
웹 브라우저
📢 이번 기회에 한 번쯤은 내가 작업하는 환경 즉, 웹 브라우저가 뒤에서 어떻게 동작하고 있는지 훑어보면서 이해도를 높여보려 합니다. 너무나 방대한 주제이므로 각 단계마다 핵심 내용만 짚고 넘어갑니다.
웹 브라우저에 웹 페이지가 표시되기까지
주소창에 주소를 치면 웹 브라우저는 다음 단계에 따라 요청받은 웹 페이지를 보여준다.
- 네비게이션
가장 먼저 내가 요청한 웹 페이지가 실제로 위치한 곳을 찾는다. 이때 DNS의 도움을 받는다. - HTTP 요청/응답
주소를 찾았으니 이제 웹 페이지의 리소스를 가져올 수 있다. HTTP 프로토콜에 따라 전송된다. - 파싱
응답받은 리소스를 구문 분석해서 브라우저가 이해할 수 있는 DOM, CSSOM으로 변환시킨다. - 렌더링
파싱과 함께 렌더링이 진행된다. 렌더 트리를 이용해서 문서의 시각적인 구조를 만든다. - 디스플레이
와우! 드디어 브라우저에 웹 페이지가 보인다.
웹 브라우저의 구조
각 단계를 더 설명하기 전에 브라우저의 구성 요소를 살펴보고 넘어가자.
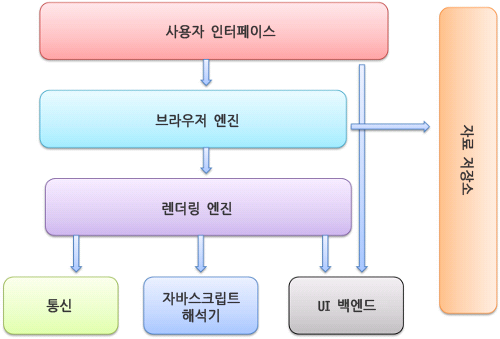
사용자 인터페이스: 주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등 웹 페이지를 보여주는 창을 제외한 나머지 모든 부분이다.브라우저 엔진: 사용자 인터페이스와 렌더링 엔진 사이에 동작을 제어한다.렌더링 엔진: 요청한 콘텐츠를 표시한다. 예를 들어 HTML을 요청하면 HTML과 CSS를 파싱하여 화면에 표시한다.통신: HTTP 요청 같은 네트워크 호출에 사용된다. 플랫폼 독립적인 인터페이스이고 각 플랫폼의 하부에서 실행된다.UI 백엔드: 콤보 박스나 창 같은 기본 장치를 그린다. 플랫폼에 명시하지 않은 일반적인 인터페이스로서 OS 사용자 인터페이스 체계를 사용한다.자바스크립트 해석기: 자바스크립트 코드를 해석하고 실행한다.자료 저장소: 자료를 저장하는 계층이다. 쿠키 등 모든 종류의 자원을 하드 디스크에 저장한다. HTML5 명세에 웹 데이터 베이스가 정의되어 있다.
네비게이션
DNS
내가 요청한 웹 페이지의 실제 위치를 찾으려면 어떻게 해야 할까? 주소창에 입력한 주소는 기억하기 쉬운 도메인 이름(예: www.google.com)으로 이를 고유한 IP 주소(예: IPv6의 경우 2400:cb00:2048:1::c629:d7a2)로 바꿔줘야 하는데 이때 DNS(Domain Name System)가 필요하다.
DNS는 도메인 이름과 IP 주소 사이의 매핑을 관리하는 시스템으로 웹 브라우저가 DNS에 도메인 이름을 넘기면 매핑된 IP 주소를 반환해준다.
TCP 3-way Handshake
이제 주소를 알게 되었으니 리소스를 요청하고 싶다. 그런데 이 리소스를 안정적으로 받기 위해서는 연결을 성립(establish)해야 한다. 이를 위해 필요한 것이 TCP 3-way handshake다.
TCP 3-way handshake는 서버와 클라이언트 사이에 데이터를 송수신할 준비가 되어 있다는 것을 보장하기 위해 필요한 과정이다.
SYN: Web Brower -> Web Server
SYN-ACK: Web Brower <- Web Server
ACK: Web Brower -> Web ServerTLS Negotiation
연결이 성립되었지만 보안되어 있지 않다면 무슨 소용일까? 따라서 통신을 암호화하기 위해서는 추가로 TLS handshake가 필요하다.
TLS(Transport Layer Security)란 데이터를 보호하기 위해 설계된 보안 프로토콜로 TLS handshake 과정이 끝나면 신뢰할 수 있는 서버임이 증명된다. 그러면 보안에 취약한 HTTP가 아닌 HTTPS(HTTP+TLS)를 통해 데이터를 주고받을 수 있게 된다.
HTTP 요청/응답
HTTP Request
암호화된 데이터 통신을 진행할 수 있게 되었으니 리소스를 가져와야할 차례다. HTTP 메서드 GET를 사용하면 된다.
