저는 술을 참 좋아합니다.
그런데 술에는 종류가 참 많습니다.
위스키, 진, 와인, 데킬라, 럼 ....
이 술의 종류 안에도 다양한 종류와 브랜드의 술이 있습니다.
위스키에는 스카치 위스키와 몰트 위스키, 아메리칸, 캐나다, 재패니즈 위스키 ....
진에는 런던 드라이, 쥬네버, 올드 톰 진 ....
이렇게 하나의 카테고리에 여러 객체들이 존재하는 데이터들을 컴퓨터는 배열로 표현해 공간을 정해주고 하나씩 넣어 사용 할 수 있습니다.
이러한 데이터 타입을 배열(Array)라고 합니다.
배열의 선언과 출력
배열은 이미 값을 가지고 있는 배열과 값을 알 수 없는 배열로 정의하는 방법이 두 가지 입니다.
1. 값이 존재 할 때
String[] whisky = {"Scotch","Single Malt","American","Canadian"};
System.out.println(A[0]); //Scotch
System.out.println(A[1]); //Single Malt
System.out.println(A[2]); //American
System.out.println(A[3]); //Canadian
int a = A.length;
System.out.println(a); //4 2. 값이 존재하지 않을 때
값이 존재하지 않을 때에는 변수를 초기화하여 사용합니다.
초기화(initialization)란 변수를 설정하고 그 변수에 최초의 값을 설정해주는 행위입니다.
객체지향 언어인 java에서는 아래와 같이 String객체 배열의 값을 초기화하지 않으면 변수에 대한 값을 할당해주지 않아 에러를 반환합니다.
String[] whisky = new String[4];
whisky[0] = "Scotch";
whisky[1] = "Single Malt";
whisky[2] = "American";
whisky[3] = "Canadian";
//호출 방법 1
for(String i : whisky) {
System.out.println(i);
/*Scotch
Single Malt
American
Canadian*/
}
//호출 방법 2
System.out.println(Arrays.toString(whisky));
//[Scotch, Single Malt, American, Canadian]
배열을 출력 할때에는 for문 혹은 Arrays.toString() 을 사용합니다.
둘 다 배열의 전체 데이터를 조회 할 수 있지만 조회 방식은 다릅니다.
배열은 데이터가 존재할때와 존재하지 않을때 정의하는 방법도 다르지만
출력 할 때 순서(index)와 길이(length)의 차이도 있습니다.
순서는 0부터 시작입니다.
[0] 이 첫번째 데이터를 호출하고 [1]이 두번 째 데이터를 호출하죠
길이(length)는 0을 포함하지 않는 자연수입니다.
예를들어 length가 4인 배열은 [0],[1],[2],[3] 로 호출 할 수 있습니다.
헷갈리지 말아야 할 것이 선언할때 []안에는 length의 값으로 크기를 정해주고
출력 할 때에는 index로 호출해야 합니다.
배열의 특징
배열의 가장 큰 특징은 데이터의 크기가 고정적이라는 점입니다.
예를 들어 술을 100병까지 적재 할 수 있는 주문 제작한 술장이 있습니다.
하지만 술을 10병만 가지고 있다면 이 술장에 채워 넣을 수 있는 90병의 공간은 비어있는 상태입니다.
또한 이 술장의 주인은 강박이 있어 A라는 위스키를 A-1이라는 자리에 두면 A위스키의 자리는 다 마셔서 버리기 전 까지 A-1이라는 고정의 자리가 생깁니다.
하지만 이 술장은 마법의 술장이 아니기 때문에 부피는 100병을 수용 할 수 있는 그대로입니다.
남은 90병의 자리는 존재하지만 비워두어야하며 101번째 술은 수용하지 못하죠
이는 곧 공간낭비(메모리낭비)로 이어집니다.
사람의 눈에는 비어있는 공간일지라도 컴퓨터는 그 공간을 사람들이 흔히 말하는 쓰레기 값으로 채워넣습니다. 예를들면 String 객체는 null, int 객체는 0을 자동할당해줍니다.
이렇듯 배열의 사이즈와 데이터의 위치는 고정적이며 이 공간을 다 사용하지 못하면 낭비가 됩니다.
이러한 특징은 단점으로 치부되기도 하지만 반대로 장점이기도 합니다.
고정적인 길이의 배열 데이터라면 메모리관리 측면에서 편리하며 검색도 용이합니다.
