Today's topic
이번 posting에서는 python으로 multithreading 작업을 할 때 만날 수 있는 GIL에 대해서 정리해 보도록 하겠다.
👉 What is "GIL"?
우리는 Python으로 programming을 하면서 multithreading 작업을 할 시 GIL이라는 단어를 만난다. GIL은 무엇일까?
GIL은 Global Interpreter Lock의 약자 이다.
GIL은 python 객체에 대한 access를 보호하여 여러 thread가 한번에 python bitecode를 한 번에 access하는 것을 방지하는 mutex이다.
즉, 한 process 내에서 python interpreter(Cpython)는 한 시점에 한 thread에서만 실행이 될 수 있다. 다른 말로 하면 multithread를 사용할 수 있으나 병렬로 사용은 불가능 하다.
- Mutex 란?
동시 프로그래밍에서 공유 불가능한 자원의 동시 사용을 피하기 위해 사용되는 알고리즘으로, 임계 구역(critical section)으로 불리는 코드 영역에 의해 구현된다.
아래 그림은 한 process 내 thread 간 동작 방식을 보여준다.
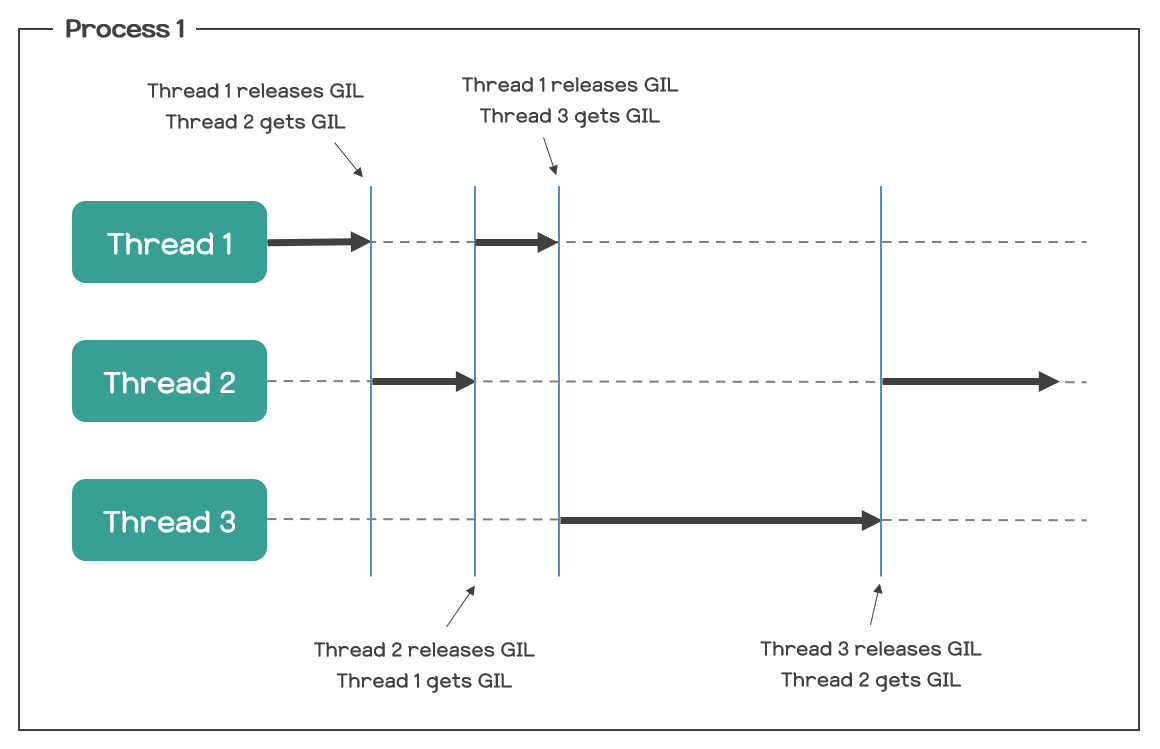
👉 Why "GIL" is necessary?
간단히 말해서 multithreading을 사용할 경우 GIL이 적용되지 않을 경우 thread는 stack을 제외한 다른 memory들을 공유하고 있으므로 객체에 대해서도 영향을 받게 된다.
Python은 객체로 이루어져 있고 이 객체들은 reference counting이라는 field를 가지고 있으며, 이 reference counting에 따라 객체가 메모리 상에서 삭제가되거나 유지되고는 한다. Reference counting이 0이되면 메모리 상에서 삭제가 되는 Garbage collection이라는 mechanism이 작동된다.
