관계 데이터 연산 (Relational Data Operation)
원하는 데이터를 얻기 위해 relation에 필요한 처리 요구를 수행하는 것.

1. 집합 연산자 (Set Operation)
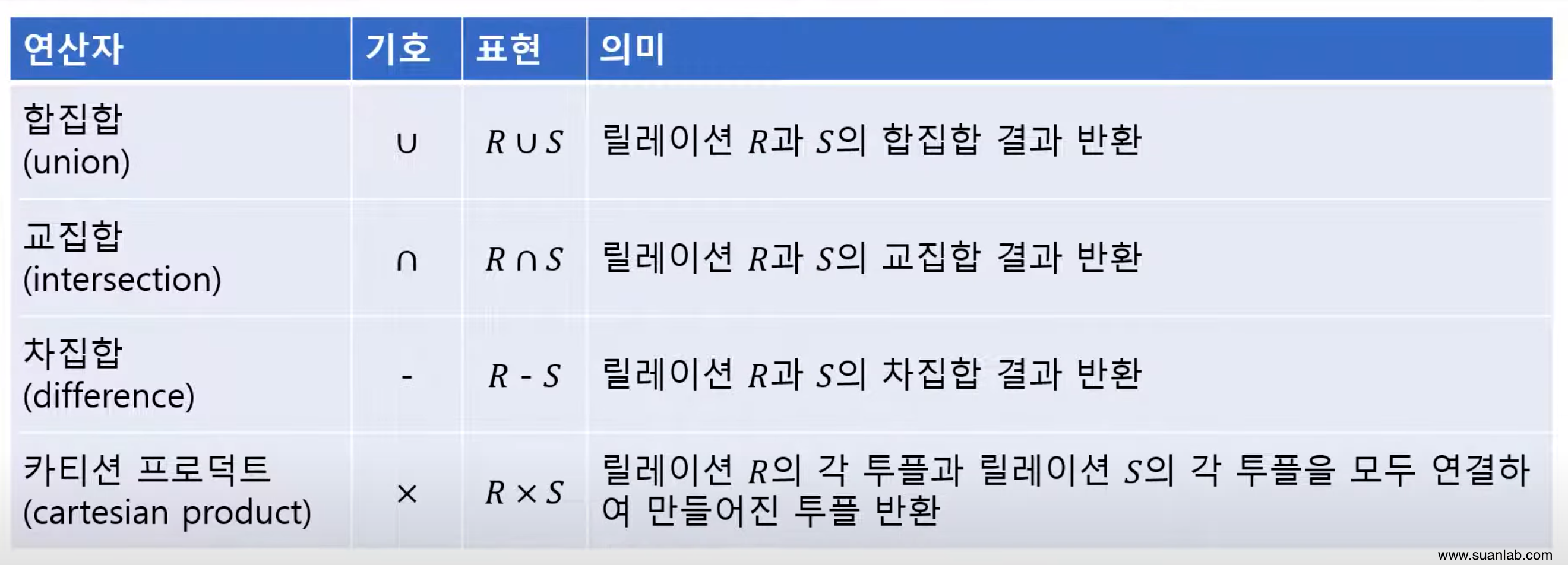
피연산자(Operand) 2개 필요.
2개의 relation을 대상으로 연산 수행.
합집합, 교집합, 차집합은 피연산자인 두 relation이 합병이 가능해야 함.
Union-compatible 조건
두 relation의 차수(degree)가 같아야 함.
두 relation에서 서로 대응되는 속성의 domain이 같아야 함.
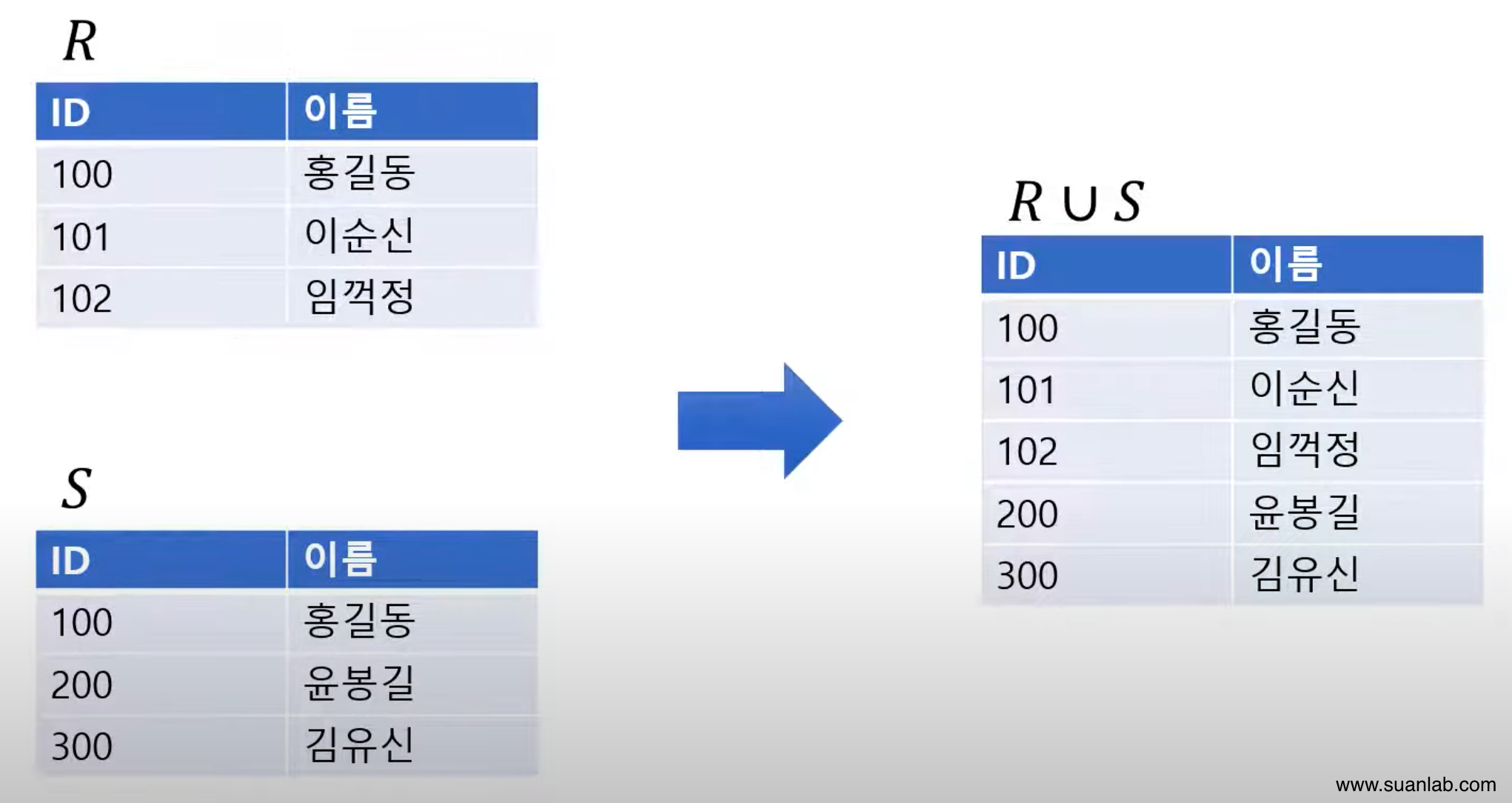
합집합 (Union)
합병 가능한 두 relation R과 S의 합집합 = R∪S.
