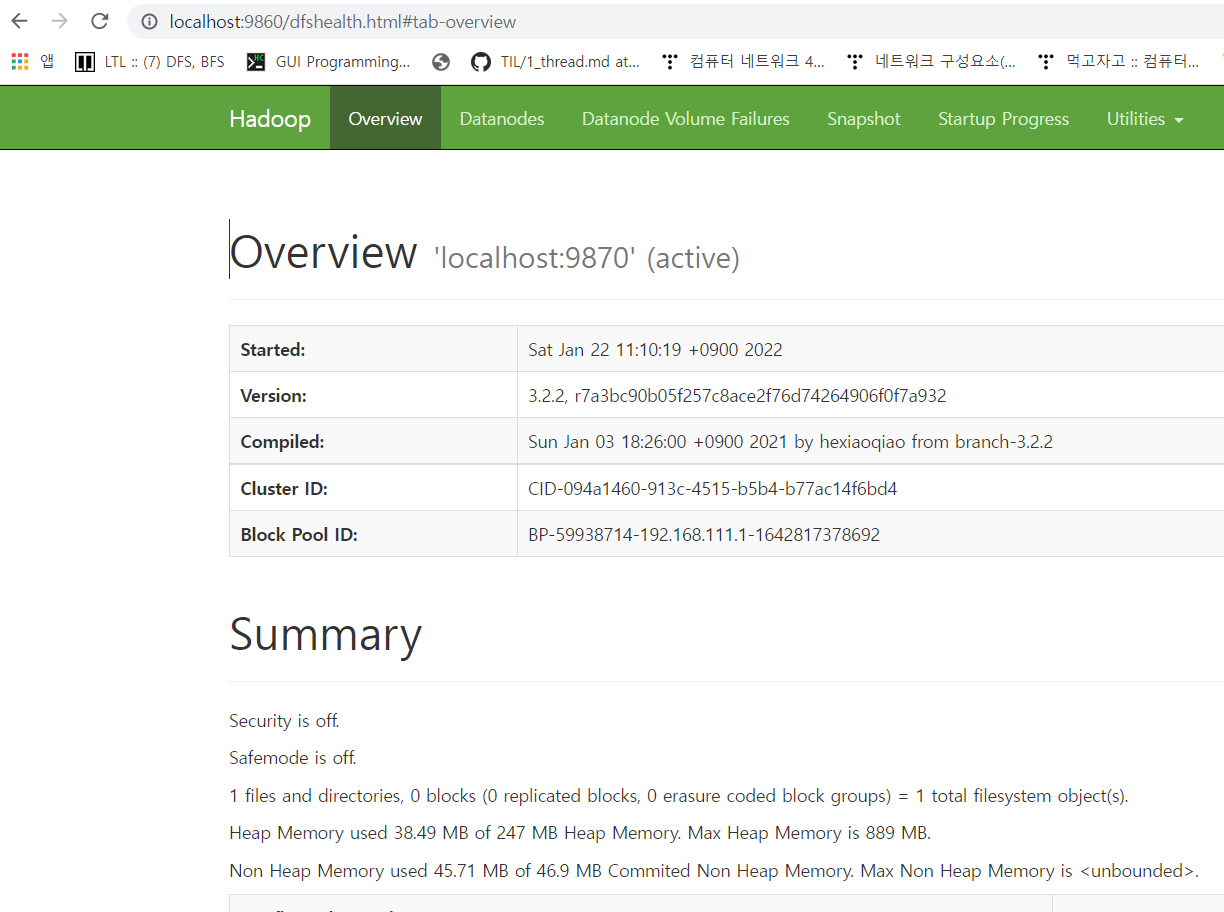
HDFS 실습
실습 01 : File 생성, 주입
hadoop fs -ls / : fs 명령어 -> 파일 확인
hadoop dfs -ls / : dfs 명령어 -> 파일 확인 
hadoop fs -mkdir /test00
hadoop fs -ls /

hdfs dfs -mkdir /test01 : hdfs 파일 생성
hdfs dfs -ls / : 생성 확인 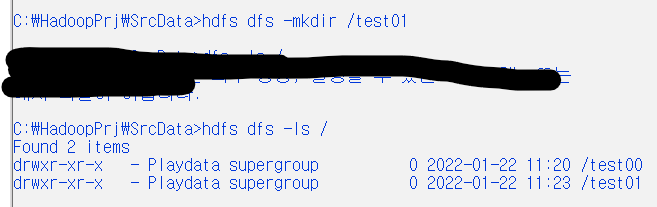
copyFromLocal로컬 파일을 hdfs로 복사 =put
