
1. stackoverflow 사이트 긁어내기
indeed.com 긁어낼때랑 코드가 거의 비슷하다. 그래서 살짝 다른 코드만 살펴보려고 한다.
import requests
from bs4 import BeautifulSoup
URL ="https://stackoverflow.com/jobs?q=python&sort=i"
def so_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagi = soup.find("div", {"class":"s-pagination"}).find_all("a")
last = pagi[-2].get_text(strip=True) #get_text() 함수를 이용해, pagi 안에 텍스트(페이지넘버)를 불러들이고 strip 해서 정리해줌.(이런식으로 strip=true를 인자로 사용가능)
return int(last)
# indeed 서 처럼 link에서 span을 다 뽑아서 리스트에 넣은다음 리스트 마지막 숫자만 뽑아내도 좋고
# 여기서 처럼 아예 링크 마지막 부분을 애초부터 뽑아내도 괜찮다.
def extract_job(html):
title = html.find("h2", {"class": "mb4"}).find("a")["title"]
company = html.find("h3", {"class":"fc-black-700"}).find("span").get_text(strip=True)
location = html.find("span", {"class": "fc-black-500"}).get_text(strip=True)
# strip=True 를 대입하지 않으면 띄어쓰기가 그대로 남아있게되어 듬성듬성 빈틈이 생긴다.
# 참고로 .string()/.strip() 함수로 태그안에 있는 텍스트만 깔끔하게 뽑아내려 했으나 get_text는 위의 함수와 incompatible 하기 때문에 사용하지 못했다.
job_id = html["data-jobid"]
link = f"https://stackoverflow.com/jobs?id={job_id}&q=python"
return {'Title': title ,
'Company': company ,
'location': location,
'link':link
}
나같은 경우 왜 그런지 모르겠지만 니코와 사이트 html 코드 배열이 달라서 사용하지 않았던 방법을 적어보려한다.
<난 사용안했지만, 니코는 사용한것>
tuple unpacking(mutiple assignment)--알아보자!(밑에 계속)
장소와 회사변수를 각각 지정안해주고 한번에 지정할 수 있음
우선 다음과 같은 코드를 살펴보자
company,location = html.find("div", {"class": "-company"}).find_all("span",recursive=False)
recursive = false 는 무슨뜻이냐면, 안에 속해있는 모든 자손을 불러오지 말고 직계자손만, first level 만 불러옴!
예를 들어 아래와 같은 html 코드가 있다고 치고. 위에 코드를 쳤다고 치자.
<div class = -company >