Relation R에 속하거나 relation S에 속하는 모든 tuple로 결과 relation 구성.
차수는 relation R과 S의 차수와 같음.
Cardinality는 relation R과 S의 cardinality를 더한 것과 같거나 적어짐.
교환적 특징: R∪S = S∪R.
결합적 특징: (R∪S)∪T = R∪(S∪T).
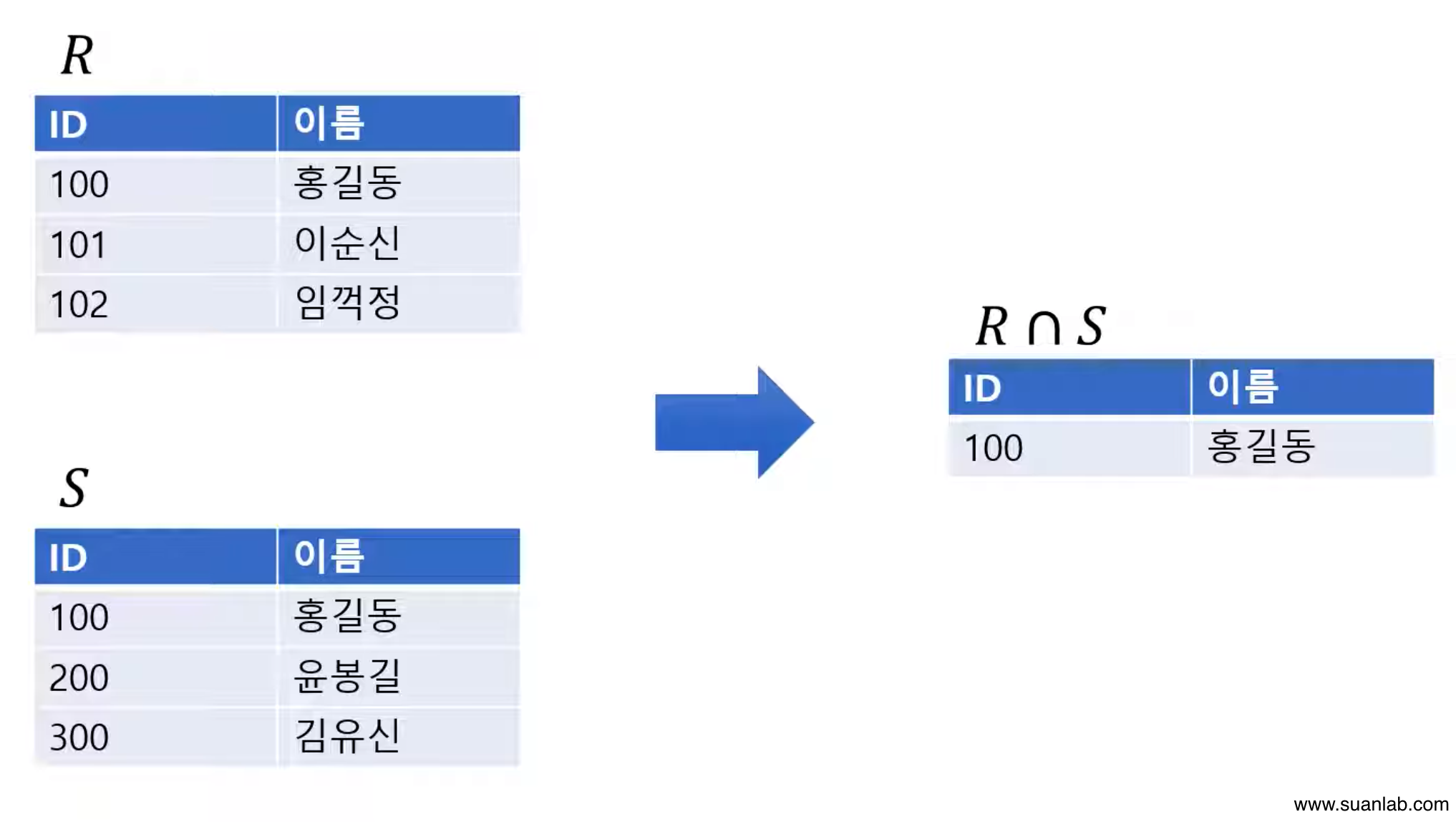
교집합 (Intersection)
합병 가능한 두 relation R과 S의 교집합 = R∩S.
Relation R과 S에 공통으로 속하는 tuple로 결과 relation 구성.
차수는 relation R과 S의 차수와 같음.
Cardinality는 relation R과 S의 어떤cardinality보다 크지않음.
교환적 특징: R∩S = S∩R.
결합적 특징: (R∩S)∩T = R∩(S∩T).
