3.4 인덱스 설계
3.4.1 인덱스 설계가 어려운 이유
- 인덱스가 많으면 문제가 발생한다
- DML 성능 저하(->TPS 저하)
- 데이터베이스 사이즈 증가(-> 디스크 공간 낭비)
- 데이터베이스 관리 및 운영 비용 증가
- 데이터 입력시 모든 인덱스에 데이터를 입력해야 하고, 수직적 탐색으로 블록을 찾고 블록 공간 여유가 없으면 인덱스 분할도 발생한다
- 데이터 지울때도 모든 인덱스의 레코드를 일일이 찾아야 한다.
운영 환경에서는 인덱스 변경이 쉽지 않다. 따라서 시스템 개발 단계에서 인덱스를 최적으로 설계하는 것이 매우 중요하다
3.4.2 가장 중요한 두가지 선택 기준
- 인덱스 선두 컬럼을 조건절에 반드시 사용하여 Index Range Scan 을 해야 한다.
- 결합 인덱스를 구성할 때 2가지 기준이 있다
- 조건절에 항상 사용하거나, 자주 사용하는 컬럼을 선정한다
- '=' 조건으로 자주 조회하는 컬럼을 앞쪽에 둔다.
3.4.3 스캔 효율성 이외의 판단 기준
-
위 2조건이 가장 중요하지만 그렇게 간단하게 뚝딱이 안된다. 고려해야한 부분이 많다
- 수행빈도
- 업무상 중요도
- 클러스터링 팩터
- 데이터량
- DML 부하(=기존 인덱스 개수, 초당 DML 발생량, 자주 갱신하는 컬럼 포함 여부 등)
- 저장 공간
- 인덱스 관리 비용 등
-
다양한 판단 기준에 의해 설계자의 성향과 스타일에 따라 결과물이 달라진다.
-
이중 가장 중요한 하나는 수행빈도 라고 저자는 말한다.
-
자주 수행하지 않는 SQL 은 인덱스 스캔 과정에 비효율이 있어도 큰 문제가 아닐 수 있다
-
하지만 수행빈도가 높은 SQL 에는 최적의 인덱스를 구성해야 한다.
-
NL 의 경우 Outer 는 1번만 그치므로 스캔 과정의 비효율을 감수 할 수 있지만 Inner 의 경우 반복적인 작업이 진행되므로 비효율이 있으면 큰 문제가 야기될 수 있다.
-
따라서 수행빈도가 높은 Inner 에서 인덱스는 '=' 조건 컬럼을 선두에 두는 것이 중요하고, 가능하면 테이블 액세스 없이 인덱스에서 필터링을 마치도록 구성해야 한다.
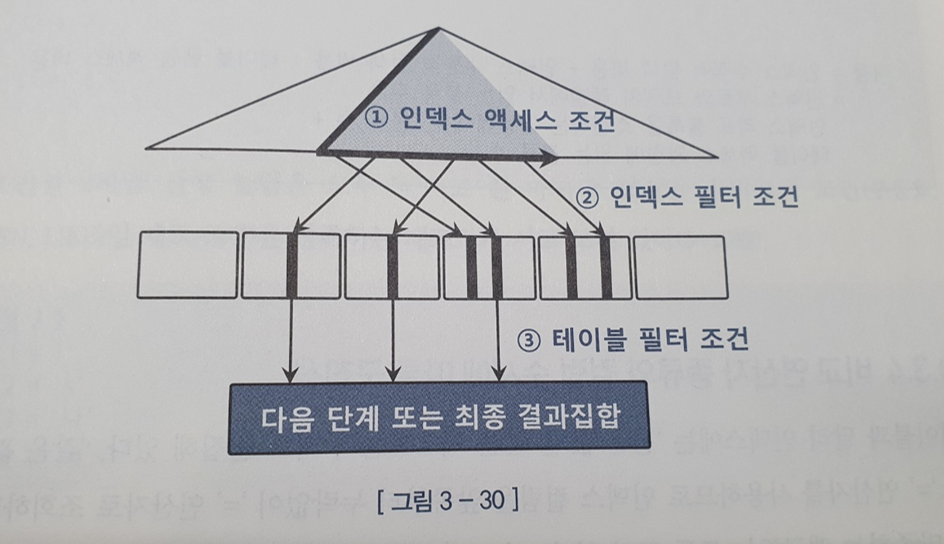
-
데이터 량도 중요하다
-
데이터 량이 많으면 insert 도 많아진다. 이런경우 인덱스 를 하나라도 줄이는 것이 시스템에 큰 영향을 미친다.
3.3.4 공식을 초월한 전략적 설계
- 모든 패턴마다 인덱스를 만들 수는 없다
- 핵심적인 액세스 경로 한 두개를 전략적으로 선택하여 최적 인덱스를 설계하고, 나머지 액세스 경로는 약간의 비효율이 있더라도 목표 성능을 만족하는 수준으로 인덱스를 구성할 수 있어야 한다.
- 이에 대한 선택과 전략적 판단 근거도 가지고 있어야 한다.
