Saga Pattern

앞선 포스팅에서 MSA 아키텍쳐에 대해 소개했다.
MSA 아키텍쳐는 각 서비스 별로 별도의 DB를 가지고 있고, 서로 구조적으로 독립적인 형태를 띄는데 어떻게 데이터가 관리 되는지 궁금해졌다.
그래서 오늘은 MSA에서 데이터를 관리하는 방법 중 하나인 Saga 패턴에 대해 알아보고자 한다.
필요성
MSA에서는 아래 그림처럼, 각 서비스가 독립적으로 존재한다.
논리적으로 독립적이라기보다는 구조적을 독립적이라는 뜻이다.
모든 서비스가 독립적은 DB를 가질 필요는 없지만, 많은 경우 각자 관리하는 DB를 가지게 된다.
그렇기 때문에, DB들이 여러개 생기게 되지만, 각 DB는 서로 정보를 공유해야할 필요가 있을 때가 있다.
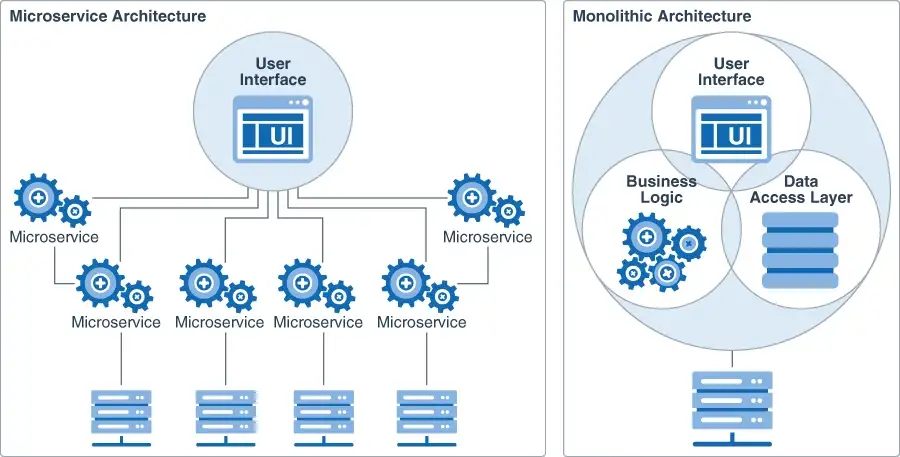
이렇게 전혀 다른 DB 간에 데이터를 주고 받고 join을 처리하고 싶다면 어떻게 해야할까.
당연히 단순한 방법으로는 서로 전혀 다른 DB간의 테이블을 join처리 할 수 없다.
이렇기 때문에 여러가지 방법이 나오게 된다.
매번 다른 서비스에서 message queue를 통해 통신해 정보를 받아 올 수도 있고,
혹은 master slave 형식을 확장해서 다른 서비스에서 참조해서 사용할 수도 있다.
이 중에 가장 마음에 들었던 Saga 방식에 대해 소개하려고 한다.
Saga
어원
Saga는 어떤 말의 약자일까하고 찾아봤지만, Saga는 사실 약자가 아니였다.
Saga는 우리가 평소에 사용하는, 서사시, 전설등을 뜻하는 그 사가에서 나온 이름이다. (그랑사가 할때 그 사가)
이야기가 전해지는 방식처럼 하나씩 타고 내려간다는 의미가 있고,
또한 길고 자세한 이야기와 같은 특징을 가진다는 의미가 포함된 내용이었다.
A LLT is a saga if it can be written as a sequence of transactions that can be interleaved with other transactions.
a long, detailed story of connected events
소개
Saga방식은 서로 다른 DB에서 동일한 데이터를 가져야 하는 경우에 사용하는 방식이다.
예를 들어, 많은 서비스에서 유저 정보는 다양한 서비스가 서로 공유하고 동일하게 가지고 있어야 한다.
그리고 이 데이터는 한 곳에서 바뀌면 다른 곳에서도 동일하게 바꿔야한다.
한 마디로 늘 싱크가 맞는 상태로 존재해야하는 것이다.
이런 경우에 Saga 방식을 사용해서 서로 다른 DB에서도 동일한 값을 유지할 수 있다.
그리고 이를 통해서 서비스 간에 독립적이지만 논리적으로 연결된 작업을 수행할 수 있다.
동작 방식
Saga에서는 DB 트렌젝션을 앱 레벨에서 관리한다.
트렌젝션의 완료를 앱에서 결정하고, 잘못 된 경우 원복한느 방식이다.
아래 그림은 이를 자세히 설명해주는 예시다.