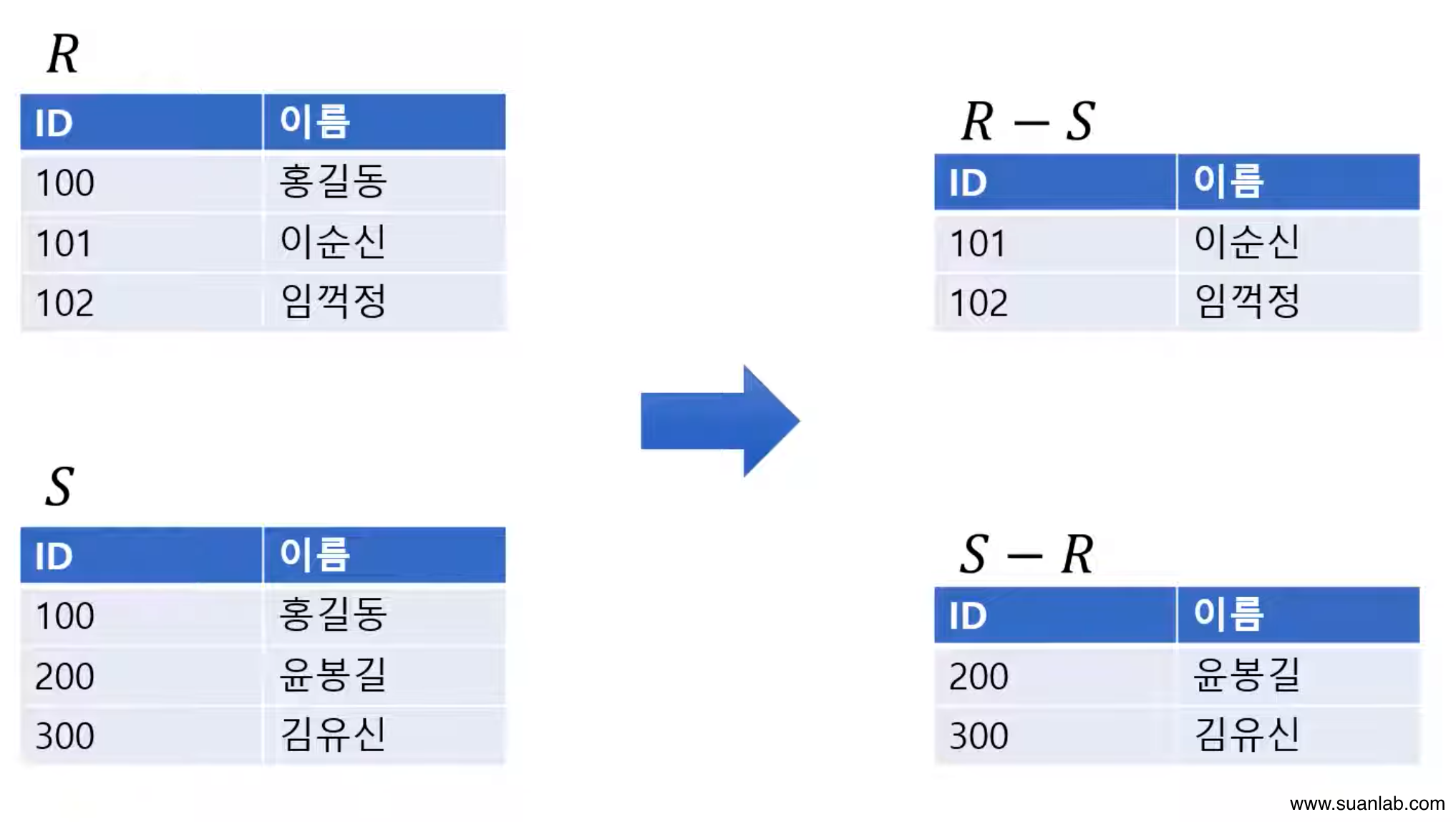
차집합 (Difference)
합병 가능한 두 relation R과 S의 차집합 = R-S.
Relation R에는 존재하지 않는 tuple로 결과 relation 구성.
차수는 relation R과 S의 차수와 같음.
R-S의 cardinality는 relation R의 cardinality와 같거나 적음.
S-R의 cardinality는 relation S의 cardinality와 같거나 적음.
교환적, 결합적 특징 없음.
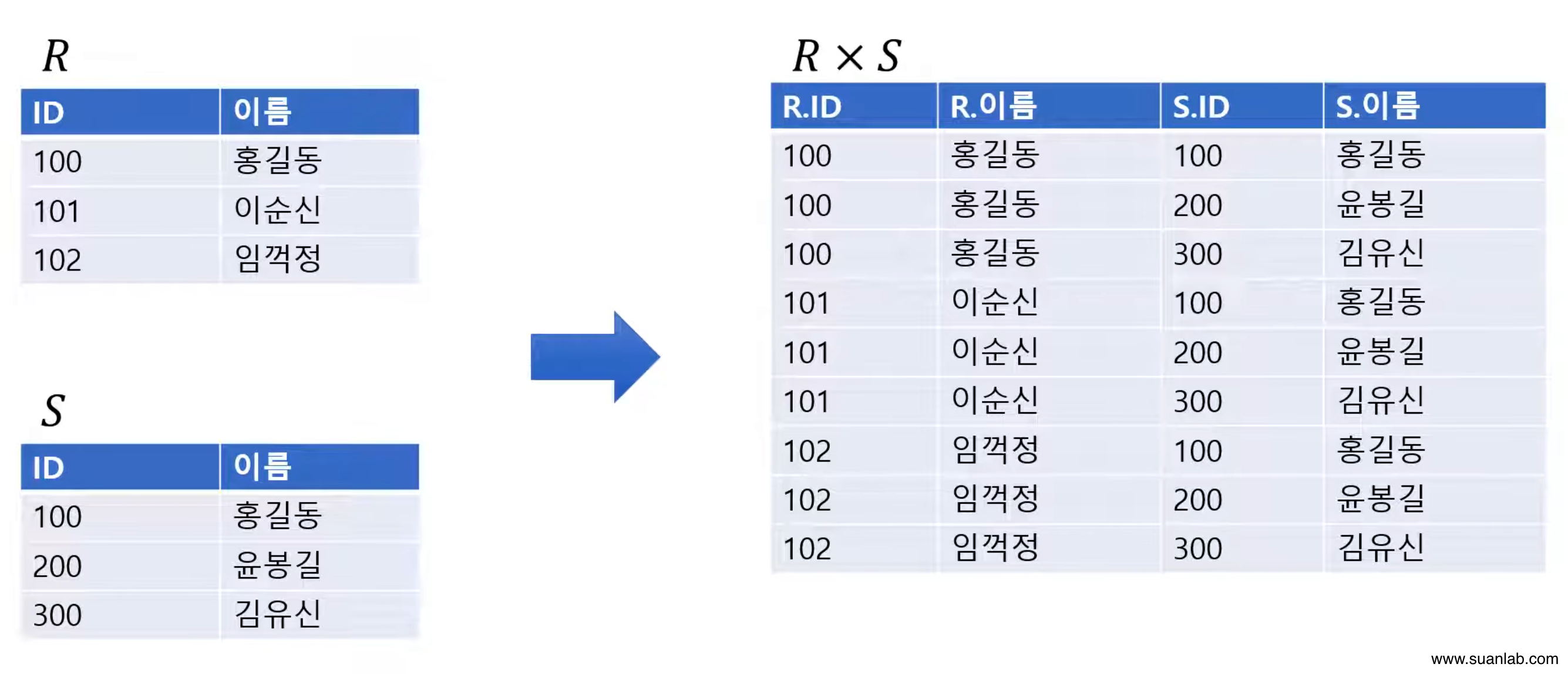
카티션 프로덕트(Cartesian Product)
두 relation R과 S의 cartesian product = RxS.
