Leveraging Hidden Positives for Unsupervised Semantic Segmentation (CVPR, 2023)
0
(0502 Seminar Previous Works)
Previous Works
- 기존 연구에서 사용한 Backbone Network인 DINO는 Segmentation Task를 위한 모델(Task-specific)이 아니라,
휴먼 비전 기반의 일반적인 시각적 유사도를 학습하도록 설계(Task-agnostic)된 Self-supervised learning 모델임 - 본 논문은 질감, 색, 형태 등 시각적 유사성을 기준으로 물체를 분할하는 기존 DINO의 한계를 극복하기 위해,
세부적인 표현능력(ex 경계 표현)의 성능을 높이는 작업을 수행함
Main Contribution
- 본 논문은 Unsupervised Semantic Segmentation을 위해 Contrastive learning 베이스의 Hidden Positives라는 개념을 도입함
- Hidden Positives: 의미적으로 비슷한 배치들을 양성 쌍으로 간주하여 Contrastive Learning에 활용하는 개념
(의미적으로 비슷하다: Anchor Patch를 기반으로 Attention Score가 평균 이상으로 넘어간다)- GHP (Task-Specific Global Hidden Positives): DINO처럼 일반적인 백본이 아닌, 현재 Segmentation task를 학습 중인 Segmentation head의 feature를 기준으로 의미적으로 유사한 패치 쌍을 새롭게 정의하여 Contrastive learning에 활용함
(Segmentation task: 이미지를 픽셀 단위로 나눠서 각 픽셀이 어떤 클래스에 속하는지 분류하는 문제)
(Segmentation head: Task 수행을 위해 Backbone이 아닌 feature를 받아 최종적으로 클래스 분류 결과를 출력하는 모델의 마지막 층) - LHP (Local Hidden Positives): 같은 이미지 안에서, Anchor 주변에 위치한 패치들 중 의미적으로 유사한 것들을 positive로 간주하고 해당 방향으로 loss gradient를 전파함
(Loss gradient를 전파한다: 해당 픽셀의 예측이 틀렸을 대, 주변 패치도 비슷한 방식으로 수정되도록 역전파 과정에서 유도하는 것)