copyToLocal hdfs 파일을 로컬로 복사 = get
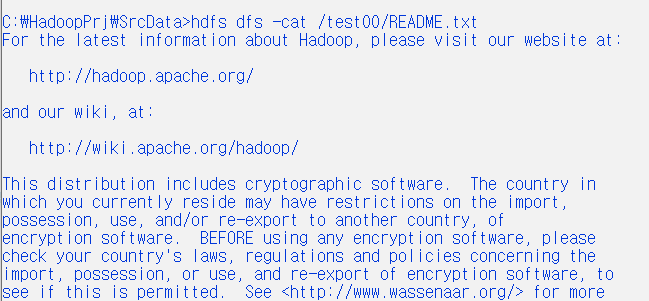
hdfs dfs -put ./README.txt /test00
hdfs dfs -ls -R /

hdfs dfs -cat /test00/README.txt
hdfs dfs -touchz /test01/test11.txt : 0byte 파일 생성

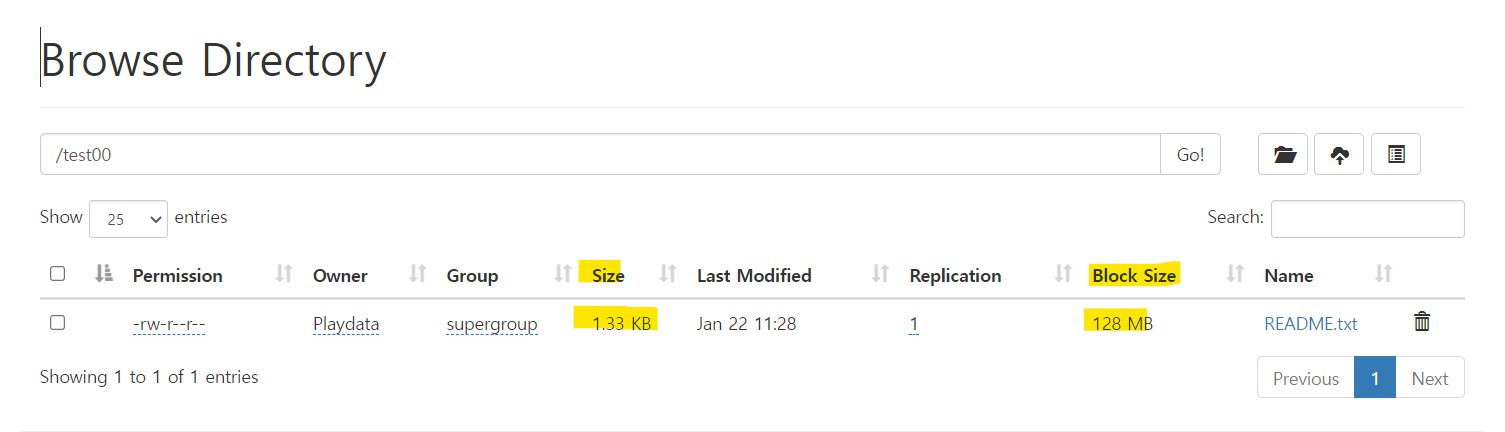
localhost:9860/explorer.html#/

http://localhost:9860/explorer.html#/test00