Relation R에속한 각 tuple과 relation S에 속한 각 tuple을 모두 연결하여 만들어진 새로운 tuple로 결과 relation을 구성.
차수는 relation R과 S의 차수를 더한 것과 같음.
Cardinality는 relation R과 S의 cardinality를 곱한 것과 같음.
교환적 특징: RxS = SxR.
결합적 특징: (RxS)xT = Rx(SxT).
2. 관계 연산자 (Relational Operators)

원하는 결과를 얻기 위해 원하는 데이터가 무엇인지 기술.
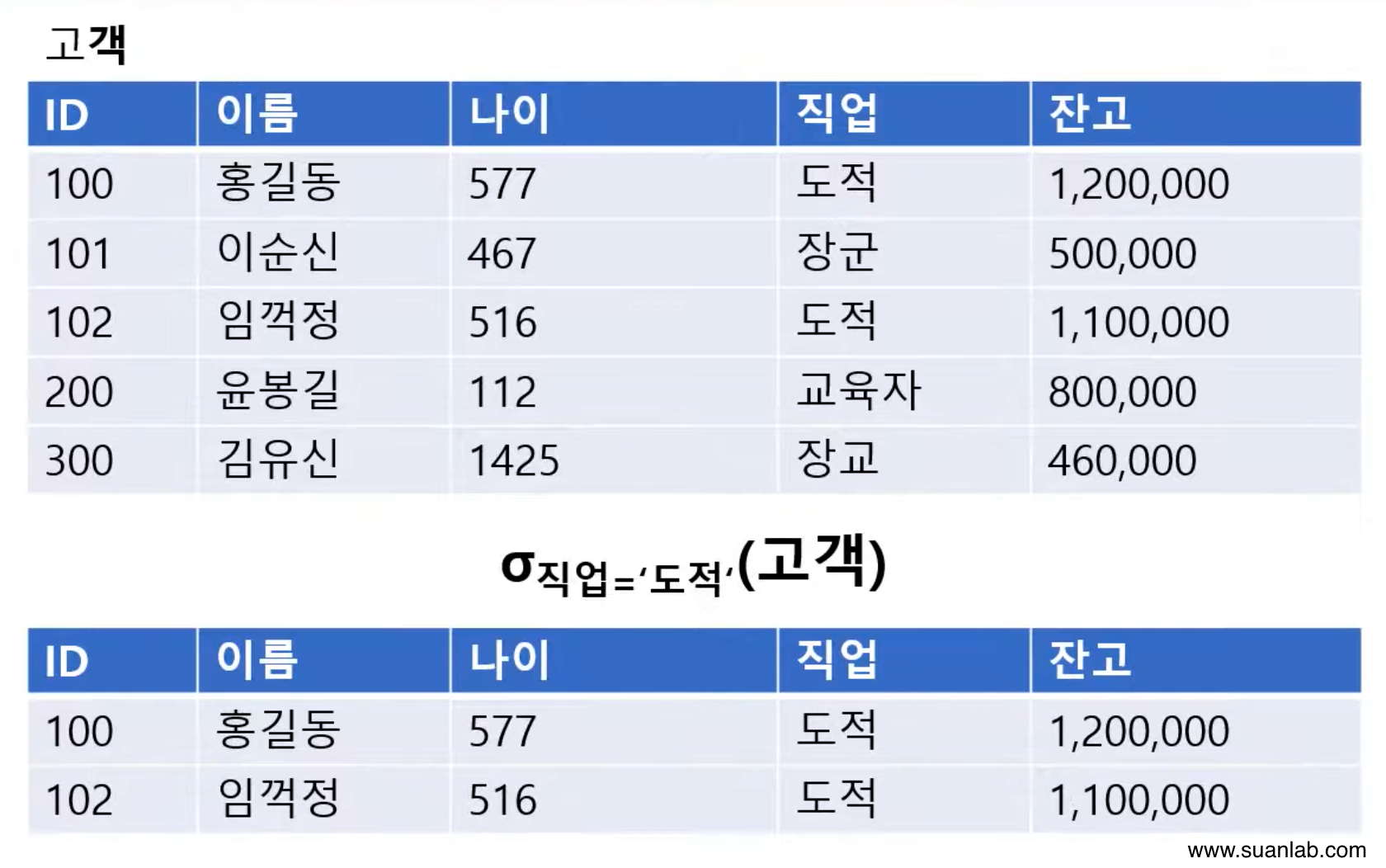
셀렉트 (Select)
Relation에서 조건을 만족하는 tuple만 선택하여 결과 relation을 구성.
하나의 relation을 대상으로 연산을 수행.
데이터 언어적 표현법: 'Relation' WHERE 'Conditional'.
조건식: 비교식 or Predicate이라고도 함.
속성과 상수의 비교나 속성들 간의 비교로 표현.
비교 연산자 (<,≤,≥,>,=,≠)와 논리 연산자(∧,∨,¬)를 이용해 작성.