<span class = a>
KIA
<span class = b>LOL</span>
</span>
<span class = a1>
KOREA
</span>
</div>
그럼 직계자손 span 만 불러오므로 결과값은 company = KIA, location = KOREA 가 된다.CSV 에 담기
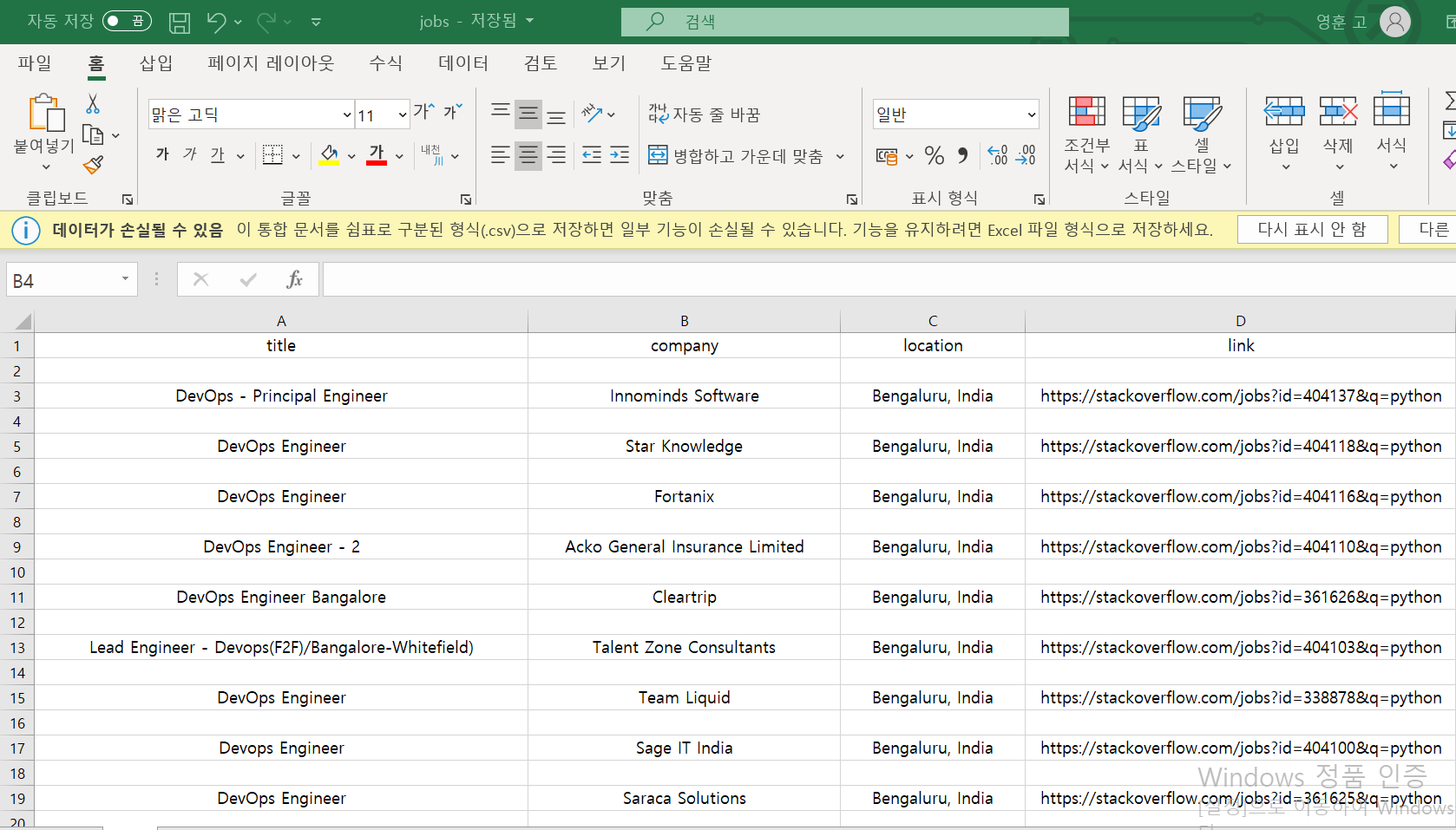
이렇게 해서 두 웹사이트에서 페이지를 긁어 모으는 프로그램을 완성했다. 그럼 엑셀에 담을 일만 남았는데, 엑셀은 윈도우에서만 실행되므로 어디서나 사용가능한, GOOGLE에서 지원하는, CSV 양식에다가 데이터를 저장해보자.
우선 CSV는 아래와 같이 굉장히 간단한 형태로 이루어져 있다.
title,company,location,link
DevOps - Principal Engineer,Innominds Software,"Bengaluru, India",https://stackoverflow.com/jobs?id=404137&q=python
DevOps Engineer,Star Knowledge,"Bengaluru, India",https://stackoverflow.com/jobs?id=404118&q=python
파이썬은 다행히 csv 모듈을 default로 지원해주고 있다.
우선 save.py 파일을 따로 만들고 아래의 코드를 입력한다.
import csv
def save_to_file(jobs):
file = open("C:\python scraper\jobs.csv", mode="w" ,encoding = "utf-8-sig") # 파일 이름이 없으면 자동으로 파일 생성. 그리고 일본어,중국어 때문에 파일이 깨진다면 -sig를 encoding에 추가!
writer = csv.writer(file) # 만든 파일안애 데이터 입력
writer.writerow(["title", "company", "location", "link"]) # 요런 식으로
for job in jobs:
writer.writerow(list(job.values()))
# 그리고 긁어온 데이터를 jobs 인자를 이용해 하나씩 입력한다. 이때 긁어온 데이터들이 list 안에 들어있으므로 list를 입력해준다
# 아울러, 우리가 가져오려는 값이 "company" : "full stack python devloper" 라고 되어있다
# 이때 key,value 중 value 만 가져오려면 ~~.value 이런식으로 코드를 적으면 된다.
return
최종실행
그리고 scrapper.py 에 새로만든 파일을 함께 사용하기 위해 module을 추가해주고 module안에 있는 함수를 지정해주면 끝이다!!
from so import get_jobs as so_jobs
from indeed import get_jobs as indeed_jobs
from save import save_to_file
jobs = so_jobs() + indeed_jobs()
save_to_file(jobs)
그럼 아래와 같이 csv 파일안에 데이터가 저장된것을 볼 수 있다!

'과연 이게 최선일까?' 끊임없이 생각하기