다차원 배열의 선언과 출력
배열에는 차원이 존재합니다.
whisky에는 위에서 말 한 것처럼 여러 종류의 위스키가 있고 여러 종류의 위스키에는 다양한 브랜드의 상품들이 존재하죠.
여러 종류의 위스키의 다양한 브랜드를 배열로 저장하려면 행과 열을 사용해야 합니다.
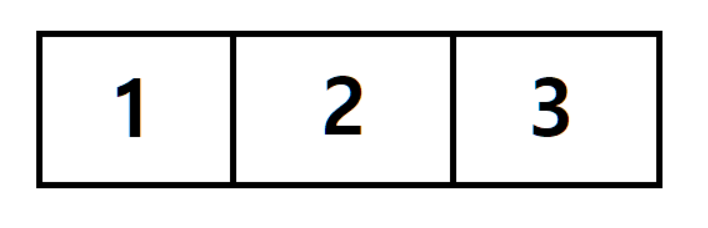
1차원 배열
1차원 배열은 위의 내용에 부합하는 조건의 배열입니다. 배열이 하나만 존재하죠
이번엔 int 배열 객체로 생성해보겠습니다.
int[] arr = new int[3];
arr[0] = 1;
arr[1] = 2;
arr[2] = 3;
System.out.println(Arrays.toString(arr1));
//[1, 2, 3]length는 3이고 index는 [0],[1],[2] 인 1차원 배열을 생성했습니다.
아래 그림과 같이 이 배열은 행이 하나죠.
2차원 배열
String[][] arr = new String[2][3];
arr[0][0] = "0-0";
arr[0][1] = "0-1";
arr[0][2] = "0-2";
arr[1][0] = "1-0";
arr[1][1] = "1-1";
arr[1][2] = "1-2";
for(int row = 0; row < arr.length; row++) {
for(int col = 0; col <arr[0].length; col++) {
System.out.println(arr[row][col]);
/*
0-0
0-1
0-2
1-0
1-1
1-2
*/
}
}
System.out.println(Arrays.deepToString(arr));
//[[0-0, 0-1, 0-2], [1-0, 1-1, 1-2]]위 2차원 배열은 2행의 3열로 사이즈가 정해져서 생성 된 배열 입니다.
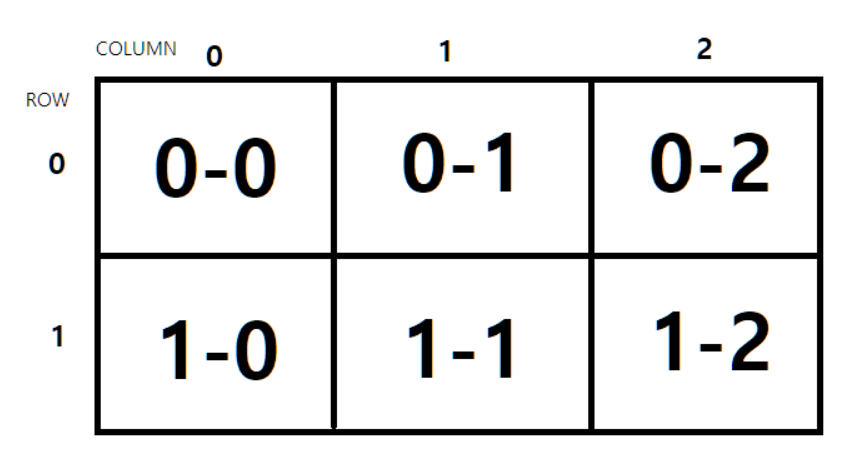
ROW와 COLUMN도 0부터 시작합니다.
arr[0][0] 은 0번째 행의 0번째 열의 값인 '0-0'을 담고있는 것 이죠
또한 출력 시 배열은 Arrays.toString()를 사용했지만 다차원 배열은 Arrays.deepToString(arr)을 사용합니다.
다차원 가변배열
String[][] staticArr = {{ "A", "B", "C" }, { "D", "E" }};
for(int row = 0; row < staticArr.length; row++) {
for(int col = 0; col < staticArr[row].length; col++) {
//row는 0,1 col은 row가 0일때 0,1,2와 row가 1일때 0,1
System.out.println(staticArr[row][col]);
/*A
B
C
D
E*/
}
}
System.out.println(Arrays.deepToString(staticArr));
//[[A, B, C], [D, E]]
}