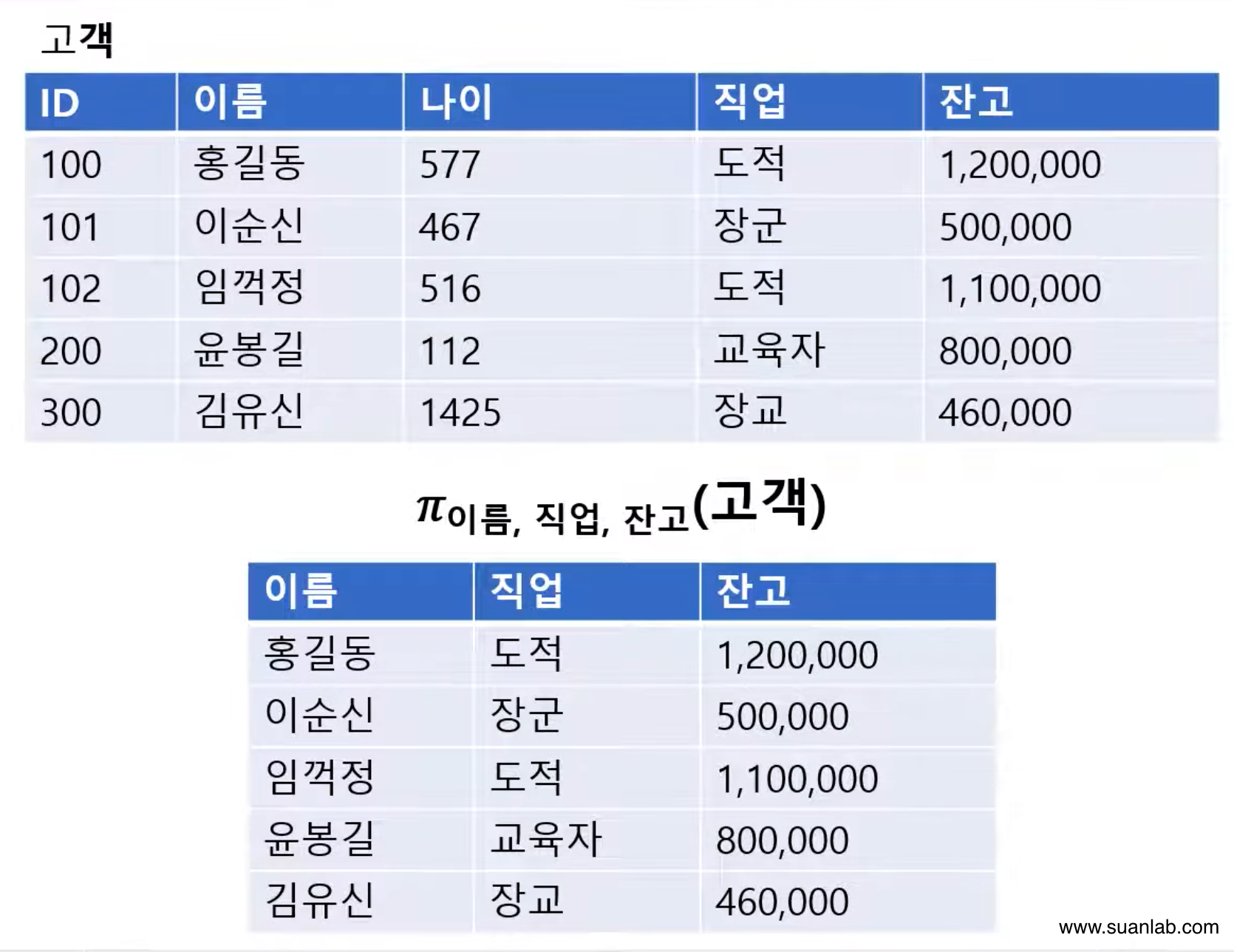
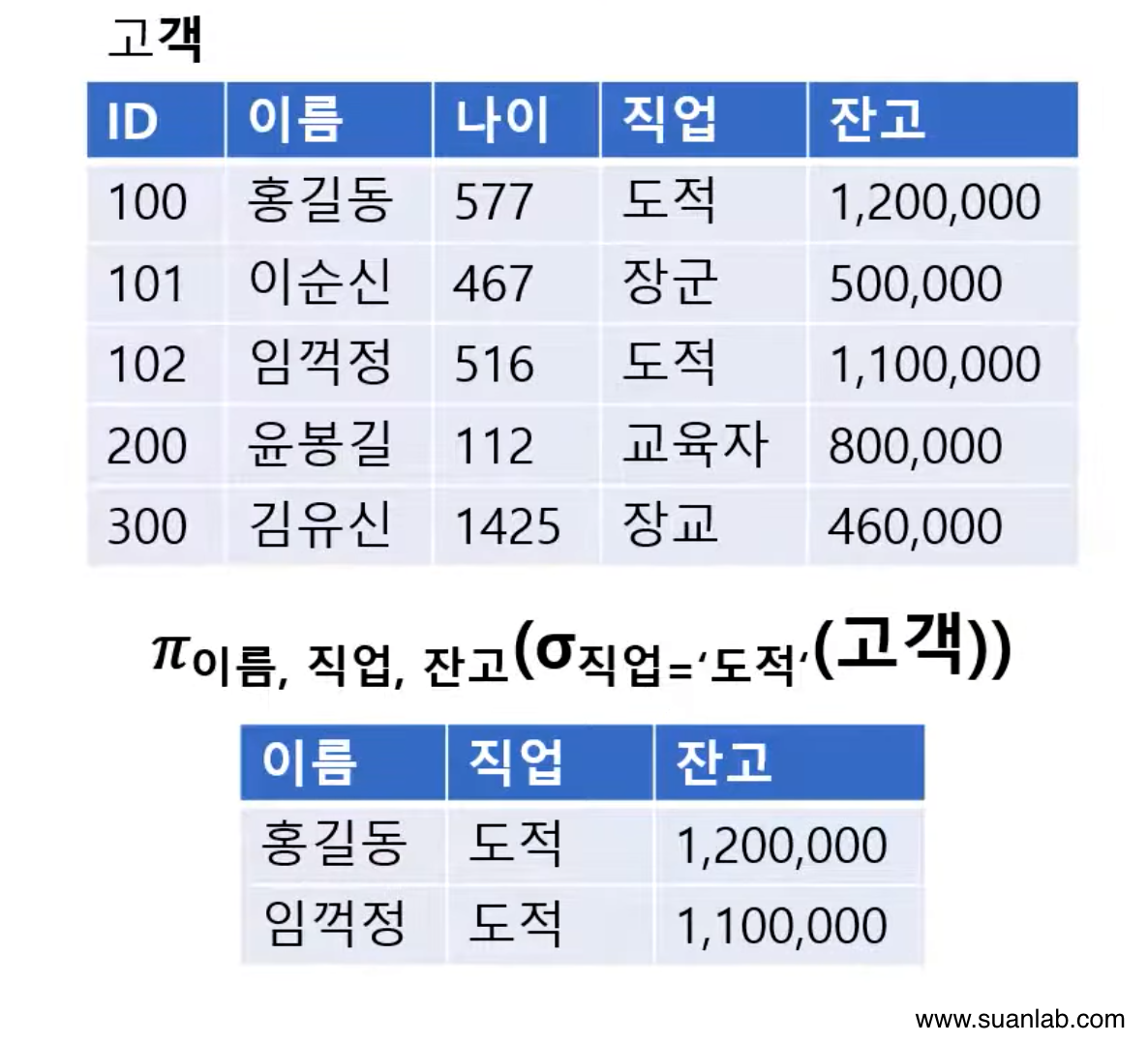
프로젝트(Project)
Relation에서 선택한 속성의 값으로 결과 relation을 구성.