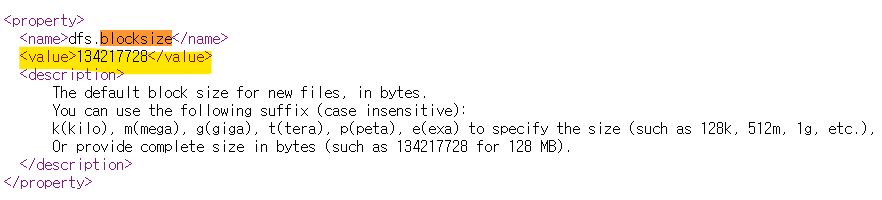
=> 파일 사이즈에 비해 block size가 너무 큼 -> 낭비 -> 바꾸는 방법
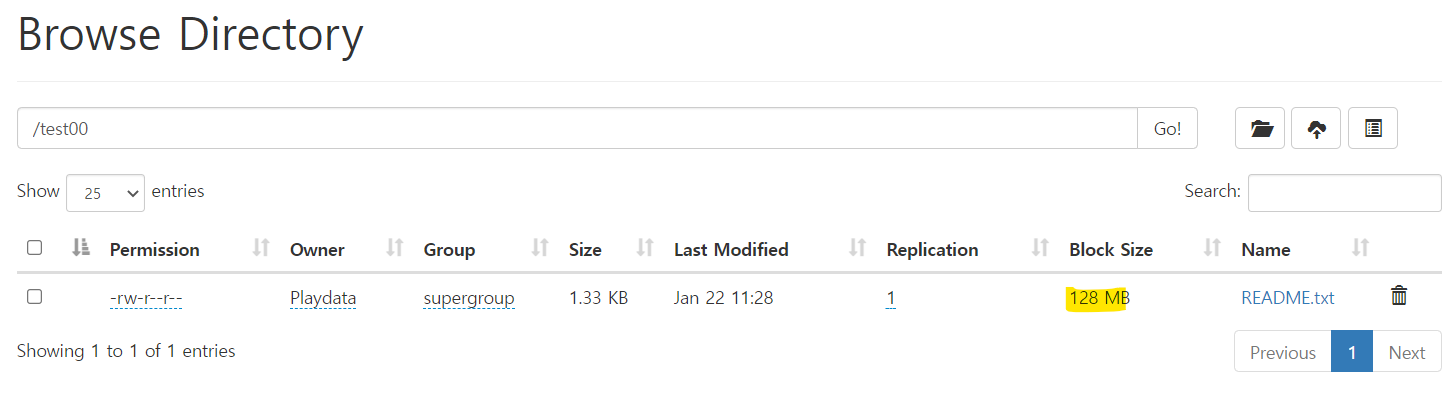
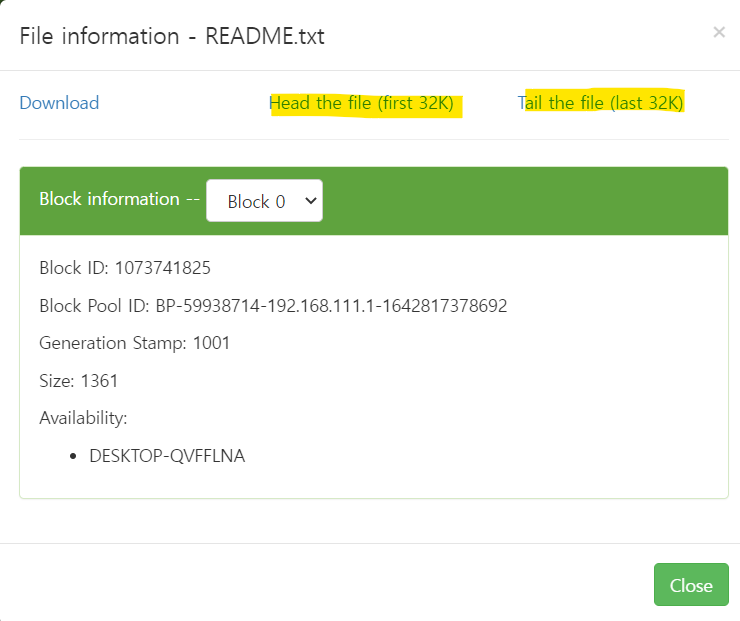
** 파일 사이즈에 비해 block size가 너무 큼 -> 낭비 -> 바꾸는 방법
-
hdfs-default.xml 수정해서 default size 변경 가능
-
dfs에 default size값이 들어감