- GHP (Task-Specific Global Hidden Positives): DINO처럼 일반적인 백본이 아닌, 현재 Segmentation task를 학습 중인 Segmentation head의 feature를 기준으로 의미적으로 유사한 패치 쌍을 새롭게 정의하여 Contrastive learning에 활용함
GHP
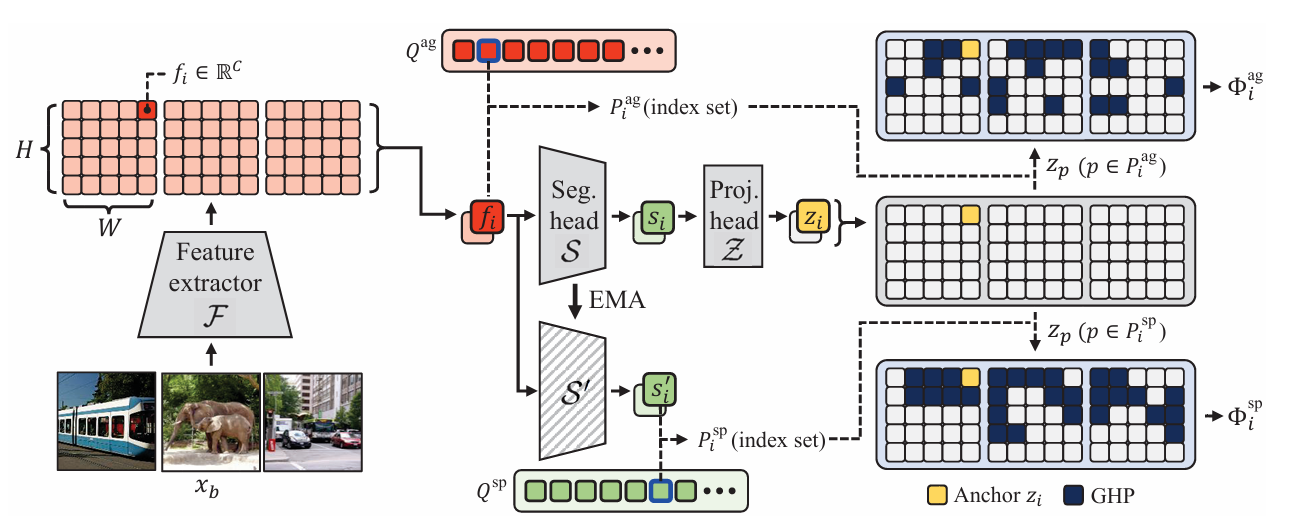
- Input으로 이미지를 받고 feature map 생성함
- 한 배치 안에서 Anchor patch 하나를 정함
- Task-Agnostic GHP, Task-Specific GHP 두 GHP를 선택함
- Segmentation Head 및 Projection Head를 통과해 feature vector z_p로 변환됨
- Contrastive loss를 계산해 Anchor와 GHP의 유사도를 최대화하고, GHP 아닌 나머지는 negative로 사용함
- 여기서 초기 학습을 위해 처음엔 Task-Agnostic GHP의 비중을 높게 두고, Segmentation head에서 나온 feature를 기반으로 Task-Specific GHP로 비중을 바꿔가는 방식을 사용함
LHP
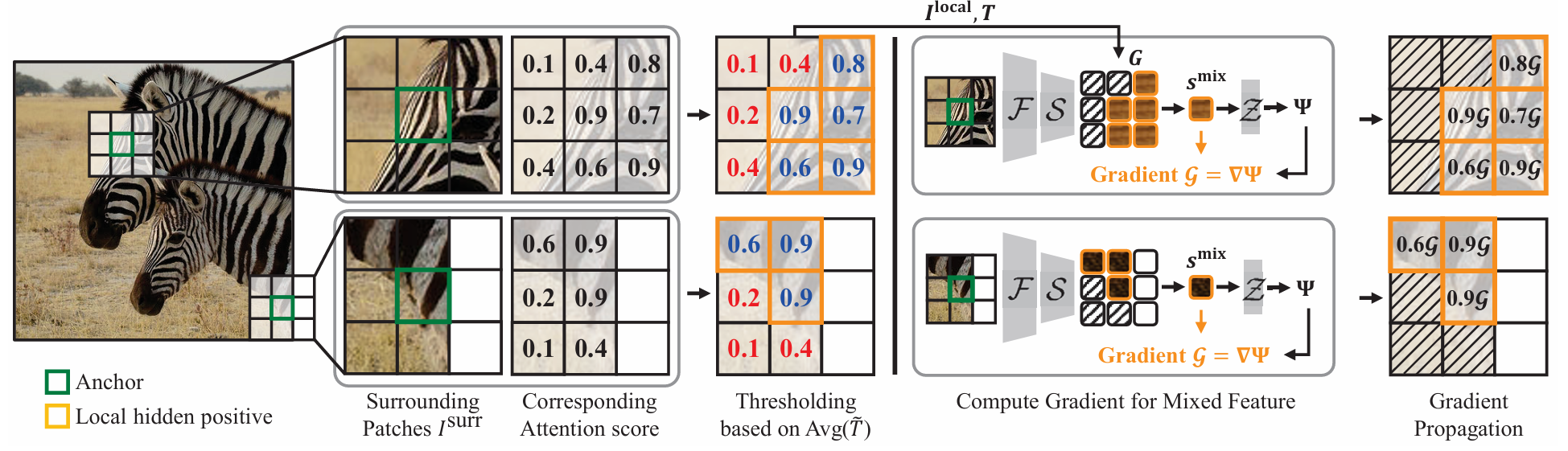
- Input으로 이미지를 받음
- 초록색인 Anchor patch를 정하고, 그 주변 8개 이웃 패치를 회색인 Surrounding patches로 정함
- Anchor patch를 기준으로 주변 패치들에 대한 Attention Score를 계산함
- 그리고 Thresholding 작업을 통해 Zebra 패턴이 있는 patch들을 Local Hidden Positives로 분류하는 작업을 진행함
- LHP의 Feature를 Attention Score 기준으로 가중 평균을 구함
- 위에서 나온 결과물인 혼합된 Feature를 가지고 projection 진행 후 Contrastive loss에 넣음
- 계산된 Loss의 Gradient를 Attention Score 비율에 따라 각각의 LHP에 전파
- Attention Score가 0.9인 패치 → Gradient의 0.9배 전파
- Attention Score가 0.6인 패치 → 0.6배 전파
- 기존 논문(STEGO)에서 위와 같은 local Semantic Consistency를 배제함. 이는 인접 픽셀이 같은 객체일 가능성을 배제했다는 한계점이 존재

💻귀찮으니 필요할 때만 쓰는 Computer Vision 일지 ㅇㅇ💻