CoreDNS를 사용하며 겪은 문제들과 이를 해결하기 위한 Actions
Trouble
-
급변하는 트래픽 환경에서 CoreDNS의 부하 발생으로 인해 네트워크 문제 및 Latancy 급증하는 문제 발생하여 HPA에 의해 파드가 증가하면서 데이터베이스 커넥션 급증 등 전체 서비스에 영향이 전파됨
-
요청이 발생하면 동작하는 Task성 파드들이 유연함을 가진 노드형태를 띄고 있어서 적은 CoreDNS의 개수가 이를 커버하지 못해 간헐적으로 네트워크가 끊겨 파드가 정상 동작하지 못하는 문제
Actions?
Pods당 요구되는 리소스양이 존재하여 CoreDNS가 감당할 수 있는 수준에 따라 Avg Latency, QPS(Query per seconds)가 차이날 수 있음
이와 관련해 고가용성과 리소스 활용도가 중요한 경우 CoreDNS 구성을 조정하는 것이 유용할 수 있음
-
CPA(Cluster Propotional Autoscaler)
- 클러스터의 전체 크기를 고려하여 CPA를 설정
- 사용중인 인스턴스 타입을 파악하고 가장 적절한 nodesPerReplica와 coresPerReplica를 설정
- 지속적인 모니터링을 통해 replica의 min, max 수치를 조정하고 perReplica를 최적화
-
Advanced Configuration - TopologySpreadConstraints
-
토폴로지 확산 제약 조건을 사용하여 가용성 영역, 노드 및 기타 사용자 정의 토폴로지 도메인과 같은 장애 도메인 사이에서 Amazon EKS 클러스터 전체에 Pod가 분산되는 방식을 제어
-
이는 고가용성과 효율적인 리소스 활용을 달성하는 데 도움이 될 수 있음
-
또한 토폴로지 조건을 설정하여 Karpenter의 Scale에 영향을 끼치지 않도록 함
- 이 설정을 통해 Consolidation, Drift 등 CoreDNS의 영향 없이 Deprovisioning 과정을 수행할 수 있음
- coredns를 최대한 많이 분산시키면서 적절한 노드에서의 분배가 필요함
- 노드가 드레인 되었을 때 많은 수의 coredns가 종료되어야 한다면 서비스에 영향을 미칠 수 있음
- coredns의 스케줄링 동작을 anti-afinity가 아닌 topologySpread를 설정하여 통합되게 하라는 Karpenter의 제안사항이 있음
- kube-scheduler에 의해 동작하지 않는 karpenter, soft contraints(
ScheduleAnyway)로 설정하여 제한을 완화하여 Karpenter에서 컨트롤 할 수 있도록 함v1.9.3-eksbuild.11및v1.10.1-eksbuild.7이상부터 topologySpreadConstraints 설정이 기본값으로 추가됨
-
-
Alert Conditions
- CoreDNS Error Rate, Panics, Request Duration, Request Rate의 Thresholds를 설정하여 즉각 대응 가능한 구조를 구성
- NewRelic 사용 시 Prometheus Agent를 설정하여 kube-dns를 integration하고 Agent 상태 대시보드를 구성
-
NodeLocal DNSCache 적용
- 1~3 항목을 적용하여 운영하던 도중 추가 문제점들을 발견하였다.
최대한 안정적으로 운영하려다 보니, 과도하게 CoreDNS Replicas를 늘려 사용하였는데 모든 노드가 오염이 적용되어 있어 Deployment인 CoreDNS가 특정 노드(ex. default)에만 파드가 생성되었고, topologySpreadConstraints maxSkew:1을 유지하려 하는데 노드당 CoreDNS의 파드가 3~4개까지 생성되는 상태가 발생하면서 노드가 Consolidation(스케일링)되지 못하는 문제가 발생
1. 해당 문제를 해결하기 위해 메인 CoreDNS의 부하를 낮출 수 있는 전략을 선택하고자 함- NodeLocal DNSCache add-on을 사용하면 각 노드에서 실행되도록 새로운 CoreDNS DaemonSet을 구성할 수 있게 되고, 이러한 새로운 CoreDNS 파드는 DNS Cache 역할을 수행 함
- 특정 노드의 모든 파드는 요청을 Local CoreDNS 파드로 전송하고 이 파드가 캐시에서 결과를 제공하거나 요청을 upstream의 메인 CoreDNS 파드로 전달함
- 이러한 구조는 DNS Query의 양이 대폭 줄어들고 스파이크 처리가 쉬워지며 DNS Cache에 대한 AWS 권장 사항을 따르게 된다.
- 또한 문제가 발생 시 메인 CoreDNS가 영향을 받지 않아 전체 서비스 문제로 번지지 않고 노드 하나의 문제로 줄어들게 되어 보다 안정적인 운영이 가능하다.
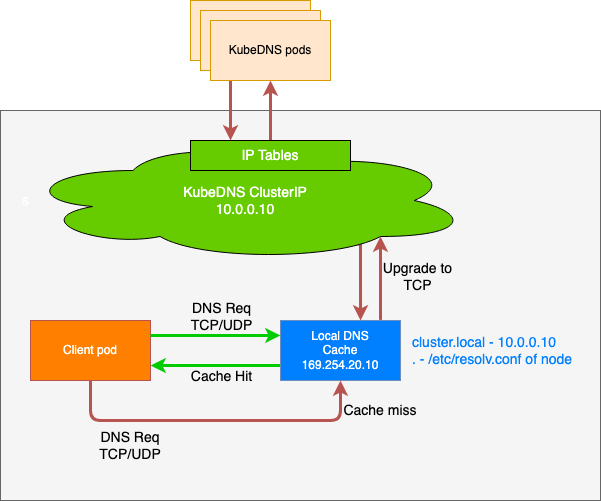
- 아키텍처를 보면서 동작에 대한 이해를 얻고 적용하기
- 이러한 구조는 DNS Query의 양이 대폭 줄어들고 스파이크 처리가 쉬워지며 DNS Cache에 대한 AWS 권장 사항을 따르게 된다.
- 1~3 항목을 적용하여 운영하던 도중 추가 문제점들을 발견하였다.
적용 이후 실제 운영 환경에서 지표가 대폭 개선된 것을 확인할 수 있었고 Consolidation 되지 못해 노드가 과확장되던 문제를 해결하게 되었다.
결론적으로 CPA와 NodeLocal DNSCache 둘 모두를 적용하여 CoreDNS의 부하 문제를 converge to zero 하였다고 본다.
https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/ 문서를 참고하여 적용