view-source:https://hadoop.apache.org/docs/r3.2.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
-
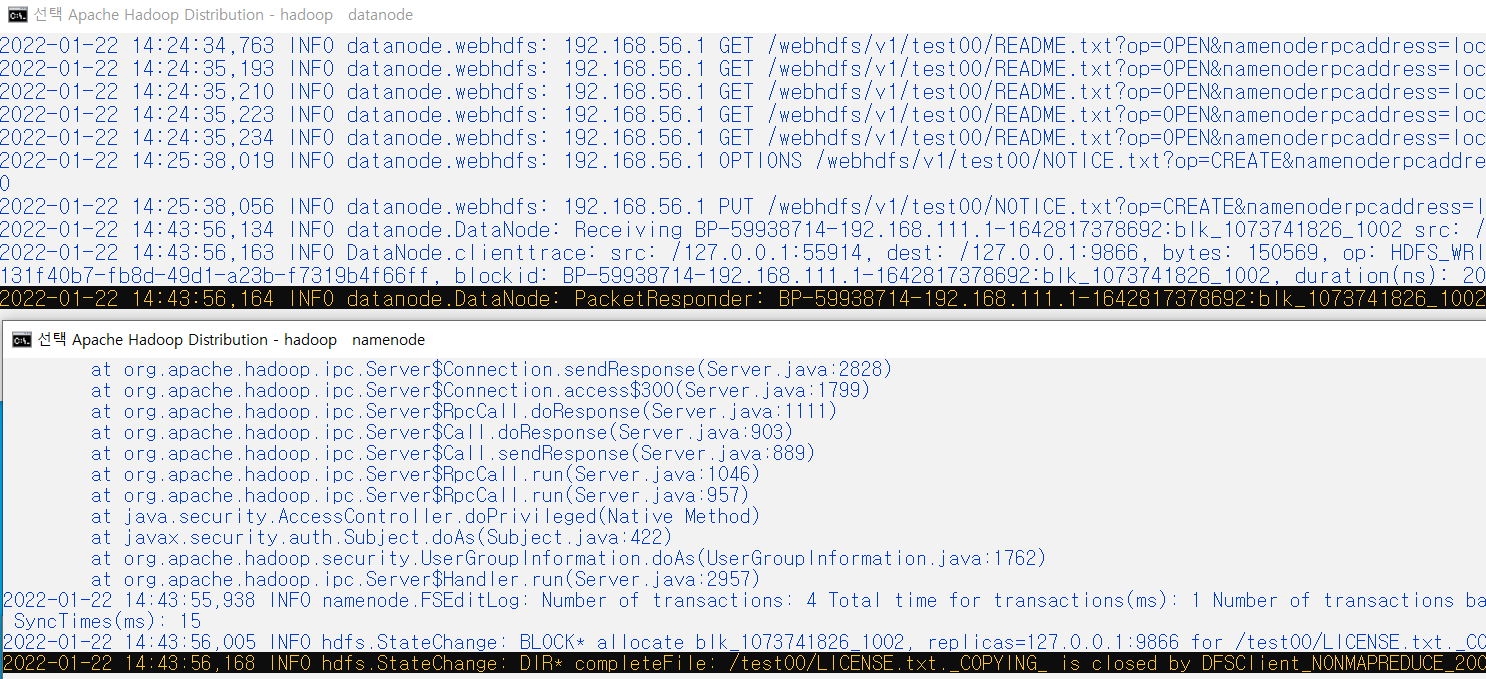
데이터를 Upload 했을 때, datanode, namenode, secondary node가 올라가는지 확인



실습 02 : java wordcount 1
mapreduce, hdfs만 나왔을 때 언어는 뭘 썼을까?
word count를 yarn, map reduce로 할 수 있음 => java를 써서 하면 됨
java가 어딨는데?