하나의 relation을 대상으로 연산을 수행.
수학적 표현법:𝜋Relation (속성리스트)
데이터 언어적 표현법: Relation [속성리스트]
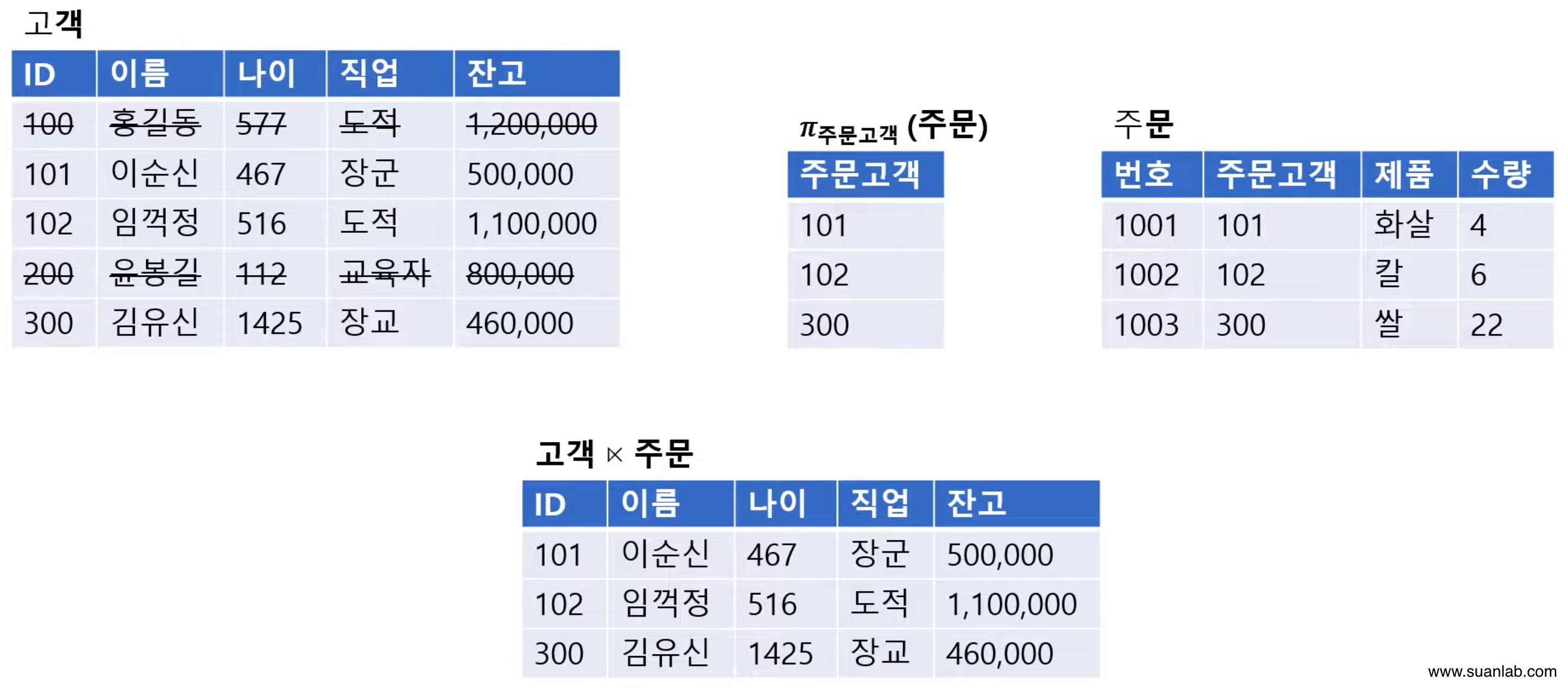
조인(Join)
Join 속성을 이용해 두 relation을 조합하여 결과 relation을 구성.
Join 속성의 값은 tuple만 연결하여 생성된 tuple을 결과 relation에 포함.
Join 속성: 두 relation이 공통으로 가지고 있는 속성.
표현법: Relation1 ⋈ Relation2
자연 조인(Natural Join)이라고도 함.
표현법: Relation1 ⋈ɴ Relation2
세타 조인(Theta Join, 𝜃-join)
자연 Join에 비해 더 일반화된 Join.
주어진 Join조건을 만족하는 두 relation의 모든 tuple을 연결하여 생성된 새로운 tuple로 결과 relation을 구성.
결과 relation의 차수는 두 relation의 차수를 더한 것과 같음.
표현법: Relation1 ⋈A𝜃B Relation2
𝜃는 비교 연산자(<,≤,≥,>,=,≠)를 의미.
동일 Join(Equi-join): 𝜃 연산자가 "="인 theta join을 의미.