프로토콜에 따라 GET과 URI(Uniform Resource Identifier)를 사용해서 서버에 리소스를 요청한다.
curl -X GET -v https://wecode.co.kr/
# GET이 기본 메서드이므로 -X GET 옵션을 설정할 필요가 없다.
# 여기에서는 어떤 메서드인지 명확하게 보여주기 위해 사용했다.
* Connection state changed (HTTP/2 confirmed)
* Copying HTTP/2 data in stream buffer to connection buffer after upgrade: len=0
* Using Stream ID: 1 (easy handle 0x7ffff12867c0)
> GET / HTTP/2
> Host: wecode.co.kr
> user-agent: curl/7.68.0
> accept: */*HTTP Response
내가 한 요청이 유효하다면 웹 서버에서 리소스를 응답해준다. 마침내 웹 페이지의 HTML을 얻게 되었다.
* Connection state changed (MAX_CONCURRENT_STREAMS == 128)!
< HTTP/2 200
< date: Sat, 14 Aug 2021 06:11:39 GMT
< content-type: text/html; charset=UTF-8
< content-length: 9063
< x-powered-by: Express
< accept-ranges: bytes
< cache-control: public, max-age=0
< last-modified: Tue, 03 Aug 2021 06:09:14 GMT
< etag: W/"2367-17b0aa163bf"
<
<!doctype html><html lang="en"><head><meta charset="utf-8"/><link rel="shortcut icon" href="/favicon.ico"/><meta name="viewport" content="width=device-width,initial-scale=1,shrink-to-fit=no"/><meta name="theme-color" content="#000000"/><meta property="og:url" content="https://wecode.co.kr/"/><meta property="og:type" content="website"/><meta property="og:title" content="WeCode | 위코드 | 코딩 부트캠프 | 코딩교육 | 온라인 부트캠프"/><meta property="og:description" content="wecode(위코드)의 부트캠프를 통해 개발자로서 커리어를 시작하세요."/>
...파싱
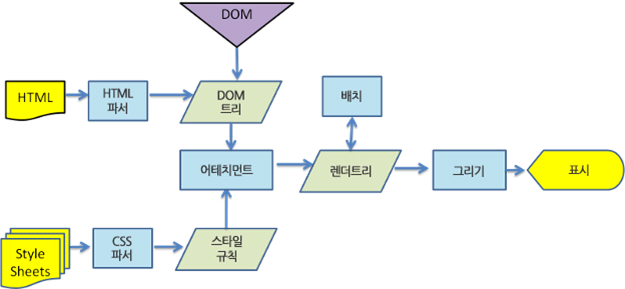
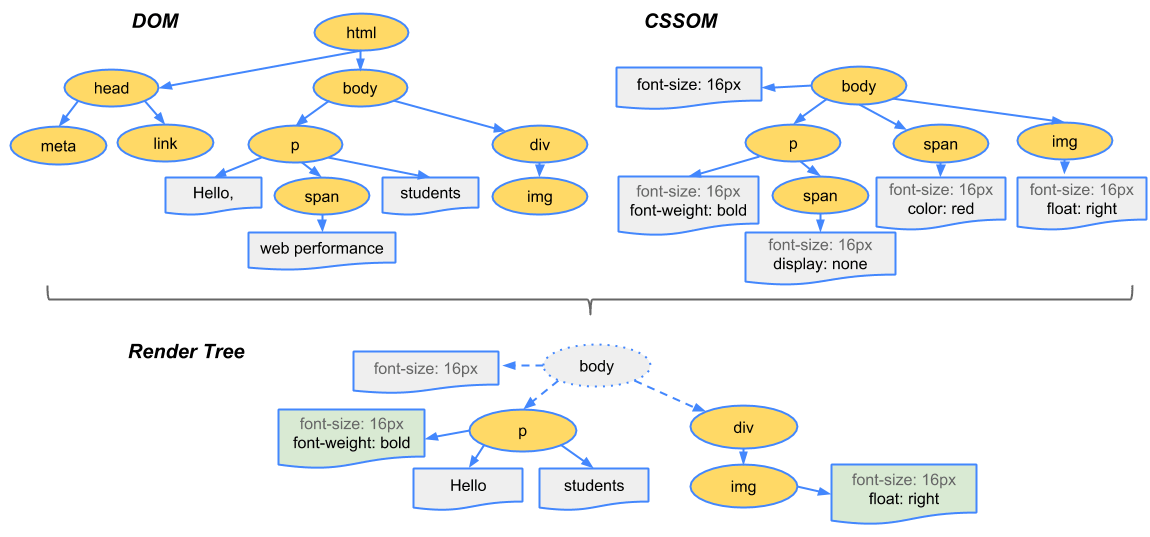
웹 브라우저가 응답을 수신했으므로 이를 이해하고 사용할 수 있도록 구문 분석을 시작해야 한다. HTML 문서를 분석하기 위해 파서를 이용하고 그 결과 파싱 트리(parse tree)가 만들어진다.
아래 이미지는 웹킷 동작 과정의 예시이다. 파서를 눈여겨 보자.
