WHERE 조건
- ~이상
나이가 30이상인 회원을 조회한다.

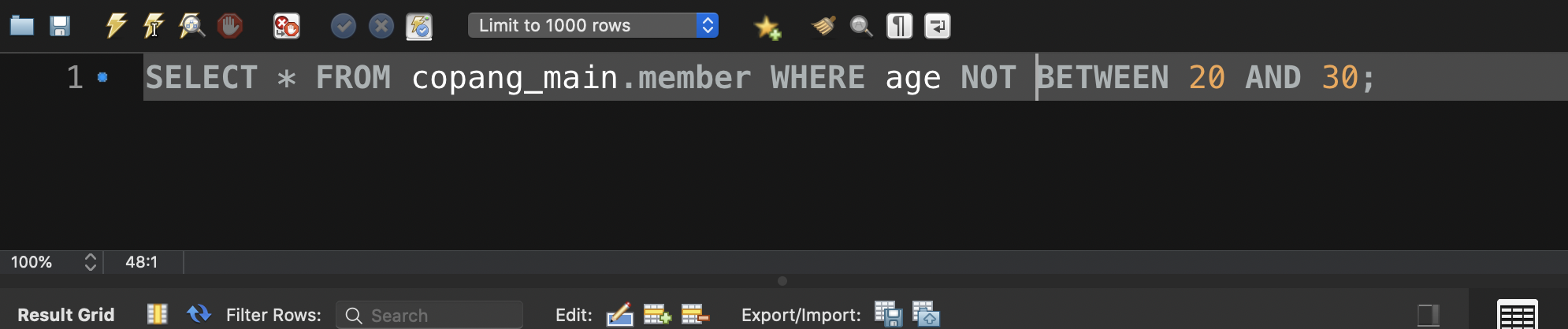
2.~에서 ~사이

NOT을 붙이면 20대가 아닌 회원이 조회된다.
- 날짜형식(DATE)일때도 동일하게 적용이 가능하다.


문자열 패턴 매칭
- LIKE
문자열의 첫 부분이 '서울'이라는 단어로 시작하고
그 뒤에 임의의 길이를 가진 문자열이 있는 모든 문자열을 나타낸다.

서울을 앞뒤로 임의의 길이를 가진 문자열들이 있는 문자열을 나타낸다.

- 같지 않음 (!=, <>)


- 이중에 있는
age IN (10, 20, 30)
나이가 10 이거나, 20 이거나, 30 인 데이터를 조회한다.

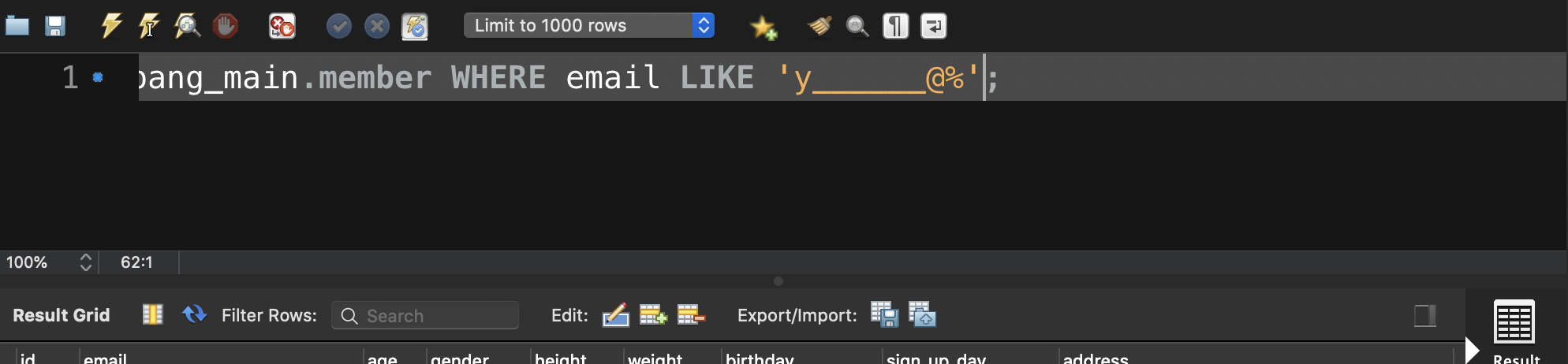
- 글자 수(_)
y라는 글자 뒤에 길이가 6개인 임의의 문자열이 있고, 골뱅이를 포함한다.
그 뒤로 임의의 길이의 문자를 가진 row를 검색한다.
- 이스케이핑(escaping) 문제
%(퍼센트), '(따옴표), _(언더바), "(큰따옴표), 대소문자 구별 과 같은 문자들은 일반적인 문자임과 동시에 표현식이기 때문에 올바르게 해석되지 못할 수 있다.
LIKE '%\%%'
LIKE '%\'%'
LIKE '%_%'
LIKE '%\"%'
와 같이 (역슬래쉬)로 구별해준다.
대소문자 구분
테이블 컬렉션을 살펴보면 아래와 같은 문구가 뜬다. ci의 의미는 문자열이 동일한지 확인할 때 대소문자를 구별하지 않겠다는 뜻이다. 바로 이 설정때문에 알파벳만 같으면 같다고 판단이 되어버린 것이다.

LIKE BINARY '%g%'
BINARY 란 이진의,0과 1로 된이라는 뜻을 가진다.
소문자 g와 대문자 g는 컴퓨터에 0과 1로 저장될 때 다른 값으로 저장이 된다.
BINARY는 알파벳 비교가 아니라 대소문자 구분이 가능하도록 문자열 비교를 하라는 뜻이 된다.