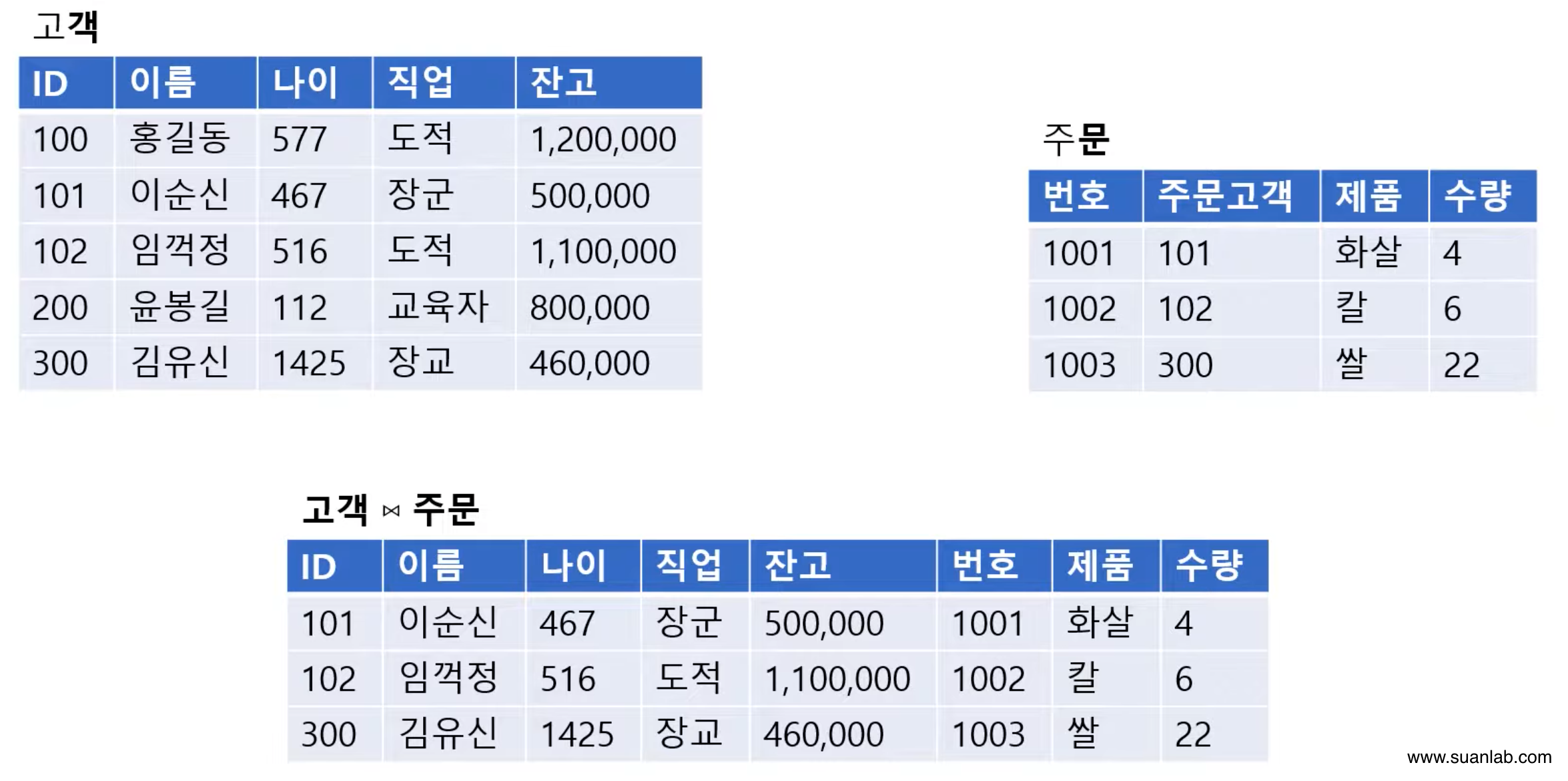
디비전(Division)
표현법: Relation1 ÷ Relation2
Relation2의 모든 tuple과 관련있는 Relation1의 tuple로 결과 relation을 구성.
단, relation1이 relation2의 모든 속성을 포함하고 있어야 연산이 가능함.
Domin이 같아야 한다는 의미.
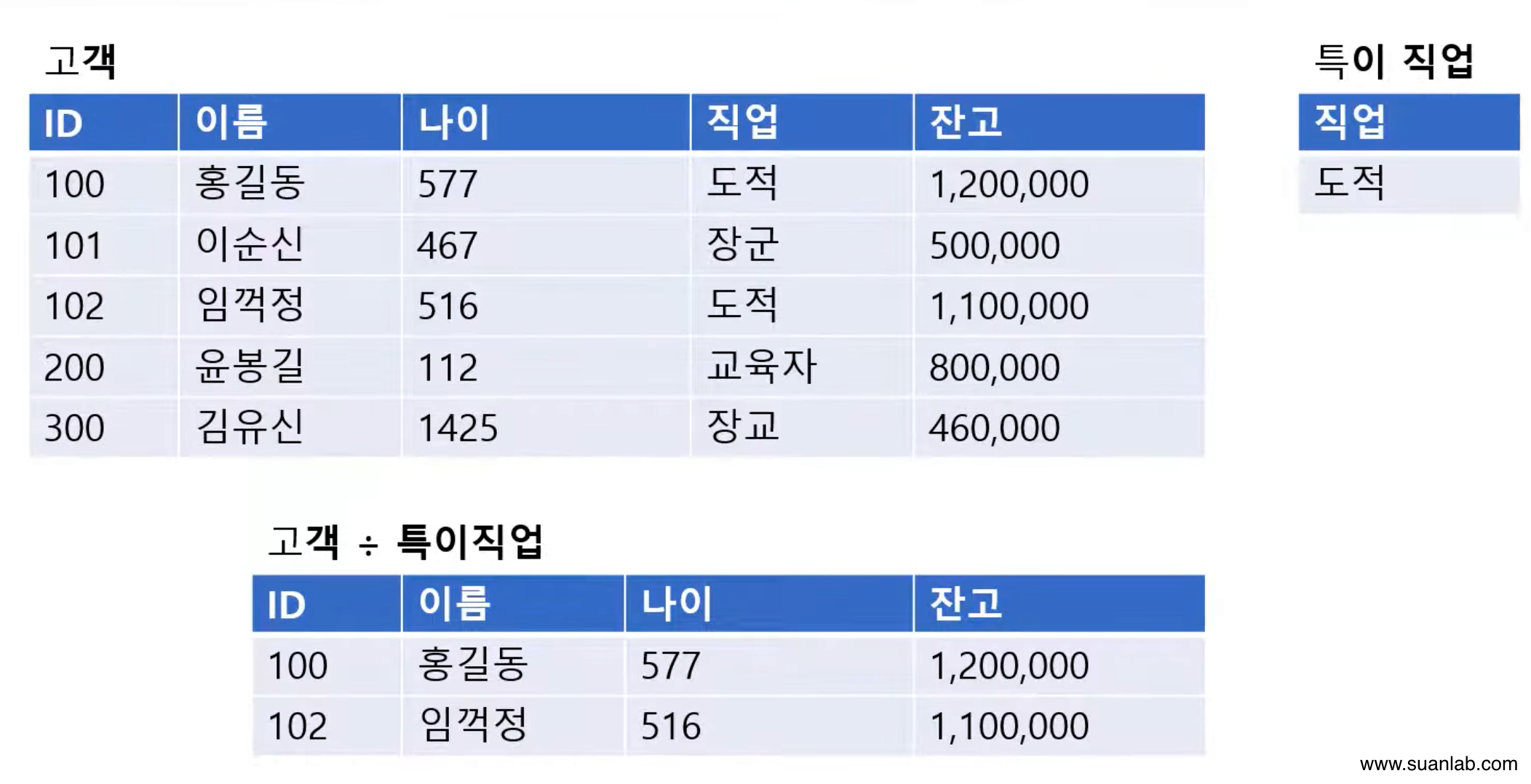
세미 조인 (Semi-join)
Join속성으로 프로젝트 연산을 수행한 relation을 연산을 수행한 relation을 이용하는 join.