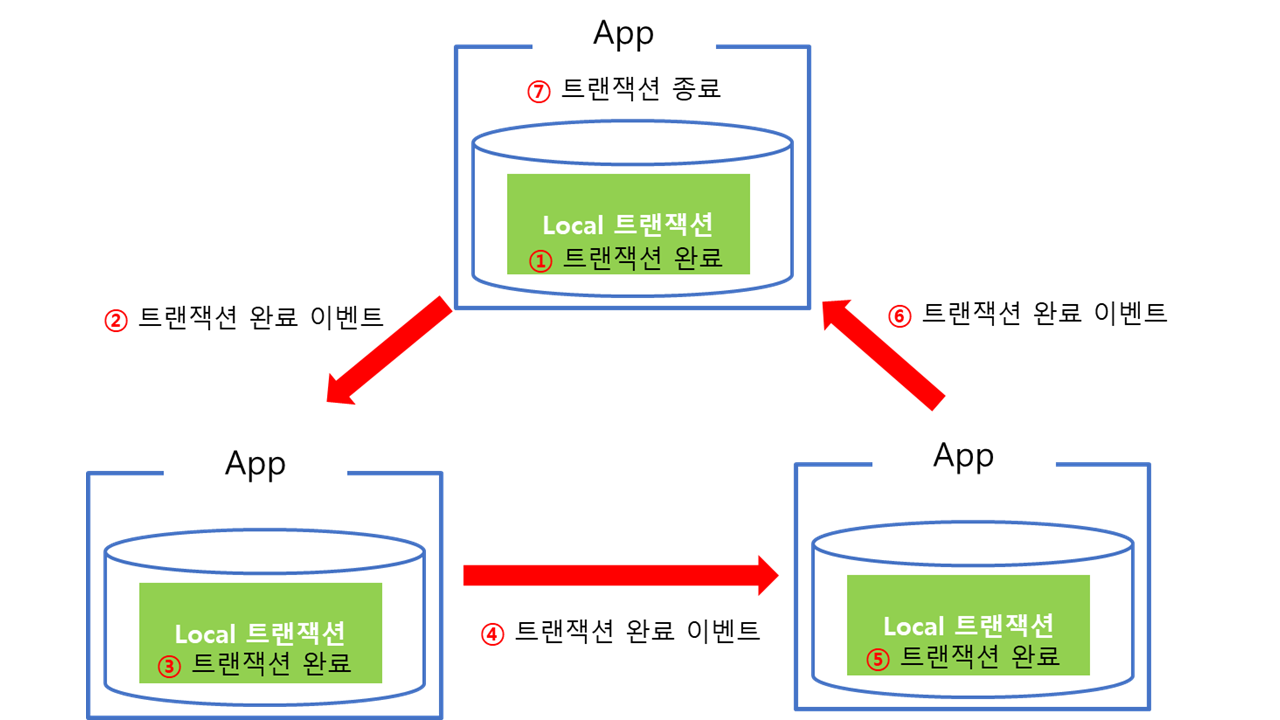
그림에서 볼 수 있듯이, 3개의 어플리케이션이 있고, 각 어플리케이션 DB가 있다고 해보자.
이때 각 DB에 내용이 서로 공유 되어야 한다.
그러면 먼저 제일 먼저 첫 번째 DB에 정보를 담는다. 이후에 다음 어플리케이션과 통신에 정보를 넘겨주고 해당 DB에도 정보를 저장한다.
이렇게 모든 연관된 DB에 정보가 잘 저장됐다면, 트랜젝션을 마무리한다.
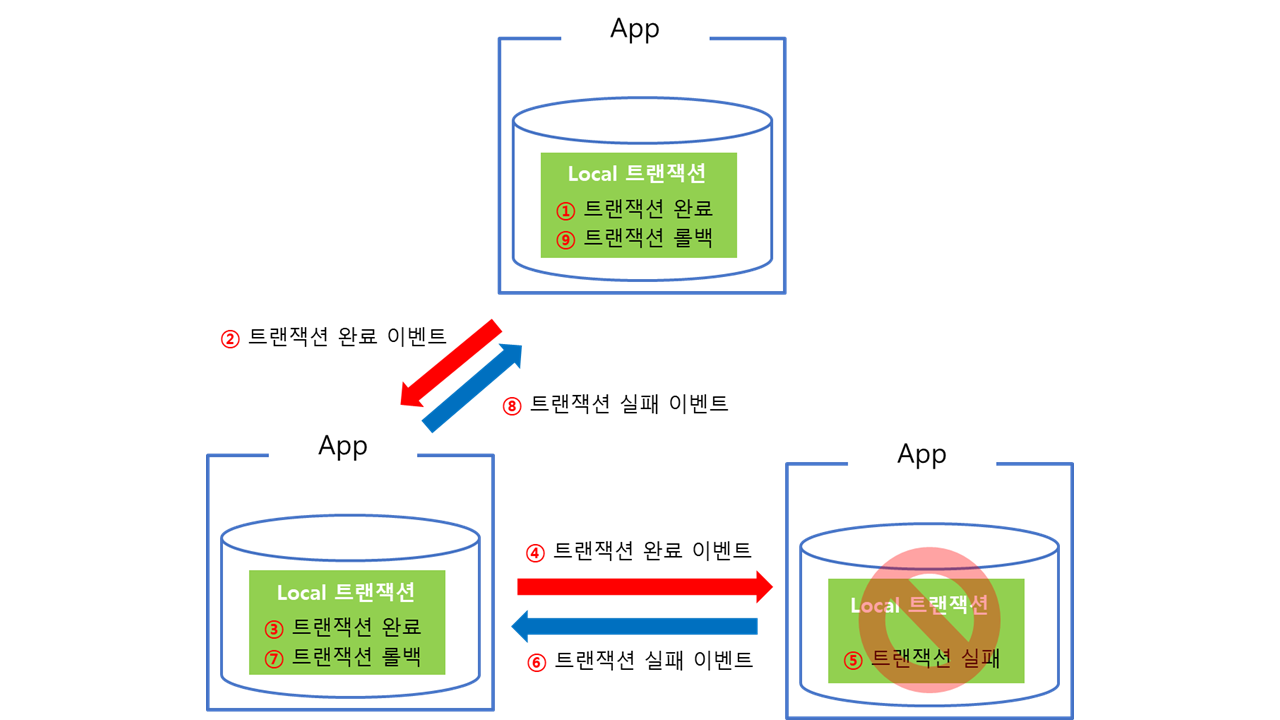
하지만, 도중에 한곳에서라도 저장이 실패한다면 저장한 트랜젝션을 롤백해서 다시 모두 동일한 상태를 유지하도록 하는 방식이다.
참고 출처
https://www.samsungsds.com/kr/insights/mas_data.html
https://www.cs.cornell.edu/andru/cs711/2002fa/reading/sagas.pdf
https://azderica.github.io/01-architecture-msa/