만약, GIL이 적용되지 않을 경우 여러 thread에서 한 객체를 참조할 때 각 thread에서 실시간 동기화가 되지 않는 경우 어디서는 reference counting이 0이되어 삭제가 될 수 있고, 어떤 thread에서는 필요로 하는 경우가 발생할 수 있어 reference counting이 맞지 않아서 발생할 수 있는 error가 발생할 수 있다.
이러한 multi thread의 환경에서 필요한 것이 GIL의 정의를 언급할 때 나왔던 mutex다. Mutex란 multithreading 환경에서 여러 개의 thread가 어떤 자원에 접근을 할 때, 그 공유된 자원에 접근하기 위한 열쇠와 같은 것이다.
Python은 객체로 이루어진 객체 지향 언어이다. 만약 GIL이 적용되지 않고 Mutex를 각 객체에 적용한다면 거의 모든 객체에 적용을 시켜야 하기에 효율성이 떨어지며, 각 programmer가 이 작업을 할 경우 놓칠 수 있는 문제점이 있다.
그렇기에 Python에서는 애초에 GIL을 적용시켜 이러한 문제점을 방지하는 전략을 택하였다.
👉 Possible to use multithreading?
위의 설명대로라면 GIL로 인해 multithreading의 사용은 python에서는 필요가 없어 보인다.
아래 예시 코딩을 보면 single thread를 사용 시나 multi thread 사용 시에 별차이가 없는 것을 볼 수 있다.
import time, threading
def for_loop():
for i in range(100000000):
pass
# Single Thread
start = time.time()
for_loop()
for_loop()
end = time.time()
print(f'[Single Thread] total time : {end - start}')
# Multi Thread
start = time.time()
thread1 = threading.Thread(target=for_loop)
thread2 = threading.Thread(target=for_loop)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
end = time.time()
print('[Multi Thread] total time : {}'.format(end - start))
#result
[Single Thread] total time : 6.235410928726196
[Multi Thread] total time : 6.110148191452026Single thread, multi thread 각각 100000000 까지를 for문으로 돌리는데 6.23초, 6.11초가 소요되었다. Multi thread를 사용하여 이정도 차이가 난다면 굳이 쓸 필요가 있는가?
아래 예시는 time.sleep이 적용된 경우이다.
이 경우는 multi threading의 경우가 확실히 시간이 적게 소요가 된 것을 알 수 있다.
import time
import threading
def sleep():
time.sleep(3)
# Single Thread
start = time.time()
sleep()
sleep()
end = time.time()
print('[Single Thread] total time : {end - start}')
# Multi Thread
start = time.time()
thread1 = threading.Thread(target=sleep)
thread2 = threading.Thread(target=sleep)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
end = time.time()
print('[Multi Thread] total time : {end - start}')
#result
[Single Thread] total time : 6.009874105453491
[Multi Thread] total time : 3.0048019886016846이 처럼 time.sleep 작업이나 I/O 작업이 많은 경우에는 multi threading을 사용할 시에는 효율이 높다.
그래서 위와 같은 경우들에는 multi threading을 사용하면 작업의 효율을 높일 수 있다.
👉 How to 'Parallel programming'?
그러면 일반 CPU 연산에 대해 병렬 처리하려면 어떻게 할 수 있을까?
크게 2가지 방법이 있다.
-
Multi processing을 이용
한 process 내의 여러 thread들은 서로 자원을 공유하지만, 여러 process 들에서는 각각의 process의 고유의 자원을 가지기에 자원을 공유하지 않는다. 물론 자원공유는 할 수 있으나 특별한 방법을 통해 공유가 가능하므로 병렬 처리를 원하는 경우에는 multi processing을 통해 처리 할 수 있다. -
다른 Interpreter 구현체를 사용
Python의 interpreter는 CPython으로 되어있다. 이 것을 Jpython 등의 interpreter로 변경하면 GIL을 우회할 수 있는데, 흔히 사용되는 방법은 아니다.
📖 출처 :
- https://it-eldorado.tistory.com/160
- https://wiki.python.org/moin/GlobalInterpreterLock
https://ssungkang.tistory.com/entry/python-GIL-Global-interpreter-Lock%EC%9D%80-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C
My opinion
이번 posting에서는 GIL에 대해 알아 보았고 이로 인한 multi threading이 받는 영향에 대해서도 알아 보았다. Multi로 사용되면 무조건 효율이 좋을 줄 알고 있었는데, 각 경우에 따라 알맞는 방법을 적용하여 programming을 해야겠다고 한 번 더 느꼈다.