여기!
hadoop에서 호출할 수 있는 jar 파일들 => java와 연동만 가능하면 호출해서 사용할 수 있음
https://hadoop.apache.org/docs/r3.2.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html

wordcount 위치
hadoop-mapreduce-examples-3.2.2.jar - 여기에 wordcount O
이 클래스 이용해
wordcount /count할 대상 폴더/ 출력할 폴더 지정해주면 여러개를 wordocunt해서 출력폴더로 내뱉음
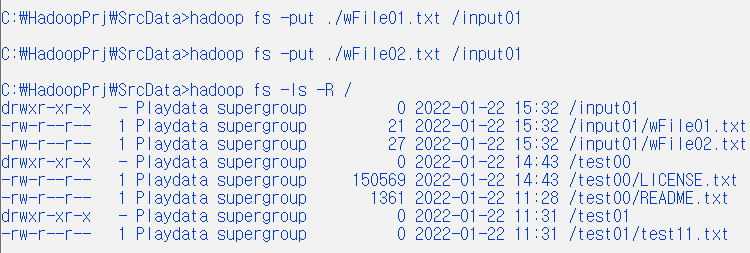
1. hdfs /input01 directory 만들어서 /wFile01.txt : [Hello World Bye World] /wFile02.txt : [Hello Hadoop Goodbye Hadoop] Local 파일(wFile01.txt, wFile02.txt) 복사하기 2. hdfs /output01 로 wordcount





#. hadoop jar hadoop-mapreduce-examples-3.2.2.jar wordcount /대상폴더 /출력폴더
hdfs /input01
/wFile01.txt : [Hello World Bye World]
/wFile02.txt : [Hello Hadoop Goodbye Hadoop]