표현법: Relation1 ⋉ Relation2.
Relation2를 join 속성으로 project 연산한 후, relation1에 natural-join하여 결과 relation을 구성.
불필요한 속성을 미리 제거하여 join 연산 비용을 줄이는 장점이 있음.
교환적 특징이 없음: R⋉S ≠ S⋉R.
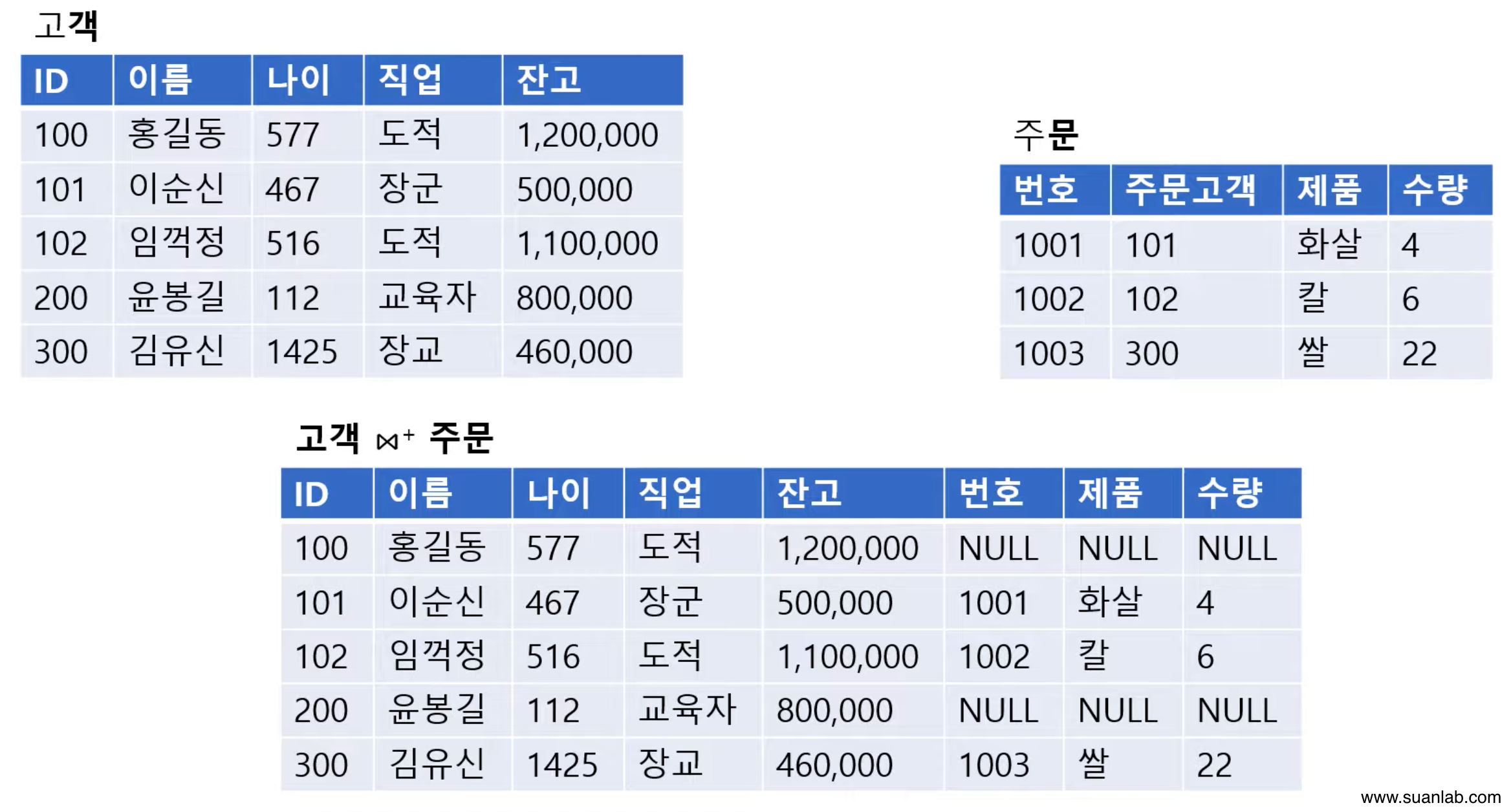
외부 조인 (Outer-join)
Natural-join 연산에서 제외되는 tuple도 결과 relation에 포함 시킴.
두 relation에 있는 모든 tuple을 결과 relation에 포함.
표현법: Relation1 ⋈+ Relation2
관계 대수 (Relational Algebra)
원하는 결과를 얻기위해 데이터의 처리 과정을 순서대로 기술.
Relation 처리 연산자: 일반 집합 연산자와 순수 관계 연산자로 분류.
Closure Property: 피연산자(Operand)도 relation이고 연산의 결과도 relation.
관계 해석 (Rational Calculus)
비절차 언어(Nonprocedural Language): 처리를 원하는 데이터가 무엇인지만 기술하는 언어.
수학 프레디킷 해석 (Predicate Calculus)에 기반을 두고 있음.
분류:
-투플 관계 해석(Tuple rational calculus)
-도메인 관계 해석(Domain rational calulus)
대수와 해석의 역할
데이터 언어의 유용성을 검증하는 기준.
기술할수 있는 모든 질의를 기술할 수 있는 데이터 언어를 relationaly complete 하다고 판단.
Query = 데이터에 대한 처리요구.