보험사 가계약 전략
- 인덱스 스캔 효율을 위해
=조건 컬럼을 앞에 두고 BETWEEN 조건 컬럼을 뒤에 두면 조회 방식에 모두 index 를 만들어야 한다. - 일자/일시 조건을 선두에 두고, 자주 사용하는 필터 조건을 모두 뒤쪽에 추가하는 방식은 어떨까?
- 두가지 핵심 포인트로 설계를 하였다.
- 일자 조회구간이 길지 않으면 인덱스 스캔 비효율이 성능에 미치는 영향이 크지 않다.
- 인덱스 스캔 효율보다 테이블 액세스가 더 큰 부하요소이다
- 대부분의 가계약은 3일 이내 데이터를 조회한다.가끔 3일을 초과하거나 한달치를 조회할 수 있지만 많지 않고, 불필요한 테이블 액세스를 발생하지 않게 하였으므로 인내할 수 있는 성능일 것이다.
- BETWEEN 조건 컬럼을 선두에 두는 것은 찝찝할 수 있다. 하지만 가계약 테이블을 다양한 패턴으로 조회하지만, 가장 많이 쓰이는(85% 이상) 패턴은 입력자
=, 데이터생성일시 BETWEEN 조건이기 때문에 상황에 맞게 설정한다. - 이런식으로 인덱스 개수를 최소화하여, 사용빈도가 높거나 중요한 액세스 경로가 새로 도출될 때 최적의 인덱스를 추가할 여유가 생긴다
3.4.5 소트 연산을 생략하기 위한 컬럼 추가
- 인덱스는 정렬을 보장하므로 ORDER BY, GROUP BY 를 위한 소트 연산을 생략한다.
=조건절 컬럼은 ORDER BY 절에 없더라도 인덱스 구성에 포함할 수 있다.(앞 뒤 어디에 두어도 상관없다)- 하지만
=이 아닌 조건절 컬럼들은 반드시 ORDER BY 컬럼 보다 뒤쪽에 두어야 한다! - 또한 ORDER BY 조건과 성능을 모두 만족시키지 못할 수 있다.(조건절에의해 탐색 구간에서 맨뒤쪽에서 데이터를 만날 수도 있다 - 많은 I/O 발생)
- I/O 를 최소화하면서도 소트 연산을 생략하기 위해 다음과 같이 인덱스를 구성해야 한다
=연산자로 사용한 조건절 컬럼 선정
- ORDER BY 절에 기술한 컬럼 추가
=연산자가 아닌 조건절 컬럼은 데이터 분포를 고려해 추가 여부 결정
- 반대 급부도 생각하면서 설계하라
IN 조건은 = 이 아니다
- 소트 연산을 생략하려면 IN 조건절이 IN-List Iterator 방식으로 풀려서는 안된다.
- 즉 IN 조건절을 인덱스 액세스 조건으로 사용하면 안된다.
- 필터 조건으로 사용해야 한다.
- ORDER BY 컬럼 뒤쪽에 분포시키자!
3.4.6 결합 인덱스 선택도
- 인덱스 생성 여부시 선택도(Selectivity) 가 낮아야 한다(전체 레코드 중 조건절에 의해 선택되는 레코드 비율<보통 15% 이하 선정>)
- 카디널리티(선택도 * 총 레코드 수) 를 구한다
컬럼 순서 결정 시, 선택도 이슈
- 결합 인덱스 구성 시 선택도가 낮은 컬럼을 앞에 두든 뒤에 두든 둘다 인덱스 조건이므로 인덱스 스캔 범위는 동일하다
- 중요한 것은 항상 사용하는 컬럼을 앞쪽에 두고 그 중
=조건을 앞쪽에 위치시키는 것이다. - 결론적으로 선택도는 매우 중요하지만 컬럼간 순서를 결정할 때는 필수조건 여부, 연산자 형태가 더 중요하다
3.4.7 중복 인덱스 제거
- 포함 관게시 '완전 중복' 이다. 모든 컬럼을 가지는 하나의 인덱스만 있으면 된다.
- 선두 컬럼이 같고 선두 컬럼의 카디널리티가 매우 낮으면 사실상 중복이다. 이를 '불완전 중복' 이라고 한다. 이런 경우에도 1개만 만들면된다.
- 실습(p245 ~ p249)
3.4.8 인덱스 설계도 작성
- 시스템 전체 효율을 고려해야 한다.
- 인덱스 설계 전체를 조망할 수 있는 설계도면이 필수이다(인덱스 설계도)
- 실제 발생하는 액세스 유형을 모두 조사하는 과정 필요
- 인덱스 설계 전에 파티션 설계를 먼저 진행하거나 최소한 병행해야 제대로 된 인덱스 전략 수립 가능
4.1 NL조인
NL 조인은 인덱스를 이용한 조인이다.
4.1.1 기본 메커니즘
- Nested Loops 조인(NL 조인)
- 일반적으로 NL 조인은 Outer 와 Inner 양쪽 테이블 모두 인덱스를 이용한다.