# wFile01.txt, wFile02.txt input01에 복사
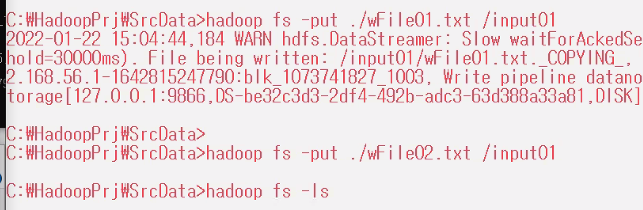
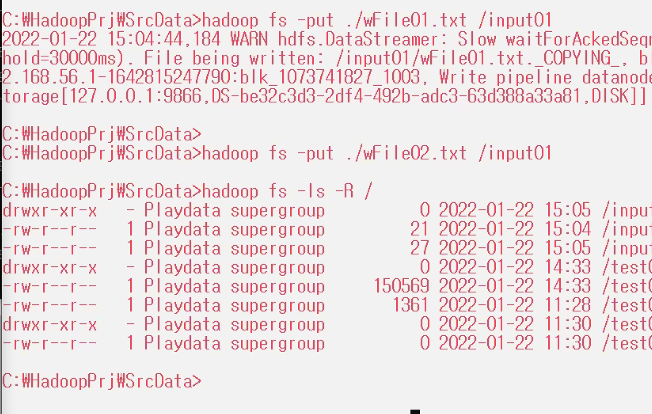
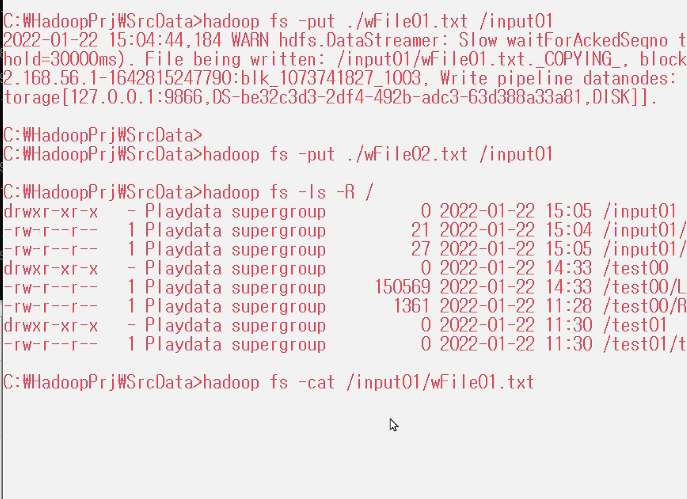
hadoop fs -put ./wFile01.txt /input01
hadoop fs -put ./wFile02.txt /input01
# file 확인
hadoop fs -ls -R /
# file 내용 확인
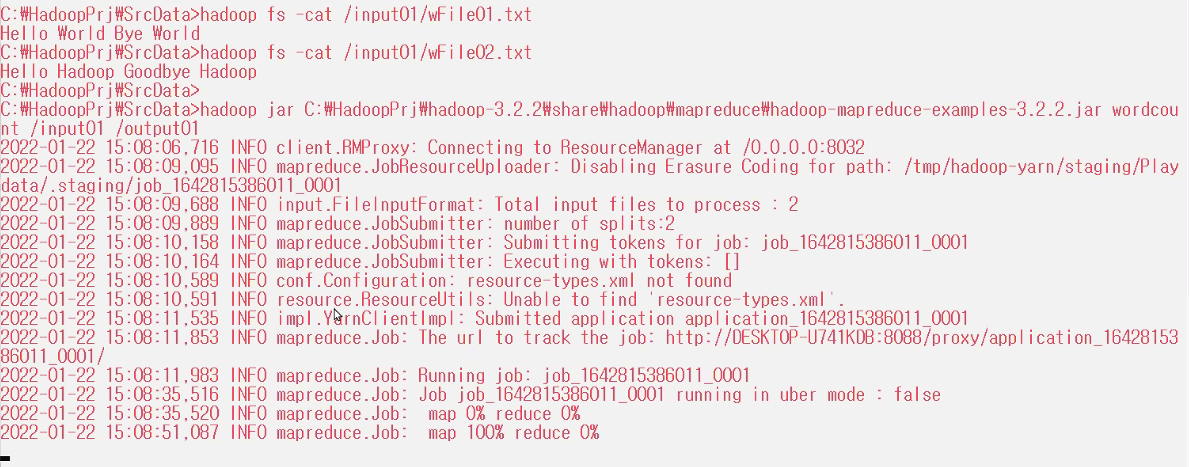
hadoop fs -cat /input01/wFile01.txt
hadoop fs -cat /input01/wFile02.txt
# wordcount
==> hadoop jar C:\~~~~\hadoop-mapreduce-examples-3.2.2.jar wordcount /input01/output01
hadoop jar C:\HadoopPrj\hadoop-3.2.2\share\hadoop\mapreduce\hadoop-mapreduce-examples-3.2.2.jar wordcount /input01 /output01
hadoop fs -ls /
hadoop fs -ls /output01
hadoop fs -cat /output01/part-r-00000
실습 02 : java wordcount 2
hdfs input02