DOM Tree
먼저 HTML 마크업을 태그, 속성을 기준으로 토큰화한 다음 DOM tree를 구축한다. DOM(Document Object Model)은 문서 내 서로 다른 태그 사이의 관계 및 계층 구조를 노드와 객체로 표현한다.
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<link href="style.css" rel="stylesheet" />
<title>Critical Path</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg" /></div>
</body>
</html>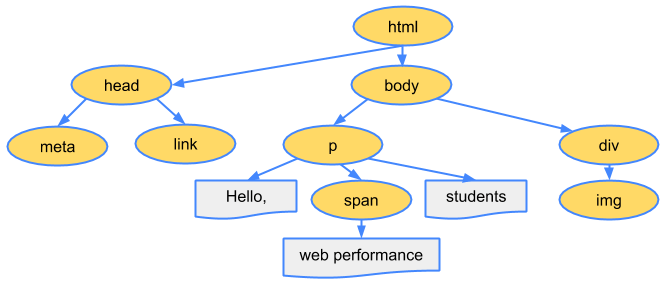
CSSOM Tree
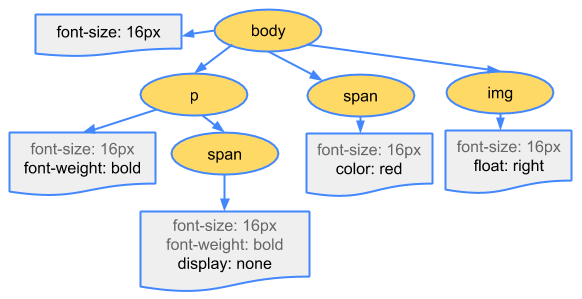
CSS도 선택자, 선언 등을 토큰화해서 CSSOM tree를 구축한다. CSSOM(CSS Object Model)은 문서 내용이 보여지는 스타일을 표현한다.
body {
font-size: 16px;
}
p {
font-weight: bold;
}
span {
color: red;
}
p span {
display: none;
}
img {
float: right;
}
Render tree
DOM tree와 CSSOM tree를 Render tree에 결합하여 렌더링을 준비한다. 웹 페이지에 표시될 DOM 콘텐츠와 CSSOM 스타일이 모두 포함된다.
렌더링
구축된 Render tree를 사용해서 HTML, CSS, JavaScript가 사용자와 상호작용하는 웹 페이지로 변환된다.
아래 이미지에서 렌더 트리를 배치하고 그리는 과정에 집중하자.
Layout
Render tree가 뷰포트 내에 표현되기 위해서는 정확한 위치와 크기를 계산해야 하는데 이 과정이 바로 Layout이다. 트리의 루트에서 시작해서 트리를 순회하며 계산한다.
아래 코드를 살펴보면 뷰포트의 너비가 100%일 때 첫 번째 div는 뷰포트 너비의 50%로 계산된다. 마찬가지로 두 번째 div는 상위 노드인 첫 번째 div 너비의 50%로 계산된다.
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<title>Critial Path: Hello world!</title>
</head>
<body>
<div style="width: 50%">
<div style="width: 50%">Hello world!</div>
</div>
</body>
</html>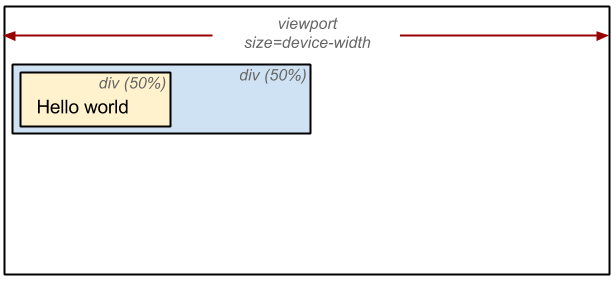
뷰포트가 달라질 경우 상대적인 단위들(%, vh, vw 등)을 재계산해야 하는데 이 때문에 Reflow라고도 부른다.
Paint
렌더링의 마지막 단계로서 계산된 위치와 크기를 화면에 실제 픽셀로 변환한다. 이 단계의 이름이 Paint인 이유가 있는데 고려해야 할 중요한 정보가 또 있기 때문이다.
실제 그림을 그린다고 가정해보자. 먼저 뒤에 있는 배경을 그린 다음 그 앞에 사물들을 그리지 않을까? 웹 브라우저도 화면에 정보를 그리기 위해 어떤 순서로 그려야 할지 목록을 작성한다.
만약 순서를 고려하지 않는다면 무슨 일이 일어날까? 예를 들어, z-index 속성을 고려하지 않고 루트 트리부터 차례로 화면에 나타낸다면 앞에 나와야 할 정보가 다른 박스에 가려져 보이지 않게 될 수 있다.
HTML, CSS 속성에 따라 위와 같은 문제들이 발생할 수 있는데 이를 위해 레이어를 사용한다. 최종적으로는 여러 레이어들을 겹쳐서 합성(Compositing)한 하나의 화면이 그려진다.
Display
마침내 사용자가 웹 페이지를 보고 상호작용할 수 있다.
실제 웹 사이트에 접속하면 페이지가 보일 때까지 1초도 안 걸리지만 사실은 이렇게 복잡한 과정이 뒤에서 진행되고 있다!