- Outer 테이블은 사이즈가 크지 않거나 또는 Table Full Scan 을 해도 한번에 그치므로 인덱스를 사용하지 않을 수 있다.
- 하지만 Inner 테이블을 Outer 루프를 읽는 건수만큼 반복되므로 인덱스를 반드시 사용해야 한다.
- 실제 작동 예시(p257 ~ p260)
4.1.2 NL 조인 실행계획 제어
p260 ~ p261 힌트를 통해 순서와 방식(NL, Hash) 제어 가능
4.1.3 NL 조인 수행 과정 분석
p262 ~ p264
4.1.4 NL 조인 튜닝 포인트
p263
- 한 레코드 씩 순차적으로 진행된다는 사실이 중요하다
- (사원_X1 인덱스를 읽고 사월 테이블 액세스하는 부분)초기 컬럼 이 BETWEEN 인 경우 비효율 없이 한벙에 스캔 한다. 하지만 그만큼 테이블 랜덤 액세스가 발생하므로 사원 테이블이 아주 많은 양의 랜덤 액세스를 발생시킬 수 잇으므로 경우에 따라 부서코드 컬럼을 인덱스에 추가하는 방안을 고려해 보저
- (고객_X1 인덱스 탐색 부분) 조인 액세스 횟수가 많을수록 성능이 느려진다. 조인 액세스 횟수는 Outer 테이블인 사원을 일고 필터링한 결과건수에 의해 결정된다.
- 만약 부서코드조건을 만족하는 액세스가 3개이면 3번의 조인시도가 있고, 그 부서코드조건을 만족하는 레코드가 10만건이고 depth 3이면 30만건이 추가적으로 블록을 읽는다.
- (고객_X1 인덱스를 읽고 고객 테이블을 액세스 하는 부분)
>=이 사용되었는데 필터링 되는 비율이 높다면 애초에 인덱스에 최종주문금액 컬럼을 추가하는 방안도 고려
- (고객_X1 인덱스를 읽고 고객 테이블을 액세스 하는 부분)
- 맨처음 액세스하는 사원_X1 인덱스에서 얻은 결과 건수에 의해 전체 일량이 좌우도니다. 이것도 고려해야 한다.
올바른 조인 메소드 선택
- OLTP 시스템에서 튜닝 시 일반적으로 NL 조인부터 고려한다.
- 성능이 느리다면 각 단계의 수행 일량을 분석해서 과도한 랜덤 액세스가 발생하는 지점을 먼저 찾는다.
- 조인 순서를 변경하거나 효과적인 다른 인덱스가 있는지 검토하여 변경하는 것도 고려한다.
- 여러가지 사안들을 고려해도 좋은 성능이 안나온다면 소트 머지 조인이나 해시 조인을 검토한다.
4.1.5 NL 조인 특징 요약
- 랜덤 액세스 위주의 조인이다.
- 레코드 하나를 읽기위해 블록을 통째로 읽는 랜덤 액세스 방식은 비효율이 존재한다.
- 대량 데이터 조인시 불리하다
- 한 레코드씩 순차적으로 진행한다
- 대량 데이터 처리 시 치명적인 한계가 있지만
- 부분범위 처리가 가능한 상황에서는 아무리 큰 테이블을 조인하더라도 매우 빠른 응답 속도를 낼 수 있다.
- 따라서 OLTP 시스템에 적합한 조인 방식이다
4.1.6 NL 조인 튜닝 실습
p 267
1.데이블 액세스가 지나치게 높다는 것은 테이블을 액세스 한 후 필터링 되는 비율이 높다는 것이다. 이런 경우 인덱스에 테이블 필터 조건 컬럼을 추가하는 것을 고려하자
2.테이블 액세스 이전의 인덱스 스캔 단계에서의 일량을 확인해봐야한다.
- 인덱스에서 읽은 블록이 100여개이고 한블록에 평균 500 개가 있다면 인덱스에서 3 건을 얻기 위해 5만개의 레코드를 읽은것이다.(현재 인덱스가
입사일자 + 부서코드인데 입사일자가>=이다 따라서 스캔량이 굉장히 많다.) 이런경우부서코드 + 입사일자로=인 부서코드를 앞에 두는 것을 고려하자. 물론 다른 쿼리에 미치는 영향력을 고려해야 한다.
- 조인 시도 횟수는 많지만 실제 결과는 적을수 있다. 이런 경우 조인 순서를 변경을 고려할 수 있다. 그래도 효과가 없다면 소트머지조인과 해시 조인을 고려해라
4.1.7 NL 조인 확장 메커니즘
- NL 조인 성능을 높이기 위해 테이블 Prefetch, 배치 I/O 기능이 오라클에 존재한다.
- Prefetch : 인덱스를 이용해 테이블을 액세스하거나 디스크 I/O 가 필요해지면 곧 읽게 될 블록까지 미리 읽어서 버퍼캐시에 적재
- 배치 I/O : I/O Call 을 미뤘다가 일정량 쌓이면 한번에 처리