LICENSE.txt
NOTICE.txt
README.txt
output 처리
==> hadoop jar wordcount / input01 /output02

-UI에서도 확인 가능
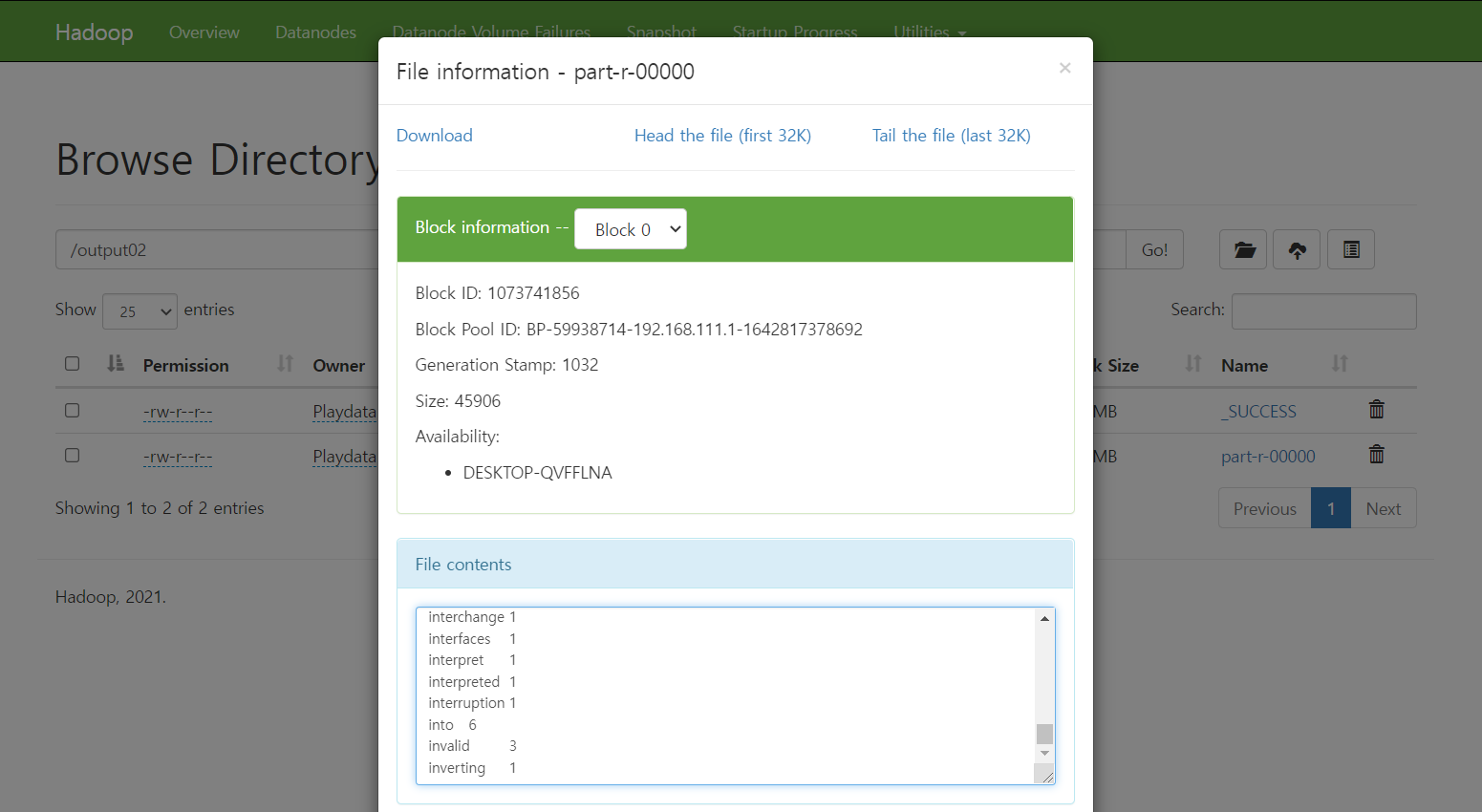
ff

-OUTPUT 폴더 새성 확인



hdfs 명령어 참고:
https://wikidocs.net/book/2203
https://wikidocs.net/26496#touchz
[ Hadooop 환경설정 참고 사이트]
- https://towardsdatascience.com/installing-hadoop-3-2-1-single-node-cluster-on-windows-10-ac258dd48aef
- https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html
- https://hadoop.apache.org/docs/r3.2.2/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
- view-source:https://hadoop.apache.org/docs/r3.2.2/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
- https://hadoop.apache.org/docs/r3.2.2/
*** CMD -> echo

HADOOP 변경함 ㅠ
